







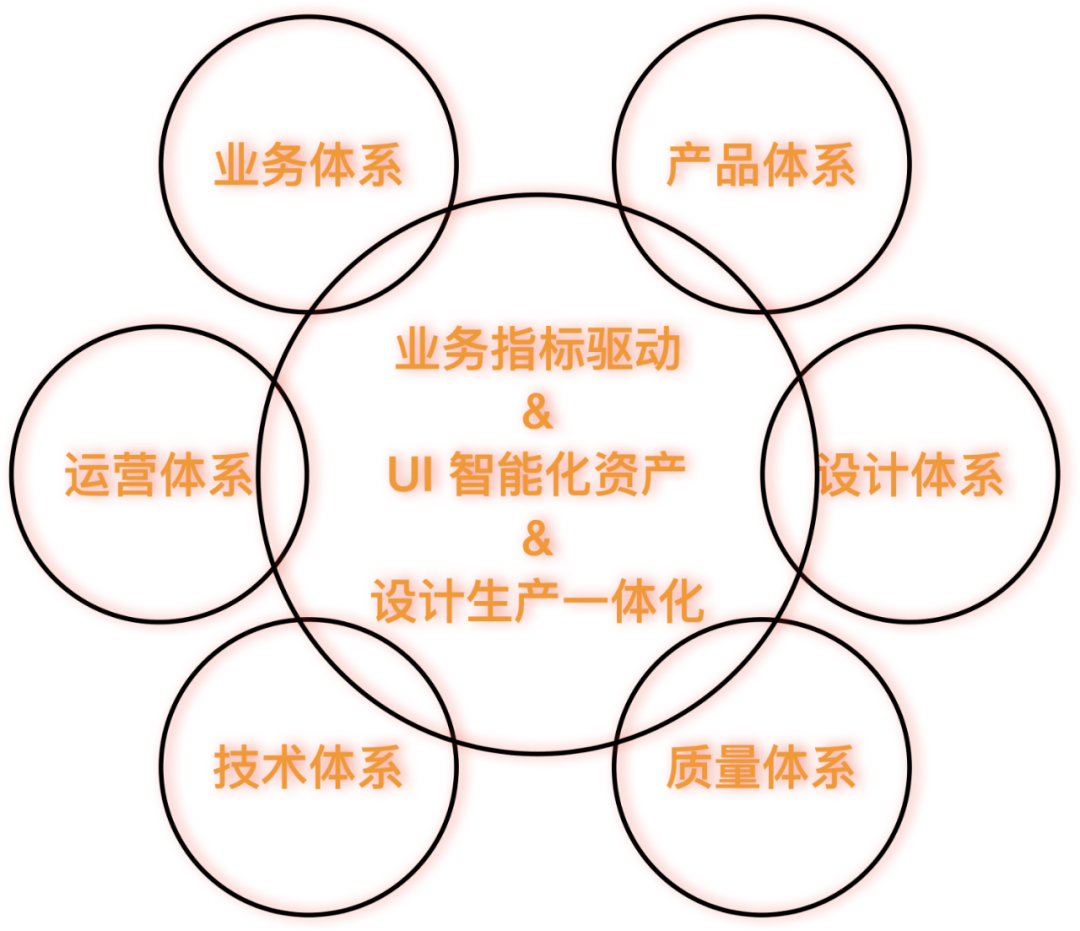
业务、产品、设计、技术——前端智能化的核心客户
做任何事情必须要有客户的视角,知道服务谁才知道要解决什么问题。前端智能化的核心客户和我们的发展阶段息息相关,在初期阶段,面向技术人员围绕“解决一线 C 端业务研发效率问题”构建“设计稿生成代码”的能力。在中后期,我们必须将技术能力赋能到业务升级为业务能力。面向业务人员围绕“解决业务缺乏用户产品抓手的问题”构建“透明、快速、直接干预业务”的能力。面向 PD 围绕“解决业务敏捷创新和快速试错的问题”构建“设计稿生成的代码之上所见即所得的需求标注即可交付上线”的能力。面向设计师围绕“解决设计规范执行难、设计创新研发成本高落地难的问题”构建“设计生产一体化”的能力。
运营使用未在我们的体系内定义成核心客户,因为,今天圆心领导的小二工作台,不仅完善的解决了招商、选品、投放……等一系列运营问题,构建了完整的数据化驱动运营的技术体系,还借助 PU 、SOP 编排的方式,帮助业务根据自己的需要进行定制,舒文领导的“诺亚”借助“方舟”在多年大促营销活动上沉淀的经验,进一步降低了小二工作台的使用成本,我们只需要在前端智能化赋能业务的过程中引入“诺亚”或其他 PU、SOP 能力即可服务好运营。
质量保障未在我们的体系内定义成核心客户,因为,今天清灵领导的质量保证体系在前端智能化初期就和我们在深度合作,从 ATS 自动化测试模块质量,到 TMQ 基于机器视觉和算法的自动化测试,都已经做得非常完善,并且,底层的技术体系和上层的开放能力都足以支撑我们“开箱即用”,保证两套体系的功能和体验的一致性,可方便的支撑好质量保障的同学进行质量验收和质量监控。
▐ 技术人员:C端业务研发效率问题
对于我们阿里来讲,技术人员是一个巨大的群体,C 端业务又是一个面向终端用户且复杂多变的场景,跨平台、需求变更、个性化是这些复杂多变场景的核心问题,他们共同要求“有一种消除重复劳动的技术”,否则,只能靠技术人员自身来填这个大坑。对于技术人员来说,跨平台、需求变更、个性化对技术而言并没有太大的挑战和创新,只是时间成本的问题:适配不同的平台、实现变更的需求、逐个开发不同的个性化承接产品,这些就是亟待消除的“重复劳动”。
