







特别是最后一行,猴子,后面没有其它字符了,但是 * 表示可以匹配 0 次,所以表达式也是成立的。我们也用 Python 代码看一下:
import re
content = """苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,
"""
for item in re.findall(pattern=',.\*',
string=content):
print(item)
,是绿色的
,是橙色的
,是黄色的
,是黑色的
,
💡 注意,.* 在正则表达式中非常常见,表示匹配任意字符任意次数。
当然这个 * 前面不是非得是 .,也可以是其它字符,如 Fig.5 所示。
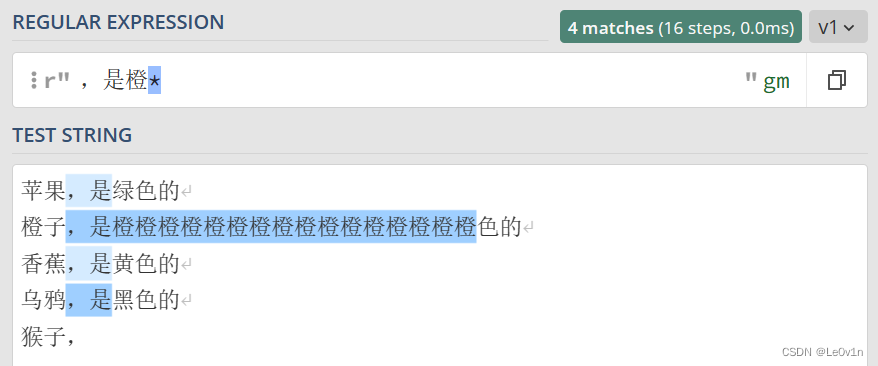
Fig.5 其他* 的示例
4.2.3 特殊字符:+(重复匹配多次,不包括 0 次)
+ 表示匹配前面的子表达式一次或多次,不包括 0 次。
还是上面的例子,我们要从文本中,选择每行逗号后面的字符串内容,包括逗号本身。但是添加一个条件,如果逗号后面没有内容,就不要选择了。
苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,
我们可以这样写正则表达式:
,.+
验证结果如 Fig.6 所示。
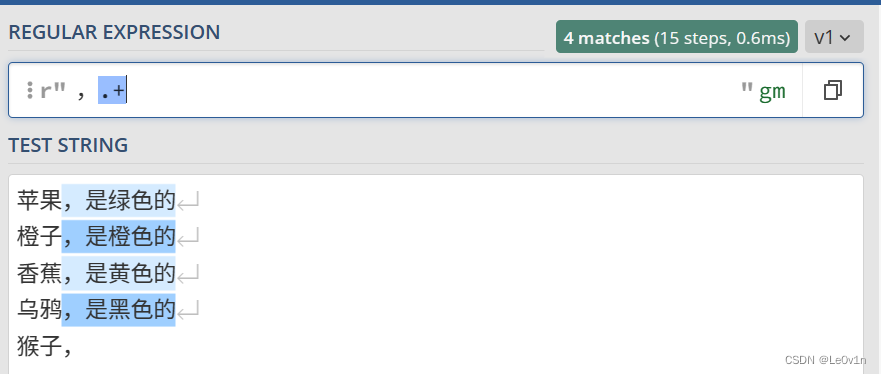
Fig.6 .+ 的使用示例
最后一行,猴子, 后面没有其它字符了,+ 表示至少匹配 1 次,所以最后一行没有子串选中。
4.2.4 特殊字符:?(匹配 0 ~ 1 次)
? 表示匹配前面的子表达式 0 次或 1 次。
还是上面的例子,我们要从文本中,选择每行逗号后面的1个字符,也包括逗号本身。
苹果,绿色的
橙子,橙色的
香蕉,黄色的
乌鸦,黑色的
猴子,
那正则表达式可以这样写:
,.?
