






近年来,深度学习领域的迅速进步对蛋白质设计产生了显著影响。最近,深度学习方法在蛋白质结构预测方面取得了重大突破,使我们能够得到数百万种蛋白质的高质量模型。结合用于生成建模和序列分析的新型架构,这些方法在过去几年里极大改变了蛋白质设计领域,提高了识别新蛋白质序列和结构的准确性和能力。深度神经网络现在能够学习和提取蛋白质结构的基本特征,预测它们与其他生物分子的相互作用,并且有潜力创造用于治疗疾病的新型药物。
从零基础开始学习,对 Python 编程基础、Linux 常用命令和 Machine Learning/Deep Learnings 领域相关算法进行详细讲解,并结合当前蛋白质设计方面的论文文献讲解相关技术的应用。主要介绍蛋白质设计的底层逻辑与基本规则,学习蛋白质结构预测、蛋白质序列设计、蛋白质-蛋白质相互作用分析、以及蛋白质功能注释和优化方法,掌握深度学习在蛋白质设计中的常见算法以及实际方法,培养学生具备基本的深度学习蛋白质设计能力和蛋白质人工智能应用的前沿视野,为参与解决生物医学、生物工程和生物能源等方面的重大问题提供更多机会。
内容主要分为三个方面:
(1)结构到序列的预测基础:基于结构的蛋白质设计是蛋白质结构预测的
逆过程。学生将学会通过生物信息学工具分析蛋白质序列,预测其二级结构和三维结构,并初步理解结构与功能之间的关联。
(2)ML/DL 算法模型应用与评估:深度学习可以用于预测蛋白质序列的
功能和稳定性。学生将能够使用机器学习或深度学习算法模型进行蛋白质特定功能和序列稳定性预测,同时学习如何评估模型的准确性和可靠性。
(3)蛋白质设计应用实践:深度学习通过预测蛋白质-蛋白质之间的相互作
用、蛋白质的功能以及生物属性为生物制药、生物医学等方面提供了新的方向。学生将通过以上学习的与蛋白质序列、结构和功能预测相关的原理,学会设计新的蛋白质复合物和抗体,识别蛋白质的功能域、结构域和功能位点等,通过神经网络和生成对抗网络的应用,优化和筛选符合特定要求的蛋白质。
第一天 Python 编程基础知识
1. Python 基础
1.1 Python 简介:了解 Python 的发展历史、特点、现状,以及与其他编程语
言的比较。
1.2 安装和设置 Python 环境:安装 Python3 ,设置 开 发 环 境 ( 如
Anaconda(miniconda)、Jupyter notebook)并运行第一个 Python 程序。
1.3 Python 变量和数据类型:数据类型(整数、浮点数、字符串、布尔值)、
表定制等。
4. 数据分析与可视化
4.1 Pandas:使用 Pandas 进行高级的数据分析操作,包括如何去做数据清洗、
预处理和排序等数学计算,数据的分箱技术,分组技术,聚合技术,以及透视表
等。
4.2 数据可视化:介绍 Seaborn 的基本使用,以及和 Matplotlib 的功能对比,
使用 Matplotlib 和 Seaborn 进行高级数据可视化。
5. 蛋白质设计中的特定应用
5.1 BioPython 包的使用:DNA,RNA 和蛋白质序列处理,访问主要的遗传
数据库(如 GenBank,SwissPort,FASTA 等)访问,执行基本生物学数据分析。
5.2 Python 脚本编写:将常见的蛋白质处理任务编写为自动化脚本,如序列
对比、结构预测等。
5.3 机器学习快速入门:学习使用 Scikit-learn 进行特征提取、机器学习模型
训练、评估和优化。
6. 实战案例
6.1 案例 1:蛋白质序列数据分析入门,如统计特定序列的频率、可视化序
列分布等。
6.2 案例 2:蛋白质结构预测基础,使用机器学习技术预测蛋白质的二级结
构或功能位点。
6.3 案例 3:开发一个自动化的蛋白质分析工具,集成数据处理、分析及可视
化功能。
第二天 Linux Shell 命令行操作基础
1. Shell 环境简介
1.1 什么是 Shell:了解 Shell 是什么,为什么要学习 Shell,以及它如何与操
作系统交互。
