







主从复制的方式
从节点复制主节点的数据后,就相当于给主从节点备份了,所谓的有备无患就是这个意思。那么主从复制的原理是怎么样的?其实主要就是三种复制方式:持续复制、全量复制、部分复制。
持续复制
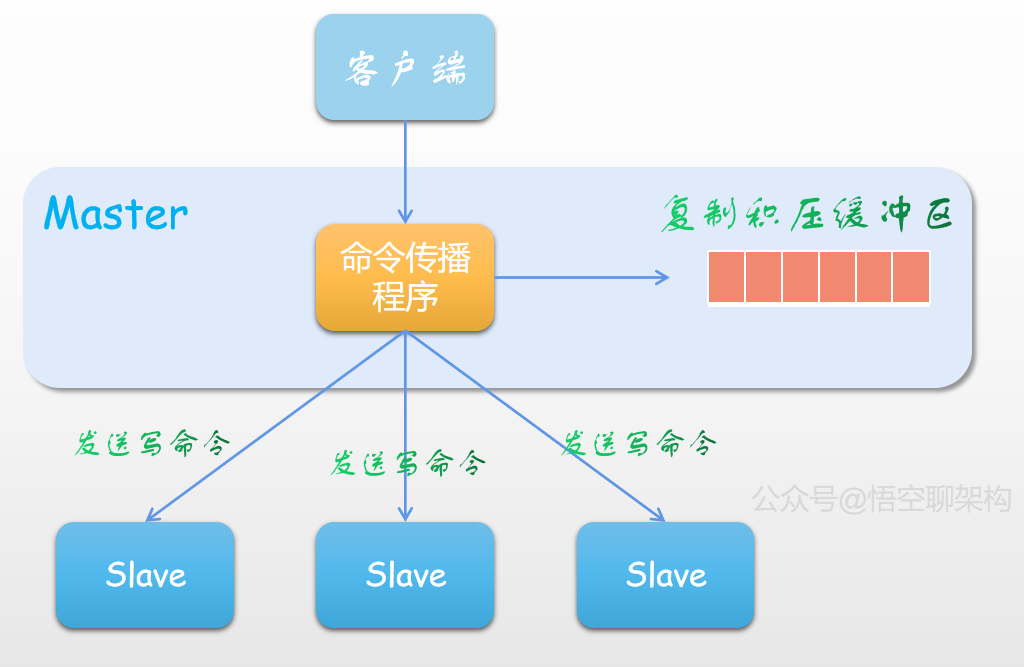
当有客户端的写命令请求到主节点后,主节点会做两件事:命令传播和将写命令写入到复制积压缓冲区。
原理图如下:
-
命令传播:将写命令持续发送给所有从服务器,保持主从数据一致。这个就可以理解为持续复制了。
-
复制积压缓冲区:其实就是一个有界队列,保存着最近传播的写命令,而队列里面的每个字节都有一个偏移量标识。复制积压缓冲区的作用和原理在部分复制的时候再细讲。
全量复制
用于主从节点第一次复制的场景。这在我们的软件开发中也很常见,比如你要把第三方的用户数据同步到自己的系统中,一开始肯定是把存量用户一次性给复制过来,后续有新增或更新的用户就采用增量更新就可以了。
当然全量复制的时候,数据量很大时,就会对主从节点和网络造成很大的开销,也就是常说的复制风暴,所以要避免不必要的全量复制,这个后面再讲怎么避免。
我们先来看下全量复制的原理图,然后我再来详细解释每一步怎么做的。

全量复制的流程图
全量复制总共可以分为 9 步:
(1)从节点发送 psync 命令进行数据同步,会发送 psync 命令,来告诉主节点我想干啥。
psync 命令格式如下:
psync {runId} {offset}
runId 是 每个 Redis 实例启动时随机生成的一个 ID,用来唯一标记这台 Redis 实例。由于第一次复制时,刚启动时会随机生成 runId,只有自己知道,外人是不知道的,所以从节点是不知道主节点的 runId 的,这个时候发送 psync 命令时 runId 就是一个问号。第一次复制时,offset 默认为 -1。
(2)主节点响应从节点,要开始全量复制了哦。
主节点响应从节点时分三种情况:全量复制、部分复制、旧版全量复制流程,这三种的区别后面会专门讲到。
而这个阶段就是全量复制:主节点告诉从节点,要开始全量复制了哦。响应如下命令:
FULLRESYNC <runId> <offset>
runId 就是主节点 id,offset 为复制偏移量。
(3)从节点收到主节点响应的 runId 和 offset,将其保存到从节点本地,这两个参数以后会用到。
(4)主节点在后台执行 bgsave 命令保存 RDB 文件到主节点的本地。
(5)主节点将第四步生成的 RDB 文件发送给从节点,子节点收到 RDB 文件后,保存到本地,后面会用到。这个发送的过程也可能直接超时。比如一个 6 GB 的 RDB 文件,100 MB 带宽下,至少需要 60 秒的传输时间,很容易超出默认配置的超时时间。那么从节点将放弃接收 RDB 文件,并清理已经下载的临时文件,导致全量复制失败。所以推荐不要超过 6 GB,如果 RDB 文件实在太大了,可以调大 repl-timeout 超时参数。
