







如果你担⼼这个指令会⼤幅抬升 Redis 的 ops ,还可以增加⼀个休眠参数。
redis-cli -h 127.0.0.1 -p 7001 –-bigkeys -i 0.1
每隔 100 条 scan 指令就会休眠 0.1s,ops 就不会剧烈抬升,但是扫描的时间会变⻓。
redis中的OPS 即operation per second 每秒操作次数。意味着每秒对Redis的持久化操作
(二)单线程架构
Redis内部使用单线程架构。Redis一个瞬间只能执行一条命令,不能执行两条命令
Redis单线程速度这么快的原因可大致归结三个:
1.纯内存
Redis把所有的数据都保存在内存中,而内存的响应速度是非常快的
2.非阻塞IO
Redis使用epoll异步非阻塞模型 ,Redis自身实现了事件处理
3.避免线程切换和竞态消耗
在使用多线程编程中,线程之间的切换也会消耗一部分CPU资源,如果不合理的实现多线程编程,可能比单线程还要慢
主要原因是 纯内存。
不过第二条和第三条倒是面试中经常会问到,尤其是第二条。为了便于大家,理解更深刻,我们这里探讨一下操作系统的IO
用户程序进行IO的读写,依赖于底层的IO读写,基本上会用到底层的read&write两大系统调用。
read系统调用,并不是直接从物理设备把数据读取到内存中;write系统调用,也不是直接把数据写入到物理设备。上层应用无论是调用操作系统的read,还是调用操作系统的write,都会涉及缓冲区。具体来说,调用操作系统的read,是把数据从内核缓冲区复制到进程缓冲区;而write系统调用,是把数据从进程缓冲区复制到内核缓冲区。
缓冲区的目的,是为了减少频繁地与设备之间的物理交换。外部设备的直接读写,涉及操作系统的中断。发生系统中断时,需要保存之前的进程数据和状态等信息,而结束中断之后,还需要恢复之前的进程数据和状态等信息。为了减少这种底层系统的时间损耗、性能损耗,于是出现了内存缓冲区。
有了内存缓冲区,上层应用使用read系统调用时,仅仅把数据从内核缓冲区复制到上层应用的缓冲区(进程缓冲区);上层应用使用write系统调用时,仅仅把数据从进程缓冲区复制到内核缓冲区中。底层操作会对内核缓冲区进行监控,等待缓冲区达到一定数量的时候,再进行IO设备的中断处理,集中执行物理设备的实际IO操作,这种机制提升了系统的性能。至于什么时候中断(读中断、写中断),由操作系统的内核来决定,用户程序则不需要关心。
从数量上来说,在Linux系统中,操作系统内核只有一个内核缓冲区。而每个用户程序(进程),有自己独立的缓冲区,叫作进程缓冲区。所以,用户程序的IO读写程序,在大多数情况下,并没有进行实际的IO操作,而是在进程缓冲区和内核缓冲区之间直接进行数据的交换。
有了对操作系统IO的基本认识之后,还要提一下操作系统四种主要的IO模型
同步阻塞IO(Blocking IO)
