







- 🎄新年快乐朋友们🎄
- 👋Redis学习之路!
- 🔎更多文章(以下redis文章均上CSDN热榜):

文章目录
-
⭐️1 主从复制
-
⭐️1.1 主从复制简介
-
1.1.1多台服务器连接方案
-
⭐️1.2 主从复制
-
⭐️1.2.1主从复制的作用
-
⭐️1.3 主从复制工作流程
-
⭐️1.3.1 建立连接阶段步骤
-
⭐️1.3.1.1 主从连接的三种方式(slave连接master)
-
下面对这三种方式分别进行操作演示
-
方式一:在slave端发送连接请求
-
方式二:启动slave时直接与master进行连接
-
方式三:设置配置文件
-
⭐️1.3.2 数据同步阶段步骤
-
⭐️1.3.2.1 数据同步阶段master说明
-
⭐️1.3.2.2 数据同步阶段slave说明
-
⭐️1.3.2.3 命令传播阶段步骤
-
⭐️1.3.2.4 服务器运行ID(runid)
-
⭐️1.3.2.5 主服务器的复制偏移量积压缓冲区
-
⭐️1.3.2.6 主从服务器的复制偏移量(offset)
-
⭐️1.3.3 数据同步+命令传播阶段步骤
-
⭐️1.3.3.1 心跳机制
-
14 主从复制工作流程完整图示

======================================================================
==========================================================================
了解主从复制之前,你的redis是否高可用?
如果我们的redis是单机的就会存在一定的风险
问题1:机器故障
-
现象:
硬盘故障,系统崩溃 -
本质:
数据丢失,很可能对业务造成灾难性打击
问题2:容量瓶颈
-
现象:
内存不足,从16G升级到64G,从64G升级到128G,无限升级内存 -
本质:没钱,硬件条件跟不上
-
结论:硬件的发展速度直接决定软件的技术,内存上不去,redis存储的数据量就很低,这样下去就会放弃redis
因此:
为了避免Redis服务器故障造成重大损失,我们准备多台服务器,互相来南通。将数据复制多个副本保存在不同的服
务器上,连接在一起,并保证数据是同步的。即使有其中一台服务器宕机,其他服务器依然可以继续提供服务,实现
Redis的高可用,同时实现数据冗余备份
============================================================================
我们让主服务器专门负责写数据,下面的从属计算机专门负责读数据,数据由主服务器提供给从属服务器,这样的话我们的数据有多个备份,也就实现了高可用
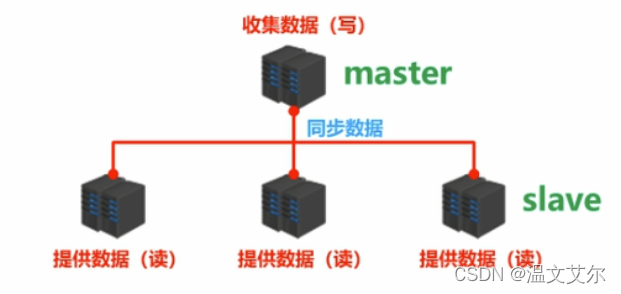
提供数据方:master
- 我们可以称之为:主服务器,主节点,主库,主客户端
接收数据方:slave
- 我们可以称之为:从节点,从库,从客户端
需要解决的问题
- 数据同步:master的数据复制到slave
这样,我么从主服务器向从服务器复制数据,就是主从复制
========================================================================
主从复制即:将master中的数据及时,有效的复制到slave中
特征:一个master可以拥有多个slave,一个slave只对应一个master
职责:
-
master
-
写数据 -
执行写操作时,将出现变化的数据
自动同步到slave -
slave
-
读数据
可能会有人说:master的压力过大崩溃了怎么办,不要着急,我们后面会说到的的哨兵模式就是为了解决这一问题的
除此之外,当我们的master压力很大时,我们可以在某一个slave上给其追加从属服务器,例如下图,所以说,
master和slave是一种相对的概念
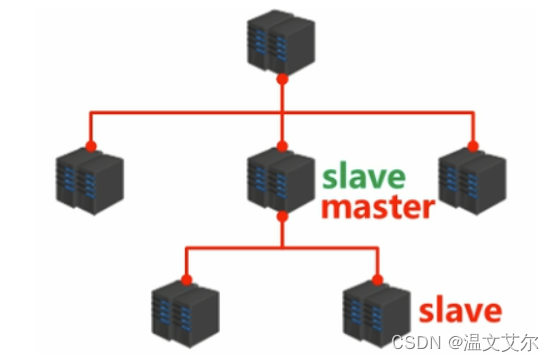