1.2 不同类型的 Shell 介绍:Bash、Zsh、Tcsh。
1.3 访问 Shell:如何打开终端窗口,基础的命令行界面操作。
2. 基础命令
2.1 文件系统操作:wc, cd, ls, pwd, rm, cp, mv 等命令的使用。
2.2 文件操作:mkdir, touch, more, less, head, tail, grep, find 等命令。
2.3 权限和所有权:使用 chmod, chown, chgrp 改变文件的权限和所有权。
2.4 文本处理:echo, cat, cut, sort, uniq, tr, awk, sed 等工具的基本使用。
2.5 归档和压缩:tar, gzip, gunzip, zip, unzip 等命令的使用。
3. Shell 脚本编写
3.1 Shell 变量和数据类型:定义和使用 String、int、float 和 array 变量。
3.2 流程控制与条件语句:if, else, elif, case 等语句的使用。
3.3 循环结构:for, while, until 循环的使用。
3.4 输入和输出:处理用户输入和脚本输出。
3.5 引用和转义字符:学习在命令行中正确使用单引号、双引号和转义字符。
3.6 高级文本编辑器 Vim 的配置和使用 Vim
3.7 创建和执行 Shell 脚本:编写一个简单的脚本并使其接收参数和执行。
4. 高级 Shell 编程
4.1 函数的高级用法:定义和使用函数,学习如何传递参数和调用函数。
4.2 调试 Shell 脚本:如何调试 Shell 脚本,包括设置和使用调试选项。
4.3 基本正则表达式的应用,学习文本处理三剑客 grep、sed、awk。
4.4 环境变量管理:了解 PATH 和其他环境变量的作用和管理方法。
5. 实用案例
5.1 案例 1: 使用 Python 运行 Shell 脚本。
5.2 案例 2: 编写一个自动整理下载并整理蛋白质序列数据的脚本。
5.3 案例 3: PDB 文件分析脚本的编写。
第三天 机器学习与深度学习基础
1. 统计学习理论基础
1.1 统计学习方法概述
1.2 传统有监督学习方法介绍
(a) 感知机与决策树算法
(b) K 近邻与朴素贝叶斯法
(c) 逻辑回归与支持向量机算法
(d) 随机森林算法与隐马尔可夫模型
1.3 集成学习算法重点介绍:GBDT、XGBoost
1.4 无监督学习与聚类算法
1.5 特征工程与模型评估
2. 神经网络与深度学习方法基础
2.1 人工神经网络基础知识
2.2 多层感知机
2.3 卷积神经网络:学习卷积的内涵、卷积的概念与特征、池化操作等
2.4 典型卷积神经网络算法结构、训练方法及应用
2.5 循环神经网络基本原理与模型介绍
2.6 长短期记忆神经网络模型及应用场景
3. 生成式神经网络
3.1 自动编码器
3.2 变分自动编码器
3.3 生成对抗网络
(a) 生成对抗网络基本原理
(b) Encoder-Decoder 模型
(c) DCGAN 和 WGAN 算法示例
4. 注意力机制
4.1 Seq2Seq 模型
4.2 (自)注意力机制模型的原理和工作机制
4.3 Transformer 模型及应用
4.4 BERT 模型与预训练方法介绍
4.5 基于 BERT 模型实现文本生成实验
5. 深度学习蛋白质设计入门
5.1 理解蛋白质设计的主要概念
5.2 传统从序列推断功能的方式介绍
5.3 机器学习领域中预测蛋白质功能的方法与局限性
5.4 了解 Pre-Trained Embeddings 方法的蛋白质设计方法
5.5 生成模型在蛋白质设计上的使用及优势
第四天 深度学习蛋白质设计基础
1. 深度学习蛋白质设计概述
1.1 蛋白质设计的背景与当前现状,
1.2 蛋白质设计面临的困难、传统方法与途径
(a) 从序列预测蛋白质结构:同源建模、共进化信息
(b) 使用神经网络预测蛋白质结构
1.3 蛋白质设计的关键点:序列、结构、功能、能量
