







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

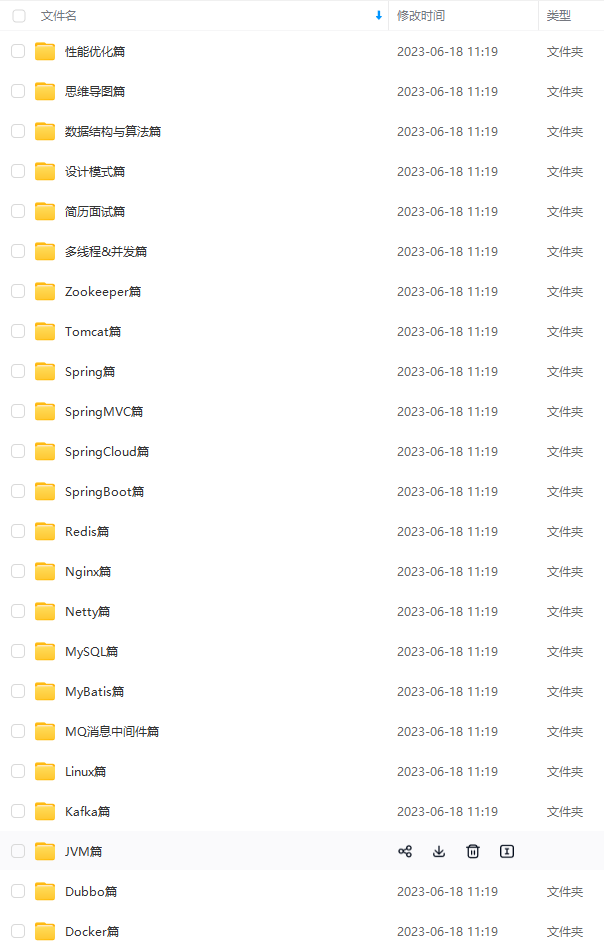
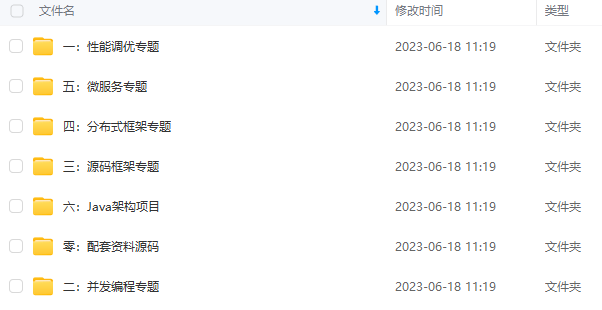
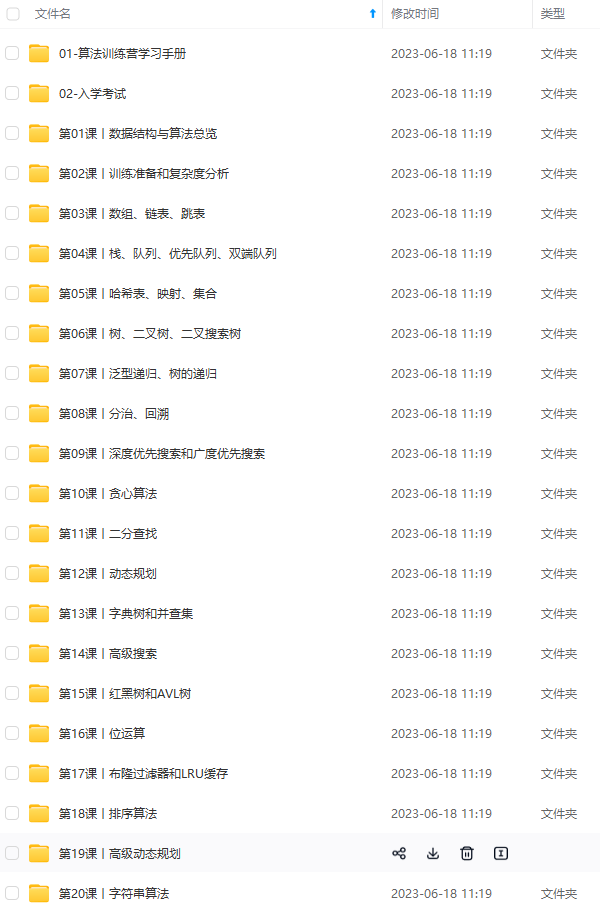
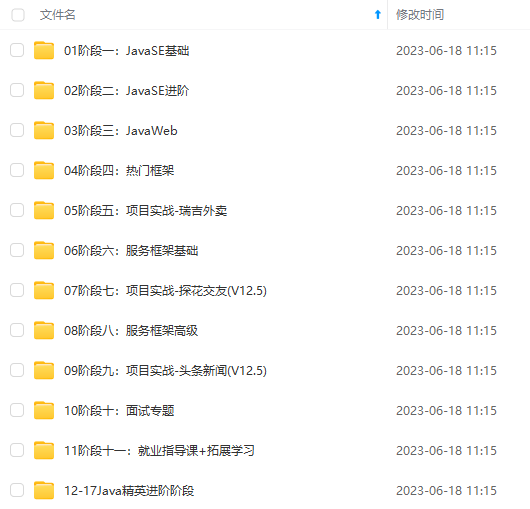
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
}
在hashmap做put操作的时候会调用到以上的方法。现在假如A线程和B线程同时对同一个数组位置调用addEntry,两个线程会同时得到现在的头结点,然后A写入新的头结点之后,B也写入新的头结点,那B的写入操作就会覆盖A的写入操作造成A的写入操作丢失
(2)删除键值对的代码
// 删除“键为key”的元素
final Entry<K,V> removeEntryForKey(Object key) {
// 获取哈希值。若key为null,则哈希值为0;否则调用hash()进行计算
int hash = (key == null) ? 0 : hash(key.hashCode());
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
// 删除链表中“键为key”的元素
// 本质是“删除单向链表中的节点”
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size–;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
当多个线程同时操作同一个数组位置的时候,也都会先取得现在状态下该位置存储的头结点,然后各自去进行计算操作,之后再把结果写会到该数组位置去,其实写回的时候可能其他的线程已经就把这个位置给修改过了,就会覆盖其他线程的修改
(3)addEntry中当加入新的键值对后键值对总数量超过门限值的时候会调用一个resize操作,代码如下:
// 重新调整HashMap的大小,newCapacity是调整后的容量
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//如果就容量已经达到了最大值,则不能再扩容,直接返回
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 新建一个HashMap,将“旧HashMap”的全部元素添加到“新HashMap”中,
// 然后,将“新HashMap”赋值给“旧HashMap”。
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
这个操作会新生成一个新的容量的数组,然后对原数组的所有键值对重新进行计算和写入新的数组,之后指向新生成的数组。
当多个线程同时检测到总数量超过门限值的时候就会同时调用resize操作,各自生成新的数组并rehash后赋给该map底层的数组table,结果最终只有最后一个线程生成的新数组被赋给table变量,其他线程的均会丢失。而且当某些线程已经完成赋值而其他线程刚开始的时候,就会用已经被赋值的table作为原始数组,这样也会有问题。
3、是否提供contains方法
HashMap把Hashtable的contains方法去掉了,改成containsValue和containsKey,因为contains方法容易让人引起误解。
Hashtable则保留了contains,containsValue和containsKey三个方法,其中contains和containsValue功能相同。
我们看一下Hashtable的ContainsKey方法和ContainsValue的源码:
public boolean containsValue(Object value) {
return contains(value);
}
// 判断Hashtable是否包含“值(value)”
public synchronized boolean contains(Object value) {
//注意,Hashtable中的value不能是null,
// 若是null的话,抛出异常!