同步非阻塞IO(Non-blocking IO)
IO多路复用(IO Multiplexing)
异步IO(Asynchronous IO)
Redis的IO模型是IO多路复用,有意思的是Java 的NIO模型,也是IO多路复用(不是同步非阻塞IO)
有兴趣的可以查阅相关的资料,或者不着急的 可以等我接下来的博文(过段日子会有网络编程详解的博文,对IO作深入探究)
这里还要强调一下,由于Redis单线程一次只运行一条命令,我们要拒绝长(慢)命令
keys
flushall
flushdb
slow lua script
mutil/exec
operate
(三)数据结构和内部编码
Redis每种数据结构及对应的内部编码如下图所示
你会发现 数据结构 内部编码方式有不同的方式,其实这是时间换空间 空间换时间的做法,选择何种内部编码要结合实际情况。
(四)字符串
字符串 string 是 Redis 最简单的数据结构。Redis 所有的数据结构都是以唯⼀的 key 字符串作为名称,然后通过这个唯⼀ key 值来获取相应的 value 数据。不同类型的数据结构的差异就在于 value 的结构不⼀样。
字符串的value值类型有三种:1. 字符串;2. 整型;3.二进制。
Redis 的字符串是动态字符串,是可以修改的字符串,内部结构实现上类似于 Java 的 ArrayList,采⽤预分配冗余空间的⽅式来减少内存的频繁分配,当字符串⻓度⼩于 1M时,扩容都是加倍现有的空间,如果超过 1M,扩容时⼀次只会多扩1M 的空间。需要注意的是字符串最⼤⻓度为 512M。
我们看一下它的常用API
1. GET

示例对不存在的键 key 或是字符串类型的键 key 执行 GET 命令:
redis> GET db
(nil)
redis> SET db redis
OK
redis> GET db
“redis”
对不是字符串类型的键 key 执行 GET 命令:
redis> DEL db
(integer) 1
redis> LPUSH db redis mongodb mysql
(integer) 3
redis> GET db
(error) ERR Operation against a key holding the wrong kind of value
2. set

可选参数
从 Redis 2.6.12 版本开始, SET 命令的行为可以通过一系列参数来修改:
EX seconds : 将键的过期时间设置为 seconds 秒。 执行 SET key value EX seconds 的效果等同于执行 SETEX key seconds value 。
PX milliseconds : 将键的过期时间设置为 milliseconds 毫秒。 执行 SET key value PX milliseconds 的效果等同于执行 PSETEX key milliseconds value 。
