







-
触发报警的堆栈聚合真实原因不是新增
-
新增问题导致的问题不触发报警
-
问题无法消费
总之,抓栈随机性决定了我们无法定位真实原因,也就无法确定新增问题的有效性,这就使得很多新增问题被带入线上,我们也在这种低效的恶性循环中不断重复。
我们的诉求
经过以上的分析和调研,我们的痛点可以归结为以下三类:
-
对于单点问题,无法定位到真实堆栈。
-
对于多点耗时问题,无法还原问题现场。
-
缺乏有效的增量问题防治手段。
现有的问题现场堆栈对于由于抓栈的不准确,无论对单点问题排查还是多段耗时问题排查都意义不大,无法正确的还原现场信息,这使得我们的问题排查优化进展缓慢,甚至偏离正常的方向。现有的卡顿及调度时序图等工具都是以 Message 为统计粒度,无法提供真正可优化的耗时定位,而现有的以 Method 为统计粒度的工具由于性能和稳定性问题都只能运行在线下。为此,我们希望有一套能够高效运行在线上的 Method trace 工具,用于卡顿及 ANR 的检测,以 Method 耗时为统计粒度,获取卡顿/ANR 时用户当前和之前一段时间内的 Method 执行耗时情况,这样我们可以完整的呈现问题发生时刻以及之前一段时间的 Method 执行耗时情况,高效清晰的定位问题症结所在。
针对增量问题的防治,由于现有的能力无法识别问题是否新增,导致在错误的方向上耗费太多精力,而真正的问题无法被发现从而带入线上,为此我们需要搭建增量问题的防治体系,去体系化前置化的完成增量问题的监控、有效信息的提供、问题的分发,前置化预防才能避免问题被带入线上,体系化才能更高效更全面的最大限度发现问题,同时将增量问题的防治体系建设和问题监控解决能力建设结合起来,建立一个自动化、前置化、发现问题全面、易消费、分发及时的的全链路体系。
监控体系建设
在目前的监控体系下,堆栈抓取不准确,堆栈聚合存在问题,大量聚合在了无意义的堆栈上,现有的工具体系下,分析成本极高,大多数问题无法得到有效消费,卡顿和 ANR 指标长期高位,这就要求我们尽快找到破解之法。
