







message String
) ENGINE = Kafka(‘localhost:9092’, ‘topic’, ‘group1’, ‘JSONEachRow’);
3.2.3:特殊引擎
1:Distributed分布式引擎
分布式引擎本身不存储数据, 但可以在多个服务器上进行分布式查询。 读是自动并行的
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = Distributed(cluster, database, table[, sharding_key[, policy_name]])
[SETTINGS name=value, ...]
cluster - 服务为配置中的集群名
database - 远程数据库名
table - 远程数据表名
sharding_key - (可选) 分片key
policy_name - (可选) 规则名,它会被用作存储临时文件以便异步发送数据
/etc/metrika.xml配置文件,一个shard代表一个节点,一个replica代表一个副本
<remote_servers>
<logs>
<!-- 分布式查询的服务器间集群密码
默认值:无密码(将不执行身份验证)
如果设置了,那么分布式查询将在分片上验证,所以至少:
- 这样的集群应该存在于shard上
- 这样的集群应该有相同的密码。
而且(这是更重要的),initial_user将作为查询的当前用户使用。
-->
<!-- <secret></secret> -->
<shard>
<!-- 可选的。写数据时分片权重。 默认: 1. -->
<weight>1</weight>
<!-- 可选的。是否只将数据写入其中一个副本。默认值:false(将数据写入所有副本)。 -->
<internal_replication>false</internal_replication>
<replica>
<!-- 可选的。负载均衡副本的优先级,请参见(load_balancing 设置)。默认值:1(值越小优先级越高)。 -->
<priority>1</priority>
<host>example01-01-1</host>
<port>9000</port>
</replica>
<replica>
<host>example01-01-2</host>
<port>9000</port>
</replica>
</shard>
<shard>
<weight>2</weight>
<internal_replication>false</internal_replication>
<replica>
<host>example01-02-1</host>
<port>9000</port>
</replica>
<replica>
<host>example01-02-2</host>
<secure>1</secure>
<port>9440</port>
</replica>
</shard>
</logs>
</remote_servers>
4:数据类型
Int类型:Int8、 Int16、 Int32、 Int64、 Int128、 Int256
时间类型:Date32、DateTime64、Date
iP:IPv4、IPv6
小数:Float32、Float64、Decimal32、Decimal64、Decimal128
boolean:
字符串:String、FixedString、UUID
特殊类型:数组Array、枚举Enum8、Enum16、元组tuple(T)、嵌套Nested、位置坐标Point、Ring、Polygon、MultiPolygon
5:数据库使用
5.1:表
5.1.1:表架构
1、本地表(Local Table)和分布式表(Distribute Table)
- 一张本地表相当于一份数据分片,只存储在自己的服务器上。可以作为分布式表的一部分,不是分布式表时就是自己的一张表
- 分布式表本身不存储数据,它是本地表的访问代理,借助分布式表,能够代理访问多个数据分片,从而实现分布式查询,分布式表只是将数据分散存放了,相当于进行了负载均衡和一定的容错
本地表和分布式缺点:存在单点问题,分片故障数据丢失
本地表与分布式表的区别在于:
- 本地表的写入和查询,受限于单台服务器的存储、计算资源,不具备横向拓展能力;
- 而分布式表的写入和查询,则可以利用多台服务器的存储、计算资源,具有较好的横向拓展能力。
2、单机表和复制表
- 单机表:数据只会存储在当前服务器上,不会被复制到其他服务器,即只有一个副本。
- 复制表:ClickHouse依靠ReplicatedMergeTree引擎族与ZooKeeper实现了复制表机制,来实现CH的高可用,数据会被复制到多个服务器上形成多副本进行存储。
单机表与复制表的区别在于:
- 单机表在异常情况下无法保证服务高可用。
- 复制表在至少有一个正常副本的情况下,仍旧能够对外提供服务。
单机表和复制表缺点:受限于单台服务器的存储、计算资源,不具备横向拓展能力;复制表的副本故障时查询需要手动切换查询的实例。
5.1.2:建表
1:单机表和复制表
创建单机表
CREATE TABLE database.order
(
`Operators` String COMMENT '操作人',