============================================================================
-
读写分离:
master写,slave读。提高服务器的读写负载能力 -
负载均衡:基于
主从结构,配合读写分离,由slave分担master负载,并根据需求的变化,改变slave的数量,通过多个从节点分担数据读取负载,大大提高Redis服务器并发量与数据吞吐量 -
故障恢复:当master出现问题时,由slave提供服务,实现快速的故障恢复
-
数据冗余:实现
数据热备份,是持久化之外的一种数据冗余方式 -
高可用基石:基于主从复制,构建哨兵模式与集群,实现Redis的高可用方案
============================================================================
主从复制过程大体可以分为3个阶段
1.建立连接阶段(即准备阶段)
2.数据同步阶段
3.命令传播阶段
流程图解:
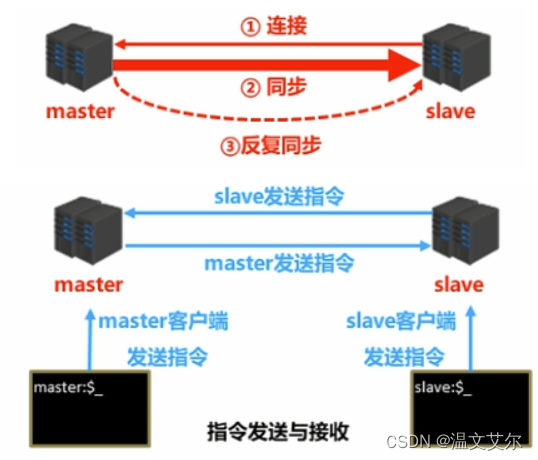
==============================================================================
建立slave到master的连接,使master能够识别slave,并保存slave端口号
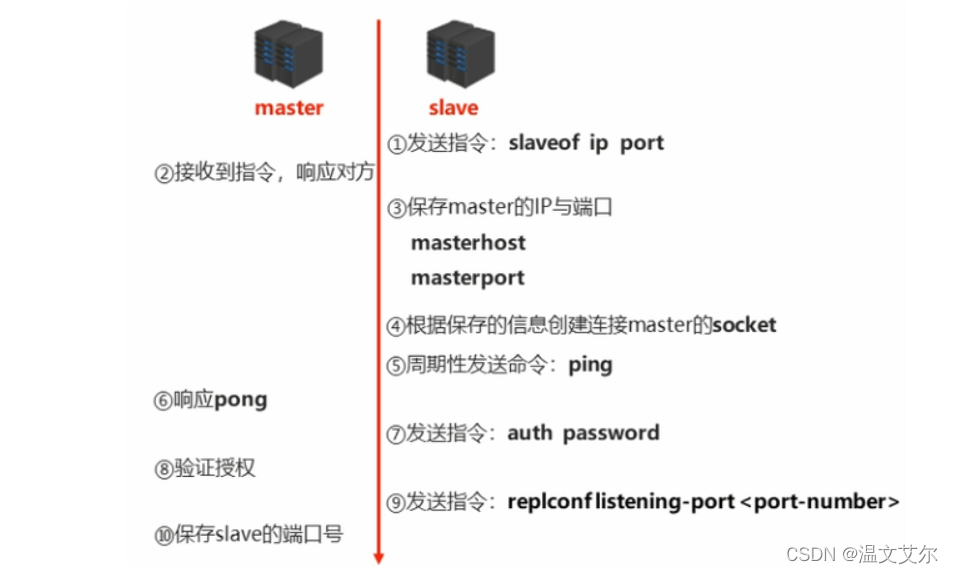
步骤1:设置master的地址和端口,保存master信息
步骤2:建立socket连接
步骤3:发送ping命令(定时器任务)
步骤4:身份验证
步骤5:发送slave端口信息
至此,主从连接成功!
最终状态:
slave:
- 保存master的地址与端口
master:
- 保存slave的端口
总体:
- 之间创建了连接的socket

⭐️1.3.1.1 主从连接的三种方式(slave连接master)
================================================================================================
方式一:客户端发送命令
- slaveof masterip masterport
方式二:启动服务器参数
- redis-server -slaveof masterip maxterport
方式三:服务器配置(主流方式,建议使用)
- slaveof masterip masterport
主从断开连接
-
客户端发送命令
-
slaveof no one
==============================================================================
我们以6739端口的服务器为master,以6380端口的服务器为slave进行操作
进入6379服务器关掉守护进程配置与日志