诚然,最终导致弹出 ANR 弹窗的诱因很多,但是归根结底,根本原因都是执行超时,而我们最需要关注的也是那些耗时较高的 Method,当 Method 耗时减少后,相应的触发 ANR 的几率也会随之减少,为此我们就需要找出那些真正耗时卡顿的地方并对其进行优化。
针对以上的痛点和诉求,我们重新梳理了思路,对比了现有方案的优缺点后,取长补短,开发了基于 Method 的高性能线上 trace 工具。在此基础上,我们针对 ANR、卡顿进行了方案升级和全方位的体系建设。
基于 Sliver 的 ANR 治理方案介绍
针对 ANR,我们希望获取到发生 ANR 时前一段时间的堆栈记录,以快速的找出发生耗时的 Method 调用堆栈。
Sliver 采用采样的方式来定时获取堆栈,我们在 APP 启动时打开 Sliver 的监控能力,根据不同机型传入不同的采样值,通常在低端机采样值会大一些,在高端机采样值会小一些,这样最大限度降低获取 trace 本身对性能的影响,Sliver 定时抓取堆栈,并对获取到的堆栈做 diff 聚合、缓存以区分不同堆栈的关系。同时,通过 NPTH 的接口注册 ANR 的回调,当发生 ANR 时,回调函数中将缓存的堆栈 dump 到文件,同时将文件随 ANR 其他信息上报到 Sladar,这样我们就可以在对 case 的分析中使用精确的 trace 信息问题定位,下图说明了针对 ANR 的整体工作流程。
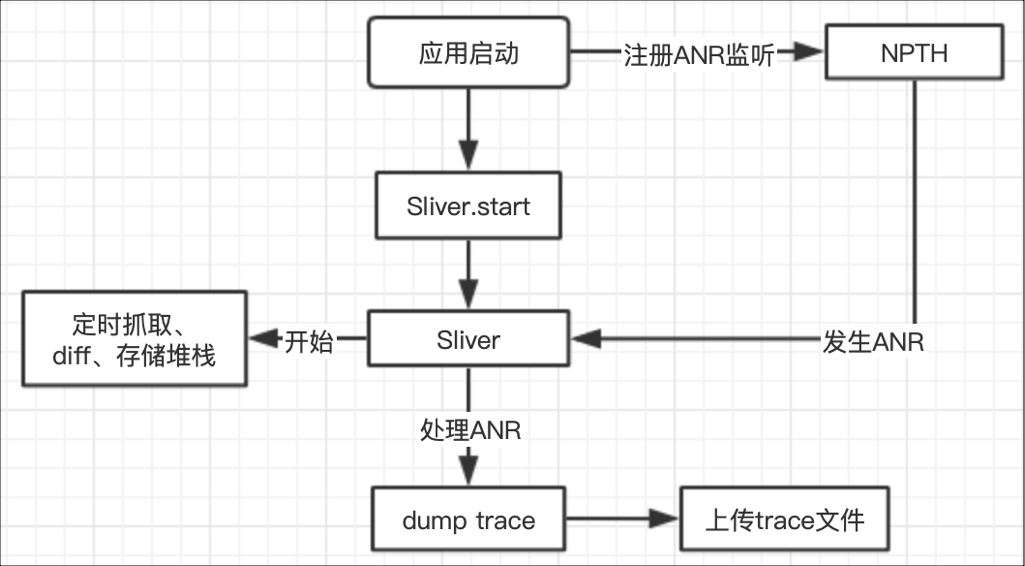
我们将这一套流程运行起来,收集了相关 case,在同一个 case 拿到相关信息对比。
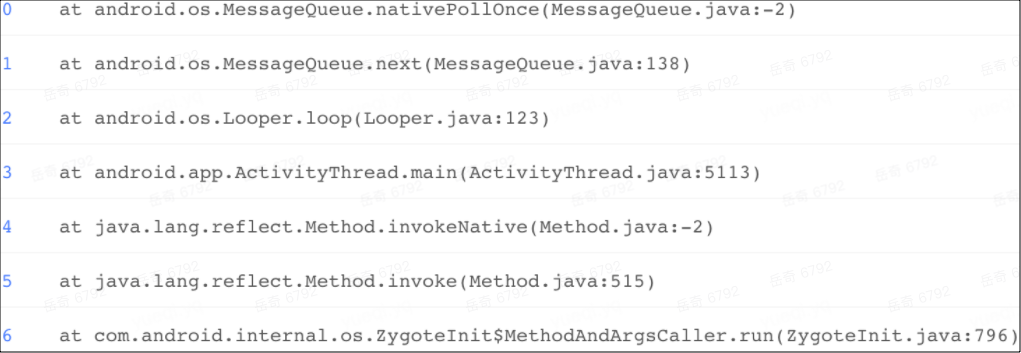
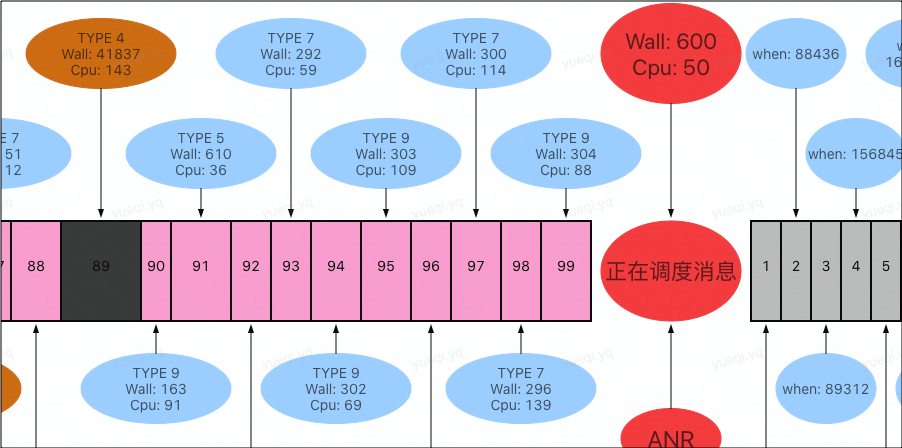

以上三个图是同一个 case 中的不同信息,分别是堆栈、调度时序图、trace,通过 trace 能清晰看出问题的原因所在。
目前该方案已在线下、灰度、众测渠道常态开启,作用明显,如下:
-
帮助新增问题的界定、归因,防止新增问题带入线上。
-
帮助存量问题的归因、定位,梳理清楚各错误堆栈聚合中的真正问题原因。
-
对于线下、众测等反馈较多渠道单点精准定位解决问题。