`Orderdate` Date COMMENT '订单日期',
`OrderTime` DateTime COMMENT '订单时间',
`CreateTime` DateTime DEFAULT now() COMMENT '创建时间'
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(Orderdate)
ORDER BY (Type, Subtype, Successflag, Province, Operators)
创建复制表就是将MergeTree()引擎替换ENGINE = ReplacingMergeTree()即可,复制表就是单机表存在副本。
2:本地表和分布式表
在分区集群环境下,在创建本地表和分区表时需要添加’on cluster cluster_name’(加此命令会在所有的集群节点上执行创建本地表的命令,不用单独创建)以便同步到所有的数据节点,否则需要再所有的节点上执行相同的建表语句。
on cluster {cluster_name}这个指令使得操作能在集群范围内的节点上都生效。
默认情况下,CREATE、DROP、ALTER 和 RENAME 查询仅影响执行它们的当前服务器
CREATE TABLE database.order_local on cluster cluster01
(
`Operators` String COMMENT '操作人',
`Orderdate` Date COMMENT '订单日期',
`OrderTime` DateTime COMMENT '订单时间',
`CreateTime` DateTime DEFAULT now() COMMENT '创建时间'
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(Orderdate)
ORDER BY (Type, Subtype, Successflag, Province, Operators)
分布式表就是对多个本地表的一个管理,数据写入时分布式表路由到各个本地表进行数据存储,分布式表只是多个本地表的视图。
分布式表依赖于Distributed分布式引擎实现。建表前需要安装该引擎的使用进行配置,下面是创建表语句
CREATE TABLE database.order_local on cluster cluster01
(
`Operators` String COMMENT '操作人',
`Orderdate` Date COMMENT '订单日期',
`OrderTime` DateTime COMMENT '订单时间',
`CreateTime` DateTime DEFAULT now() COMMENT '创建时间'
)
ENGINE = Distrubute(cluster01,database,order_local,rand())
PARTITION BY toYYYYMMDD(Orderdate)
ORDER BY (Type, Subtype, Successflag, Province, Operators)
其中,以上 Distrubute引擎的参数解释如下:
cluster01:集群名称,要根据搭建ck集群的环境配置给出;
database:库名;
order_local:本地表名;
rand():随机函数,表示随机的请求ck所在服务器的机器,做到随机轮询。
5.2:高可用:分布式复制表
复制表:存在单点磁盘,cpu资源受限缺点,有高可用的优点
分布式:存在单点故障问题,数据易丢失缺点,有高性能优点
在查询某个副本时,这个副本宕机了还无法把这个查询自动切换到其他副本查询。需要重新去另外一个未宕机的副本实例上查询那个副本对应的本地复制表。虽然不同副本的数据是一样的,但对用户来说,某个副本宕机了还需要手动切换查询的副本实例。
如果要做到在某个副本宕机时自动切换到其他可用副本,那么就需要结合Distributed分布式表进行使用了。
则可以结合复制表和分布式表形成分布式复制表达到CH数据高可用高性能方案
5.2.1:读写流程
1.写入通过负载均衡策略(分布式引擎的轮询、hash等策略)将数据写入到多个分片的Buffer引擎中
2.Buffer引擎按照设定的触发条件将数据同步到ReplicatedMergeTree引擎中
3.同一分片中,ReplicatedMergeTree引擎直接同步分片数据到副本
4.查询时只需查询任意分片中Distributed引擎,即可获取整个集群所有数据
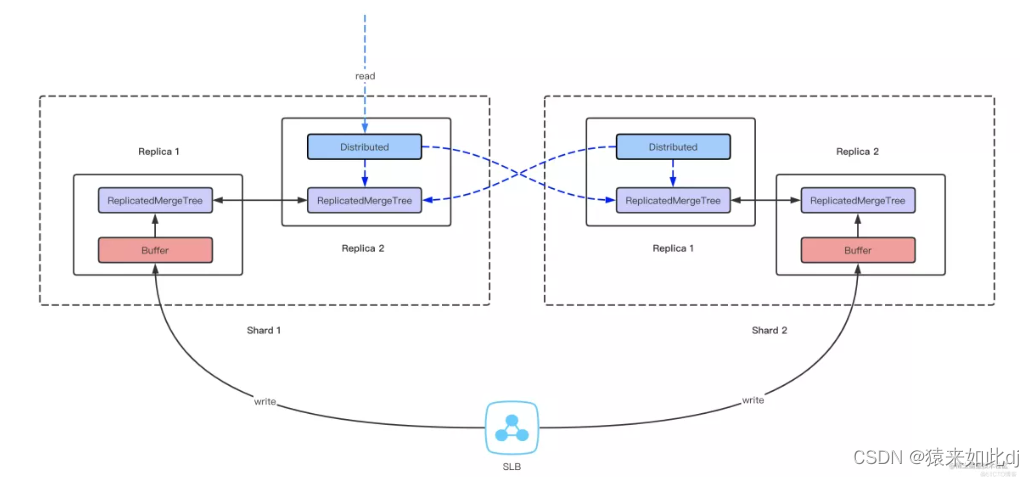
5.2.2:分布式集群搭建实施
ReplicatedMergeTree副本管理机制依赖zookeeper实现。此方案依赖于clickhouse集群完成。
集群搭建主要由3个配置文件
- config.xml (基本配置)
- metrika.xml (集群配置)
- users.xml (用户以及限额相关配置)
集群访问:使用 Distribute 表引擎作为集群的统一访问入口
1、2分片2副本共4节点分布式集群架构
1、集群架构