验证结果如 Fig.7 所示。
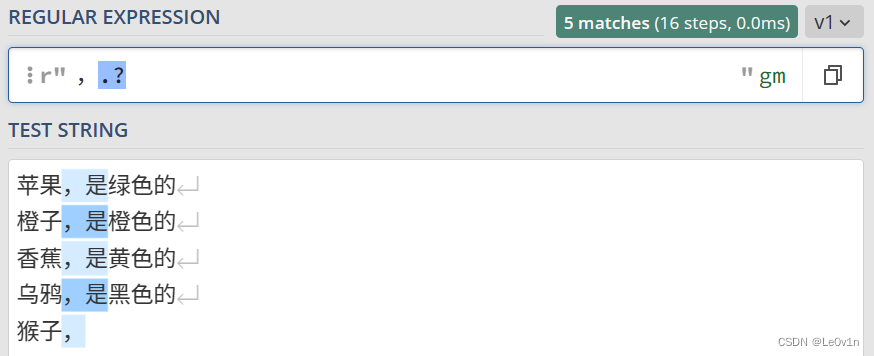
Fig.7 .? 的使用示例
最后一行,猴子, 后面没有其它字符了,但是 `?`` 表示匹配 1 次或 0 次,所以最后一行也选中了一个逗号字符。
4.2.5 特殊字符:{}(匹配指定次数)
示例文本如下所示:
红彤彤,绿油油,黑乎乎,绿油
红彤彤,绿油油,黑乎乎,绿油油
红彤彤,绿油油,黑乎乎,绿油油油
红彤彤,绿油油,黑乎乎,绿油油油油
红彤彤,绿油油,黑乎乎,绿油油油油油
- 表达式
油{3}就表示匹配连续的油字 3 次。 - 表达式
油{3,4}就表示匹配连续的油字至少 3 次,至多 4 次
示例如 Fig.8 所示。
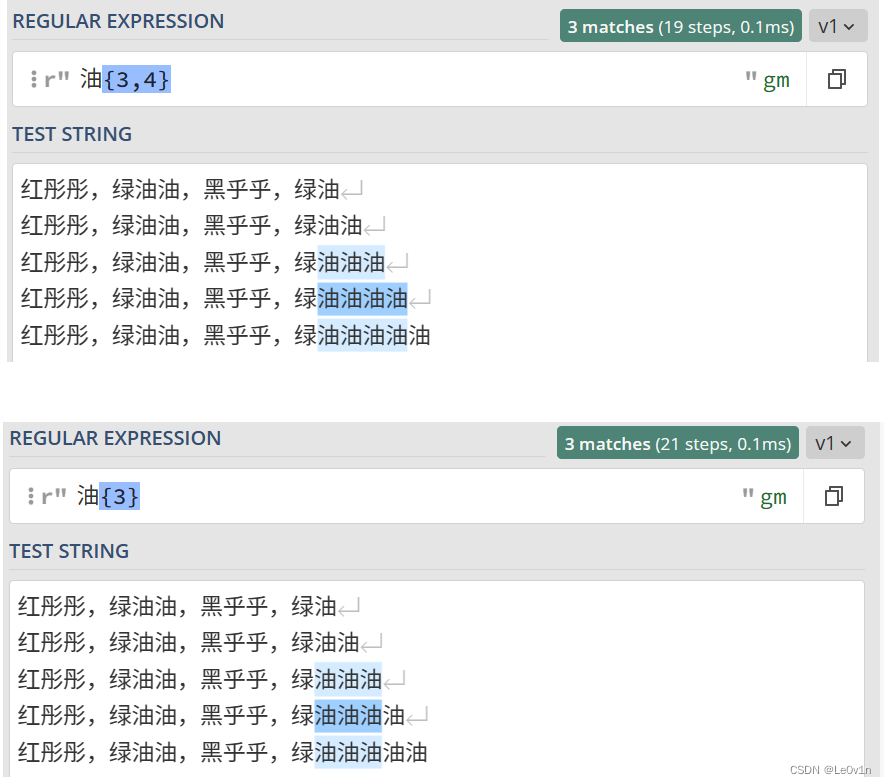
Fig.8 字符{int} 和字符{int,int} 的使用示例
4.2.6 特殊字符:\(转义字符)
反斜杠 \ 用作转义字符,它有两种作用:
- 用于转义紧跟其后的特殊字符,使其失去特殊含义,被当作普通字符对待。
- 用于创建一些特定的字符类,如换行符
\n、制表符\t等。
例如,如果我们想匹配一个实际的点 .,而不是作为通配符的点,我们需要在点前面加上反斜杠 \.。同样,如果我们想匹配一个实际的反斜杠 \,我们需要使用两个反斜杠 \\,因为在字符串中反斜杠本身也是一个转义字符。
我们的示例文本如下:
example.com
example.net
example.org
现在我们想要得到 . 后面的后缀以确定网页的类型(包括 . 本身),那么我们的 Regex 可以这样写:
\..*
我们验证一下,验证结果见 Fig.9。
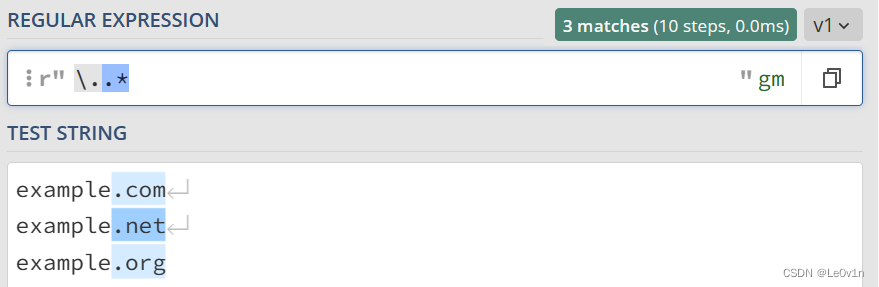
Fig.9 转义字符 \ 的使用示例
在这里,\. 表示 . 本身,它是一个普通字符而非特殊字符。.* 表示除了换行符外的所有字符。
我们也用 Python 进行一下验证:
import re
text = "这是一个例子:example.com"
pattern = r"example\.com"
match = re.search(pattern, text)
if match:
print(f"匹配结果:{match.group()}")
else:
print("没有匹配结果")
# 匹配包含反斜杠的文本
text_with_backslash = "路径:C:\\Program Files\\Example"
pattern_with_backslash = r"C:\\Program Files\\Example"
