







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

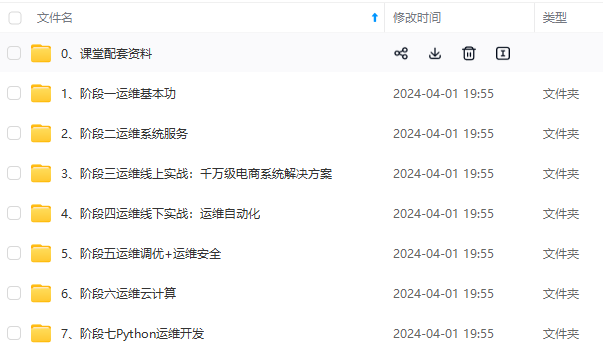
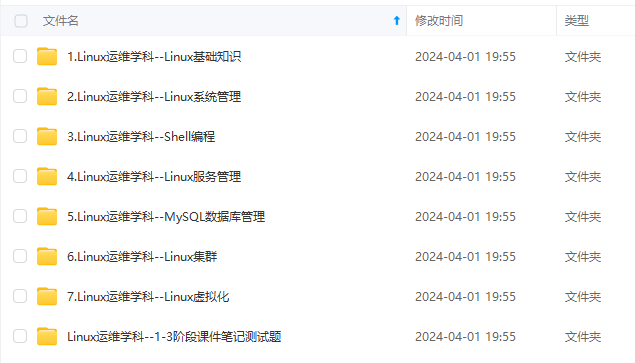
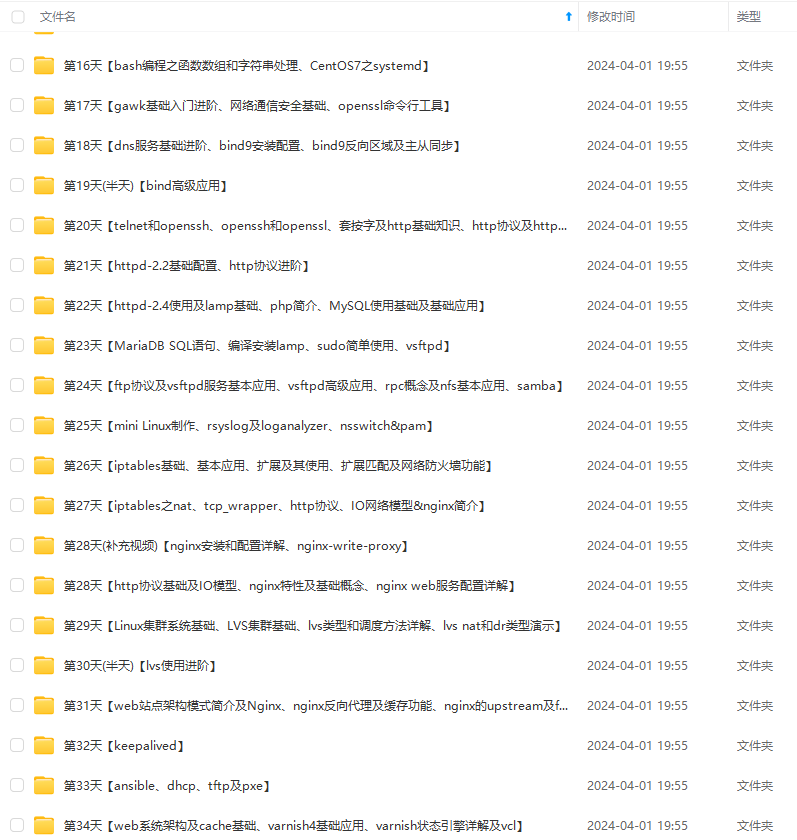
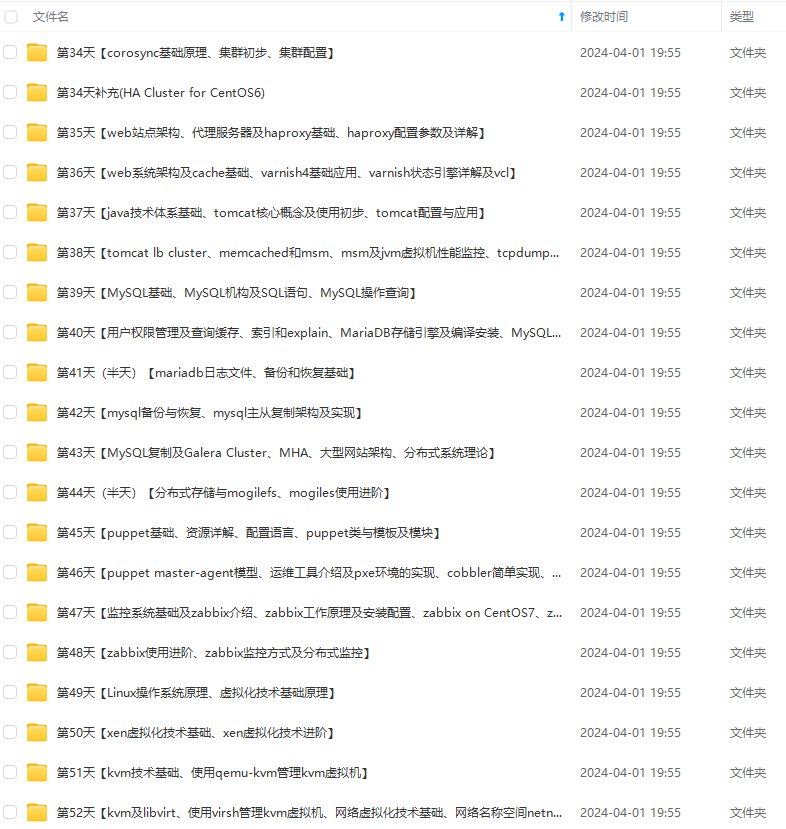
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)