ClickHouse 分布式集群有 4 个节点(4个服务器),2 个 Shard,副本数为 2。其中节点 example1,example2 属于同一 Shard,互为副本,他们的数据一致。example3,example4 属于同一 Shard。查询时,分布从 2 个 Shard 中随机取一个节点进行访问。其中任何单节点异常时,写入和查询都能保障数据完整性,高可用,业务无感知
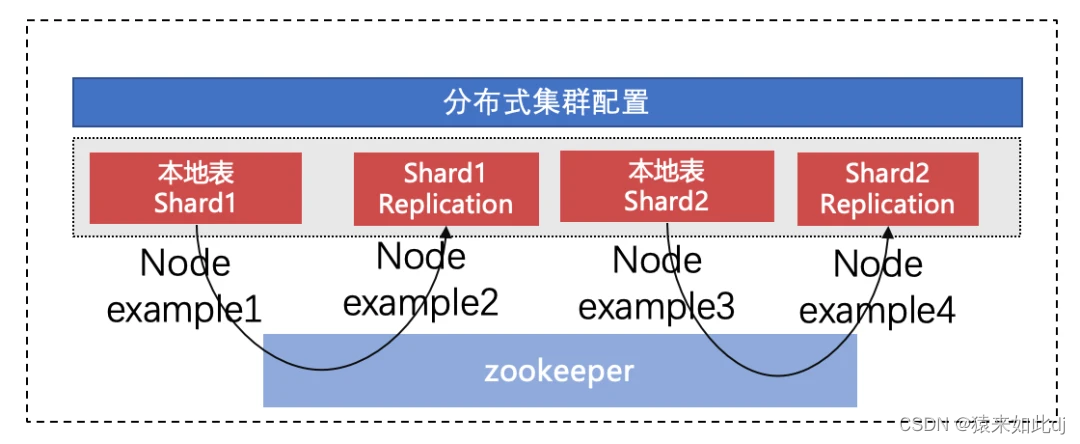
ClickHouse 的分布式也是一个有意思的设计方式,多个节点部署完成后,节点与节点之间并没有联系。通过 ClickHouse 集群的配置文件来实现,即节点与节点之间通过配置文件来形成成集群,配置中包含集群的节点信息,复制节点,分片节点,同构成一个 Cluster

综上可知本地复制表建立时,执行语句R1+R3\R1+R4\R2+R3\R2+R4四种搭配方案(副本间自动复制)。然后建立分布式表把四种方案内的两个分片管理连接起来R1+R3\R1+R4\R2+R3\R2+R4
2、集群配置
有四个节点,example1、example2、example3、example4,可以在 config.xml 中配置,配置文件中搜索 remote_servers,在 remote_servers 内即可配置字集群,也可以提出来配置到扩展文件中。incl 属性表示可从外部文件中获取节点名为 clickhouse_remote_servers 的配置内容。
1、通常,我们采用扩展文件的方式来配置集群,首先,在 config.xml 文件中添加外部扩展配置文件 metrika.xml 的配置信息,在 config.xml 文件中加入以下内容允许使用扩展文件 metrika.xml 来配置信息。
<include_from>/etc/metrika.xml</include_from>
2、然后,在/etc/clickhouse-server 下新建 metrika.xml 文件,进行编辑
<yandex>
<!-- 集群配置 -->
<clickhouse_remote_servers>
<cluster_with_replica> #这是集群的名称,自己可以自定义,同一服务器可以在多个集群中被定义
<shard> #一个shard一组,数据分片1
<internal_replication>true</internal_replication> #副本同步写入方式,复制表true否则false
<replica> #该shard的副本是哪个,可以配置多个
<host>example1</host>
<port>9000</port>
</replica>
<replica>
<host>example2</host>
<port>9000</port>
</replica>
</shard>
<!-- 数据分片2 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>example3</host>
<port>9000</port>
</replica>
<replica>
<host>example4</host>
<port>9000</port>
</replica>
</shard>
</cluster_with_replica>
</clickhouse_remote_servers>
<macros>
<shard>1</shard>
<replica>01</replica>
</macros>
<!-- ZK -->
<zookeeper-servers>
<node index="1">
<host>example1</host>
<port>2181</port>
</node>
<node index="2">
<host>example2</host>
<port>2181</port>
</node>
<node index="3">
<host>example3</host>
<port>2181</port>
</node>
</zookeeper-servers>
<!-- 数据压缩算法 -->
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
Shard 标签里面配置的 replica 互为副本,将 internal_replication 设置成 true,此时写入同一个 Shard 内的任意一个节点的本地表,ZooKeeper 会自动异步的将数据同步到互为副本的另一个节点。
把上面配置复制到各个服务器,形成一个集群(集群名称一样)
3、保存即可,集群会热加载配置文件。
4、开始建表
- 创建本地复制表(引擎是ReplicatedMergeTree),加oncluster {cluster_name} 参数实现只随意在一个节点执行创建表即可。
- 创建分布式表,串联起多个本地复制表(引擎是Distributed。指定数据库和表)
5、数据写入和查询。ClickHouse 提供两个网络端口分别是
HTTP 默认 8123;
TCP 默认 9000;
Distribute 表引擎作为集群的统一访问入口
5.2.3:3服务器6节点(3分片两副本)分布式集群搭建实施
资源有限共3台服务器。部署3分片2副本共6节点分布式集群
Clickhouse “3 分片 2 副本” 的部署模式可以在保障高效查询的同时,开启错误容忍的功能:理论上,三台物理节点搭建的 Clickhouse 3 Shard 2 Replica 集群可以充分并行使用 3 台物理节点的计算资源,同时支持最多 1 台主机的宕机;
