







从原数据集中取出一部分数据集放入train对应的类别中,一部分放入val对应的类别中。把原数据集中的test直接复制到test中。
_C.DATA.DATA_PATH = ‘dataset’
Dataset name
_C.DATA.DATASET = ‘imagenet’
Model name
_C.MODEL.NAME = ‘swin_tiny_patch4_window7_224’
Checkpoint to resume, could be overwritten by command line argument
_C.MODEL.RESUME =‘swin_tiny_patch4_window7_224.pth’
Number of classes, overwritten in data preparation
_C.MODEL.NUM_CLASSES = 2
对上面参数的解释:
_C.DATA.DATA_PATH :数据集路径的根目录,我定义为dataset。
_C.DATA.DATASET:数据集的类型,这里只有一种类型imagenet。
_C.MODEL.NAME:模型的名字,对应configs下面yaml的名字,会在模型输出的root目录创建对应MODEL.NAME的目录。
_C.MODEL.RESUME:预训练模型的目录。
_C.MODEL.NUM_CLASSES:模型的类别,默认是1000,按照数据集的类别数量修改。
将nb_classes =1000改为nb_classes = config.MODEL.NUM_CLASSES
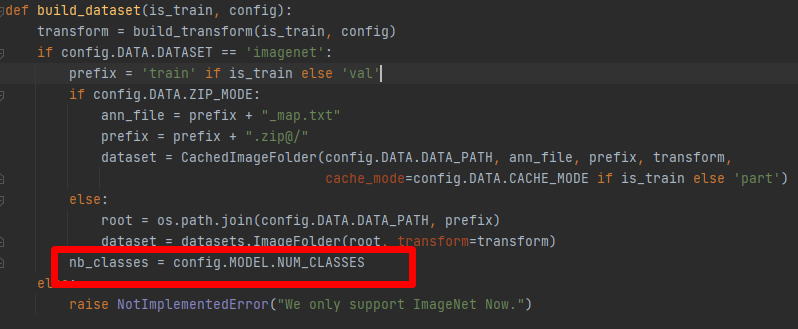
由于类别默认是1000,所以加载模型的时候会出现类别对不上的问题,所以需要修改load_checkpoint方法。在加载预训练模型之前增加修改预训练模型的方法:
if checkpoint[‘model’][‘head.weight’].shape[0] == 1000:
checkpoint[‘model’][‘head.weight’] = torch.nn.Parameter(
torch.nn.init.xavier_uniform(torch.empty(config.MODEL.NUM_CLASSES, 768)))
checkpoint[‘model’][‘head.bias’] = torch.nn.Parameter(torch.randn(config.MODELNUM_CLASSES))
msg = model.load_state_dict(checkpoint[‘model’], strict=False)
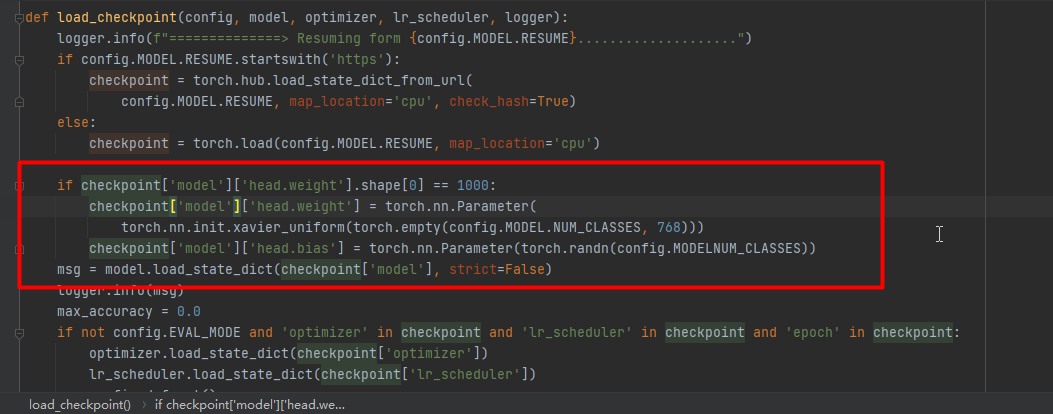
将92-94注释,如下图:
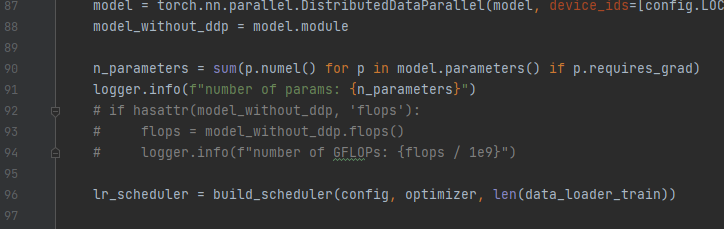
将312行修改为:torch.distributed.init_process_group(‘gloo’, init_method=‘file://tmp/somefile’, rank=0, world_size=1)
打开Terminal,运行如下命令:
python main.py --cfg configs/swin_tiny_patch4_window7_224.yaml --local_rank 0 --batch-size 16
如果想单独验证,运行命令:
python main.py --eval --cfg configs/swin_tiny_patch4_window7_224.yaml --resume ./output/swin_tiny_patch4_window7_224/default/ckpt_epoch_1.pth --data-path dataset --local_rank 0
=============================================================
这个项目没有推理脚本,我自己写了一个。写这部分需要看懂验证部分的代码即可。
import torch.utils.data.distributed
import torchvision.transforms as transforms
from PIL import Image
from torch.autograd import Variable
import os
from models import build_model
from config import get_config
import argparse
def parse_option():
parser = argparse.ArgumentParser(‘Swin Transformer Test script’, add_help=False)
parser.add_argument(‘–cfg’, default=‘configs/swin_tiny_patch4_window7_224.yaml’, type=str, metavar=“FILE”,
help=‘path to config file’, )
parser.add_argument(
“–opts”,
help="Modify config options by adding ‘KEY VALUE’ pairs. ",
default=None,
nargs=‘+’,
)
easy config modification
parser.add_argument(‘–batch-size’, type=int, help=“batch size for single GPU”)