NX : 只在键不存在时, 才对键进行设置操作。 执行 SET key value NX 的效果等同于执行 SETNX key value 。
XX : 只在键已经存在时, 才对键进行设置操作。
关于返回值
在 Redis 2.6.12 版本以前, SET 命令总是返回 OK 。
从 Redis 2.6.12 版本开始, SET 命令只在设置操作成功完成时才返回 OK ; 如果命令使用了 NX 或者 XX 选项, 但是因为条件没达到而造成设置操作未执行, 那么命令将返回空批量回复(NULL Bulk Reply)。
3. INCR
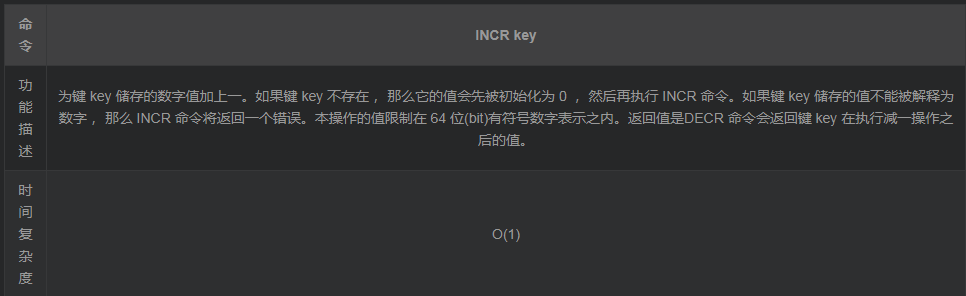
对储存数字值的键 key 执行 DECR 命令:
redis> SET page_view 20
OK
redis> INCR page_view
(integer) 21
redis> GET page_view # 数字值在 Redis 中以字符串的形式保存
“21”
对不存在的键执行 DECR 命令:
redis> EXISTS count
(integer) 0
redis> DECR count
(integer) -1
4. DECR
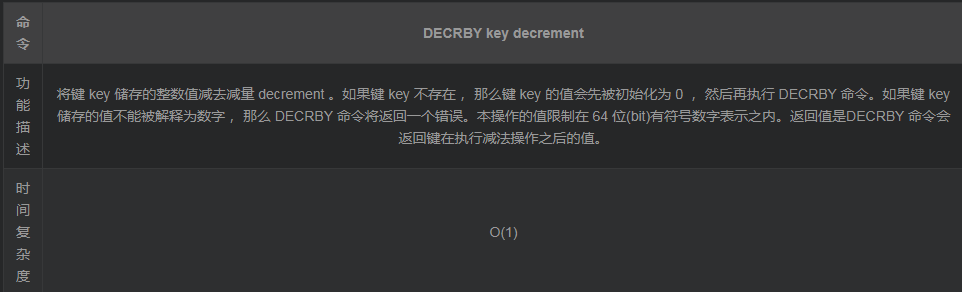
对已经存在的键执行 DECRBY 命令:
redis> SET count 100
OK
redis> DECRBY count 20
(integer) 80
对不存在的键执行 DECRBY 命令:
redis> EXISTS pages
(integer) 0
redis> DECRBY pages 10
(integer) -10
5. INCRBY
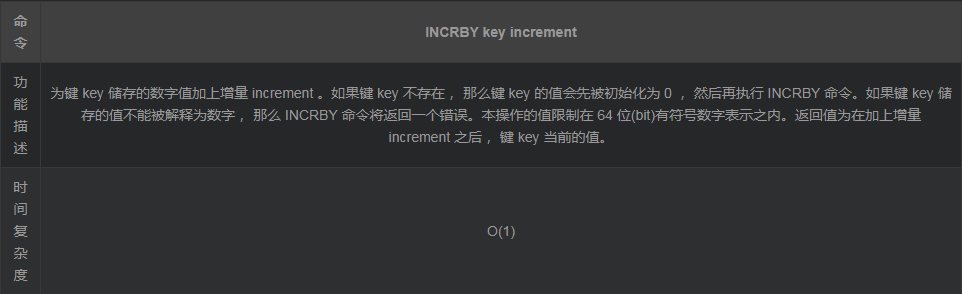
示例演示与上面类似
6. DECRBY
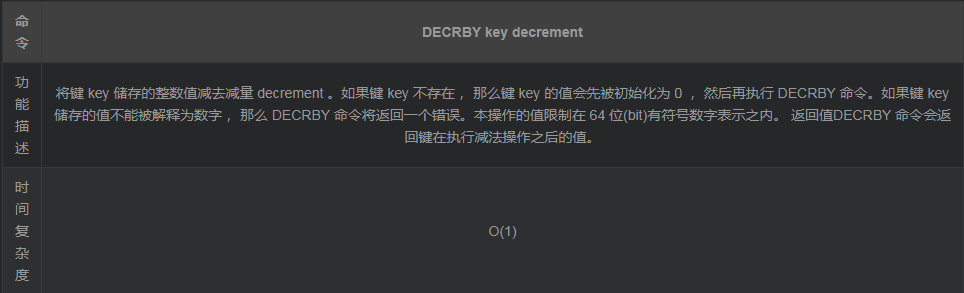
示例演示与上面类似
使用上面这一些命令,其实我们就可以做一些事情了。
应用
1.比如说记录每个用户博文的访问量
incr userid:pageview(单线程:无竞争)
2.缓存用户的基本信息(数据源在 MySQL中),信息被序列化存放在value中。
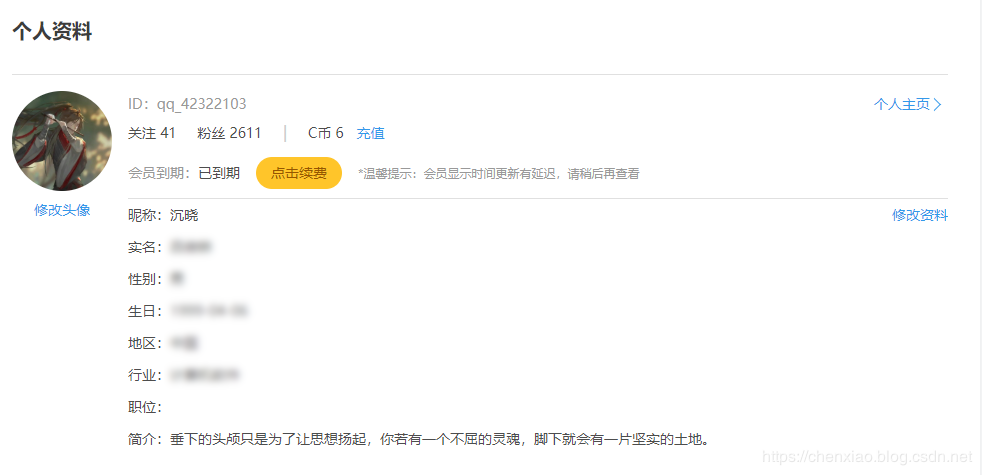
一般而言,需要通过我们自定义规则的key,从Redis获取value,如果key存在的话,则直接获取value使用;如果不存在的话,从Mysql中读取使用,然后存在Redis中。
主要的命令是 get 和 set
3.分布式id生成器
如果集群规模和运算不太复杂的话,可以用Redis生成分布式id,因为Redis单线程的特点,一次只执行一条指令,保证了id值的唯一。
主要的命令还是incr
7. SETNX

