







sample(n):随机抽取 n 行显示
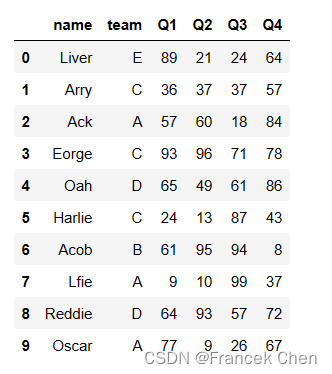
df.head(10)
(三)选择列
选择列的方法主要基于把 DataFrame 看成字典的观点。
1、选择单列
# 选择单列
# df['team']
df['team'].unique()
unique()方法:去掉重复值
array(['E', 'C', 'A', 'D', 'B'], dtype=object)
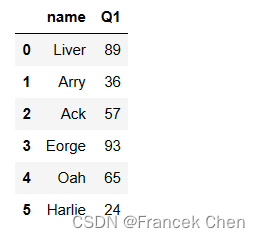
2、选择多列
# 选择多列
df[['name','Q1']].head(6)
(四)选择多行多列
1、使用位置索引器iloc
选择行的方法主要基于把 DataFrame 看成二维数组的观点。选择多行多列,使用位置索引器iloc,行列下标的位置上都允许切片和花式索引。
df.iloc[3:5,[0,2]]

为了使用标签索引,需要先判断name列的取值是否唯一。判断姓名是否有重名。
# df['name'].unique().shape
df['name'].unique().shape==df['name'].shape
True
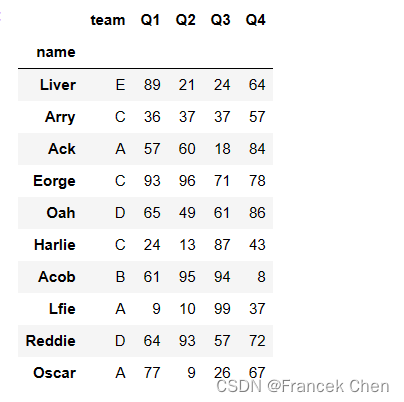
发现无重名,则可以把name作为行索引Index。
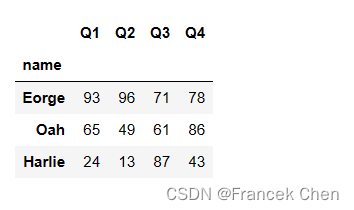
df.set_index('name',inplace=True)
df.head(10)
2、使用标签索引器loc
选择多行多列,使用标签索引器loc,行列下标的位置上都允许切片和花式索引。
df.loc['Eorge':'Harlie','Q1':'Q4']
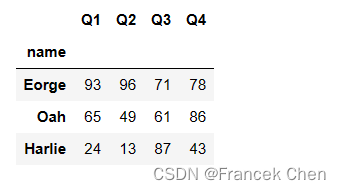
注意:使用切片时,位置索引不包含终值,而标签索引却包含终值。
3、使用ix索引器
也可以用ix索引器,混合使用位置和标签索引,但不建议这样做。
df.ix[3:5,'Q1':'Q4']
C:\Users\Administrator\Anaconda3\lib\site-packages\ipykernel_launcher.py:2: DeprecationWarning:
.ix is deprecated. Please use
.loc for label based indexing or
.iloc for positional indexing
See the documentation here:
http://pandas.pydata.org/pandas-docs/stable/indexing.html#ix-indexer-is-deprecated
二、带条件筛选
(一)startswith()方法
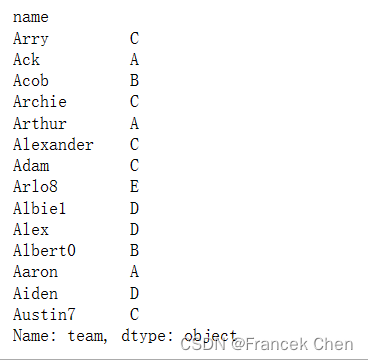
1、选择 DataFrame df中索引值以字母'A'开头的所有行,并选择'team'列:
# 带条件筛选
df.loc[df.index.str.startswith('A'),'team']
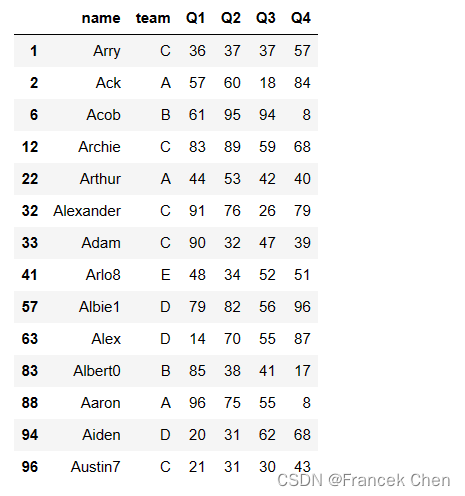
2、选择 DataFrame df中索引值以字母 ‘A’ 开头的所有行,并选择所有列:
# loc中使用函数筛选满足条件的行
df.loc[lambda x:x.name.str.startswith('A'),:]
将整个 DataFrame 对象作为实参传递给形参x,注意x的行索引是整数。
(二)mean()方法
比较 DataFrame 中列'Q1'的每个元素是否大于或等于'Q1'列的平均值:
df['Q1']>=df['Q1'].mean()
它的返回结果将是一个布尔类型的 Series,其中每个元素对应于相应的 ‘Q1’ 列元素是否大于或等于 ‘Q1’ 列的平均值。
0 True
1 False
2 True
3 True
4 True
5 False
6 True
7 False
8 True
9 True
10 False
11 False
12 True
13 True
14 True
15 False
16 True
17 True
18 True
19 True
20 True
21 True
22 False
23 True
24 True
25 True
26 True
27 True
28 True
29 False
...
70 True
71 True
72 False
73 False
74 True
75 True
76 True
77 True
78 False
79 True
80 True
81 False
82 False
83 True
84 True
85 False
86 False
87 False
88 True
89 False
90 False
91 True
92 True
93 False
94 False
95 False
96 False
97 True
98 False
99 False
Name: Q1, Length: 100, dtype: bool
(三)columns属性
获取 DataFrame 中倒数第四列及其后面的所有列的列名:
df.columns[-4:]
df.columns返回一个包含 DataFrame 中所有列名的 Index 对象。通过索引-4:,获取了倒数第四列及其后面的所有列的列名。
Index(['Q1', 'Q2', 'Q3', 'Q4'], dtype='object')
(四)apply()方法
使用apply()函数,它会对 DataFrame 的每一列应用指定的函数。
df1 = df.apply(lambda x: np.sum(x) if x.name.startswith('Q') else print(x.name)) #默认一次处理一列
df1
- 对于以 ‘Q’ 开头的列,
lambda x: np.sum(x)函数会计算该列的总和。 - 对于其他列,
print(x.name)函数会打印列的名称。
然而,需要注意的是,apply()函数返回的是一个 Series,其中包含每一列的处理结果。这意味着,对于那些不以 ‘Q’ 开头的列,由于print(x.name)函数没有返回值,因此相应位置的结果会是 NaN。另外,可能想要使用axis=0参数来指定apply()函数按列而不是按行进行操作。

