







第二代 RocketMQ 在服务于交易场景基础上开始探索自研存储引擎,这个版本采用了拉模式和自研的专有消息存储,在日志处理方面能够媲美 Kafka 的吞吐性能。
在前两代初步打磨了自研的存储引擎后, RocketMQ 3.0 的重构前瞻性地去除了 ZooKeeper 等组件的外部依赖,并支持了单机海量 Topic。而刚好在前不久,我们也报道过消息系统 Kafka 去除 ZooKeeper 依赖。
第四代 RocketMQ 在高可靠低延迟方面重点优化,构建了全新的低延迟存储引擎、新增了 Raft 多副本存储能力、提供了丰富的消息特性。
RocketMQ 架构演进的思考
目前社区开发者对 RocketMQ 的诉求来自于三个方面:首先,RocketMQ 如何更方便地与云原生生态整合是开发者最为关心的问题;其次,在流计算场景里,社区对 RocketMQ 的吞吐能力提出了更高的要求,企业客户也一直希望就近处理流转在 RocketMQ 系统中的如支付、交易等高价值的业务数据;还有一类则是在企业集成过程中,希望 RocketMQ 能提供更多 connector 帮助用户构建企业数据流转中心。
伴随如今企业全面上云以及云原生的兴起,新一代基础架构必须朝着云原生化演进,RocketMQ 在 5.0 里面提供了可分可合的存储计算分离架构以顺应这一趋势。
通过可分可合的存储计算分离架构,用户可以同一进程启动存储和计算的功能,也可以将两者分开部署。分开部署后的计算节点可以做到“无状态”,一个接入点可代理所有流量,在云上结合新硬件内核旁路技术,可以降低分离部署带来的性能及延迟问题。而选择“存储计算一体化”架构,同时也能契合“就近计算”的趋势,也就是在最靠近数据的地方做计算。
林清山表示新版本在存储计算分离的架构选择上非常慎重:“首先我们认为在云上多租、多 VPC、多种接入方式的场景下是非常有必要的,存储计算分离后能够避免后端存储服务直接暴露给客户端,便于实现流量的管控、隔离、调度、权限管理。”
但是有利必有弊,除了带来延迟的上升、成本的增加以外,存储计算分离也会给线上运维带来巨大挑战。在大多数场景下,用户更希望的还是存储计算一体化的架构,开箱即用、性能高、延迟低、运维轻松,尤其是在大数据场景下,能够极大降低机器及流量成本。其实这个问题本质上还是由消息产品的特性决定的,消息相比于数据库,计算逻辑相对简单,拆分后往往会沦为无计算场景可发挥、存储节点也得不到简化的状态,这个从 Kafka 的架构演进也可以得到印证。”
“存储计算分离只是适应了部分场景,架构的演进还是要回归到客户的真实场景。”
面向多场景的弹性架构
在 4.0 版本中,RocketMQ 主要由 NameServer、Broker、Producer 以及 Consumer 四部分构成。Producer 和 Consumer 由用户进行分布式部署。NameServer 以轻量级的方式提供服务发现和路由功能,每个 NameServer 存有全量的路由信息,提供对等的读写服务,支持快速扩缩容。Broker 负责消息存储,以 Topic 为纬度支持轻量级的队列,单机可以支撑上万队列规模。
在 5.0 版本中,对系统中的不同服务进行了解耦,比如 Nameserver 和 Broker,设计为以下架构:

图中借用了 Service Mesh 关于控制和数据面的划分思想以及 xDS 的概念来描述各个组件的职责。
-
全新轻量级 SDK,基于 gRPC 协议重新打造的一批多语言客户端,采取 gRPC 的主要考虑其在云原生时代的标准性、兼容性以及多语言传输层代码的生成能力。
-
导航服务(Navigation Server),这是个可选组件,通过 LB Group 暴露给客户端。客户端通过导航服务获取数据面的接入点信息(Endpoint),随后通过计算集群 CBroker 的 LB Group 进行消息的收发。通过 EDS 暴露 CBroker 的接入点信息的方式比通过 DNS 解析的负载均衡更加智能且可以更精细实现流量控制等逻辑。
-
NameServer,RocketMQ 原有的核心组件,主要提供 SBroker 的集群发现(CDS),存储单元 Topic 的路由发现(RDS)等,为运维控制台组件、用户控制台组件、计算集群 CBroker 提供 xDS 服务。
-
Compute-Broker(CBroker),重构版本后抽象出的无状态计算集群,作为数据流量的入口,提供鉴权与签名、上层计量统计、资源管理、客户端连接管理、消费者管控治理、客户端 RPC 处理、消息编解码处理、流量控制、多协议支持等。
-
Storage-Broker(SBroker),重构后下沉的存储节点,专注于提供极具竞争力的高性能、低延迟的存储服务。
-
LB Group,根据用户的需求提供多样化的负载均衡接入能力。
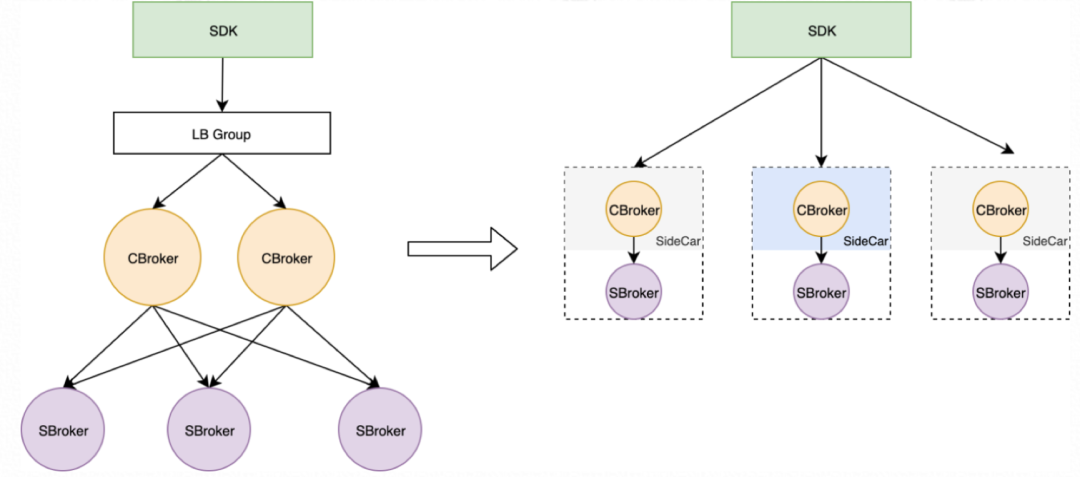
但存储计算一体化在很多场景下依然是最佳选择,因此,RocketMQ 在 5.0 为存储计算分离架构提供了灵活的选择:可分可合。如上图所示,左边是一个分离部署的形态,右边是合并部署的形态,合并部署时计算节点可以作为存储节点的 SideCar,采用网格的思想部署,也可以将计算和存储揉进同一个进程部署。
在云原生架构设计中,我们常听到要让基础设施完全解耦,这意味着可以让用户在任意的基础设施上部署交付。现在公有云、专有云、混合云、多云下的基础设施均不相同,以存储为例,可能有云盘,也有可能是本地盘;以网络为例,可能是经典网络,也有可能是多 VPC 网络… 这样的环境要求对于基础服务的云原生架构设计是一个非常大的挑战。所以,RocketMQ 5.0 架构的重塑,很重要的改变是在不同的应用场景下都能提供极致的弹性和统一的架构,“我们称之为场景多元化”,RocketMQ 创始人誓嘉表示。
举例来说,使用 RocketMQ 可以自由选择私有化多副本部署方式或者利用公共云云盘的方式,后者既能提升性能又能降低硬件成本及运维成本,也带来了更高的弹性能力。在对一致性要求非常高且需要主从自动切换能力的场景,Raft 又可以保证数据可靠性、业务可用性。同时,RocketMQ 还支持多元索引,可以基于一份原始数据构建多份索引来满足不同的业务场景,包括消费索引、查询索引、批索引、百万队列索引等,以便在同一套架构支撑着不同行业的各种差异化诉求。
2融合“消息、事件、流”于一体
拥抱 Flink 生态的轻量级流处理平台
目前业界有两个发展态势,一个是不可阻挡的云原生改造趋势,另一个是流计算时代的全面兴起。因此,除提供对云原生的支持外,作为业界首个兼容 Flink 生态的消息产品,RocketMQ 5.0 这个大版本里面提供了 rocketmq-streams 实时计算框架, 目前已经在 Apache 社区开源。
作为一套全新的流式处理框架,rocketmq-streams 依赖少、部署简单,可任意横向扩展,利用 RocketMQ 资源即可完成轻量级的数据处理和计算。除此以外,为了方便开发者让基于 RocketMQ 的流式计算更容易,后续还会开源 rsqlDB,为开发者提供基于 SQL 的开发体验。