相应地,为了进行 Fault Tolerance,本方案会由于每个 Shard 配置了 2 个 Replica,故会额外消耗一倍的存储资源
5.2.3.1:配置文件
由于我们需要在同一台物理节点上启动多个 Clickhouse instance,所以多实例间配置文件存在端口,挂载目录修改的情况。故需要不同的配置文件对配置多个 实例instance。我们复制 Clickhouse 默认的配置文件 config.xml。
1:修改对应端口号: (9000 / 8123 / 9009 端口)
2:修改数据存储目录<logger>改为自己存储的目录,不存在请先创建
3:配置interserver_http_host为本机ip
remote_servers:修改为自己的ip地址,或者服务器名称。
4:<remote_servers>修改集群级配置
<remote_servers>
<production_cluster_3s2r> <!-- The Cluster Name集群名称,在下面配置macros会用 -->
<shard> 同一shard中的多个replica互为副本。
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica> 每个副本的地址ip或名称,配置服务器名称时必须先在/etc/hosts配置:ip name
端口,有密码的还需要配置用户名,密码,密码的shard256。副本配置时和macros中要对应
<priority>1</priority>
<host>p0-lpsm-rf1</host>
<port>9000</port>
</replica>
<replica>
<priority>2</priority>
<host>p0-lpsm-rf2</host>
<port>9100</port>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>false</internal_replication>
<replica>
<priority>1</priority>
<host>p0-lpsm-rf2</host>
<port>9000</port>
</replica>
<replica>
<priority>2</priority>
<host>p0-lpsm-rf3</host>
<port>9100</port>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>false</internal_replication>
<replica>
<priority>1</priority>
<host>p0-lpsm-rf3</host>
<port>9000</port>
</replica>
<replica>
<priority>2</priority>
<host>p0-lpsm-rf1</host>
<port>9100</port>
</replica>
</shard>
</production_cluster_3s2r>
</remote_servers>
5:<macros>对自己所在的分片和副本起名称,共同组成用于标识唯一实例。
和该配置项在 3 个节点上的共计 6 个实例均互不相同。cluster为集群名称
两个相同的shard下的replica组成副本,<replica>名称唯一各不相同。
<macros>
<shard>01</shard>
<replica>01</replica>
<cluster>production_cluster_3s2r</cluster>
</macros>
6:配置zookeeper。多个节点的ip和端口这个所有实例是一样的配置
7:时区配置<timezone>Asia/Shanghai
配置完毕后放到自己实例配置的数据目录下的conf中替换原来的配置文件
启动实例,登录使用。
检查:创建副本表分布式表进行测试ok
5.3:clickhouse的元数据表
clickhouse默认自带了三个数据库
1:default默认为空也是我们一般直接建表使用的数据库
2:system系统数据库,存储clickhouse系统的如表、列、存储空间、用户、集群的元数据信息
其中的parts记录所有表的记录数等元数据信息
3:information_schema
5.3.1:表元数据获取
表元数据获取默认统计为本服务器上的表,需要查询集群表的元数据(如根据分布式引擎建的表)时则统计不准备。
所以:分布式集群进行表数据量统计时可根据本地的system.parts建立分布式表进行统一查询:
步骤:
1:搭建分布式集群
2:根据本地的system.parts建立分布式表
CREATE TABLE default.system_all_parts on cluster clusterName
as system.parts
ENGINE = Distrubute(clusterName,system,parts,rand())
3:创建本地表和分布式进行表元数据查询
此时查询default.system_all_parts会汇聚各个本地的system.parts表中的数据
select * from default.system_all_parts where database='' and table=''