只有深入研究跨平台的业务研发问题,我们才能准确的定义 RunCook 的功能,才能解决业务研发过程中对宿主环境业务能力的适配和降级问题。只有深入研究需求变更,我们才能准确定义 BizCook、imgCook、LogicCook 的功能,才能通过 NLP 的算法模型理解业务定义的指标如何被 PD 描述成需求、设计师又如何用设计语言来表达 PD 的需求、设计稿如何借助 imgCook 生成 UI和交互逻辑、UI 的内容及状态的变化如何借助 LogicCook 从 PaaS 上获取并实例化成 Node FaaS 的胶水层代码挂载在 UI 和交互逻辑之上。深入研究消费者,我们才能准确定义 UICook和鲸幂的功能,才能通过智能设计生产一体化、代码生成能力降低一线业务研发人员为不同圈层用户开发产品功能的成本,给消费者带来极致的产品体验。
▐ 业务人员
小芃在介绍数据中台的时候说:「 以观星台举例,逍遥子可以通过观星台看到全集团宏观的业务治理,这是一个最大的顶层的节点。再往下这个子节点,就是各个业务总裁和业务的矩阵,下面每个业务有自己业务数据的逻辑和数据决策的体系。再往下就是每一次的活动,或是一些节点,基本上形成了一个决策体系。我对这个观点深以为然,今天决策体系化才能让业务形成战斗力,然而,却有一些问题会阻碍这种战斗力的形成:执行。」
在技术产品里有一个生动的比喻:P9 的战略、P8 的规划、P7 的设计、P5 的执行,最后,一个好的思想和理论没有能够形成好的技术产品。为什么不能是 P9 的战略、P8 的规划、设计和执行呢?因为,信息在传递的时候会有损耗。通俗的理解就是:张大妈说你和女同学放学一起回家,李大婶说你和女同学谈恋爱,王大爷说你和女同学结婚了。信息论里研究信息的损耗,因为信号在介质中传递的时候会受到干扰,电信号在取值范围上下的波动未达到信号电压要求,从而导致信息的一些编码丢失,李大婶和王大爷自身的偏见就是导致信息损耗的干扰。下面,借助一些信息论里的知识谈谈服务业务人员过程中如何抗干扰?