整体上,该方案的上线,使得我们能够更清晰准确的定位问题原因,加快问题的流转解决,促进各类隐藏较深问题的快速解决。
卡顿问题的防治方案
不同于 ANR 问题,卡顿问题的标准是我们自己定义的,卡顿以及多次卡顿的叠加是导致 ANR 以及影响性能的大项,现有的卡顿监控只能拿到单一的堆栈链路,无法完整还原当前卡顿产生现场全貌,基于此我们设计了基于 Sliver trace 的卡顿监控体系。
先看整体流程图:
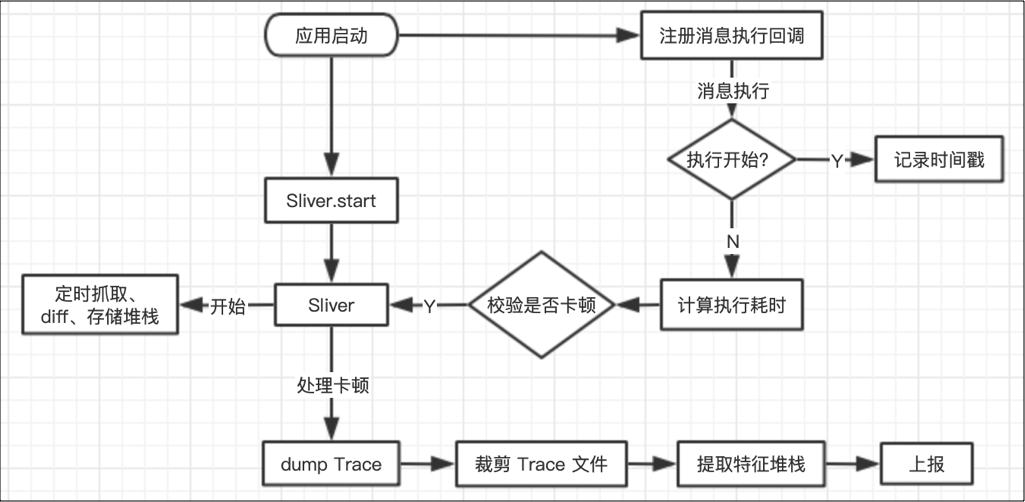
主要包含两个方面:
- 检测方案
在监控卡顿时,首先需要打开 Sliver 的 trace 记录能力,Sliver 采样记录 trace 执行信息,对抓取到的堆栈进行 diff 聚合和缓存。
同时基于我们的需要设置相应的卡顿阈值,以 Message 的执行耗时为衡量。对主线程消息调度流程进行拦截,在消息开始分发执行时埋点,在消息执行结束时计算消息执行耗时,当消息执行耗时超过阈值,则认为产生了一次卡顿。
- 堆栈聚合策略
当卡顿发生时,我们需要为此次卡顿准备数据,这部分工作是在端上子线程中完成的,主要是 dump trace 到文件以及过滤聚合要上报的堆栈。分为以下几步:
-
拿到缓存的主线程 trace 信息并 dump 到文件中。
-
然后从文件中读取 trace 信息,按照数据格式,从最近的方法栈向上追溯,找到当前 Message 包含的全部 trace 信息,并将当前 Message 的完整 trace 写入到待上传的 trace 文件中,删除其余 trace 信息。
-
遍历当前 Message trace,按照(Method 执行耗时 > Method 耗时阈值 & Method 耗时为该层堆栈中最耗时)为条件过滤出每一层函数调用堆栈的最长耗时函数,构成最后要上报的堆栈链路,这样特征堆栈中的每一步都是最耗时的,且最底层 Method 为最后的耗时大于阈值的 Method。
之后,将 trace 文件和堆栈一同上报,这样的特征堆栈提取策略保证了堆栈聚合的可靠性和准确性,保证了上报到平台后堆栈的正确合理聚合,同时提供了进一步分析问题的 trace 文件。
上线后,我们通过和原卡顿体系进行效果对比:
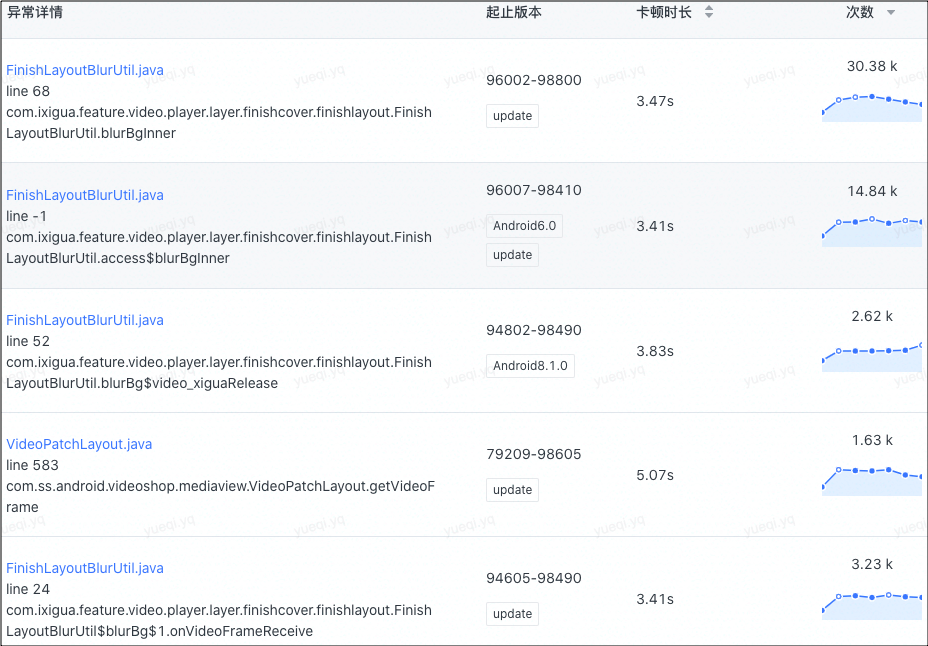


以上三图分别是,针对高斯模糊问题的原卡顿列表、现在卡顿列表、trace 。在原先的卡顿上报列表中,问题分散到了不同的堆栈中,这是由于发生卡顿时抓栈随机,而现在的卡顿列表聚合到了单一的堆栈链路中,这是由于我们取每一层堆栈中耗时最长的函数组合成特征堆栈,通过trace也可以验证特征堆栈的有效性,能够更准确的定位问题原因。同时,trace 详细的展示了函数调用链路,提供了深入分析问题的能力。
经过 trace 和堆栈验证,该方式输出的卡顿信息,堆栈聚合更加契合真正的卡顿点,当然一个 Message 中可能有多个大大小小的耗时函数存在,trace 文件的存在能够更全面的还原现场情况,二者的结合才能更好的解决问题。
目前卡顿检测体系已经在众测及线下自动化常态运行,产出数据来看均为线上存在问题。
前置发现能力建设
基于 Sliver 能力的卡顿和 ANR 检测方案,能够极大提高解决问题的效率,接下来我们需要考虑如何将这两种能力常态的运行起来,服务于我们的日常存量问题、增量问题的防和治,尤其是将问题的暴露阶段提前,减少对用户的影响尤为重要。为此,我们进行了以下几个方向的建设。
- 线下压力测试
目前,测试平台提供了一些自动化测试 job,这些 job 大多以遍历方式自动的测试 APP 的功能,对所有功能优先级一样的触达,我们将我们的 ANR 检测能力和卡顿检测能力进行集成打包,触发自动化 job,产出相关的卡顿和 ANR case。
分析对比这些 case 后发现,线下上报的 TOP 问题和线上问题差异较大,不符合用户真实的使用场景。线下检测出的一些量级较大的 case 在线上场景出现的量级很小,影响的用户很少,而线上一些影响用户较多的 case,线下检测却上报很少。分析这是由于遍历式的测试方案不符合真实的用户行为,这会使我们在推动解决问题中优先级错误,无法及时正确辨别那些真正量级高、影响用户多、优先级高的问题,影响整体的优化节奏。
为此,我们接入了更智能的基于用户行为的测试策略,产出了更符合用户真实行为的智能测试 job,基于此 job 进行卡顿和 ANR 数据收集,采样分析相关数据符合线上数据分布,在量级和影响用户量级分布上更接近真实的用户场景,得到正确的问题优先级。