redis> EXISTS job # job 不存在
(integer) 0
redis> SETNX job “programmer” # job 设置成功
(integer) 1
redis> SETNX job “code-farmer” # 尝试覆盖 job ,失败
(integer) 0
redis> GET job # 没有被覆盖
“programmer”
8. SETEX

SETEX 命令的效果和以下两个命令的效果类似:
SET key value
EXPIRE key seconds # 设置生存时间
SETEX 和这两个命令的不同之处在于 SETEX 是一个原子(atomic)操作, 它可以在同一时间内完成设置值和设置过期时间这两个操作, 因此 SETEX 命令在储存缓存的时候非常实用。
这两个命令的典型应用就是分布式锁了。
⽐如⼀个操作要修改⽤户的状态,修改状态需要先读出⽤户的状态,在内存⾥进⾏修改,改完了再存回去。如果这样的操作同时进⾏了,就会出现并发问题。这个时候就要使⽤到分布式锁来限制程序的并发执⾏。Redis 分布式锁使⽤⾮常⼴泛,必须要掌握。
分布式锁本质上要实现的⽬标就是在 Redis ⾥⾯占⼀个“位置”,当别的进程也要来占时,发现“位置”被占了,就只好放弃或者稍后
再试。
占位置⼀般是使⽤ setnx(set if not exists) 指令,只允许被⼀个客户端占据。先来先占,⽤完了,再调⽤ del 指令释放位置。
如果逻辑执⾏到中间出现异常了,可能会导致 del指令没有被调⽤,这样就会陷⼊死锁,锁永远得不到释放。于是我们在拿到锁之后,再给锁加上⼀个过期时间。
但如果在 setnx 和 expire 之间服务器进程突然挂掉了,可能是因为机器掉电或者是被⼈为杀掉的,就会导致expire 得不到执⾏,也会造成死锁。
原因是 setnx 和 expire 是两条指令⽽不能保证都一定成功执行。如果这两条指令可以⼀起执⾏就不会出现问题(要么成功,要么失败)。所以说setex是最佳的方案
上面就是分布式锁的基本思想。但是在真正投入使用的时候,还会面临一个常见的问题:超时问题
Redis 的分布式锁不能解决超时问题,如果在加锁和释放锁之间的逻辑执⾏的时间太⻓,超出了锁的超时限制,就会出现问题。这时候第⼀个线程持有的锁过期了,临界区的逻辑没有执⾏完,而第⼆个线程就提前重新持有了这把锁,导致临界区代码不能严格地串⾏执⾏。
为了避免这个问题,Redis 分布式锁不要⽤于较⻓时间的任务。
我们会在下篇文章,也就是分布式章节继续探讨分布式锁。
9. MSET

同时对多个键进行设置:
redis> MSET date “2012.3.30” time “11:00 a.m.” weather “sunny”
OK
redis> MGET date time weather
-
“2012.3.30”
-
“11:00 a.m.”