match_with_backslash = re.search(pattern_with_backslash, text_with_backslash)
if match_with_backslash:
print(f"匹配结果:{match\_with\_backslash.group()}")
else:
print("没有匹配结果")
匹配结果:example.com
匹配结果:C:\Program Files\Example
**Question**:为什么要加 r ?
**Answer**:在 Python 中,字符串前加上 r 或 R 表示这是一个原始字符串(raw string)。在原始字符串中,反斜杠 \ 不会被当作转义字符处理,而是保持其字面意义。这意味着在原始字符串中,反斜杠后面的字符不会被特殊解释。💡 如果我们不使用原始字符串,我们需要写四个反斜杠 \\\\ 来表示一个反斜杠 🤣。
4.2.7 特殊字符:[](匹配字符集中任意字符)
方括号 [] 用于创建一个字符集,匹配方括号内列出的任意一个字符。字符集可以包含普通字符和特殊字符,但特殊字符在字符集中将失去其特殊含义,被视为普通字符。
例如,字符集 [abc] 将匹配字母 a、b 或 c 中的任意一个。字符集也可以包含字符范围,如 [a-z] 将匹配从小写 a 到小写 z 的任意字母。
如果字符集的第一个字符是脱字符 ^,则表示取非,匹配任何不在方括号内的字符。例如,[^abc] 将匹配除了 a、b 和 c 之外的任意字符。
我们的示例文本如下:
abc def ghi jkl mno a b c d aa a a a a a a sdsad sajkjclkx jsadkl dskljnsdlijewqlkjsadj lasdjlkjdwijsalkj lksajd lkasjwd
- 现在我们想要得到字符 ace,那么我们的 Regex 可以这样写:
[ace]
- 如果我们不想要字符 ace,那么我们的 Regex 可以这样写:
[^ace]
- 如果我们想要字符 a 到 e 范围内的所有字符,那么我们的 Regex 可以这样写:
[a-e]
验证如 Fig.10 所示。
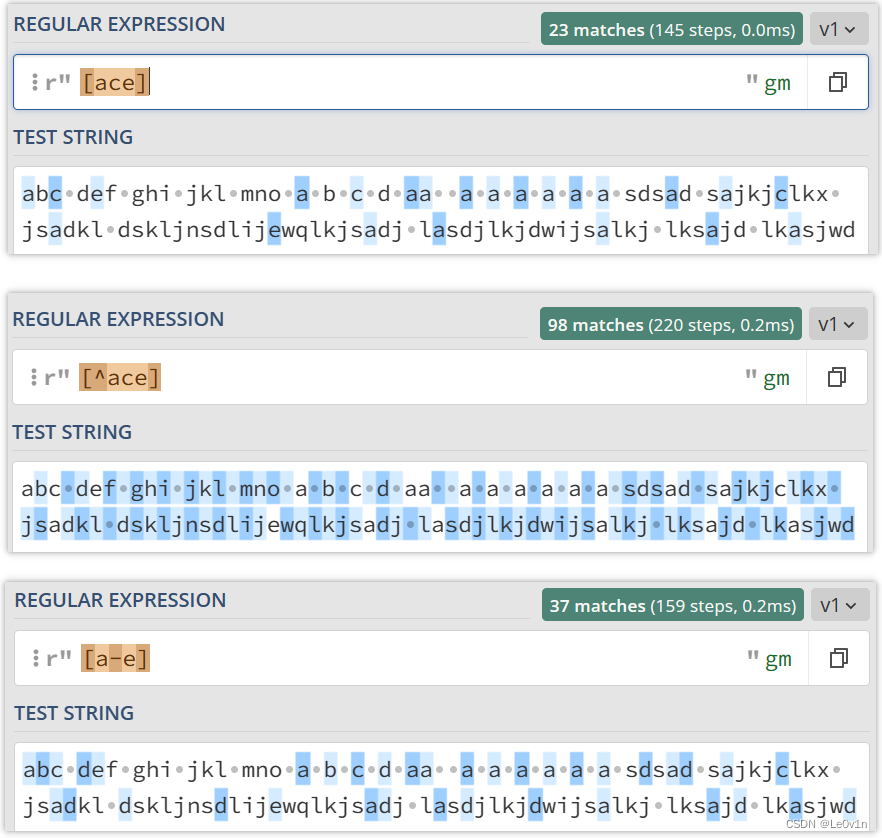
Fig.10 字符集的使用示例
可以看到,当我们不想要字符 ace 时([ace]),空格也被包围了,很合理。当 [a-e] 时,空格并没有被选中,也非常合理。
[] 的 Python 示例:
import re