4:但是查询本地表时依旧是system.parts,如果查本地表查询default.system_all_parts可能统计结果不准确(不同服务器的相同库中可能本地表名称一样)
5.4:clickhouse数据备份和异常恢复
尽管副本可以提供针对硬件的错误防护(可用多副本提高容错性,同样也可以使用磁盘阵列实现对数据的容错,不同的是磁盘阵列实现的是同服务器的备份,副本机制本质上是异服务器的备份), 但是它不能预防人为操作失误: 数据的意外删除, 错误表的删除或者错误集群上表的删除, 以及导致错误数据处理或者数据损坏的软件bug. 在很多案例中,这类意外可能会影响所有的副本. ClickHouse 有内置的保护措施可以预防一些错误 — 例如, 默认情况下 不能人工删除使用带有MergeTree引擎且包含超过50Gb数据的表. 但是,这些保护措施不能覆盖所有可能情况,并且这些措施可以被绕过。
可实现的数据备份方案
1:通常摄入到ClickHouse的数据是通过某种持久队列传递的,例如 Apache Kafka.
2:系统自带的FREEZE备份 和ATTACH加载恢复,本次使用第三方工具clickhouse-backup
5.4.1:clickhouse-backup开源方案
工具官网:https://github.com/Altinity/clickhouse-backup
下载安装包
使用前提:
1、这个工具只支持MergeTree 系列表引擎
2、ck的默认数据目录是/var/lib/clickhouse,docker时同样要映射出来,暂未发现修改数据目录的配置项
3、关于表的备份,只是对本地表的备份,分布在多个服务器上的实例进行备份。如果需要对副本表实现备份,则需要在每个分片的第一个副本所在的服务器上安装配置clickhouse-backup。再通过脚本,自己实现api接口或者k8s完成多个服务器的备份调用。
5.4.1.1:安装
方式1、tar包安装上传服务器:解压tar -zxvf clickhouse-backup.tar.gz
cd clickhouse-backup
cp clickhouse-backup /usr/local/bin/ # 将可执行文件复制到/usr/local/bin
mkdir /etc/clickhouse-backup # /etc下创建一个目录,用来放置配置文件config.yml
cp config.yml /etc/clickhouse-backup/
vim /etc/clickhouse-backup # 修改配置文文件
方式2、rpm安装
如果上述安装步骤有问题请下载rpm格式安装包使用rpm进行安装
,此时配置文件会安装到/etc/clickhouse-backup下,clickhouse-backup会自动复制到/usr下
cd /etc/clickhouse-backup
cp config.yml.default cp config.yml
vim /etc/clickhouse-backup # 修改配置文文件
5.4.1.2:配置文件config.yml如下:
general:
remote_storage: sftp # 备份文件上传其他文件系统时的配置,
比如通过sftp,上传到远程服务器的话,需要这个参数,否则为none
max_file_size: 1099511627776
disable_progress_bar: false
backups_to_keep_local: 2 # 本地备份的个数,大于2则自动删除旧的备份,默认为0,不删除备份
backups_to_keep_remote: 2 # 远程备份的个数
log_level: info
allow_empty_backups: false
RESTORE_SCHEMA_ON_CLUSTER:使用“ON CLUSTER”子句作为分布式DDL执行所有与架构相关的SQL查询。
watch_interval:1h#watch\_interval,仅用于`watch`命令,备份将每1h创建一次
full_interval:24h#full\_interval,仅用于`watch`命令,每24小时创建一次完整备份
clickhouse:
username: default # 本地clickhouse的连接参数
password: ""
host: localhost
port: 9010
disk_mapping: {}
skip_tables:
1. system.*
2. db.*
3. information_schema.*
4. INFORMATION_SCHEMA.*
timeout: 5m
freeze_by_part: false
secure: false
skip_verify: false
sync_replicated_tables: true
skip_sync_replica_timeouts: true
log_sql_queries: false
s3:
access_key: ""
secret_key: ""
bucket: ""
endpoint: ""
region: us-east-1
acl: private
force_path_style: false
path: ""
