







最后
ActiveMQ消息中间件面试专题
- 什么是ActiveMQ?
- ActiveMQ服务器宕机怎么办?
- 丢消息怎么办?
- 持久化消息非常慢怎么办?
- 消息的不均匀消费怎么办?
- 死信队列怎么办?
- ActiveMQ中的消息重发时间间隔和重发次数吗?
ActiveMQ消息中间件面试专题解析拓展:

redis面试专题及答案
- 支持一致性哈希的客户端有哪些?
- Redis与其他key-value存储有什么不同?
- Redis的内存占用情况怎么样?
- 都有哪些办法可以降低Redis的内存使用情况呢?
- 查看Redis使用情况及状态信息用什么命令?
- Redis的内存用完了会发生什么?
- Redis是单线程的,如何提高多核CPU的利用率?

Spring面试专题及答案
- 谈谈你对 Spring 的理解
- Spring 有哪些优点?
- Spring 中的设计模式
- 怎样开启注解装配以及常用注解
- 简单介绍下 Spring bean 的生命周期
Spring面试答案解析拓展

高并发多线程面试专题
- 现在有线程 T1、T2 和 T3。你如何确保 T2 线程在 T1 之后执行,并且 T3 线程在 T2 之后执行?
- Java 中新的 Lock 接口相对于同步代码块(synchronized block)有什么优势?如果让你实现一个高性能缓存,支持并发读取和单一写入,你如何保证数据完整性。
- Java 中 wait 和 sleep 方法有什么区别?
- 如何在 Java 中实现一个阻塞队列?
- 如何在 Java 中编写代码解决生产者消费者问题?
- 写一段死锁代码。你在 Java 中如何解决死锁?
高并发多线程面试解析与拓展

jvm面试专题与解析
- JVM 由哪些部分组成?
- JVM 内存划分?
- Java 的内存模型?
- 引用的分类?
- GC什么时候开始?
JVM面试专题解析与拓展!

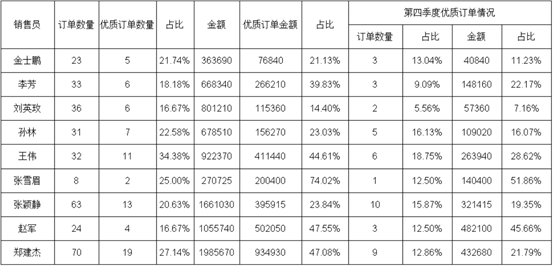
还是基于这个数据表,我们做个一个格式再复杂一些的表样
按销售人员统计优质订单的情况,优质订单指:回款日期在订单日期30日内且单笔订单金额>=10000
制作过程
数据集设置
ds1:select order_date,price,amount,name,re_date from orderlist where substr(order_date,0,4)=‘2012’
报表模板设计