正文
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
**********告警通知**********
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
{{- end }}
=====================
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.description }}
故障时间: {{ $alert.StartsAt.Local }}
{{ if gt (len $alert.Labels.instance) 0 -}}故障实例: {{ $alert.Labels.instance }}{{- end -}}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
**********恢复通知**********
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
{{- end }}
=====================
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.description }}
故障时间: {{ $alert.StartsAt.Local }}
恢复时间: {{ $alert.EndsAt.Local }}
{{ if gt (len $alert.Labels.instance) 0 -}}故障实例: {{ $alert.Labels.instance }}{{- end -}}
{{- end }}
{{- end }}
{{- end }}
尖叫注意!我废了两小时才得出的结论!
alertmanager用的UTC时间,所以报警时间出来都是错误的!!!所以在这里我跋山涉水终于找到了使用本地时间的方法!就是alert.StartsAt.Local这种写法!!!原罪还是自己太菜!但是好在解决了,全网首发~
第三个文件是在Prometheus下进行修改报警设置:
 添加预警的指标,我这里写了一个
添加预警的指标,我这里写了一个test.rules:
groups:
- name: monitor_base
rules:
- alert: CpuUsageAlert_waring
expr: sum(avg(irate(node_cpu_seconds_total{mode!='idle'}[5m])) without (cpu)) by (instance) > 0.60
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} CPU usage high"
description: "{{ $labels.instance }} CPU usage above 60% (current value: {{ $value }})"
- alert: CpuUsageAlert_serious
#expr: sum(avg(irate(node_cpu_seconds_total{mode!='idle'}[5m])) without (cpu)) by (instance) > 0.85
expr: (100 - (avg by (instance) (irate(node_cpu_seconds_total{job=~".*",mode="idle"}[5m])) * 100)) > 85
for: 3m
labels:
level: serious
annotations:
summary: "Instance {{ $labels.instance }} CPU usage high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
- alert: MemUsageAlert_waring
expr: avg by(instance) ((1 - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes) / node_memory_MemTotal_bytes) * 100) > 70
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} MEM usage high"
description: "{{$labels.instance}}: MEM usage is above 70% (current value is: {{ $value }})"
- alert: MemUsageAlert_serious
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes)/node_memory_MemTotal_bytes > 0.90
for: 3m
labels:
level: serious
annotations:
summary: "Instance {{ $labels.instance }} MEM usage high"
description: "{{ $labels.instance }} MEM usage above 90% (current value: {{ $value }})"
- alert: DiskUsageAlert_warning
expr: (1 - node_filesystem_free_bytes{fstype!="rootfs",mountpoint!="",mountpoint!~"/(run|var|sys|dev).*"} / node_filesystem_size_bytes) * 100 > 80
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Disk usage high"
description: "{{$labels.instance}}: Disk usage is above 80% (current value is: {{ $value }})"
- alert: DiskUsageAlert_serious
expr: (1 - node_filesystem_free_bytes{fstype!="rootfs",mountpoint!="",mountpoint!~"/(run|var|sys|dev).*"} / node_filesystem_size_bytes) * 100 > 90
for: 3m
labels:
level: serious
annotations:
summary: "Instance {{ $labels.instance }} Disk usage high"
description: "{{$labels.instance}}: Disk usage is above 90% (current value is: {{ $value }})"
- alert: NodeFileDescriptorUsage
expr: avg by (instance) (node_filefd_allocated{} / node_filefd_maximum{}) * 100 > 60
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} File Descriptor usage high"
