







========
JVM优化首先需要选择目标。在下一步为GC调优准备系统时围绕着这些目标设置值。可参考的目标选择方向:
-
延迟——JVM在执行垃圾收集时引起的Stop The World(STW)。有两个主要的指标,平均GC延迟和最大GC延迟。这个目标的动机通常与客户感知到的性能或响应能力有关。
-
吞吐量——JVM可用于执行应用程序的时间百分比。可用来执行应用程序的时间越多,可用来服务请求的处理时间就越多。需要注意的是,高吞吐量和低延迟并不一定相关——高吞吐量可能伴随着较长但不频繁的暂停时间。
-
内存成本——内存占用是JVM为执行应用程序所消耗的内存量。如果应用程序环境内存有限,将此项设为目标也可以起到降低成本的作用。
以上内容可以在Java官方手册的HotSpot调优部分找到,而一些经验性的优化原则如下:
-
优先考虑MinorGC。在大多数应用程序中,大多数垃圾都是由最近短暂的对象分配创建的,所以优先考虑年轻代的GC。年轻代对象生命周期越短,不会因为动态年龄判断和空间分配担保等因素导致存活时间不长的对象被分配到老年代;同时老年代对象生命周期长,JVM的整体垃圾收集就越高效,这将导致更高的吞吐量。
-
设定合适的堆区大小。给JVM的内存越多,收集频率就越低。此外,这还意味着可以适当地调整年轻代的大小,以更好地应对短期对象的创建速度,这就减少了向老年代分配的对象数量。
-
设定简单的目标。为了使事情变得更容易,把JVM调优的目标设定的简单一点,例如只选择其中两个性能目标进行调整,而牺牲另一个甚至只选择一个。通常情况下,这些目标是相互竞争的,例如,为了提高吞吐量,你给堆的内存越多,平均暂停时间就可能越长;反之,如果你给堆的内存越少,从而减少了平均暂停时间,暂停频率就可能增加,降低吞吐量。同样,对于堆的大小,如果所有分代区域的大小合适则可以提供更好的延迟和吞吐量,这通常是以牺牲JVM的占用率为代价的。
简而言之,调整GC是一种平衡的行为。通常无法仅仅通过GC的调整来实现所有的目标。
Typical Distribution for Lifetimes of Objects 。 图不重要,看文本~
3.业务逻辑分析
========
这里并不会把真实的业务系统拿出来进行分析,而是模拟类似的场景,大致的业务信息如下:
-
一个微服务系统(本例中是一个SpringBoot Demo,以下简称D服务)主要提供书籍实体信息的缓存和搜索业务
-
底层数据库为MySQL+Redis+Elasticsearch
-
业务场景为向其他微服务模块或者其他部分提供高速缓存及书籍信息检索
-
实际实现需求时采用MySQL+Redis+应用内存式多级缓存
从D服务的性质来说并不属于用户强交互类型的后端服务,主要面向的部门内的其他微服务和其他部门的后端服务,所以对于请求的响应速度(延迟)并不属于第一目标,所以可以把主要的调优目标设定为增加吞吐量或者降低内存占用。当然由于服务本身并不算臃肿,生产资源也不是很吃紧,所以也不考虑降低内存,则最后的目标为增加吞吐量。
从业务逻辑的角度分析主要是对书籍信息的增删改查,请求流量中90%以上是查,增删改则大多是服务内部对于多方数据的维护。
查询的类型分为多种,从对象的角度来说大多数是短期对象,例如:
-
通过AdvanceSearch(AS)模块生成的复杂ES查询语句对象(数据量小,频率中等,存活时间极短)
-
从多方数据源整合业务逻辑的数据响应对象(数据量中,频率极高,存活时间极短)
-
多级缓存体系中在内存中暂存的数据对象(数据量小,频率高,存活时间中等,因为是LRU缓存)
-
定期维护任务处理分发的数据对象(数据量大、频率低、存活时间极短)
可能会进入老年代的业务对象只有内存缓存中的对象,这一块结合业务量+过期时间常时保持在数百MB以内,这里的大小是多次压测中Dump堆内存+MAT分析得出的结果。
统合以上所有信息可以看出这是一个大部分对象存活时间都不会太长的应用,所以初步的想法是增大年轻代的大小,让大部分对象都在年轻代被回收,减少进入老年代的几率。
下面贴出Demo的代码,为了模拟一个类似的情况可能Demo中的代码采用了一些取巧或者极端的设定,或许这也不能很好的表达原本的逻辑,但一个40行不到就可以运行的Demo总比一个复杂的项目或者开源软件容易理解
复制代码12345678910111213141516171819202122232425262728293031323334353637383940414243444546JAVA/**
-
@author fengxiao
-
@date 2021-11-09
*/
@RestController
@SpringBootApplication
public class Application {
private final Logger logger = LoggerFactory.getLogger(Application.class);
//1. 模拟内存缓存, 短期对象
private Cache<Integer, Book> shortCache;
//2. 模拟业务流程里 中等存活时长 对象,,从而使短期对象更有可能进入老年代
private Cache<Integer, Book> mediumCache;