parser.add_argument(‘–data-path’, type=str, help=‘path to dataset’)
parser.add_argument(‘–zip’, action=‘store_true’, help=‘use zipped dataset instead of folder dataset’)
parser.add_argument(‘–cache-mode’, type=str, default=‘part’, choices=[‘no’, ‘full’, ‘part’],
help='no: no cache, ’
'full: cache all data, ’
‘part: sharding the dataset into nonoverlapping pieces and only cache one piece’)
parser.add_argument(‘–resume’, default=‘output/swin_tiny_patch4_window7_224/default/ckpt_epoch_1.pth’,
help=‘resume from checkpoint’)
parser.add_argument(‘–accumulation-steps’, type=int, help=“gradient accumulation steps”)
parser.add_argument(‘–use-checkpoint’, action=‘store_true’,
help=“whether to use gradient checkpointing to save memory”)
parser.add_argument(‘–amp-opt-level’, type=str, default=‘O1’, choices=[‘O0’, ‘O1’, ‘O2’],
help=‘mixed precision opt level, if O0, no amp is used’)
parser.add_argument(‘–output’, default=‘output’, type=str, metavar=‘PATH’,
help=‘root of output folder, the full path is /<model_name>/ (default: output)’)
parser.add_argument(‘–tag’, help=‘tag of experiment’)
parser.add_argument(‘–eval’, action=‘store_true’, help=‘Perform evaluation only’)
parser.add_argument(‘–throughput’, action=‘store_true’, help=‘Test throughput only’)
parser.add_argument(“–local_rank”, default=‘0’, type=int, help=‘local rank for DistributedDataParallel’)
args, unparsed = parser.parse_known_args()
config = get_config(args)
return args, config
这个配置参数是为了创建模型,从main.py中复制过来,然后将required=True这样的字段删除。
定义class、创建transform
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
classes = (“cat”, “dog”)
将图像resize为224×224大小
定义类别,顺序和数据集对应。
DEVICE = torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)
_, config = parse_option()
model = build_model(config)
checkpoint = torch.load(‘output/swin_tiny_patch4_window7_224/default/ckpt_epoch_1.pth’, map_location=‘cpu’)
model.load_state_dict(checkpoint[‘model’], strict=False)
model.eval()
model.to(DEVICE)
判断gpu是否可用,如果不可以使用cpu。
获取config参数
创建模型
加载训练的模型权重
将权重放入model中。
定义测试集的路径,然后循环预测每张图片
path = ‘dataset/test/’
testList = os.listdir(path)
for file in testList:
img = Image.open(path + file)
img = transform_test(img)
img.unsqueeze_(0)
img = Variable(img).to(DEVICE)
out = model(img)
Predict
_, pred = torch.max(out.data, 1)
print(‘Image Name:{},predict:{}’.format(file, classes[pred.data.item()]))
结果如下:
import torch.utils.data.distributed
import torchvision.transforms as transforms
from PIL import Image
from torch.autograd import Variable
import os