同时利用测试平台接口,我们构建了完全自动化的测试机制:基于最新 release 分支定时触发打包平台打包 -> 配置渠道为性能测试专用渠道 -> 成功后执行自动化测试生成数据。
- 线上 (beta_version 和灰度)
线下的自动化测试毕竟受机型、场景等条件限制,不易发现一些用户个性化问题。为此,在线上进行问题检测显得尤为重要。beta_version 和灰度渠道都是真实的用户渠道,能够覆盖各种场景,但二者又有所不同,beta_version 用户较少但活跃度更高。为此我们在 beta_version 渠道集成了卡顿和 ANR 数据的收集方案。同时,灰度渠道由于用户数多,可以提供更全面的场景和用户,我们也在灰度渠道集成了 ANR 方案,不过由于卡顿发生的频率相对较高,考虑到灰度用户多的特点,我们暂未开启灰度渠道的卡顿采集。
- 动态能力建设
很多时候需要对线上用户遇到的问题进行动态调查,相关调查能力虽然完备,但出于包大小的考虑很多时候并不会带到线上。针对此类问题,需要有一种类似于补丁但又相对轻量的方案,能够动态的下发能力到用户的手机上。
为了提高西瓜 Android 客户端的动态调查能力,将所有的通用能力封装成一个模块,通过统一的接口进行调度与事件分发,结合插件化下发加载能力,实现精准下发调查能力到任意手机上。
在实现上,整体流程如下图:
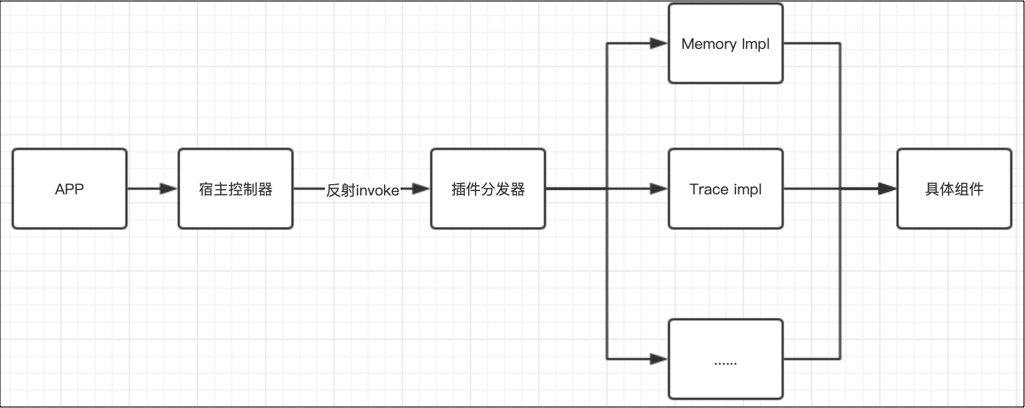
可以分为宿主、插件、组件三部分来看:
-
宿主控制器,进行配置的拉取、插件初始化,预埋接口供宿主调用,根据调用及动态配置反射向插件分发器传递指令。
-
插件分发器,接收宿主的指令,并对应的加载不同的组件,执行不同的操作。
-
组件是一个个的独立模块,提供能力的具体实现,执行具体的功能。
基于此框架,我们可以根据需求以动态下发插件的方式下发携带不同能力的插件包,同时利用 Setting 控制宿主执行相应的操作,完成动态的定向下发特定能力到特定手机或某类渠道的能力,这有以下优点:
-
工具无需集成到 APK,不影响包大小