在 Streaming 领域,与 Kafka 只是作为 Flink 的上下游数据不同,RocketMQ 会全面拥抱 Flink 开源生态。RocketMQ-flink connector 将在近期从社区毕业,相比于 Kafka-flink connector,RocketMQ 实现了最新的 FLIP-27/FLIP-143 接口,能够为开发者提供更一致的流批一体实时数据处理体验。
更为重要的是,与其他任何消息产品不同,rsqlDB 首创性地兼容了 Flink/Blink SQL 标准以及 UDF/UDAF/UDTF,使得两个开源产品的生态可以更好地融合,开发者可以将 Flink/Blink 已有 SQL 计算任务迁移到 RocketMQ ,在 RocketMQ 内部完成轻量级的计算处理,在算力受限或者更大规模的场景下,同样可以将 RocketMQ 的实时计算任务迁移到 Flink,利用 Flink 的大数据计算能力满足业务诉求。
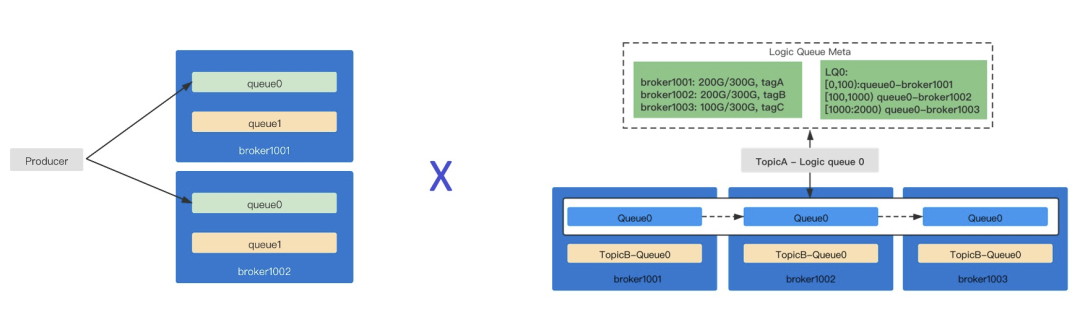
另外,RocketMQ 4.x 的设计里,用户的消息分布在 Topic 内的多个队列上,但这些队列都是和物理节点内的索引文件一一对应。这样的设计虽然能够保证单机范围内万级队列的高效读写,但也导致了运维不灵活的问题,即 RocketMQ 的存储物理节点扩缩容时,用户 Topic 内的队列数量就会产生变化。众所周知,在流式数据处理过程中上层业务一般要求存储队列始终固定,同时还要求在底层节点运维过程中物理节点的变化对上层队列是透明的,只有这样才能保证流式数据处理的顺序性和完整性。
RocketMQ 5.0 将消息队列下沉为物理队列,上层重新抽象了逻辑队列。一个逻辑队列可以包含多个物理队列,各个物理队列都作为逻辑队列的一个片段,以此拼接出真正的流式队列。也因此可以做到更轻量,秒级扩缩,在物理节点发生变化时不涉及到存量数据复制迁移;实现数据存储的灵活调度,配合 TTL 实现无限存储能力。
RocketMQ 5.0 通过全新设计实现的 Streaming 计算框架以及对 Streaming 场景的逻辑队列存储优化,使得 RocketMQ 快速具备了完善的流式数据计算能力和兼容 Flink 的 SQL 计算能力,所以这个版本绝对算得上是一次里程碑式的发布。
消息系统的未来:事件流
另一方面,“基于云厂商的视角,我们判断在企业全面上云的时代,事件驱动又会重新发挥作用”,林清山表示。
总结
谈到面试,其实说白了就是刷题刷题刷题,天天作死的刷。。。。。
为了准备这个“金三银四”的春招,狂刷一个月的题,狂补超多的漏洞知识,像这次美团面试问的算法、数据库、Redis、设计模式等这些题目都是我刷到过的
并且我也将自己刷的题全部整理成了PDF或者Word文档(含详细答案解析)

66个Java面试知识点
架构专题(MySQL,Java,Redis,线程,并发,设计模式,Nginx,Linux,框架,微服务等)+大厂面试题详解(百度,阿里,腾讯,华为,迅雷,网易,中兴,北京中软等)

算法刷题(PDF)

Linux,框架,微服务等)+大厂面试题详解(百度,阿里,腾讯,华为,迅雷,网易,中兴,北京中软等)**
[外链图片转存中…(img-d3OHZZPv-1714442909894)]
算法刷题(PDF)
[外链图片转存中…(img-qJxxWxbX-1714442909894)]














 247
247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