(五)copy()方法
df2 = df.copy()
df2
首先通过df.copy()创建了 DataFrame df的副本df2。这样做是为了避免在对df2进行操作时影响到原始的 DataFrame df。
副本df2与原始的 DataFrame df具有相同的数据和结构,但它们是独立的对象,对其中一个对象的操作不会影响另一个对象。因此,通过这样的方式可以安全地对df2进行任何需要的修改或处理。

对 DataFrame df2中的每一行,从 ‘Q1’ 到 ‘Q4’ 列的值进行求和:
df2.apply(lambda x:sum(x['Q1':'Q4']),axis=1) # 一次处理一行
使用了apply()函数,对 DataFrame 中的每一行进行操作。
其中lambda x: sum(x['Q1':'Q4'])表示对每一行从 ‘Q1’ 到 ‘Q4’ 列进行求和操作。而axis=1参数指定了按行操作。
因此,该代码将会对 DataFrame df2中的每一行,从 ‘Q1’ 到 ‘Q4’ 列的值进行求和,并返回一个包含每一行求和结果的 Series。
name
Liver 198
Arry 167
Ack 219
Eorge 338
Oah 261
Harlie 167
Acob 258
Lfie 155
Reddie 286
Oscar 179
Leo 133
Logan 198
Archie 299
Theo 251
Thomas 225
James 188
Joshua 177
Henry 198
William 177
Max 216
Lucas 240
Ethan 301
Arthur 179
Mason 251
Isaac 190
Harrison 195
Teddy 231
Finley 287
Daniel 233
Riley 203
...
Nathan 239
Blake 203
Luke6 306
Elliot 130
Roman 143
Stanley 276
Dexter 240
Michael 261
Elliott 133
Tyler 198
Ryan 257
Ellis 187
Finn 92
Albert0 181
Kai 172
Liam 131
Calum 203
Louis2 180
Aaron 234
Ezra 219
Leon 136
Connor 209
Grayson7 250
Jamie0 275
Aiden 181
Gabriel 268
Austin7 125
Lincoln4 212
Eli 234
Ben 179
Length: 100, dtype: int64
(六)groupby()方法
1、将 DataFrame 按照'team'列进行分组,并对每个分组应用了一个函数:
df.groupby('team').apply(lambda x :print(x))
这段代码使用了groupby()函数将 DataFrame 按照'team'列进行分组,并对每个分组应用了一个函数。
在这个例子中,使用了一个lambda函数,它接受每个分组作为输入,并将其打印出来。print(x)语句会打印每个分组的内容。
请注意,这段代码在每个分组中都会打印出该分组的内容,而不会返回任何值。
team Q1 Q2 Q3 Q4
name
Ack A 57 60 18 84
Lfie A 9 10 99 37
Oscar A 77 9 26 67
Joshua A 63 4 80 30
Henry A 91 15 75 17
Lucas A 60 41 77 62
Arthur A 44 53 42 40
Reggie1 A 30 12 23 9
Toby A 52 27 17 68
Dylan A 86 87 65 20
Hugo0 A 28 25 14 71
Caleb A 64 34 46 88
Nathan A 87 77 62 13
Blake A 78 23 93 9
Stanley A 69 71 39 97
**自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
**深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。**






**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注:Python)**
1713725433373)]
[外链图片转存中...(img-Cir7II9B-1713725433374)]
[外链图片转存中...(img-mu9qDzUb-1713725433374)]


**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注:Python)**















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