-
动态能力强,线上可以定向调查问题,线下可以快速验证问题。
目前,我们已将多种问题调查能力进行了集成,为线上问题调查和修复提供了支撑。
卡顿数据的消费链路建设
以上部分从线上、线下、动态能力角度结合卡顿 & ANR 方案进行了全方位的运行,产出了易消费可消费的数据,接下来我们需要完善消费流程,提高问题的解决效率。
针对产出的数据,我们通过轻服务进行数据处理,根据 apm_open 开放接口,我们可以拿到 job 对应的卡顿& ANR 数据列表,遍历列表,将每一个 case 的相关信息进行拼接,尤其是卡顿的 trace 文件链接,避免了文件下载链路较长的弊端,降低优化成本,之后将这些信息分发到对应的跟进群中。同时,在 Sladar 上根据对应的代码修改人或模块 owner 指定 owner 跟进。效果如下:
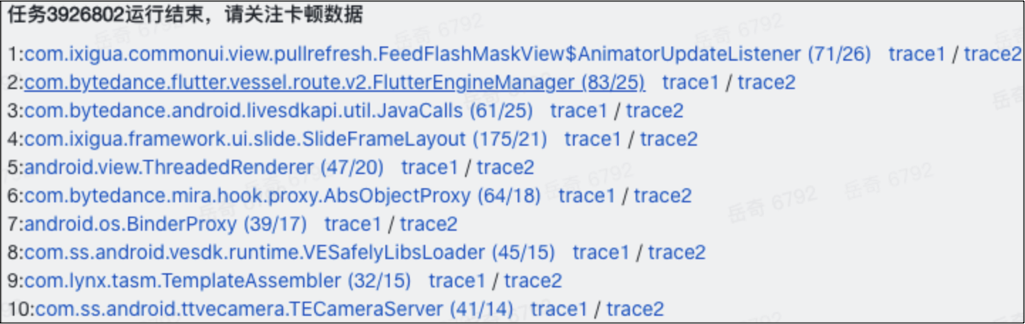
同时,针对需要获取大量 trace 文件进行分析的场景,我们也开发了本地工具,便捷批量拉取 trace 文件。
总的来说,西瓜从基础工具的开发到在此之上卡顿 & ANR 方案的优化到线上线下动态前置发现能力建设再到最终的消费链路,完成整个卡顿 & ANR 监控体系的闭环,在存量问题解决、增量问题防治、单点问题跟进、整体性能治理上发挥了重要作用。
典型案例介绍
堆栈聚合错误案例
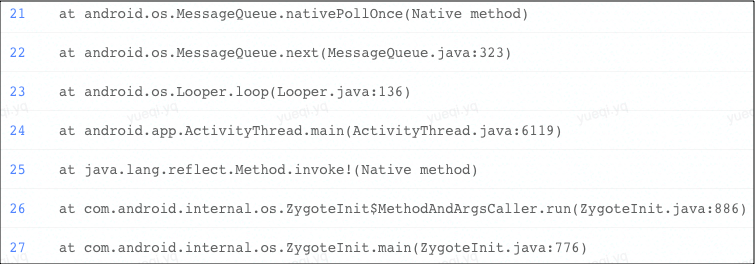
对 TOP 1 的 nativePollOnce 问题捞取多个 trace 样本进行分析,堆栈表现如下:
- 数据库问题
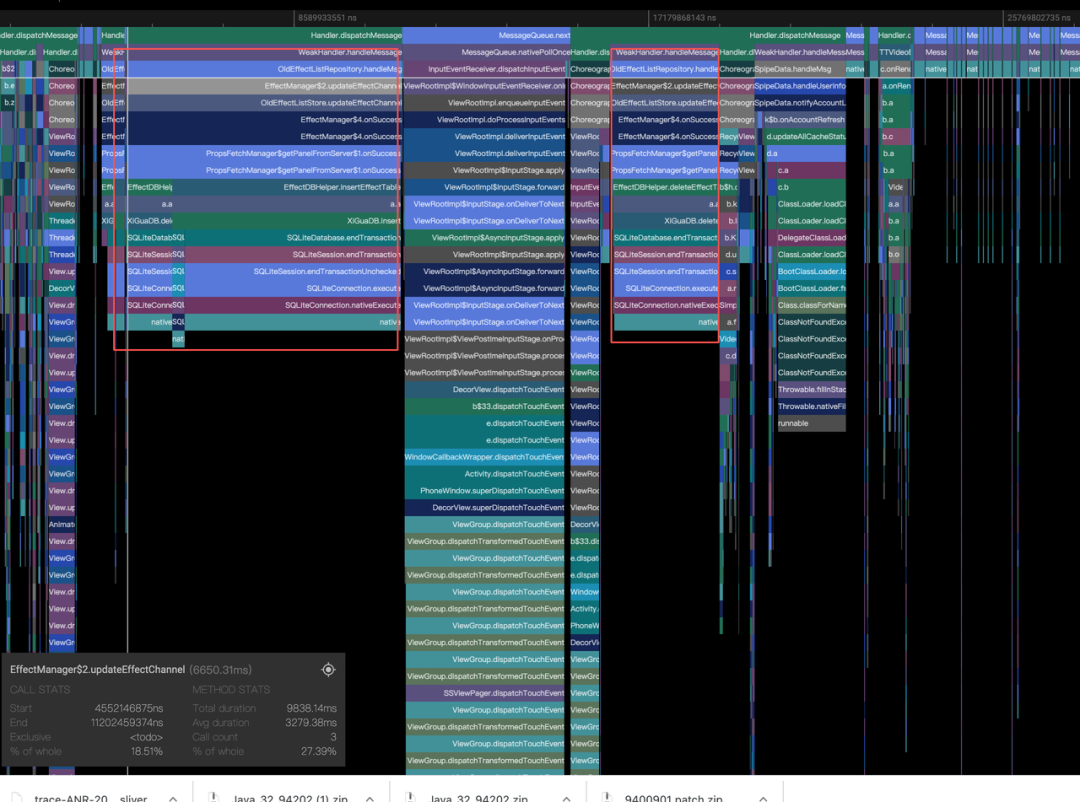
通过 trace 看出其实是主线程在执行数据库操作,快速推动解决。
- Dex2oat 问题

通过 trace 看出其实是 ClassLoader. 执行了 20+s,查看源码,发现是 PluginClassLoader.->…dex2oat…->Runtime.exec 这样一个调用链路。
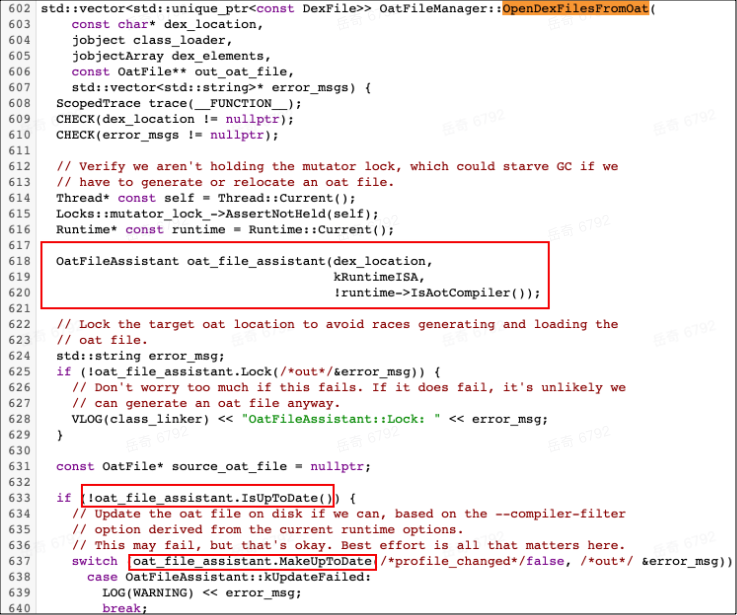