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@PostConstruct
public void init() {
//3. 这里本地缓存的数值设定在实际业务中并不具有参考性,只是设法让一部分对象在初始的设定下进入老年代
shortCache = Caffeine.newBuilder().maximumSize(800).initialCapacity(800)
.expireAfterWrite(3, TimeUnit.SECONDS)
.removalListener((k, v, c) -> logger.info(“Cache Removed,K:{}, V:{}, Cause:{}”, k, v, c))
.build();
mediumCache = Caffeine.newBuilder().maximumSize(1000).softValues()
.expireAfterWrite(30, TimeUnit.SECONDS)
.build();
}
@GetMapping(“/book”)
public Book book() {
//4. 模拟业务处理流程中其他模块短期对象生成的消耗,可以调整这个参数来对老年代无干扰的增加YoungGC的频率
// byte[] bytes = new byte[16 * 1024];
return shortCache.get(new Random().nextInt(5000), (id) -> {
//5. 模拟正常的LRU缓存场景消耗
Book book = new Book().setId(id).setArchives(new byte[256 * 1024]);
//6. 模拟业务系统中对老年代的正常消耗
mediumCache.put(id, new Book().setArchives(new byte[128 * 1024]));
return book;
}
);
}
}
4.准备调优环境
========
一旦确定了方向,就需要为GC调优准备环境。这一步的结果将是你所选择目标的价值。总之,目标和价值将成为要调优的环境的系统需求。
4.1 容器镜像选择
==========
其实就是选择JDK的版本,不同版本的JDK可选择的收集器组合不尽相同,而根据业务类型选择收集器也是至关重要的。
因为在日常工作中使用的JDK版本还是1.8,结合上面谈到的吞吐量目标自然就选择了PS/PO(也是JDK1.8服务端默认收集器),关于收集器的特性和组合在这里不做展开,有需要自行查阅书籍和文档。
4.2 启动/预热工作负载
=============
在测量特定应用程序JVM的GC性能之前,需要能够让应用程序执行工作并达到稳定状态。这是通过将load应用到应用程序来实现的。
建议将负载建模为希望调优GC的稳定状态负载,即反映应用程序在生产环境中使用时的使用模式和使用量的负载。这里可以拉上测试部门的同事一起完成,通过压测、流量回放等手段让目标程序接近于真实生产中的状态,同时需要注意的是类似的硬件、操作系统版本、加载配置文件等等。负载环境、配额可以通过容器化很方便的实现。
Demo这里以MeterSphere来模拟压力。简单的一点也可以用Jmeter快速启动或者直接录制真实的流量进行回放。
4.3 开启GC日志/监控
=============
这一点相信大部分生产上的系统都是默认开启的,如果是JDK9以下则:
复制代码1SHELLJAVA_OPT=“ J A V A O P T − X l o g g c : {JAVA_OPT} -Xloggc: JAVAOPT−Xloggc:{BASE_DIR}/logs/server_gc.log -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M”
JDK9则整合在了xlog参数中:
复制代码1SHELL-Xlog:gc*:file=${BASE_DIR}/logs/server_gc.log:time,tags:filecount=10,filesize=102400"
然后就需要理解GC日志的各种字段信息含义了,这里建议多观察自己系统中的GC日志,理解日志含义。
至于监控的话可以接入类似Prometheus+Grafana这样的监控系统,监控+报警,谁也不想天天盯着GC日志看。所以此处为了方便展示结果临时搭建了一个Prometheus+Grafana监控,Elasticsearch+Kibana用来分析GC日志。用最小的配置启动Grafana:
复制代码1234567891011121314151617YAMLversion: ‘3.1’
services:
prometheus:
image: prom/prometheus
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- 9090:9090
container_name: prometheus
grafana:
image: grafana/grafana
depends_on:
- prometheus
ports:
- 3000:3000
container_name: grafana
对Prometheus和Grafana做一些基本的配置后随意导入一个JVM相关的监控面板即可:
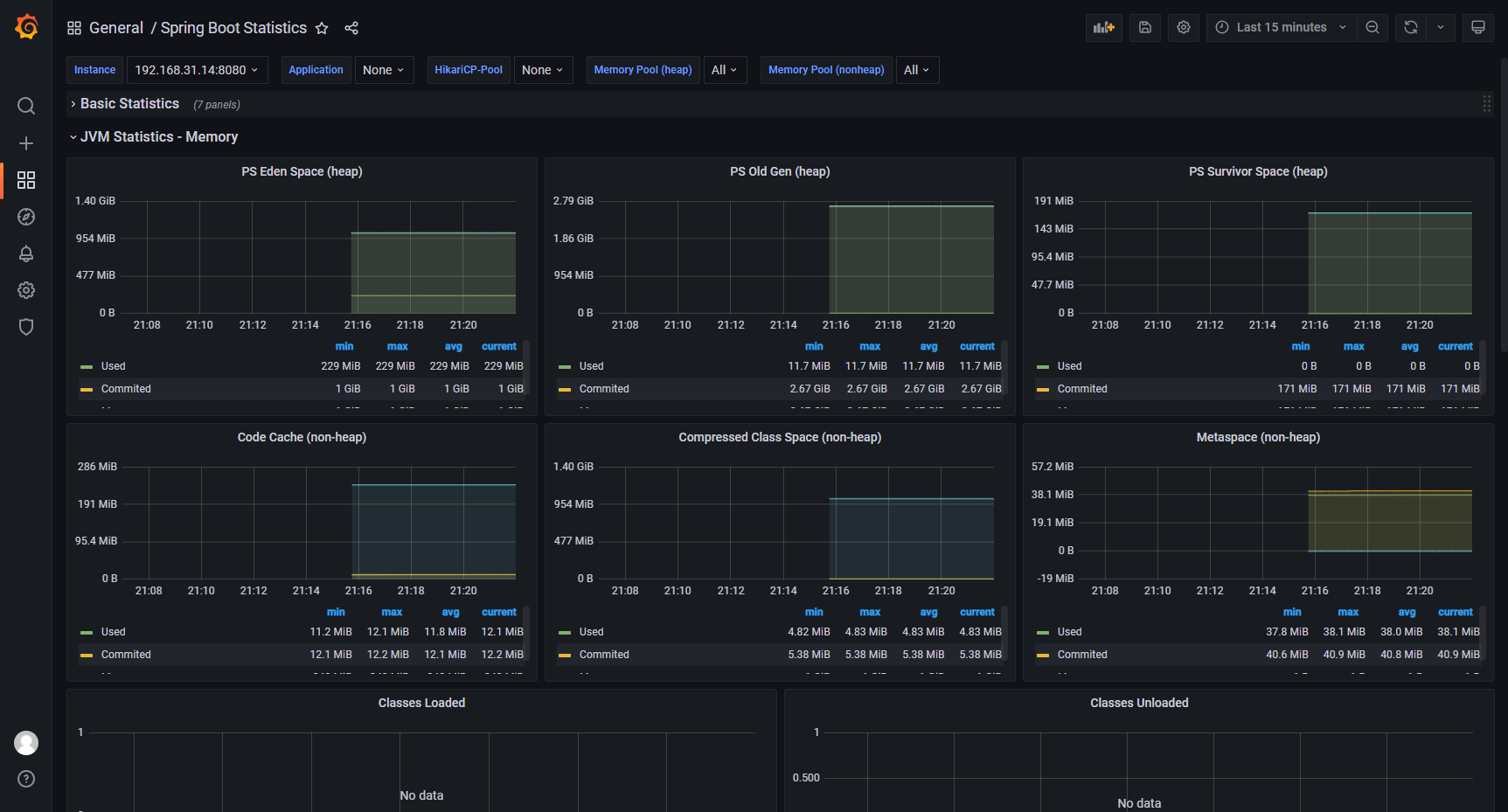
4.4 确定内存足迹
==========
内存足迹是指程序在运行时使用或引用的主内存的数量(Wiki传送门:Memory footprint,以下以内存占用这个通俗的理解作为简称)
为了优化JVM分代的大小,需要很好地了解稳定状态活动数据集的大小,可以通过以下两种方式获得相关信息:
-
从GC日志观察
-
从可视化监控中观察(直观)
5. 确定系统需求
==========
回到性能目标,我们讨论了VM GC调优的三个性能目标。现在需要确定这些目标的值,它们表示你正在调优GC性能的环境的系统需求。需要确定的一些系统要求是:
-
可接受的平均Minor GC暂停时间
-
可接受的平均GC暂停时间
-
最大可容忍的Full GC暂停时间
-
可用时间百分比表示的可接受的最小吞吐量
通常,如果关注的是Latency(延迟)或Footprint(内存占用)目标,那么可能倾向于较小的堆内存值,并使用较小的吞吐量值设置暂停时间的最大容限;相反,如果您关注的是吞吐量,那么您可能会希望在没有最大容差的情况下使用更大的暂停时间值和更大的吞吐量值。
这部分最好结合自己当前负责业务系统的现状进行评估和拟定,在一个基准值上进行调优。以D服务的原始吞吐量举例(实际的业务系统中各种复杂的情况都要细致考虑):
系统要求 | 值 |
可接受的Minor GC暂停时间: | 0.2秒 |
可接受的Full GC暂停时间: | 2秒 |
可接受的最低吞吐量: | 95% |
这一步可以多理解Java官方文档中的 Behavior-Based Tuning ,以及一些现成的JVM调优案例,重要的是理解思想然后结合自己的业务来确定需求。
6. 设定样本参数开始压测
==============
以下为本例中D服务的基准运行参数
复制代码12345678910111213SHELLjava -Xms4g -Xmx4g
-XX:-OmitStackTraceInFastThrow
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=logs/java_heapdump.hprof
-Xloggc:logs/server_gc.log
-verbose:gc
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=10
-XX:GCLogFileSize=100M
-jar spring-lite-1.0.0.jar
此时使用jmap命令分析堆区情况如下,程序是跑在虚拟机里的,因为调试参数的时候发现有些情况下会频繁GC所以只分配了4个逻辑处理器:
复制代码123456789101112131415161718192021222324252627282930313233343536373839404142434445SHELLDebugger attached successfully.
Server compiler detected.
JVM version is 25.40-b25
using thread-local object allocation.
Parallel GC with 4 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 4294967296 (4096.0MB)
NewSize = 1431306240 (1365.0MB)
MaxNewSize = 1431306240 (1365.0MB)
OldSize = 2863661056 (2731.0MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 1073741824 (1024.0MB)
used = 257701336 (245.76314544677734MB)
free = 816040488 (778.2368545532227MB)
24.00030717253685% used
From Space:
capacity = 178782208 (170.5MB)
used = 0 (0.0MB)
free = 178782208 (170.5MB)
0.0% used
To Space:
capacity = 178782208 (170.5MB)
used = 0 (0.0MB)
free = 178782208 (170.5MB)
0.0% used
PS Old Generation
capacity = 2863661056 (2731.0MB)
used = 12164632 (11.601097106933594MB)
free = 2851496424 (2719.3989028930664MB)
0.42479301014037324% used
14856 interned Strings occupying 1288376 bytes.