6380服务器同样

启动master及slave
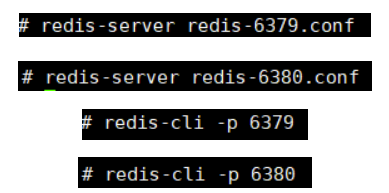

===============================================================================

我们查看slave的日志信息

发现连接过程中master与slave的信息已经同步
我们测试一下在master中set一个数据并在slave看能不能获取
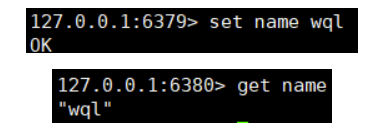
方式一成功
=======================================================================================

我们测试一下在master中set一个数据并在slave看能不能获取
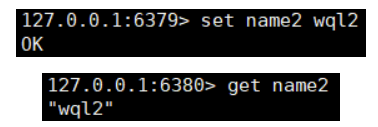
方式二成功
现在上面这样种方式都不是主流方式,主流的是直接在配置文件中进行设置
========================================================================
修改slave的配置文件,添加如箭头所指的配置
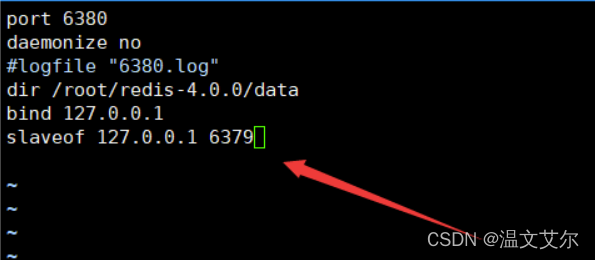
添加完毕我们启动slave,并查看信息是否同步
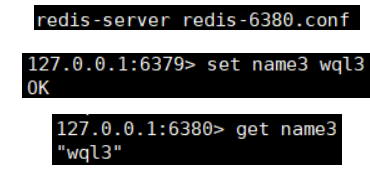
方式三成功

==============================================================================
在slave初次连接master后,会复制master中的所有数据到slave,数据同步阶段包括全量复制与部分复制
也就是将slave的数据库状态更新成master当前的数据库状态
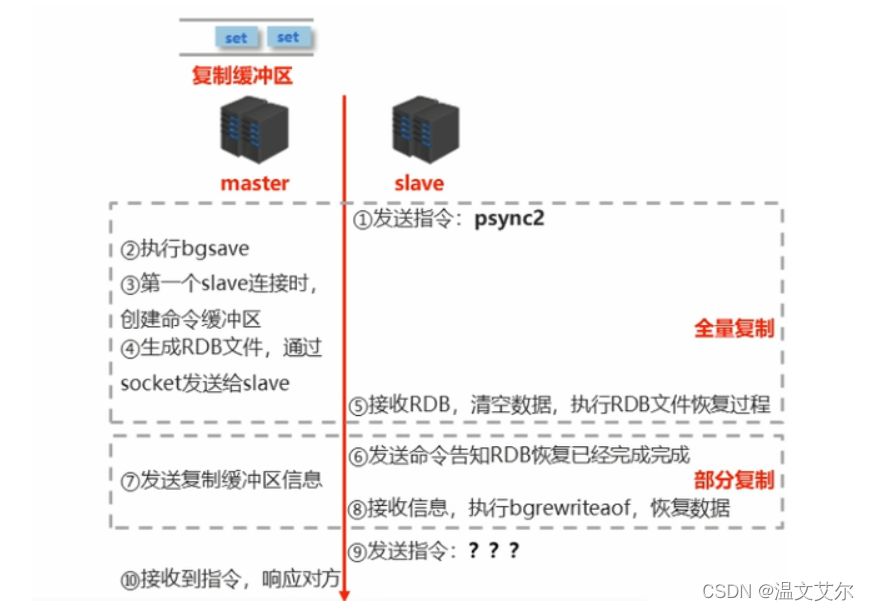
步骤1:请求同步数据
步骤2:创建RDB同步数据
步骤3:恢复RDB同步数据(以上阶段为全量复制)
步骤4:请求部分同步数据(同步的是缓冲区中的指令引起的数据)
步骤5:恢复部分同步数据(此过程会执行bgrewriteaof重写操作,恢复数据,步骤4,步骤5阶段为部分复制)
至此数据同步工作完成
全量复制
- 获取发指令的那一刻开始
原来的所有数据
部分复制
- 恢复进行
RDB过程中对应的所有数据
最终状态:
slave:
具有master端全部数据,包含RDB过程接收的数据
master
- 保存slave当前数据同步的位置
总体
- 之间完成了数据克隆
======================================================================================
-
如果master数据量巨大,数据同步阶段应
避开流量高峰期,避免造成master堵塞,影响业务正常执行 -
复制缓冲区大小设置不合理,会导致
数据溢出,如进行全量复制周期太长,进行部分复制时发现数据已经存在丢失的情况,必须进行第二次全量复制,致使slave陷入死循环状态