A3:=ds1.group(NAME;NAME:1),可以鼠标拖拽,也可以手动输入
B3:=ds1.count()
C3:=ds1.count(price*amount>=10000 and interval(ORDER_DATE,RE_DATE)<=30)
D3:=C3/B3,设置显示格式为“#0.00%”
E3:=ds1.sum(PRICE*amount)
F3:=ds1.sum(PRICE*amount,price*amount>=10000 and interval(ORDER_DATE,RE_DATE)<=30),条件表达式和C3一样,可以在=ds1.sum(PRICE*amount)基础上,直接将条件表达式复制过来
G3:将D3直接复制到G3,单元格引用名称自动变化,显示格式保留
H3:=ds1.count(price*amount>=10000 and interval(ORDER_DATE,RE_DATE)<=30 and month(ORDER_DATE)>=10 and month(ORDER_DATE)<=12),在C3的基础上增加季度判断条件
I3:=H3/B3,设置显示格式为“#0.00%”
J3:=ds1.sum(PRICE*amount,price*amount>=10000 and interval(ORDER_DATE,RE_DATE)<=30 and month(ORDER_DATE)>=10 and month(ORDER_DATE)<=12),在E3的基础上,直接将H3的条件表达式复制过来
K3:将I3直接复制到K3,单元格引用名称自动变化,显示格式保留
到这个例子,是不是已经感觉这些表达式写起来也没有多困难了,即使是初学者,也能轻易看懂并写出来了,是的,有这样的感觉就对了,对于搞计算机的同学,这确实不难
再来看看其他的一些只能通过对话框来设置条件的工具处理这样的情况会怎样
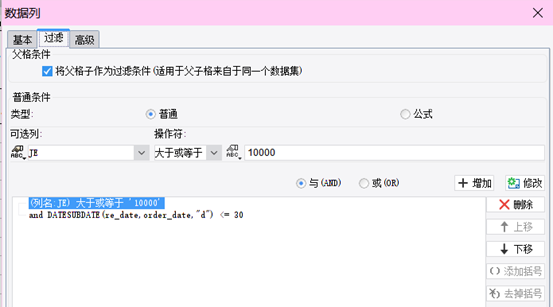
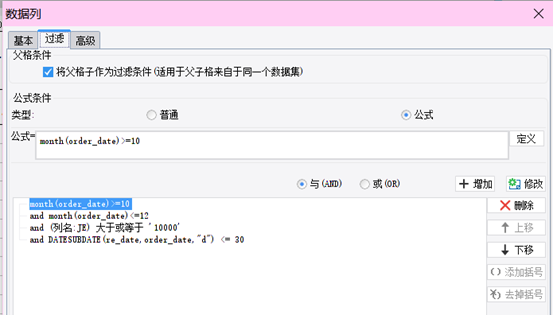
每增加一个条件,一个and,就得点一次增加,如果要修改,删除,同样得挨个去点,每次设置还都得打开、关闭一次对话框
如果每次都得这样,估计初学者也不会觉得简单而是会感到麻烦了,更别说熟练的老同学了这样无端端多出了好多没必要的操作,会浪费很多的时间,减少很多产出
懂了表达式以后,还是直接写表达式更快更好,可视化操作看上去很美,但效率并不会高
本章小节
从上面三个报表我们可以看出,简单的表样,可视化的对话框设置确实使用体验更好,但格式稍微变复杂一点以后,工程师已经掌握表达式的书写以后,如果仍然还得用对话框就显得繁琐了
而且报表开发人员是技术工种,从初学者到熟手是轻而易举的事情,是否快和方便,要从一个熟手的角度去衡量,而不是初学者,所以考察的时候千万不要掉到生手容易熟手繁琐的操作陷阱中
上面三个报表都是比较初级的报表,我们更多的是从简单的普通操作上来看开发的效率如何,但实际的项目中,报表常常远没有这么简单,很多都会涉及较复杂的计算, 制作这些复杂的报表耗费的时间会更多,也更需要注重效率,所以复杂计算报表的开发效率,也是我们考察的重点
我们继续用两个示例来看下更复杂的报表的开发效率如何考察
示例4侧重于考察报表工具函数的功能,看一些复杂计算场景中,是否有对应的高级函数来直接解决问题,示例5侧重于考察工具处理一些复杂的多步、过程式计算的能力,看处理这些计算是否简单高效
示例4:找出进步最快的3名同学
基于如下数据学生成绩表:
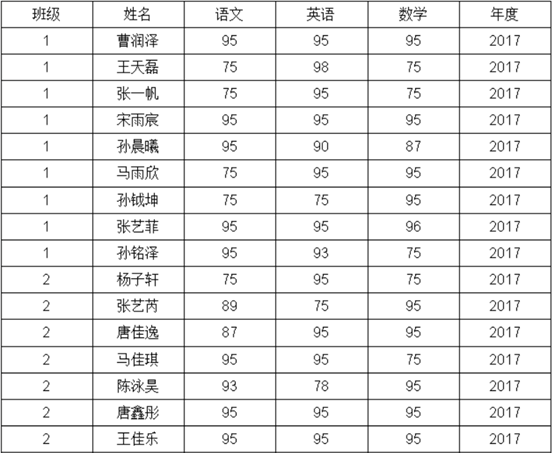
进行年度学生成绩汇总,进行班级班名以及和去年成绩对比,找出进步最快的三位同学,形成如下结果:
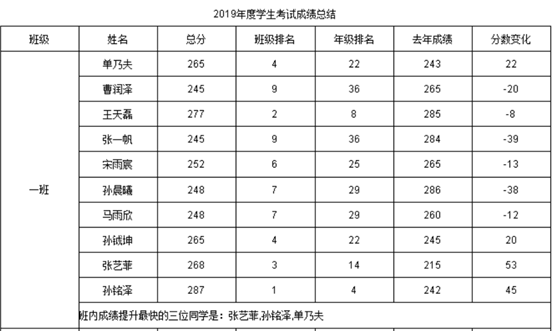
要点:看各工具怎么去做这个计算,看哪个更简单高效
制作过程
参数设置
报表中增加参数nd,默认值为2019,用于接收年份
数据集设置:
ds1:SELECT bj,studentid,yuwen+shuxue+yingyu zf,nd FROM XSCJ where nd=?,问号对应参数表达式:nd,用于对参数对应年度数据
ds2:SELECT bj,studentid,yuwen+shuxue+yingyu zf,nd FROM XSCJ where nd=?,问号对应参数表达式:nd-1,取参数对应上一年数据
报表模板设计:
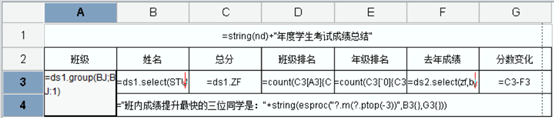
A3、A4单元格合并,按照班级分组,设置显示值表达式:chn(int(value()))+“班”
B3、B4分别取出姓名、分数字段
D3:=count(C3[A3]{C3>$C3})+1,班级内排名
E3:=count(C3[`0]{C3>=$C3})+1,年级排名
F3:=ds2.select(zf,bjA3 && studentidB3),从ds2数据集中取出去年成年,条件直接写在select函数内
G3:=C3-F3,成绩变化
B4:=“班内成绩提升最快的三位同学是:”+string(esproc(“?.m(?.ptop(-3))”,B3{},G3{})),使用润乾内置函数esproc,将K3单元格(名次变化幅度)传入,ptop(-3)取最大的3位的位置,然后用m()函数根据位置取对应的姓名
结果如下:
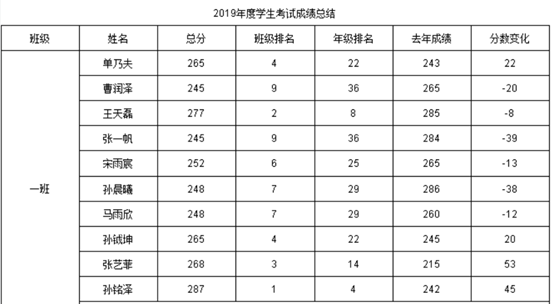
这个例子主要是测试报表工具的一些复杂计算能力,如果报表工具的模型中函数较为丰富且计算能力强,比如润乾报表内置了很多开源SPL计算工具的高级函数,那处理起复杂计算来就会游刃有余
如果函数计算功能不足,那就得通过多步计算,额外在报表中设置辅助计算格才可以完成,比如有些报表工具,需要像下面这样用H列进一步计算需要的数据,然后再隐藏掉