-
“sunny”
覆盖已有的值:
redis> MGET k1 k2
-
“hello”
-
“world”
redis> MSET k1 “good” k2 “bye”
OK
redis> MGET k1 k2
-
“good”
-
“bye”
10 . MGET

redis> SET redis redis.com
OK
redis> SET mongodb mongodb.org
OK
redis> MGET redis mongodb
-
“redis.com”
-
“mongodb.org”
redis> MGET redis mongodb mysql # 不存在的 mysql 返回 nil
-
“redis.com”
-
“mongodb.org”
-
(nil)
下面说说mset和mget的好处
不使用mget和mset::
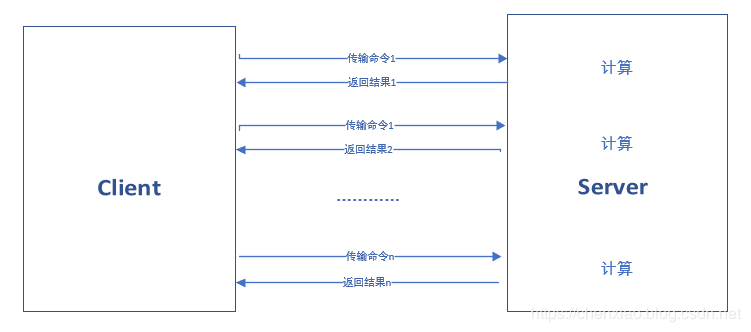
客户端和服务器端可能不在同一个地方n次get/set=n次网络时间+n次命令时间
一次mget/mset:
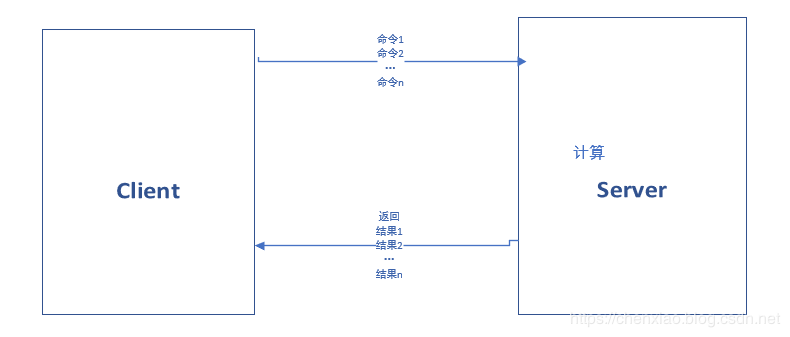
1次mget/mset=1次网络时间+n次命令时间
随着n的增大,差距一下子就体现出来了。
下面的命令不太常用,大体过一下:
10. GETSET
GETSET key value
将键 key 的值设为 value , 并返回键 key 在被设置之前的旧值。
11. STRLEN
STRLEN key
返回键 key 储存的字符串值的长度
12. APPEND
APPEND key value
如果键 key 已经存在并且它的值是一个字符串, APPEND 命令将把 value 追加到键 key 现有值的末尾。
13. INCRBYFLOAT
INCRBYFLOAT key increment
为键 key 储存的值加上浮点数增量 increment 。
如果键 key 不存在, 那么 INCRBYFLOAT 会先将键 key 的值设为 0 , 然后再执行加法操作。
如果命令执行成功, 那么键 key 的值会被更新为执行加法计算之后的新值, 并且新值会以字符串的形式返回给调用者。
无论是键 key 的值还是增量 increment , 都可以使用像 2.0e7 、 3e5 、 90e-2 那样的指数符号(exponential notation)来表示, 但是, 执行 INCRBYFLOAT 命令之后的值总是以同样的形式储存, 也即是, 它们总是由一个数字, 一个(可选的)小数点和一个任意长度的小数部分组成(比如 3.14 、 69.768 ,诸如此类), 小数部分尾随的 0 会被移除, 如果可能的话, 命令还会将浮点数转换为整数(比如 3.0 会被保存成 3 )。
此外, 无论加法计算所得的浮点数的实际精度有多长, INCRBYFLOAT 命令的计算结果最多只保留小数点的后十七位。
当以下任意一个条件发生时, 命令返回一个错误:
键 key 的值不是字符串类型(因为 Redis 中的数字和浮点数都以字符串的形式保存,所以它们都属于字符串类型);
键 key 当前的值或者给定的增量 increment 不能被解释(parse)为双精度浮点数。
14. GETRANGE
GETRANGE key start end
返回键 key 储存的字符串值的指定部分, 字符串的截取范围由 start 和 end 两个偏移量决定 (包括 start 和 end 在内)。
负数偏移量表示从字符串的末尾开始计数, -1 表示最后一个字符, -2 表示倒数第二个字符, 以此类推。
GETRANGE 通过保证子字符串的值域(range)不超过实际字符串的值域来处理超出范围的值域请求。
15. SETRANGE
SETRANGE key offset value
从偏移量 offset 开始, 用 value 参数覆写(overwrite)键 key 储存的字符串值。
不存在的键 key 当作空白字符串处理。
SETRANGE 命令会确保字符串足够长以便将 value 设置到指定的偏移量上, 如果键 key 原来储存的字符串长度比偏移量小(比如字符串只有 5 个字符长,但你设置的 offset 是 10 ), 那么原字符和偏移量之间的空白将用零字节(zerobytes, “\x00” )进行填充。