1.4 蛋白质设计的目标:设计一个给定结构或功能的蛋白质
1.5 当前深度学习方法在蛋白质设计中的进展
(a) 基于序列的深度学习方法:DeepSequence,Progen,ProteinBERT 等
(b) 基于结构的深度学习方法:AlphaFold2, ColabFold, RoseTTAFold,
OmegaFold 等
(c) 其他蛋白质深度学习方法:
1.6 蛋白质设计方法的评估(亲和力、催化活性、配体特异性等)
2. 蛋白质设计概述
1.1 蛋白质序列表示形式
(a) 独热编码(One-Hot Encoding)
(b) 嵌入表示(Learned Embedding)
(c) 特定位置评分矩阵(Position-Specific Scoring Matrix)
1.2 蛋白质结构的表示形式
(a) 基于顺序和手工修正的表示
(b) Voxel 表示
(c) 距离图
(d) 图表示形式:图和点云
1.3 蛋白质结构可视化工具介绍和使用
(a) 蛋白质数据结构文件格式 PDB 介绍
(b) PyMOL:查看和分析蛋白质、DNA 和小分子的 3D 结构
(c) Chimera:综合性分子建模程序,提供多种分析和可视化功能,包括
体积数据的处理。
(d) VMD:一个分子可视化程序,用于使用 3D 图形和内置脚本显示、动
态化和分析大型生物分子系统。
1.4 蛋白质设计的常用评估指标:NSR、RMSD、GDT、能量评分函数、可
溶性、与靶标之间的结合强度和特异性
3. 蛋白质数据库介绍
1.1 一级蛋白质序列数据库:UniProtKB
1.2 一级蛋白质结构数据库:PDB
1.3 二级蛋白质数据库:Pfam,CATH,SCOP2
1.4 专用数据库:KEGG,OMIM
4. 蛋白质设计工具箱介绍
1.1 Rosetta:提供一个灵活的函数库来完成一组不同生物分子的建模任务,
完成对各种生物分子系统的预测、设计和分析,包括蛋白、RNA 和 DNA、肽、
小分子以及非标准或衍生氨基酸。
1.2 Foldit: 一个结合了游戏和科学的蛋白质折叠和设计平台,允许用户通过
游戏界面参与蛋白质设计。
1.3 Bioluminate: 是 Schrödinger 提供的一套生物分子建模和设计工具,包含
蛋白质设计模块。集成了高质量的分子动力学模拟和自由能计算,适用于精准设
计和预测。
1.4 EvoDesign:一个基于进化信息和结构模拟的蛋白质设计工具,主要用于
功能性蛋白质设计。
1.5 OpenFold: 是 AlphaFold2 的开源实现,具有相同的架构,但拥有改进的
速度和内存使用效率。
5. Rosetta 工具箱使用案例:一种基于统计势函数的蛋白质设计方法
1.1 统计势函数的一般定义:基于对已知蛋白质结构的大规模数据库的统计
分析,提取出各种结构特征之间的概率分布。
1.2 蛋白质设计中的统计势函数介绍
(a) 学习 Rosetta 工具箱中统计势函数定义和基本理念
(b) Rosetta 工具箱中能量函数常见项及物理意义
1.3 基于 Rosetta 工具箱中统计势函数的蛋白质设计案例
(a) 使用 Rosetta 工具检查输入的 PDB 文件,预处理,确定设计目标
(b) 执行序列设计实验,使用 Rosetta 的 PackRotamers 协议
(c) 使用 Rosetta 的标准能量函数(包括统计势函数)对设计结果进行能
量评估
第五天 基于深度学习的蛋白质设计进阶
1. 一种基于深度学习的蛋白质序列设计模型 ProteinMPNN
1.1 ProteinMPNN 简介与核心理念:通过深度学习生成具有特定功能的蛋白
质序列
1.2 ProteinMPNN 模型结构与工作原理
(a) ProteinMPNN 技术分析
(b) ProteinMPNN 模型介绍
(c) ProteinMPNN 模型训练与模型推理
1.3 基于 ProteinMPNN 的蛋白质设计应用:设计新型抗菌肽
(a) 实验流程:环境配置,数据准备、模型训练、筛选与验证。