if (value == null) {
throw new NullPointerException();
}
// 从后向前遍历table数组中的元素(Entry)
// 对于每个Entry(单向链表),逐个遍历,判断节点的值是否等于value
Entry tab[] = table;
for (int i = tab.length ; i-- > 0 😉 {
for (Entry<K,V> e = tab[i] ; e != null ; e = e.next) {
if (e.value.equals(value)) {
return true;
}
}
}
return false;
}
// 判断Hashtable是否包含key
public synchronized boolean containsKey(Object key) {
Entry tab[] = table;
/计算hash值,直接用key的hashCode代替
int hash = key.hashCode();
// 计算在数组中的索引值
int index = (hash & 0x7FFFFFFF) % tab.length;
// 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return true;
}
}
return false;
}
下面我们看一下HashMap的ContainsKey方法和ContainsValue的源码:
// HashMap是否包含key
public boolean containsKey(Object key) {
return getEntry(key) != null;
}
// 返回“键为key”的键值对
final Entry<K,V> getEntry(Object key) {
// 获取哈希值
// HashMap将“key为null”的元素存储在table[0]位置,“key不为null”的则调用hash()计算哈希值
int hash = (key == null) ? 0 : hash(key.hashCode());
// 在“该hash值对应的链表”上查找“键值等于key”的元素
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
// 是否包含“值为value”的元素
public boolean containsValue(Object value) {
// 若“value为null”,则调用containsNullValue()查找
if (value == null)
return containsNullValue();
// 若“value不为null”,则查找HashMap中是否有值为value的节点。
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (value.equals(e.value))
return true;
return false;
}
通过上面源码的比较,我们可以得到第四个不同的地方
4、key和value是否允许null值
其中key和value都是对象,并且不能包含重复key,但可以包含重复的value。
通过上面的ContainsKey方法和ContainsValue的源码我们可以很明显的看出:
Hashtable中,key和value都不允许出现null值。但是如果在Hashtable中有类似put(null,null)的操作,编译同样可以通过,因为key和value都是Object类型,但运行时会抛出NullPointerException异常,这是JDK的规范规定的。另外,欢迎关注我们,公号终码一生,后台回复“资料”获取视频教程和最新面试资料。
HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,可能是 HashMap中没有该键,也可能使该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
5、两个遍历方式的内部实现上不同
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
6、hash值不同
哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
hashCode是jdk根据对象的地址或者字符串或者数字算出来的int类型的数值。
Hashtable计算hash值,直接用key的hashCode(),而HashMap重新计算了key的hash值,Hashtable在求hash值对应的位置索引时,用取模运算,而HashMap在求位置索引时,则用与运算,且这里一般先用hash&0x7FFFFFFF后,再对length取模,&0x7FFFFFFF的目的是为了将负的hash值转化为正值,因为hash值有可能为负数,而&0x7FFFFFFF后,只有符号外改变,而后面的位都不变。
7、内部实现使用的数组初始化和扩容方式不同
HashTable在不指定容量的情况下的默认容量为11,而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。
Hashtable扩容时,将容量变为原来的2倍加1,而HashMap扩容时,将容量变为原来的2倍。
Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。
PS:防止找不到本篇文章,可以收藏点赞,方便翻阅查找哦。
往期推荐
最后
文章中涉及到的知识点我都已经整理成了资料,录制了视频供大家下载学习,诚意满满,希望可以帮助在这个行业发展的朋友,在论坛博客等地方少花些时间找资料,把有限的时间,真正花在学习上,所以我把这些资料,分享出来。相信对于已经工作和遇到技术瓶颈的朋友们,在这份资料中一定都有你需要的内容。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
荐
最后
文章中涉及到的知识点我都已经整理成了资料,录制了视频供大家下载学习,诚意满满,希望可以帮助在这个行业发展的朋友,在论坛博客等地方少花些时间找资料,把有限的时间,真正花在学习上,所以我把这些资料,分享出来。相信对于已经工作和遇到技术瓶颈的朋友们,在这份资料中一定都有你需要的内容。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-t9YenmKD-1713305940978)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1036
1036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