description: "{{$labels.instance}}: File Descriptor usage is above 60% (current value is: {{ $value }})"
- alert: NodeLoad15
expr: avg by (instance) (node_load15{}) > 80
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Load15 usage high"
description: "{{$labels.instance}}: Load15 is above 80 (current value is: {{ $value }})"
- alert: NodeAgentStatus
expr: avg by (instance) (up{}) == 0
for: 2m
labels:
level: warning
annotations:
summary: "{{$labels.instance}}: has been down"
description: "{{$labels.instance}}: Node_Exporter Agent is down (current value is: {{ $value }})"
- alert: NodeProcsBlocked
expr: avg by (instance) (node_procs_blocked{}) > 10
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Process Blocked usage high"
description: "{{$labels.instance}}: Node Blocked Procs detected! above 10 (current value is: {{ $value }})"
- alert: NetworkTransmitRate
#expr: avg by (instance) (floor(irate(node_network_transmit_bytes_total{device="ens192"}[2m]) / 1024 / 1024)) > 50
expr: avg by (instance) (floor(irate(node_network_transmit_bytes_total{}[2m]) / 1024 / 1024 * 8 )) > 40
for: 1m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Network Transmit Rate usage high"
description: "{{$labels.instance}}: Node Transmit Rate (Upload) is above 40Mbps/s (current value is: {{ $value }}Mbps/s)"
- alert: NetworkReceiveRate
#expr: avg by (instance) (floor(irate(node_network_receive_bytes_total{device="ens192"}[2m]) / 1024 / 1024)) > 50
expr: avg by (instance) (floor(irate(node_network_receive_bytes_total{}[2m]) / 1024 / 1024 * 8 )) > 40
for: 1m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Network Receive Rate usage high"
description: "{{$labels.instance}}: Node Receive Rate (Download) is above 40Mbps/s (current value is: {{ $value }}Mbps/s)"
- alert: DiskReadRate
expr: avg by (instance) (floor(irate(node_disk_read_bytes_total{}[2m]) / 1024 )) > 200
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Disk Read Rate usage high"
description: "{{$labels.instance}}: Node Disk Read Rate is above 200KB/s (current value is: {{ $value }}KB/s)"
- alert: DiskWriteRate
expr: avg by (instance) (floor(irate(node_disk_written_bytes_total{}[2m]) / 1024 / 1024 )) > 20
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Disk Write Rate usage high"
description: "{{$labels.instance}}: Node Disk Write Rate is above 20MB/s (current value is: {{ $value }}MB/s)"
全部复制进去就行了,如下图:

注意:这里需要重启Prometheus
第三步进行运行配置文件alertmanager:
nohup ./alertmanager --config.file=./alertmanager.yml --storage.path=/opt/software/prometheus/alertmanager/alertmanager/data/ --log.level=debug &
启动之后可以在hostname:9093查看到信息,显示出如下界面则说明alertmanager启动成功:
 后台日志:
后台日志:

Prometheus下可以看到预警的指标,访问地址ip:9090,出现如下界面则说明预警指标配置成功!:


4.测试报警
故意宕掉一个节点,然后企业微信中显示如下,节点恢复后显示如下:

本文参考了如下博客:
https://www.cnblogs.com/sanduzxcvbnm/p/13724172.html
https://blog.csdn.net/wanchaopeng/article/details/83857130
https://blog.51cto.com/10874766/2530127?source=dra
https://www.fxkjnj.com/?p=2488
感谢以上博客的贡献!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)
[外链图片转存中…(img-QEd1xujx-1713392720955)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 6724
6724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