(b) 实验总结:学会如何应用 ProteinMPNN 进行实际的蛋白质设计任务。
2. 从统计分析到深度残差网络的蛋白质结构预测算法
2.1 直接耦合分析和互信息计算:分析蛋白质序列中残基之间的相互作用信
息来推测它们之间的耦合关系或互信息。
2.2 深度残差网络和蛋白质接触图预测:深度残差网络可以用来预测蛋白质
的接触图,即残基之间的接触概率或距离,从而揭示蛋白质的结构信息。
2.3 蛋白质距离矩阵预测:预测蛋白质结构中所有残基对之间的距离或接近
程度。
2.4 图神经网络方法:捕捉蛋白质结构中残基之间复杂的相互作用和依赖关
系。
3. 从几何约束的梯度下降法到端到端深度学习的蛋白结构预测
1.1 梯度下降法和其在蛋白结构优化中的应用概述。
1.2 几何约束如何被集成到梯度下降法中,以实现特定的结构优化目标。
1.3 端到端几何深度学习方法介绍以及在蛋白结构预测中的优势和挑战。
1.4 AlphaFold 等先进模型如何利用端到端深度学习实现高效精准的蛋白质
结构预测。
(a) TrRosetta 介绍:使用了经过调整的残基接触预测方法,通过分析多
序列对应(MSA)和残基间的共进化信息来推断蛋白质的三维结构。
(b) AlphaFold 介绍:使用了端到端的深度学习模型,结合了残基对应、
残基接触预测和结构优化等步骤,以预测蛋白质的三维结构。
(c) RoseTTAFold 介绍:基于 AlphaFold 的技术思路进行开发的一种端到
端几何深度学习方法, 综合利用 MSA、距离和 3D 坐标信息,提高
结构预测的准确性。
4. Alphafold2 详解
4.1 AlphaFold2 的发展背景及其前身 AlphaFold 的演变过程。
4.2 AlphaFold2 的工作原理
(a) 多序列对应(MSA)和残基接触预测:利用多序列对应信息和残基
间的共进化信号来预测蛋白质的三维结构。
(b) Evoformer 架构:介绍 AlphaFold2 中使用的 Evoformer 架构,包括其
在特征提取和结构预测中的应用。
4.3 AlphaFold2 的算法和技术细节
(a) 神经网络架构:AlphaFold2 中的主要神经网络架构和层次结构。
(b) 训练和优化:AlphaFold2 如何通过大规模数据集的训练来优化结构
预测的准确性。
4.4 了解 AlphaFold3 相比于 AlphaFold2 的优势
5. RoseTTAFold 详解
5.1 RoseTTAFold 背景和基本概念
5.2 RoseTTAFold 的工作原理与技术细节
(a) 多序列对应(MSA)和残基接触预测:RoseTTAFold 如何利用多序
列对应信息和残基间的共进化信号来预测蛋白质的三维结构。
(b) 深度神经网络架构:RoseTTAFold 中使用的主要神经网络结构和层
次。
(c) 模型架构和训练:详细介绍 RoseTTAFold 的模型架构,如何训练和
优化模型以提高预测准确性。
5.3 RoseTTAFold 的优势和局限性。
6. 案例演示
6.1 使用 AlphaFold2 进行蛋白质结构在线预测
6.2 使用 RoseTTAFold All-Atom(RFAA)进行蛋白-小分子复合物结构预测
6.3 RoseTTAFold、ProteinMPNN 和 AlphaFold 之间的主要区别
第六天 深度学习蛋白质设计应用实战
1. 基于 AlphaFold2 多体蛋白结构预测与设计
1.1 多序列比对与序列拼接配对问题
(a) 多序列比对在蛋白质结构预测中的关键作用。
(b) 序列拼接配对问题如何影响蛋白质结构预测的准确
(c) AlphaFold2 中模板匹配的原理及其应用范围。
(d) 多肽和蛋白质柔性对接的挑战和解决方案。
2. 基于 AlphaFold2 做蛋白结构和序列新设计及结构聚类
2.1 AlphaFold2 如何实现蛋白质序列和结构的新设计
2.2 结构聚类与新功能发现
(a) Alphadatabase 数据库的结构分析与新功能发现。