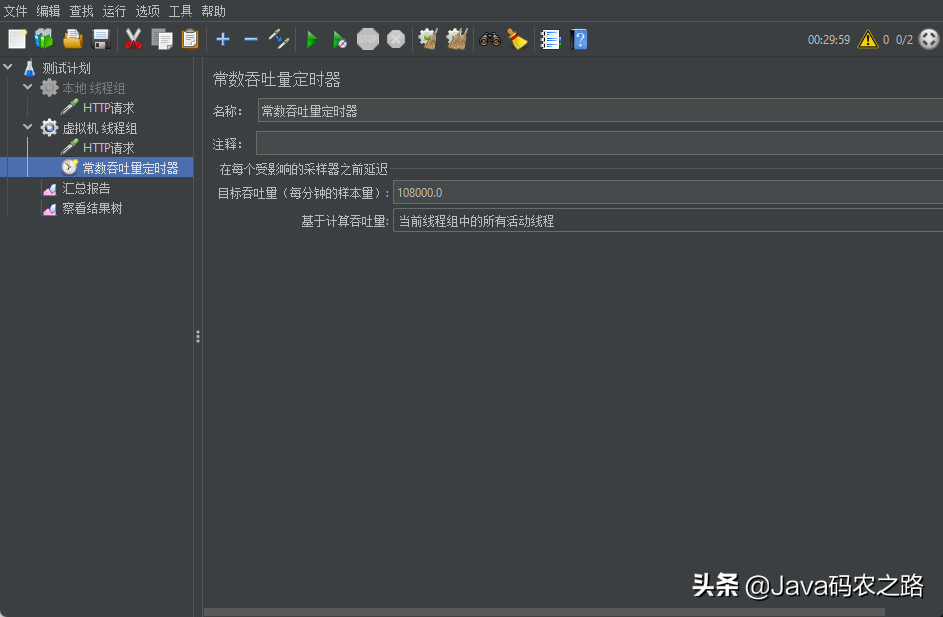
Jmeter请求设置如下,因为Demo的流程里没有任何业务逻辑所以即使单线程都有较高的吞吐量,但要注意测试环境配置的区别,例如我在IDE中直接使用Jmeter单线程吞吐量就可以达到1800/s,而到了一个配置较低的虚拟机中需要多个线程才能达到相似的吞吐量级,所以可以加几个线程同时用吞吐量定时器控制请求速率:
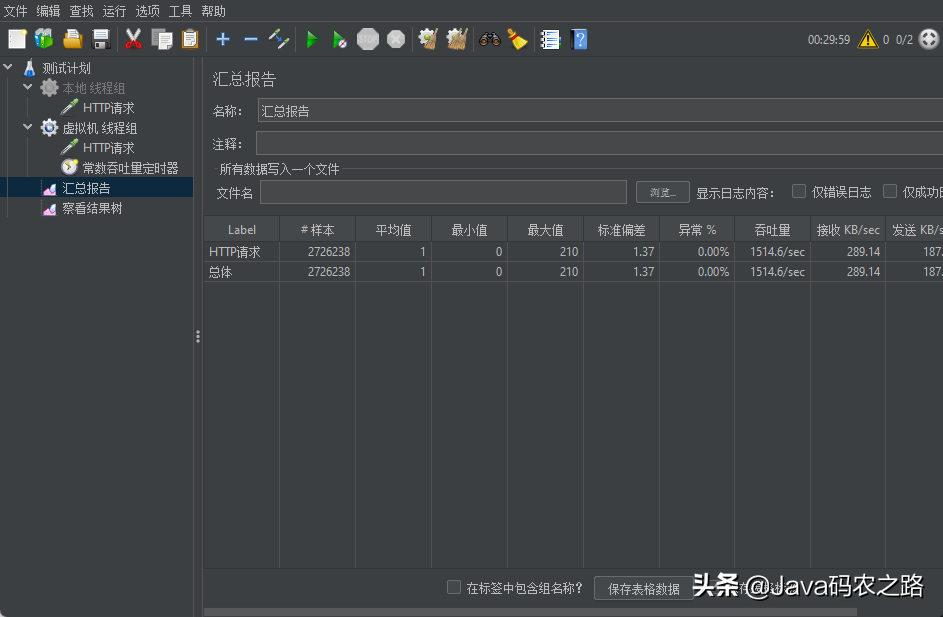
每次调整参数反复的进行请求,每次半个小时。这是对于Demo的,如果时真实的业务系统务必多花时间采样
7.分析GC日志
========
对于本例中的Demo取了四种参数下的GC日志结果,Grafana概览如下:
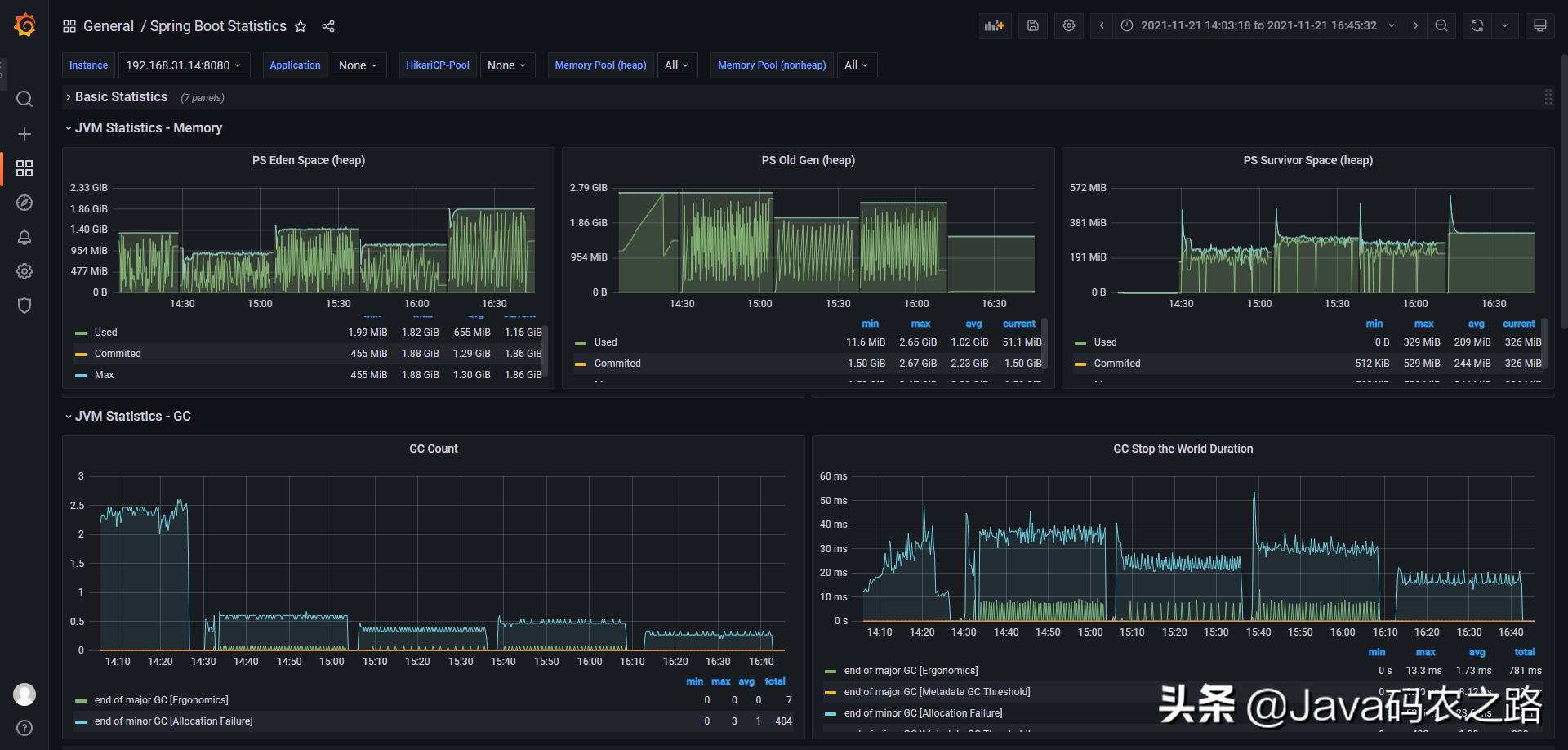
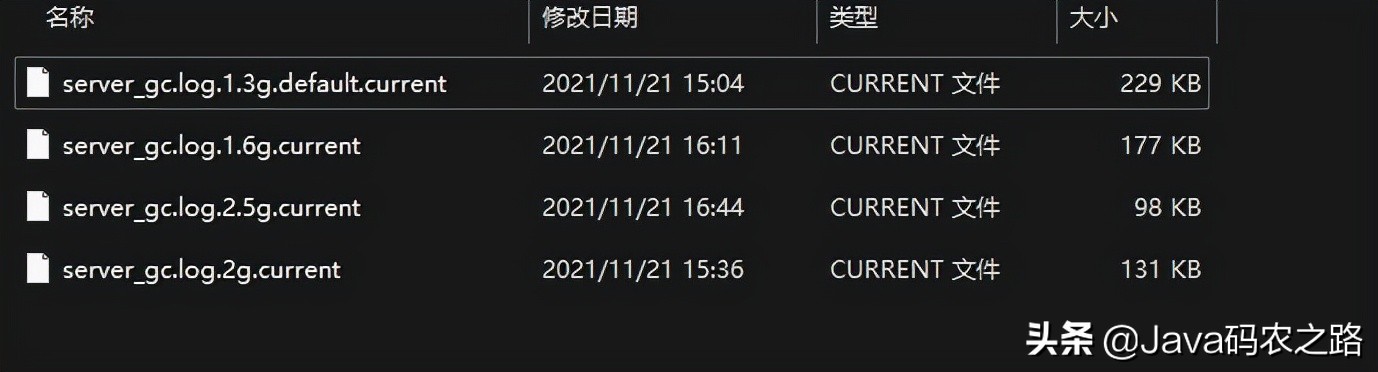
最终产生了四个GC日志样本,文件名里的内存大小是指年轻代的大小,对于生产服务可以从多个角度采集更多参数样本:
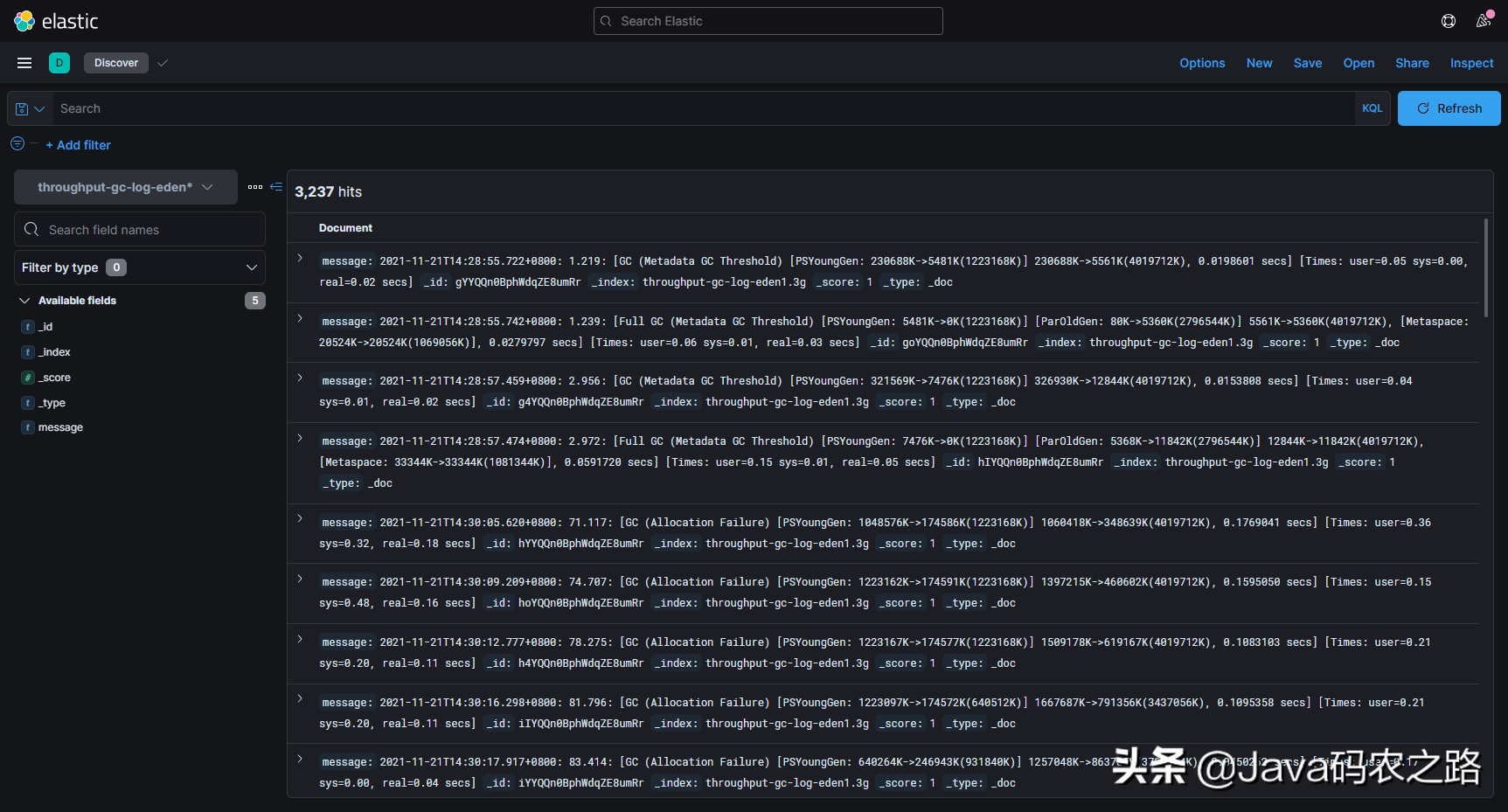
7.1 导入Elasticsearch
===================
接下来我们将GC日志导入到Elasticsearch中,并来到Kibana查看(注意这里的Elasticsearch和Kibana必需是7.14版本以上的,否则后续的操作会因为版本原因无法完成):
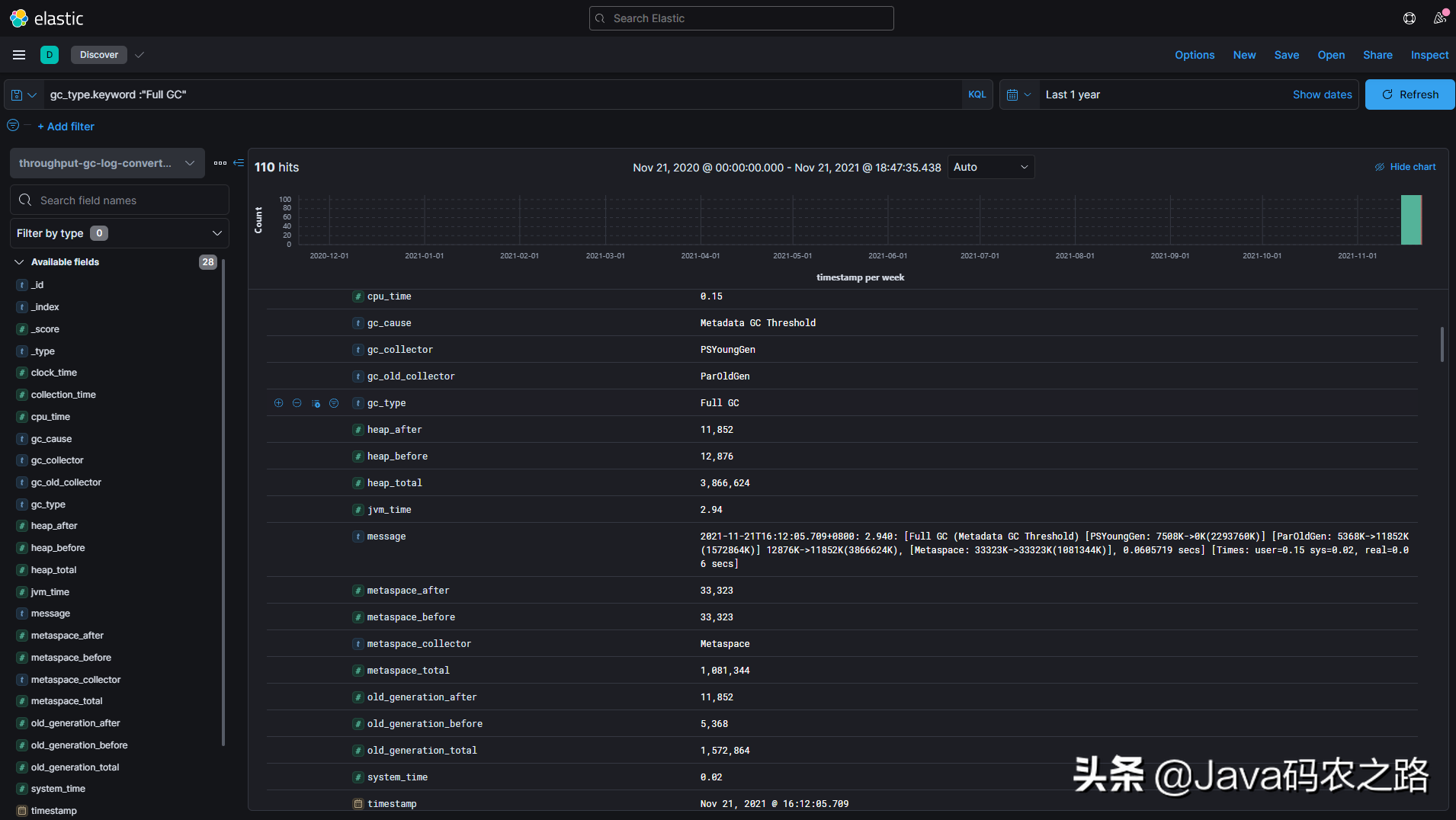