这些额外辅助计算格,不仅增加了开发工作量,数据量大的时候,还会影响报表的性能
其实这款报表已经不错,提供有层次坐标之类的东西,用隐藏格还能做出来,有些报表工具连这个都没有,只能自己在外部写代码实现了,工作效率会大受影响
示例5:找出指定时间内的大客户
从如下销售数据中:
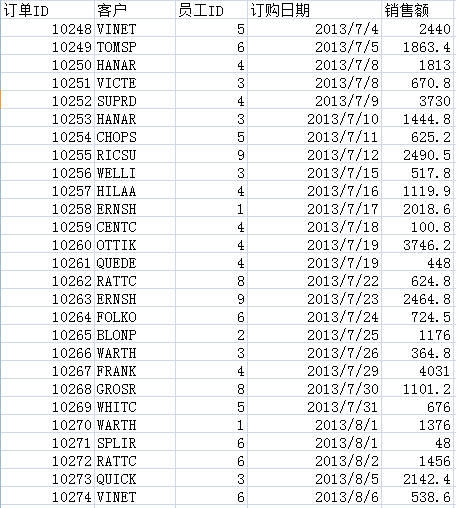
取出指定时段的大客户。所谓大客户,定义为销售额占前一半的客户,也就是把客户销售额从大到小排序后,前面若干个客户的合计销售额构成总销售的一半,这些客户被称为大客户
报表结果:
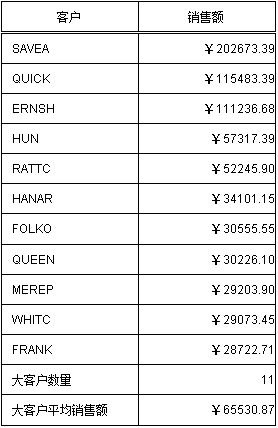
制作过程
数据集设置
润乾报表内置了高效的开源计算工具SPL,可以通过内置的脚本更简单高效的计算这些复杂的多步计算,把计算结果当做数据集直接供报表来使用,脚本如下:

A3:对销售额进行求和操作并处以2,取出总金额的一半,用于判断大客户。B3设置初始值为0,用于做销售额累加操作
A4:对销售额进行累加,取出累加金额大于A3中对应的A2的序号
A5:根据序号取A2中对应的值,并做为结果集返回给报表
报表模板设计
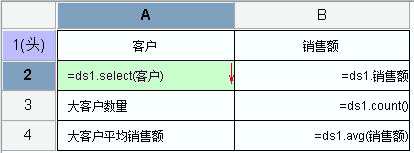
报表结果
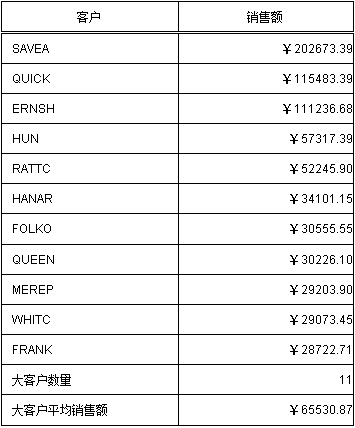
从这个例子可以看出,原本需要在报表中做大量计算才能做出的报表,经过脚本准备数据后,只需要在报表中直接取数就可以了
如果没有脚本,那就只能在报表中完成这样的计算,写起来麻烦,需要设置很多辅助格,同时增大了实现难度,对人员要求变高了很多(意味着成本上升),而且性能也远没有脚本的好

本示例只是举了一个很小的需要分步计算的例子,就已经可以看出不同工具的设计效率了,一个简单易懂的脚本搞定,还是一堆辅助计算格+复杂的表达式来完成,开发效率差异是显而易见的
实际的项目中的复杂报表,对原始数据的处理和计算,远远要比本例复杂的多,如果有脚本功能,那可以用脚本来处理这些计算,不仅写起来简单,算起来还快,如果没有脚本功能,那就只能用成百上千行的复杂SQL,存储过程或者高级语言去写了,那样开发效率就更低了
所以我们考察报表工具对于复杂报表的开发效率时,可以看看自己的项目中有没有需要写复杂的SQL、存储过程或者更复杂的数据来源处理的报表,拿来找各工具测试验证下,看看它们的效率都如何
写在最后
为了这次面试,也收集了很多的面试题!
以下是部分面试题截图

看看它们的效率都如何
写在最后
为了这次面试,也收集了很多的面试题!
以下是部分面试题截图
[外链图片转存中…(img-T9gadr8W-1714997904672)]















 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