因为 Redis 字符串的大小被限制在 512 兆(megabytes)以内, 所以用户能够使用的最大偏移量为 2^29-1(536870911) , 如果你需要使用比这更大的空间, 请使用多个 key 。
在对字符串类型有了整体的了解之后,我们看看它具体的结构
Redis 的字符串名字是SDS(Simple Dynamic String)。它的结构是⼀个带⻓度信息的字节数组。
struct SDS {
T capacity; // 数组容量
T len; // 数组⻓度
byte flags; // 特殊标识位,不理睬它
byte[] content; // 数组内容
}
capacity 表示所分配数组的⻓度,len 表示字符串的实际⻓度。前⾯API提到⽀持 append操作(字符串是可修改的)。如果数组没有冗余空间,那么追加操作必然涉及到分配新数组,然后将旧内容复制过来,再 append 新内容。如果字符串的⻓
度⾮常⻓,这样的内存分配和复制开销就会⾮常⼤。
/* Append the specified binary-safe string
pointed by ‘t’ of ‘len’ bytes to the
- end of the specified sds string ‘s’
.
- After the call, the passed sds string is no
longer valid and all the
- references must be substituted with the new
pointer returned by the call.
*/
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s); // 原字符串⻓度
// 按需调整空间,如果 capacity 不够容纳追加的内容,就会重新分配字节数组并复制原字符串的内容到新数组中
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL; // 内存不⾜
memcpy(s+curlen, t, len); // 追加⽬标字符串的内容到字节数组中
sdssetlen(s, curlen+len); // 设置追加后的⻓度值
s[curlen+len] =‘\0’; // 让字符串以\0 结尾,便于调试打印,还可以直接使⽤ glibc 的字符串函数进⾏操作
return s;
}
上⾯的 SDS 结构使⽤了范型 T,这是Redis 对内存做出的优化,不同⻓度的字符串使⽤不同的结构体来表示,字符串⽐较短时,len 和 capacity 可以使⽤ byte 和 short来表示。
Redis 规定字符串的⻓度不得超过 512M 字节。创建字符串时 len和 capacity ⼀样⻓,不会多分配冗余空间,这是因为绝⼤多数场景下我们不会使⽤ append 操作来修改字符串。
(五)hash (字典)
Redis 的字典结构为数组 +链表⼆维结构。第⼀维 hash 的数组位置碰撞时,就会将碰撞的元素使⽤链表串接起来。Redis 的字典的值只能是字符串。当字典很大的时候,会进行rehash,Redis 为了⾼性能,不能堵塞服务,采⽤了渐进式 rehash 策略。
渐进式 rehash 保留新旧两个 hash 结构,查询时会同时查询两个 hash 结构,然后在后续的定时任务中以及hash 操作指令中,循序渐进地将旧 hash 的内容⼀点点迁移到新的hash 结构中。当搬迁完成了,就会使⽤新的hash结构取⽽代之。当 hash 移除了最后⼀个元素之后,该数据结构⾃动被删除,内存被回收。
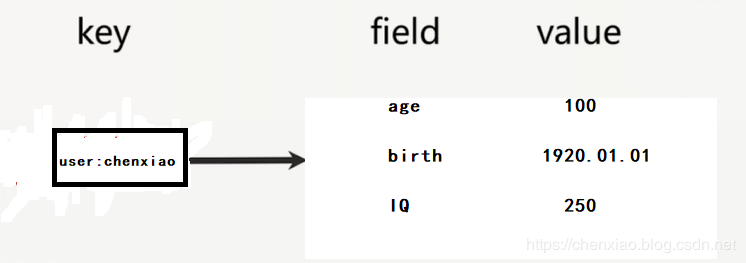
下面我们看一下它的API, 所有hash的命令都是h开头
1. HSET hash field value
时间复杂度: O(1)
将哈希表 hash 中域 field 的值设置为 value 。如果给定的哈希表并不存在, 那么一个新的哈希表将被创建并执行 HSET 操作。如果域 field 已经存在于哈希表中, 那么它的旧值将被新值 value 覆盖。当 HSET 命令在哈希表中新创建 field 域并成功为它设置值时, 命令返回 1 ; 如果域 field 已经存在于哈希表, 并且 HSET 命令成功使用新值覆盖了它的旧值, 那么命令返回 0 。
设置一个新域:
redis> HSET website google “www.g.cn”
(integer) 1
redis> HGET website google
“www.g.cn”
对一个已存在的域进行更新:
redis> HSET website google “www.google.com”
(integer) 0
redis> HGET website google
“www.google.com”
2.HGET hash field
时间复杂度: O(1)
返回哈希表中给定域的值。HGET 命令在默认情况下返回给定域的值。如果给定域不存在于哈希表中, 又或者给定的哈希表并不存在, 那么命令返回 nil 。
域存在的情况:
redis> HSET homepage redis redis.com
(integer) 1
redis> HGET homepage redis
“redis.com”
域不存在的情况:
redis> HGET site mysql
(nil)
3.HDEL
HDEL key field [field …]
O(N), N 为要删除的域的数量。
删除哈希表 key 中的一个或多个指定域,不存在的域将被忽略。返回值为被成功移除的域的数量,不包括被忽略的域。
测试数据
redis> HGETALL abbr
-
“a”
-
“apple”
-
“b”
-
“banana”
-
“c”
-
“cat”
-
“d”
-
“dog”
删除单个域
redis> HDEL abbr a
(integer) 1
删除不存在的域
redis> HDEL abbr not-exists-field
(integer) 0
删除多个域
redis> HDEL abbr b c
(integer) 2
redis> HGETALL abbr
-
“d”
-
“dog”
4. HSETNX hash field value
时间复杂度: O(1)
当且仅当域 field 尚未存在于哈希表的情况下, 将它的值设置为 value 。如果给定域已经存在于哈希表当中, 那么命令将放弃执行设置操作。如果哈希表 hash 不存在, 那么一个新的哈希表将被创建并执行 HSETNX 命令。HSETNX 命令在设置成功时返回 1 , 在给定域已经存在而放弃执行设置操作时返回 0 。
域尚未存在, 设置成功:
redis> HSETNX database key-value-store Redis
(integer) 1
redis> HGET database key-value-store
“Redis”
域已经存在, 设置未成功, 域原有的值未被改变:
redis> HSETNX database key-value-store Riak
(integer) 0
redis> HGET database key-value-store
“Redis”
5. HLEN
时间复杂度:O(1)
返回哈希表 key 中域的数量。当 key 不存在时,返回 0 。
redis> HSET db redis redis.com
(integer) 1
redis> HSET db mysql mysql.com
(integer) 1
redis> HLEN db
(integer) 2
redis> HSET db mongodb mongodb.org
(integer) 1
redis> HLEN db
(integer) 3
6.HMSET
HMSET key field value [field value …]
时间复杂度:O(N), N 为 field-value 对的数量。
同时将多个 field-value (域-值)对设置到哈希表 key 中。此命令会覆盖哈希表中已存在的域。如果 key 不存在,一个空哈希表被创建并执行 HMSET 操作。如果命令执行成功,返回 OK 。当 key 不是哈希表(hash)类型时,返回一个错误。
redis> HMSET website google www.google.com yahoo www.yahoo.com
OK
redis> HGET website google
“www.google.com”
redis> HGET website yahoo
“www.yahoo.com”
7. HMGET
HMGET key field [field …]
时间复杂度:O(N), N 为给定域的数量。