此时索引中的GC还是原始格式,就像是在Linux中直接打开一样,所以我们需要通过Grok Pattern将日志拆分成各个关键字段。实际开发场景可以用Logstash解析并传输,这里只是做个演示,所以通过IngestPipeline + Reindex 快速处理索引数据。
成功后索引如下所示,我们拥有了可以制作可视化面板的结构化GC数据(Grok Pattern这里就不分享了,主要是我花了半个小时写出来的表达式似乎还不能完美匹配一些特殊的GC日志行= =。也是建议大家自己编写匹配表达式,这样可以细致的消化GC日志的结构)
7.2 制作可视化面板
===========
现在通过聚合找到每个日志索引对应的开始时间以及结束时间
复制代码123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354JSONGET throughput-gc-log-converted*/_search
{
“size”: 0,
“aggs”: {
“index”: {
“terms”: { “field”: “_index”, “size”: 10 },
“aggs”: {
“start_time”: {
“min”: { “field”: “timestamp” }
},
“stop_time”: {
“max”: { “field”: “timestamp” }
}
}
}
}
}
// 响应如下:
“aggregations” : {
“index” : {
“doc_count_error_upper_bound” : 0,
“sum_other_doc_count” : 0,
“buckets” : [
{
“key” : “throughput-gc-log-converted-eden1.3g”,