(b) 使用 Foldseek 工具进行新结构的探索与功能预测。
3. 基于 AlphaFold2 做多构象预测与质量评估
3.1 多构象预测与功能发现
(a) 多序列比对采样聚类分析在蛋白质多构象预测中的应用。
(b) 不同 MSA 对蛋白质构象预测和功能发现的影响。
3.2 模型质量评估与侧链构象优化
(a) 三角机制如何提升蛋白质模型质量评估的准确性。
(b) 局部三角机制和 Evoformer 在蛋白质侧链构象预测中的应用和效果
评估。
4. RFdiffusion 实现通用性蛋白结构生成
4.1 RFdiffusion 基于指定骨架的蛋白质结构设计核心知识点:
4.2 利用用户提供的特定结构框架进行蛋白质结构设计应用案例:
(a) 无约束单体设计(contigmap):全新骨架的蛋白质结构创新设计,通
过 RFdiffusion 实现从头生成新颖、非同源蛋白质结构;
(b) 特定骨架引导设计 (scaffoldguided):利用已有结构骨架指导蛋白质
结构创新与改造。
5. ProteinGenerator 与 Rosettafold AA 的进阶应用
5.1 ProteinGenerator 实现蛋白质骨架与序列的 co-design
(a) 隐空间中蛋白质序列和结构的联合分布模型。
(b) 与 RFdiffusion 在设计中的异同和比较分析。
5.2 Rosettafold AA 实现多类生物大分子结构预测与生成
(a) 加入小分子结构预测器的 Rosettafold AA 版本。
(b) 将局部坐标系迁移到小分子结构的技术与方法。
6. 一种蛋白质生成模型 Chroma 的基本构架与实现
6.1 Chroma 模型的基本架构和理论背景。
6.2 利用 Chroma 逼近蛋白构象空间全空间采样和生成的方法。
第七天 大语言模型在蛋白质设计中的应用进展
1.蛋白质大预言模型发展现状
1.1 介绍当前基于不同结构的蛋白质语言模型
2. ProGen 介绍
2.1 ProGen 模型构架讲解及其优势
2.2 ProGen 的性能与改进
3. ESMFold 介绍
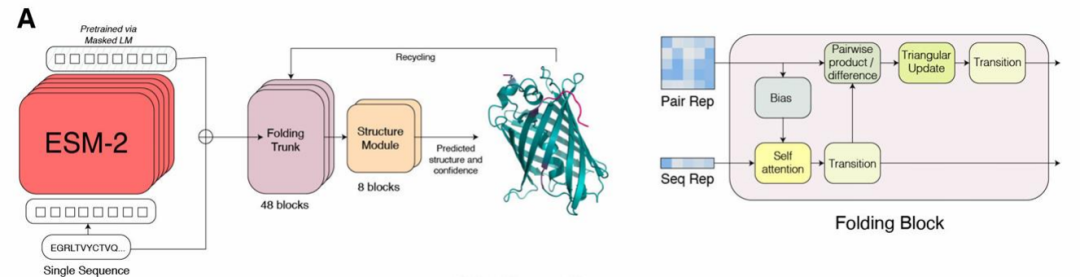
3.1 ESM 网络构架介绍
3.2 ESMFold 环境配置与使用步骤讲解
3.3 ESMFold 运行结构预测及性能评估
3.4 ESMFold 与 AlphaFold2 方法的对比
4. ProLLaMA:用于多任务蛋白质语言处理的蛋白质大语言模型
4.1 ProLLaMA 模型介绍
4.2 ProLLaMA 训练框架概述及应用特色
5. ProteinBERT:蛋白质序列和功能的通用深度学习模型
5.1 ProteinBERT 方法概述与框架介绍
5.2 ProteinBERT 的优势及应用场景
6. 深度学习算法在多肽设计的应用
6.1 基于 RF diffusion 实现多肽设计
6.2 基于 AlphaFold2 梯度下降进行多肽骨架和序列设计
6.3 多肽对接算法介绍:
(a) 基于 AutoDock 的多肽对接
(b) 基于 AlphaFold2 的多肽柔性对接
(c) 其他对接算法
6.4 基于多肽蛋白复合物训练的深度学习多肽设计算法
时间:
2024.08.17-----2024.08.18全天授课(上午9:00-11:30下午13:30-17:00)
2024.08.23晚上授课(晚上19:00-22:00)
2024.08.24-----2024.08.25全天授课(上午9:00-11:30下午13:30-17:00)
2024.08.30晚上授课(晚上19:00-22:00)
2024.08.31-----2024.09.01全天授课(上午9:00-11:30下午13:30-17:00)
腾讯会议 线上(共七天时间 提供全程回放视频)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