# 匹配字符集内的任意字符
text = "abc def ghi jkl mno a b c d aa a a a a a a sdsad sajkjclkx jsadkl dskljnsdlijewqlkjsadj lasdjlkjdwijsalkj lksajd lkasjwd"
pattern = r"[ace]"
matches = re.findall(pattern, text)
print(f"匹配结果:{matches}")
# 匹配不在字符集内的任意字符
text = "abc def ghi jkl mno a b c d aa a a a a a a sdsad sajkjclkx jsadkl dskljnsdlijewqlkjsadj lasdjlkjdwijsalkj lksajd lkasjwd"
pattern = r"[^ace]"
matches = re.findall(pattern, text)
print(f"匹配结果:{matches}")
# 匹配字符范围
text = "abc def ghi jkl mno a b c d aa a a a a a a sdsad sajkjclkx jsadkl dskljnsdlijewqlkjsadj lasdjlkjdwijsalkj lksajd lkasjwd"
pattern = r"[a-e]"
matches = re.findall(pattern, text)
print(f"匹配结果:{matches}")
匹配结果:['a', 'c', 'e', 'a', 'c', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'c', 'a', 'e', 'a', 'a', 'a', 'a', 'a']
匹配结果:['b', ' ', 'd', 'f', ' ', 'g', 'h', 'i', ' ', 'j', 'k', 'l', ' ', 'm', 'n', 'o', ' ', ' ', 'b', ' ', ' ', 'd', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', 's', 'd', 's', 'd', ' ', 's', 'j', 'k', 'j', 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1611
1611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