“doc_count” : 1165,
“start_time” : { “value” : 1.637476135722E12, “value_as_string” : “2021-11-21T06:28:55.722Z”
},
“stop_time” : { “value” : 1.637478206592E12, “value_as_string” : “2021-11-21T07:03:26.592Z” }
},
{
“key” : “throughput-gc-log-converted-eden1.6g”,
“doc_count” : 898,
“start_time” : { “value” : 1.637480290228E12, “value_as_string” : “2021-11-21T07:38:10.228Z”
},
“stop_time” : { “value” : 1.637482100695E12, “value_as_string” : “2021-11-21T08:08:20.695Z” }
},
{
“key” : “throughput-gc-log-converted-eden2.0g”,
“doc_count” : 669,
“start_time” : { “value” : 1.63747831467E12, “value_as_string” : “2021-11-21T07:05:14.670Z”
},
“stop_time” : { “value” : 1.637480148437E12, “value_as_string” : “2021-11-21T07:35:48.437Z” }
},
{
“key” : “throughput-gc-log-converted-eden2.5g”,
“doc_count” : 505,
“start_time” : { “value” : 1.637482323999E12, “value_as_string” : “2021-11-21T08:12:03.999Z”
},
“stop_time” : { “value” : 1.637484145358E12, “value_as_string” : “2021-11-21T08:42:25.358Z” }
}
]
}
}
确定了时间范围之后进入Dashboard页面,创建可视化面板如下。之所以需要精确的时间范围,就是需要精确的偏移时间以对比不同情况下GC的表现,现在我们可以观察不同设置下的GC次数和GC耗时,另外和同事分享或者向领导汇报调优结果时有现成的图标总比一堆数据好用吧~
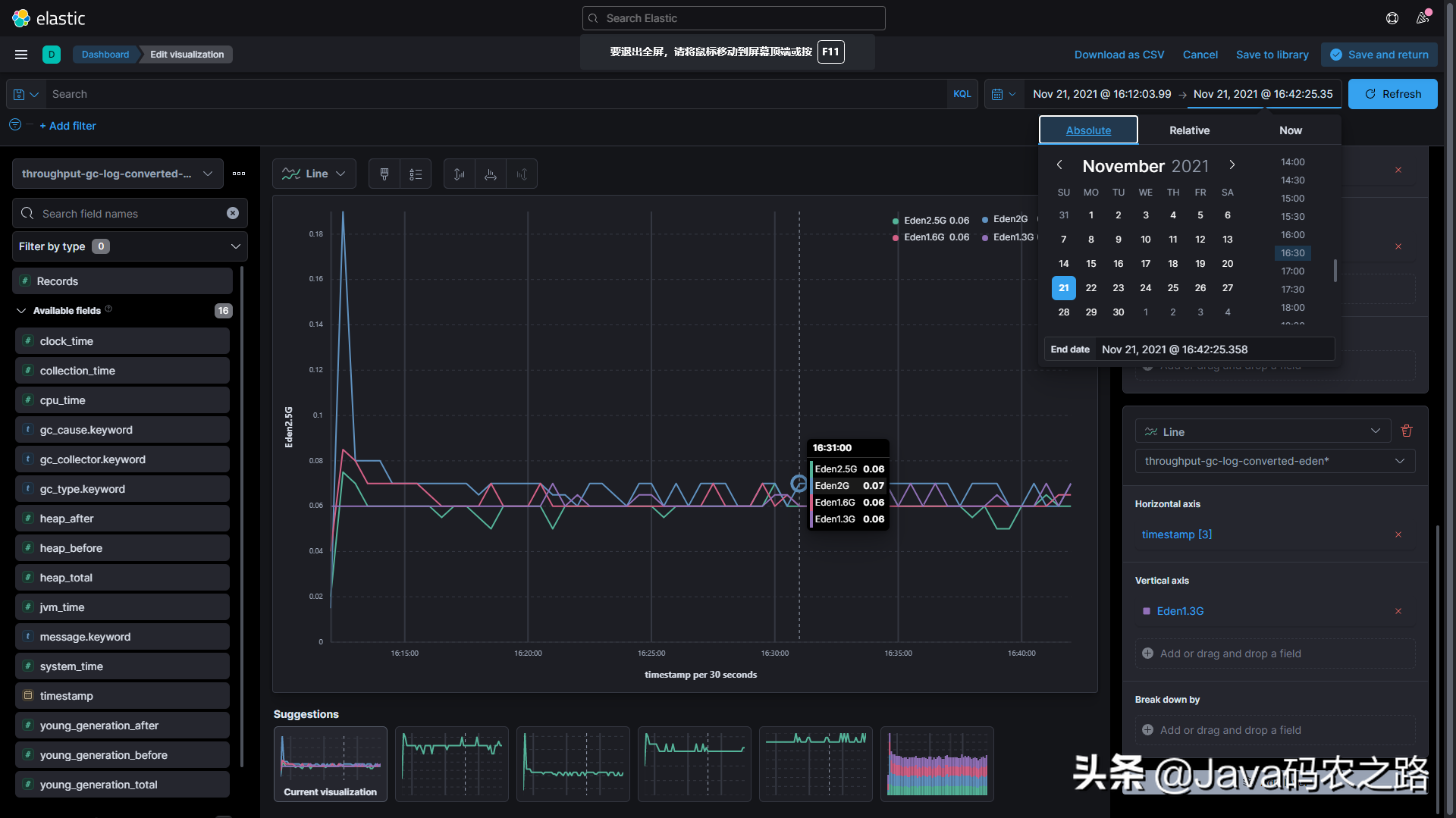
7.3 获得性能指标
==========
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

最后
分享一些系统的面试题,大家可以拿去刷一刷,准备面试涨薪。
这些面试题相对应的技术点:
- JVM
- MySQL
- Mybatis
- MongoDB
- Redis
- Spring
- Spring boot
- Spring cloud
- Kafka
- RabbitMQ
- Nginx
- …
大类就是:
- Java基础
- 数据结构与算法
- 并发编程
- 数据库
- 设计模式
- 微服务
- 消息中间件









《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
大家可以拿去刷一刷,准备面试涨薪。
这些面试题相对应的技术点:
- JVM
- MySQL
- Mybatis
- MongoDB
- Redis
- Spring
- Spring boot
- Spring cloud
- Kafka
- RabbitMQ
- Nginx
- …
大类就是:
- Java基础
- 数据结构与算法
- 并发编程
- 数据库
- 设计模式
- 微服务
- 消息中间件
[外链图片转存中…(img-jaXKOVJv-1713757516457)]
[外链图片转存中…(img-JsSmFKqg-1713757516458)]
[外链图片转存中…(img-K2MUMrHV-1713757516458)]
[外链图片转存中…(img-0H0AuNqV-1713757516458)]
[外链图片转存中…(img-Qxo1GtZS-1713757516458)]
[外链图片转存中…(img-ONIYAzJu-1713757516459)]
[外链图片转存中…(img-0e7VtT91-1713757516459)]
[外链图片转存中…(img-KQSO3Goe-1713757516459)]
[外链图片转存中…(img-lAyyVST8-1713757516459)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 503
503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