disable_ssl: false
part_size: 536870912
compression_level: 1
compression_format: tar
sse: ""
disable_cert_verification: false
storage_class: STANDARD
gcs:
credentials_file: ""
credentials_json: ""
bucket: ""
path: ""
compression_level: 1
compression_format: tar
cos:
url: ""
timeout: 2m
secret_id: ""
secret_key: ""
path: ""
compression_format: tar
compression_level: 1
api:
listen: localhost:7171 #api开启clickhouse-backup server访问时的地址
enable_metrics: true
enable_pprof: false
username: ""
password: ""
secure: false
certificate_file: ""
private_key_file: ""
create_integration_tables: false
ftp:
address: ""
timeout: 2m
username: ""
password: ""
tls: false
path: ""
compression_format: tar
compression_level: 1
sftp:
address: "host"
port: 端口号
username: "用户名"
password: "密码"
key: ""
path: "/home/data\_dev/clickhouse\_backup" # 上传文件到远程服务器的路径
compression_format: tar
compression_level: 1
azblob:
endpoint_suffix: core.windows.net
account_name: ""
account_key: ""
sas: ""
container: ""
path: ""
compression_level: 1
compression_format: tar
sse_key: ""
5.4.1.3:使用-本地和远程创建备份
clickhouse-backup tables # 查看可以备份的表
clickhouse-backup create # 全库备份,一般这个备份的位置是原clickhouse数据存储路径下新建了一个backup文件夹,这个文件夹下会存备份
clickhouse-backup create -t 数据库.表名1,数据库.表名2 # 多表备份,单表类似
clickhouse-backup list # 查看已经生成的备份,如果设置了remote\_storage: sftp,此条命令还会检测是否成功连接上了远程服务器
clickhouse-backup restore --help # 查看数据恢复相关参数
# 使用scp,将备份上传到服务器上,如果config.yml中设置了sftp,则不需要这一步
scp -rp /var/lib/clickhouse/backup/备份名 name@host:/data/clickhouse-backup/
# 通过配置文件里的sftp上传备份到服务器
clickhouse-backup upload 备份名
- crontab定时备份
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Linux运维工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Linux运维知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)

b定时备份
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Linux运维工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
[外链图片转存中…(img-Kk1AkVMi-1712944942947)]
[外链图片转存中…(img-GqqPfu1j-1712944942948)]
[外链图片转存中…(img-lWjDkpNP-1712944942948)]
[外链图片转存中…(img-iBg6l3Ug-1712944942949)]
[外链图片转存中…(img-z9IfdYYh-1712944942949)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Linux运维知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)
[外链图片转存中…(img-t0w3IThm-1712944942949)]














 2771
2771











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