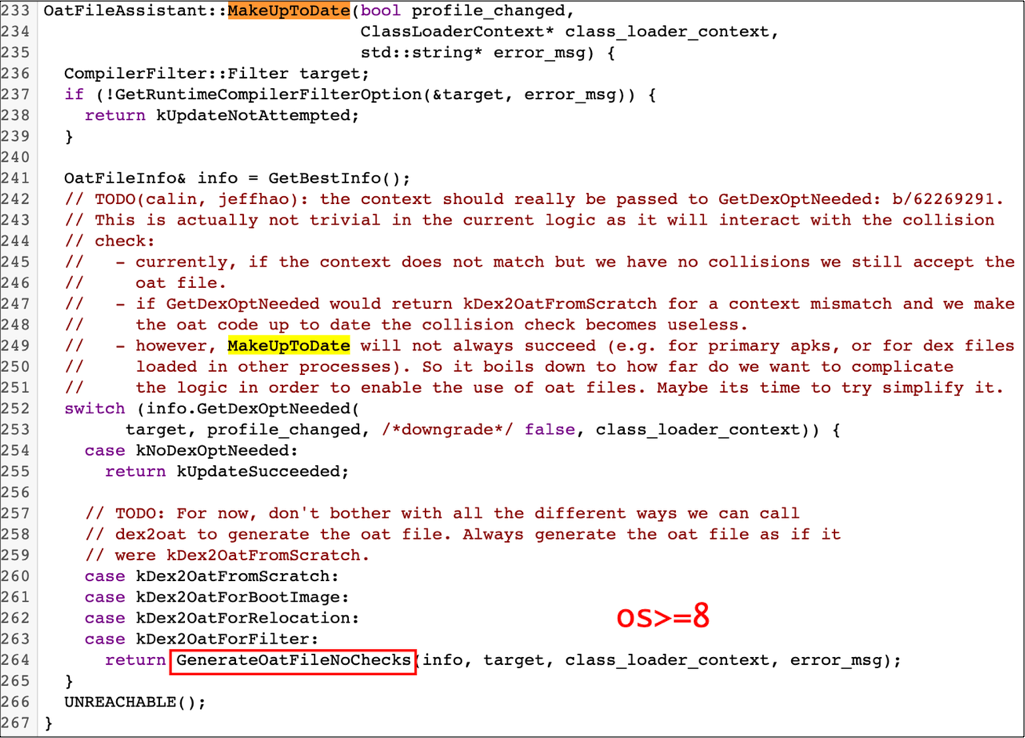
基于以上的堆栈,我们知道该问题是在加载插件时,验证 oat 文件不通过而触发主线程 dex2oat 操作导致。因此我们提前在插件 Plugin 实例初始化时,判断 oat 文件是否有效,无效的话中断插件状态机,置为不可用,同时异步重新生成 dex2oat 产物。
- 直播问题

通过 trace 清晰看出是直播插件内部的初始化耗时严重导致问题,而非上报的堆栈分析发现,触发主要发生在插件加载成功的回调中,基于现在的插件框架,插件的加载主要有两条路径:
-
主动 preload 插件
-
反射插件类从而被动触发插件加载
为此,我们从两个方面进行了优化:
-
从宿主层面梳理两类拉起插件时机,避免过早无意义拉起插件,按需加载
-
推动业务方,根本上优化初始化耗时。
非常规案例
- Json copy 问题
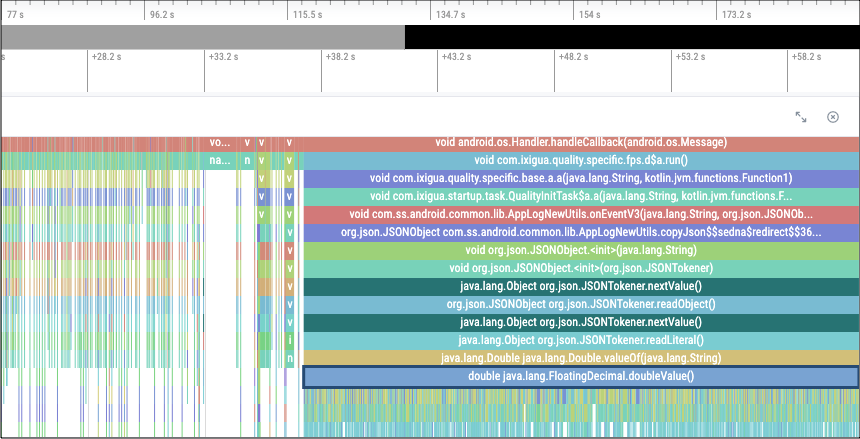
有一类这样的问题,看堆栈发生在 JSONObject clone = new JSONObject(origin.toString),在其中的浮点类型转换时。

看到这个堆栈的第一印象是该方法并不耗时,堆栈偏移,然后拿到对应的 trace 可以看到,确实是当前方法非常耗时导致。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Android工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Android移动开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip204888 (备注Android)

最后
感觉现在好多人都在说什么安卓快凉了,工作越来越难找了。又是说什么程序员中年危机啥的,为啥我这年近30的老农根本没有这种感觉,反倒觉得那些贩卖焦虑的都是瞎j8扯谈。当然,职业危机意识确实是要有的,但根本没到那种草木皆兵的地步好吗?