谈到信息论,就离不开编码。谈到信息论就离不开传递信息,传递信息的过程需要对信息进行编码,而如何用最少的编码表示所要传递的信息就是我们要研究的目标了。
假设两地互相通信,两地之间一直在传递A,B,C,D四类消息,那应该要选择什么样的编码方式才能尽可能少的使用资源呢?如果这四类消息的出现是等概率的,都为四分之一,那么肯定应该采用等编码方式,也就是
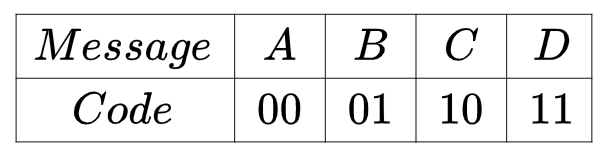
这样就能达到最优的编码方式,平均编码长度为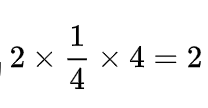 。
。
但是,如果四类消息出现的概率不同呢?例如 A 消息出现的概率是二分之一,B 是四分之一,C 是八分之一,D 是八分之一,那应该怎样编码呢?直觉告诉我们,为了使平均编码长度尽可能小,出现概率高的 A 消息应该使用短编码,出现概率低的C ,D 消息应该使用长编码。与等长编码相比,这样的编码方式叫做变长编码,它的效果更好,例如采用下表所示的编码(其实这是最优编码)
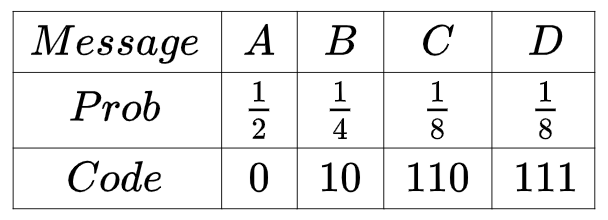
平均编码长度为
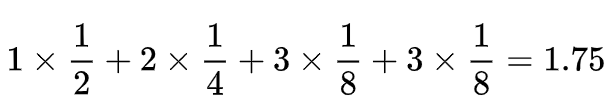
显然要优于等长编码。
业务同学决策依据的数据指标有大量的歧义和冗余,这就需要有一套编码机制有效的对业务指标进行编码,保证在决策信息传递的过程中更精确、有效,因为,信息冗余越多损耗的概率就越大,编码的有效性越差,编码的冗余信息就越多。我们在 BizCook 上重新构建 C 端业务研发的指标体系和其编码方式,对指标包含的信息进行有效编码,是决策信息有效传递的第一步。
若现在还有一种消息序列的概率分布满足 q 分布,但是它仍然使用 p 分布的最优编码方式,那么它的平均编码长度即为
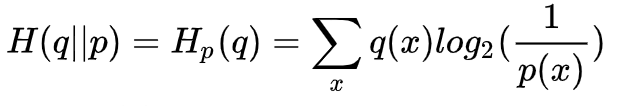
其中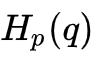 被称为 q 分布相对于 p 分布的交叉熵(Cross Entropy),它衡量了 q 分布使用 p 分布的最优编码方式时的平均编码长度。
被称为 q 分布相对于 p 分布的交叉熵(Cross Entropy),它衡量了 q 分布使用 p 分布的最优编码方式时的平均编码长度。
交叉熵不是对称的,即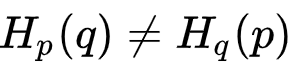 。交叉熵的意义在于它给我们提供了一种衡量两个分布的不同程度的方式。两个分布 p 和 q 的差异越大,交叉熵
。交叉熵的意义在于它给我们提供了一种衡量两个分布的不同程度的方式。两个分布 p 和 q 的差异越大,交叉熵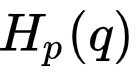 就比