我们可以通过配置修改缓冲区的大小
- repl-backlog-size lmb
master单机内存占用主机内存的比例不应过大,建议使用50%-70%的内存,留下30%-50%的内存用于执行bgsave命令
和创建复制缓冲区
=====================================================================================
-
为避免slave进行全量复制,部分复制时服务器响应阻塞或数据不同步,建议关闭此期间的对外服务
-
slave-serve-stale-data yes|no(当主服务器挂掉时是否提供过期数据)
-
数据同步阶段,master发送给slave信息可以理解master是slave的一个客户端,主动向slave发送命令
-
多个slave同时对master请求数据同步,master发送的RDB文件增多,会对带宽造成巨大冲击,如果master带宽
不足,因此数据同步需要根据业务请求,适量错峰
- slave过多时,建议调整拓扑结构,由一主多从结构变为树状结构,中间的节点是master,也是slave,注意使用
树状结构时,由于层级深度,导致深度越高的slave与最顶层master间数据同步延迟较大,数据一致性变差,
应谨慎选择

================================================================================
当master数据库状态被修改后,导致主从服务器数据库状态不一致,此时需要让主从数据同步到一致的状态,同步的动作称为命令传播
一句话就是实时保持主从之间的数据同步
命令传播阶段的部分复制
-
命令传播阶段出现了断网情况
-
网络闪断闪连 忽略
-
短时间网络中断 部分复制
-
长时间网络中断 全量复制
-
部分复制的三个核心要素
-
服务器的运行id(run id)
-
主服务器的复制偏移量积压缓冲区
-
主从服务器的复制偏移量
下面我们对这三个核心要素分别进行叙述
======================================================================================
概念:服务器运行ID是每一台服务器每次运行的身份识别码,一台服务器多次运行可以生成多个运行id
组成:运行id由40位字符组成,是一个随机的十六进制字符
作用:运行id被用于在服务器间进行传输,识别身份
- 如果想两次操作均对同一台服务器进行,
必须每次操作携带对应的运行id,用于对方识别
实现方式:
- 运行id在每台服务器启动时
自动生成的,master在首次连接slave时,会将自己的运行ID发送给slave,slave保存此ID,通过info Server命令可以查看节点的runid
我们输入info server命令查看服务器运行id
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024b (备注Java)

结语
小编也是很有感触,如果一直都是在中小公司,没有接触过大型的互联网架构设计的话,只靠自己看书去提升可能一辈子都很难达到高级架构师的技术和认知高度。向厉害的人去学习是最有效减少时间摸索、精力浪费的方式。
我们选择的这个行业就一直要持续的学习,又很吃青春饭。
虽然大家可能经常见到说程序员年薪几十万,但这样的人毕竟不是大部份,要么是有名校光环,要么是在阿里华为这样的大企业。年龄一大,更有可能被裁。
送给每一位想学习Java小伙伴,用来提升自己。

本文到这里就结束了,喜欢的朋友可以帮忙点赞和评论一下,感谢支持!
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

存中…(img-F2fp4hxg-1712881132884)]
[外链图片转存中…(img-DYMzyplI-1712881132884)]
[外链图片转存中…(img-I03t8ojM-1712881132884)]
[外链图片转存中…(img-j1ug2ACl-1712881132885)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-l92JXzH0-1712881132885)]
结语
小编也是很有感触,如果一直都是在中小公司,没有接触过大型的互联网架构设计的话,只靠自己看书去提升可能一辈子都很难达到高级架构师的技术和认知高度。向厉害的人去学习是最有效减少时间摸索、精力浪费的方式。
我们选择的这个行业就一直要持续的学习,又很吃青春饭。
虽然大家可能经常见到说程序员年薪几十万,但这样的人毕竟不是大部份,要么是有名校光环,要么是在阿里华为这样的大企业。年龄一大,更有可能被裁。
送给每一位想学习Java小伙伴,用来提升自己。
[外链图片转存中…(img-k95X4ni3-1712881132885)]
本文到这里就结束了,喜欢的朋友可以帮忙点赞和评论一下,感谢支持!
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-QXFtSbO5-1712881132886)]















 1496
1496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