from models import build_model
from config import get_config
import argparse
def parse_option():
parser = argparse.ArgumentParser(‘Swin Transformer Test script’, add_help=False)
parser.add_argument(‘–cfg’, default=‘configs/swin_tiny_patch4_window7_224.yaml’, type=str, metavar=“FILE”,
help=‘path to config file’, )
parser.add_argument(
“–opts”,
help="Modify config options by adding ‘KEY VALUE’ pairs. ",
default=None,
nargs=‘+’,
)
easy config modification
parser.add_argument(‘–batch-size’, type=int, help=“batch size for single GPU”)
parser.add_argument(‘–data-path’, type=str, help=‘path to dataset’)
parser.add_argument(‘–zip’, action=‘store_true’, help=‘use zipped dataset instead of folder dataset’)
parser.add_argument(‘–cache-mode’, type=str, default=‘part’, choices=[‘no’, ‘full’, ‘part’],
help='no: no cache, ’
'full: cache all data, ’
‘part: sharding the dataset into nonoverlapping pieces and only cache one piece’)
parser.add_argument(‘–resume’, default=‘output/swin_tiny_patch4_window7_224/default/ckpt_epoch_1.pth’,
help=‘resume from checkpoint’)
parser.add_argument(‘–accumulation-steps’, type=int, help=“gradient accumulation steps”)
parser.add_argument(‘–use-checkpoint’, action=‘store_true’,
help=“whether to use gradient checkpointing to save memory”)
parser.add_argument(‘–amp-opt-level’, type=str, default=‘O1’, choices=[‘O0’, ‘O1’, ‘O2’],
help=‘mixed precision opt level, if O0, no amp is used’)
parser.add_argument(‘–output’, default=‘output’, type=str, metavar=‘PATH’,
help=‘root of output folder, the full path is /<model_name>/ (default: output)’)
parser.add_argument(‘–tag’, help=‘tag of experiment’)
parser.add_argument(‘–eval’, action=‘store_true’, help=‘Perform evaluation only’)
parser.add_argument(‘–throughput’, action=‘store_true’, help=‘Test throughput only’)
parser.add_argument(“–local_rank”, default=‘0’, type=int, help=‘local rank for DistributedDataParallel’)
args, unparsed = parser.parse_known_args()
config = get_config(args)
return args, config
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
classes = (“cat”, “dog”)
DEVICE = torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)
_, config = parse_option()
model = build_model(config)
checkpoint = torch.load(‘output/swin_tiny_patch4_window7_224/default/ckpt_epoch_1.pth’, map_location=‘cpu’)
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。
三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。















 7756
7756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