就比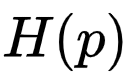 大的越多,如图
大的越多,如图
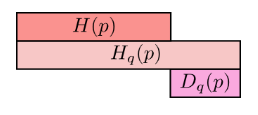
它们的不同的大小为 ,这在信息论中被称为 KL 散度(Kullback-Leibler Divergence),它满足
,这在信息论中被称为 KL 散度(Kullback-Leibler Divergence),它满足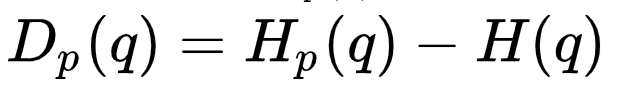 。
。
KL散度可以看作为两个分布之间的距离,也可以说是可以衡量两个分布的不同程度。
对于业务的同学,围绕自己两三个核心目标层层拆解下去的业务指标也有 q 和 p 的分布,我们可以在 BizCook 上根据交叉熵来衡量实际:产品、设计和技术在承接这些指标时候的偏差程度,也可以在 BizCook 上利用 KL 散度来判断决策指标在承接过程中的信息损耗。
和单变量相同,如果有两个变量 X,Y,我们可以计算它们的联合熵(Joint Entropy)
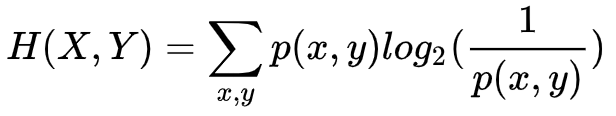
当我们事先已经知道 Y 的分布,我们可以计算条件熵(Conditional Entropy)

X 与 Y 变量之间可能共享某些信息,我们可以把信息熵想象成一个信息条,如下图:
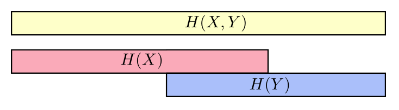
从中可以看出,单变量的信息熵H(x)(或H(Y))一般比多变量信息熵
H(X,Y)要小。如果把条件熵也放进来,那么可以从信息条更清晰的看出它们之间的关系
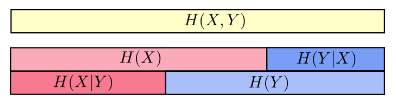
可以看出
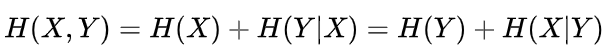
更细一点,我们把H(X)与H(Y)重叠的部分定义为 X 与 Y 的互信息(Mutual Entropy),记作I(X,Y),则 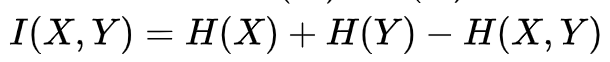 。互信息代表了 X 中包含的有关于 Y 的信息(或相反)。
。互信息代表了 X 中包含的有关于 Y 的信息(或相反)。
将 X 与 Y 不重叠的信息定义为差异信息(Variation of Information),记为
V(X,Y),则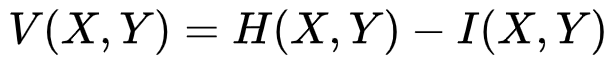
差异信息可以衡量变量 X 与 Y 的差距,若V(X,Y)为0,就意味着只要知道一个变量,就知道另一个变量的所有信息。随着V(X,Y)的增大,也就意味着 X 与 Y 更不相关。形象化的表示可以从下图看出
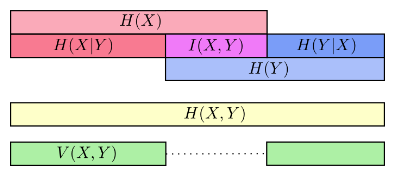