返回哈希表 key 中,一个或多个给定域的值。
如果给定的域不存在于哈希表,那么返回一个 nil 值。因为不存在的 key 被当作一个空哈希表来处理,所以对一个不存在的 key 进行 HMGET 操作将返回一个只带有 nil 值的表。具体返回一个包含多个给定域的关联值的表,表值的排列顺序和给定域参数的请求顺序一样。
redis> HMSET pet dog “doudou” cat “nounou” # 一次设置多个域
OK
redis> HMGET pet dog cat fake_pet # 返回值的顺序和传入参数的顺序一样
-
“doudou”
-
“nounou”
-
(nil) # 不存在的域返回nil值
8.HINCRBY
HINCRBY key field increment
时间复杂度:O(1)
为哈希表 key 中的域 field 的值加上增量 increment 。增量也可以为负数,相当于对给定域进行减法操作。如果 key 不存在,一个新的哈希表被创建并执行 HINCRBY 命令。如果域 field 不存在,那么在执行命令前,域的值被初始化为 0 。对一个储存字符串值的域 field 执行 HINCRBY 命令将造成一个错误。本操作的值被限制在 64 位(bit)有符号数字表示之内。执行 HINCRBY 命令之后,返回值哈希表 key 中域 field 的值。
increment 为正数
redis> HEXISTS counter page_view # 对空域进行设置
(integer) 0
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024b (备注Java)

惊喜
最后还准备了一套上面资料对应的面试题(有答案哦)和面试时的高频面试算法题(如果面试准备时间不够,那么集中把这些算法题做完即可,命中率高达85%+)


一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

HINCRBY
HINCRBY key field increment
时间复杂度:O(1)
为哈希表 key 中的域 field 的值加上增量 increment 。增量也可以为负数,相当于对给定域进行减法操作。如果 key 不存在,一个新的哈希表被创建并执行 HINCRBY 命令。如果域 field 不存在,那么在执行命令前,域的值被初始化为 0 。对一个储存字符串值的域 field 执行 HINCRBY 命令将造成一个错误。本操作的值被限制在 64 位(bit)有符号数字表示之内。执行 HINCRBY 命令之后,返回值哈希表 key 中域 field 的值。
increment 为正数
redis> HEXISTS counter page_view # 对空域进行设置
(integer) 0
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
[外链图片转存中…(img-1h6cRk2a-1712763034821)]
[外链图片转存中…(img-80Nplqd4-1712763034822)]
[外链图片转存中…(img-0ZuA4LjN-1712763034822)]
[外链图片转存中…(img-s0xKdrwn-1712763034822)]
[外链图片转存中…(img-LNz7Tyfz-1712763034823)]
[外链图片转存中…(img-Dnvg2Lq5-1712763034823)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-eDK26Rv9-1712763034823)]
惊喜
最后还准备了一套上面资料对应的面试题(有答案哦)和面试时的高频面试算法题(如果面试准备时间不够,那么集中把这些算法题做完即可,命中率高达85%+)
[外链图片转存中…(img-QbieBuaK-1712763034824)]
[外链图片转存中…(img-f2YCztzz-1712763034824)]
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-V7MfPSlb-1712763034824)]
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