Android凉了都是弱者的借口和说辞。虽然 Android 没有前几年火热了,已经过去了会四大组件就能找到高薪职位的时代了。这只能说明 Android 中级以下的岗位饱和了,现在高级工程师还是比较缺少的,很多高级职位给的薪资真的特别高(钱多也不一定能找到合适的),所以努力让自己成为高级工程师才是最重要的。
所以,最后这里放上我耗时两个月,将自己8年Android开发的知识笔记整理成的Android开发者必知必会系统学习资料笔记,上述知识点在笔记中都有详细的解读,里面还包含了腾讯、字节跳动、阿里、百度2019-2021面试真题解析,并且把每个技术点整理成了视频和PDF(知识脉络 + 诸多细节)。

以上全套学习笔记面试宝典,吃透一半保你可以吊打面试官,只有自己真正强大了,有核心竞争力,你才有拒绝offer的权力,所以,奋斗吧!骚年们!千里之行,始于足下。种下一颗树最好的时间是十年前,其次,就是现在。
最后,赠与大家一句诗,共勉!
不驰于空想,不骛于虚声。不忘初心,方得始终。
Android 没有前几年火热了,已经过去了会四大组件就能找到高薪职位的时代了。这只能说明 Android 中级以下的岗位饱和了,现在高级工程师还是比较缺少的,很多高级职位给的薪资真的特别高(钱多也不一定能找到合适的),所以努力让自己成为高级工程师才是最重要的。
所以,最后这里放上我耗时两个月,将自己8年Android开发的知识笔记整理成的Android开发者必知必会系统学习资料笔记,上述知识点在笔记中都有详细的解读,里面还包含了腾讯、字节跳动、阿里、百度2019-2021面试真题解析,并且把每个技术点整理成了视频和PDF(知识脉络 + 诸多细节)。
[外链图片转存中…(img-uDMR4YjT-1712035430634)]
以上全套学习笔记面试宝典,吃透一半保你可以吊打面试官,只有自己真正强大了,有核心竞争力,你才有拒绝offer的权力,所以,奋斗吧!骚年们!千里之行,始于足下。种下一颗树最好的时间是十年前,其次,就是现在。
最后,赠与大家一句诗,共勉!
不驰于空想,不骛于虚声。不忘初心,方得始终。














 7054
7054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