对于业务的同学来说,可以很容易通过互信息来衡量:产品、设计、技术承接自己的决策时,其指标和自己目标之间的关联度,BizCook 可以借助互信息和差异信息来进行度量,从而帮助业务同学解决目标落地执行的偏离问题。
由于业务决策被编码成业务指标,业务生产指标被编码成产品指标、设计指标、技术指标,借助前端智能化的生成技术体系,决策和执行将前所未有的统一,而不再是割裂的,由此,BizCook 解决了“张大妈说你和女同学放学一起回家,李大婶说你和女同学谈恋爱,王大爷说你和女同学结婚了。”这个信息损耗的问题。
▐ 产品和设计人员
和 B 端业务不同,在 C 端业务里,因为大部分情况设计直接决定了 UI 的视觉和交互,UI 的视觉和交互又是 C 端业务非常核心的部分,因此,产品和设计多数情况下是共同定义产品的功能的,可以放在一起说。
产品定义产品的工具是:需求文档,设计定义产品的工具是:设计稿、交互稿,这两者都是在描述:什么用户?在什么场景?看到什么?做什么?只是,需求文档在视觉方面更加抽象、功能层面更加具体,而设计稿、交互稿在视觉方面更加具体、功能层面更加抽象,结果,PD 和设计师一合计,干脆合一起吧!于是,平常在生产过程中拿到的设计稿大多是酱紫的:

这个视觉和功能二合一的描述方式,怎一个“赞”字了得?简单清晰,把设计和产品功能完美的融合在一起,一目了然。既然 PD 和设计师都喜欢这样的产品定义描述方式,我们何不在前端智能化领域吸收借鉴一下呢?于是,有了“基于设计稿生成代码所见即所得的产品定义”能力在 BizCook 上诞生,在继承了 imgCook 设计稿生成代码的基础上,扩展了 LogicCook 的业务逻辑代码生成和推荐,让 PD 和设计师在定义产品的过程中就完成了 MVP 并可以上线灰度进行小批量产品验证。
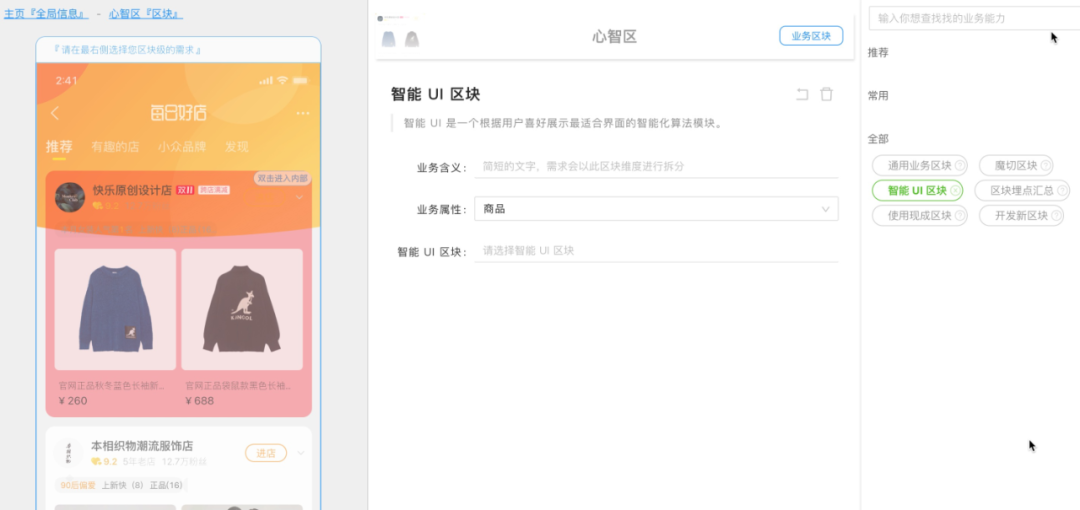
可以从上图看到,左侧预览区域的内容都是 imgCook 通过设计稿生成的,PD 可以在这个基础上选择一个区块去定义这个区块承接什么业务?完成什么关联业务指标?功能上有什么约束?要怎样提供个性化服务?……从定义业务到子业务、到页面、再到一个区块层层递进,把定义产品的过程和业务决策、业务指标无缝连接在一起。
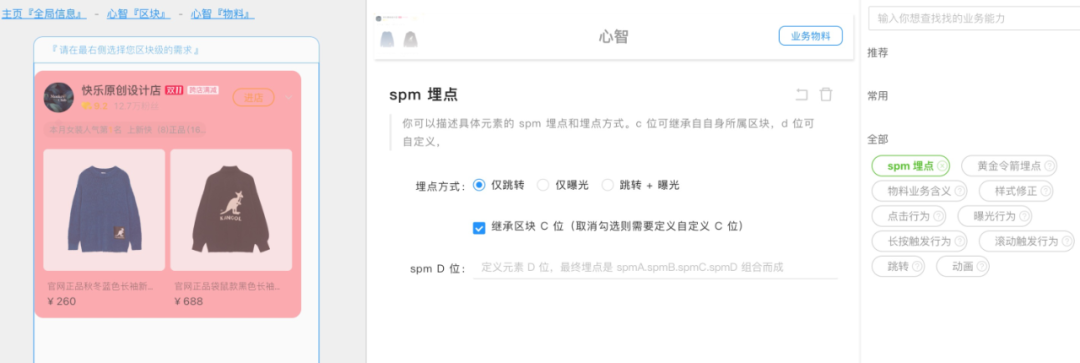
所以,BizCook 服务产品和设计这两个核心客户的时候,首要原则就是符合 PD 和设计师的工作习惯,用 PD 和设计师熟悉的概念描述产品的定义和业务的功能,不额外引入新概念,也坚决不用晦涩难懂的技术概念。这样,不仅能够让产品定义“高度保真”,还能够极大将降低 PD 和设计师理解和使用的成本。
总结和展望
从最初服务一线研发人员,到后来的服务于产品和设计人员,再到未来服务于业务人员,这个路线背后的思考是:在技术领域围绕效率创新,必须逐步过渡到生产,再进入业务领域进行升华。脱离业务、生产单纯在技术领域里兜兜转转,是制约大部分技术人向上发展的王屋和太行。
仰望星空再回到现实里脚踏实地,必须清醒认识到:技术向生产乃至业务领域过渡是一个复杂且漫长的过程。进入生产领域需要大局观和架构能力,进入业务领域需要全局观和商业能力,不去改变和提升自己,终是画虎画皮难画骨,形似而神不在。
大部分同仁,在听过、见过甚至部分实践过后,仍会觉得云里雾里,初时,觉得头头是道,做时,觉得千头万绪。总的来说,我认为缺的是内观、俯察。所谓内观,要求我们向自己找原因,真正有价值的东西是方案和成果背后的思考,是无法通过表象所感应、知觉、理解的,这就像两个音叉,敲响一个另一个谐振的原因是这两个音叉的质地一致,我们在无法跟别人的观点产生共鸣的大部分情况是自己的质地无法和别人观点背后的质地一致而已,去修炼自己即可。所谓俯察,要求我们向脚下之路找原因,不要好大喜功、好高骛远,要清楚自己迈出的每一步:轻了?重了?快了?慢了?甚至要进行逆察,不断审视过去的每一步。
今天的前端智能化,在技术上有点儿小成绩,同时也有很多问题。今天的生产领域、业务领域拓展尝试,在结果上有点儿小业务效果,同时也有很多过程上乃至源头能力上的缺失和不足。这就需要我们仰观俯察,既要看到大方向、大趋势、大战略,又要看到小闭环、小问题、小细节。从大处着眼、小处着手,把 UI 智能化资产并前端智能化易学、易用落到实处,解决一线业务研发过程中的实际问题。
为此,我们把未来的发展具象化到一些大方向、大趋势、大战略上,同时,拆解到类似“开箱即用的算法”、“业务上取得实际效果”……等一系列小闭环、小问题、小细节中去。在教授(展炎)的指导下,新财年里设立“用户体验升级”这个主题,来聚焦我们要解决的问题,把前端智能化落到实处:
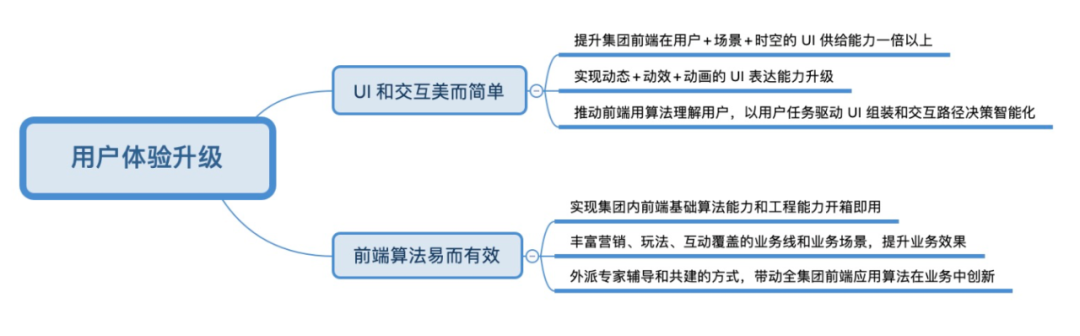
由此,设定我们的 OKR (还是讨论版)去约束我们的发展方向和发展目标,给出一个清晰明确的路径:
- 面向场景和人群的视觉设计智能化
KR1:基于 UI 交互的场景、人群标签扩展2~3倍,准确率达到 80% 以上
KR2:基于 UI 交互的场景、人群理解算法自动化生成用户承接 UI
KR3:利用设计中台打通智能 UI 和智能设计两大体系,实现高质量方案自动化生成
- 人机交互方式的智能化
KR1:端侧模型和服务端算法模型能力协力实现 UI 的个性化呈现,提升用户粘性
KR2:基于算法对用户的理解,以用户任务驱动 UI 组装和交互路径决策,提升用户交互的有效性
KR3:用端侧算法模型能力开拓新的用户交互方式和用户承接场景,用新奇特智能人机交互驱动用户体量增长
- 降低面向上述场景下的前端应用门槛
KR1:达成智能 UI 生成能力和智能 UI 推荐算法、端智能模型优化和下发的开箱即用
KR2:用 PipCook 降低前端学习、应用、部署机器学习算法的成本
KR3:外派专家辅导和共建的方式,融合前端算法课程培训,带动集团前端应用算法在业务中创新
期望在新的一年,我们能够建设好我们的数据、标签、算法、物料…… UI 智能化资产,还能够继续把我们的生产能力进行升级,同时,借助 PipCook 降低前端应用门槛,让前端智能化对阿里集团每个前端普惠和开放。同时,也期望每个参与前端智能化的同仁,都能够在自己的业务场景中,用自己的慧眼去发现更多因机器学习、算法所带来的技术、工程乃至业务的可能性,用自己的智慧并前端智能化一起,给业务创造更多属于阿里前端的价值!共勉!
✿ 拓展阅读




作者|甄子
**编辑|**橙子君
**出品|**阿里巴巴新零售淘系技术


自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数前端工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Web前端开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注前端)

文末
js前端的重头戏,值得花大部分时间学习。
推荐通过书籍学习,《 JavaScript 高级程序设计(第 4 版)》你值得拥有。整本书内容质量都很高,尤其是前十章语言基础部分,建议多读几遍。
CodeChina开源项目:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
另外,大推一个网上教程 现代 JavaScript 教程 ,文章深入浅出,很容易理解,上面的内容几乎都是重点,而且充分发挥了网上教程的时效性和资料链接。
学习资料在精不在多,二者结合,定能构建你的 JavaScript 知识体系。
面试本质也是考试,面试题就起到很好的考纲作用。想要取得优秀的面试成绩,刷面试题是必须的,除非你样样精通。
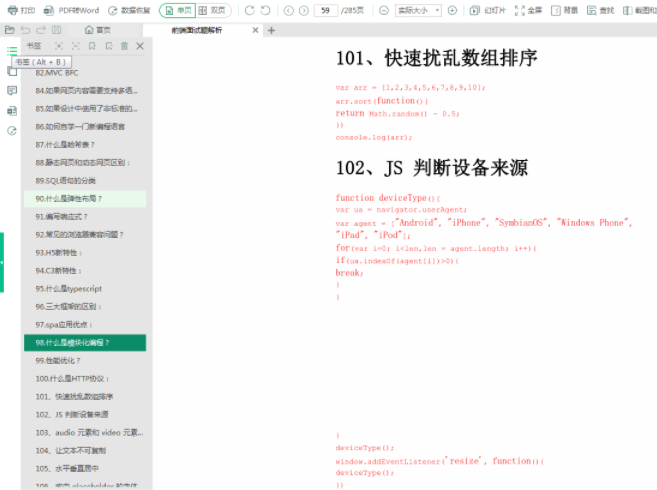
这是288页的前端面试题
(第 4 版)》你值得拥有。整本书内容质量都很高,尤其是前十章语言基础部分,建议多读几遍。
CodeChina开源项目:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
另外,大推一个网上教程 现代 JavaScript 教程 ,文章深入浅出,很容易理解,上面的内容几乎都是重点,而且充分发挥了网上教程的时效性和资料链接。
学习资料在精不在多,二者结合,定能构建你的 JavaScript 知识体系。
面试本质也是考试,面试题就起到很好的考纲作用。想要取得优秀的面试成绩,刷面试题是必须的,除非你样样精通。
这是288页的前端面试题















 951
951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