(6)在第五步的时候,主节点也没有闲着,会往另外一个缓冲区写东西,就是来自客户端的写命令数据。这个缓冲区叫做:复制客户端缓冲区。等第五步完成后,主节点就把这个缓冲区的数据发送给从节点。注意:对于高流量写入的场景,很容易就把复制客户端缓冲区给占满了,如果 60 秒内缓冲区消耗持续大于 64 MB 或者直接超过 256 MB 时,主节点将直接关闭复制客户端连接,造成全量不同失败。
(7)从节点在第五步保存完 RDB 文件后,就会把自身的旧数据清空。
(8)历经磨难,从节点终于可以开始加载 RDB 文件了,但是对于较大的 RDB 文件,加载 RDB 文件,进行数据恢复,还是非常耗时的,如果从节点负责响应读命令,则可能拿到过期或错误的数据。
(9)从节点加载完 RDB 后,如果当前节点开启了 AOF 持久化功能,从节点会执行 bgrewriteof 操作,保证 AOF 持久化文件可以立刻使用。
“总结下全量复制的步骤:
”
从节点给主节点发送命令;
主节点回复从节点,要开始全量复制了;
从节点保存主节点信息;
主节点开始生成 RDB 快照文件;
RDB 文件发给从节点,主节点发送 RDB 文件;
主节点发送缓存的客户端命令;
从节点清空旧数据;
从节点加载 RDB 文件;
从节点执行 AOF 操作。
由上面的几个步骤可以看出,全量复制是非常耗时的,可能比较大的时间开销如下:
-
第四步,主节点 fork 出子进程执行 bgsave 时,fork 操作耗时。
-
第五步,RDB 文件的网络传输时间。
-
第七步,从节点清空数据花时间。
-
第八步,从节点加载 RDB 的时间。
-
第九步,AOF 的重写时间。
所以除了第一次需要采用全量复制外,其他场景应该避免全量复制的发生。下面介绍另外一种复制方式,可以极大提高复制的效率。
部分复制
这个可以理解为增量更新,比如和第三方系统对接时,如果第三方有数据更新,定期进行增量更新就可以了。
而 Redis 主从的部分复制就是指当主从之间的网络故障等原因造成持续复制中断了,当从节点再次连上主节点后,主节点就补发数据给从节点,避免了全量复制的过高开销。补发数据的来源就是复制积压缓冲的数据。
原理图如下所示:
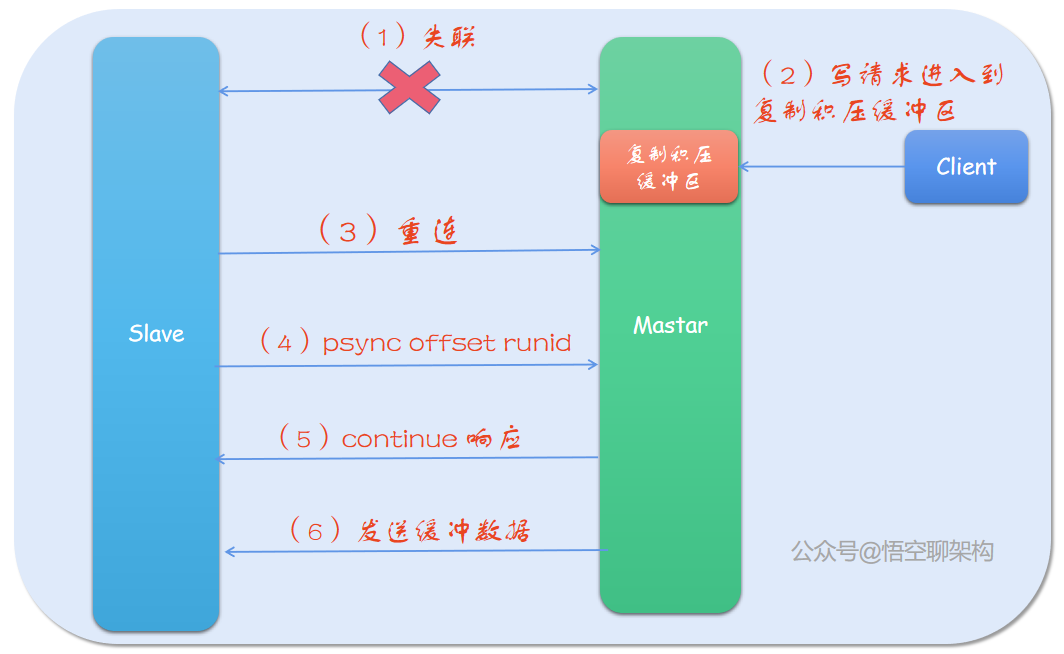
部分复制总共分为六步:
(1)当主节点之间失联后,如果时间超过了 repl-timeout 时间,主节点就认为从节点发生故障了,中断连接。
(2)主节点其实一直都在把客户端写命令放入复制积压缓冲区,所以即使断连了,主节点还是会保留断连期间的命令,但因为队列是固定的,当写命令太多时,就会导致部分命令被覆盖了。
(3)主从节点恢复连接。
(4)从节点发送 psync 命令给主节点,带有 runId 和 offset 参数,runId 是上一次复制时保存的主节点的 runId值,offset 是从节点的复制偏移量。
(5)主节点接收到从节点的命令后,先判断传过来的 runId 是否和自己匹配,如果不匹配,则进行全量复制;如果 runId 匹配,则响应 CONTINUE,告诉从节点,可以进行部分复制了。我要把复制积压缓冲区的数据发给你了哦,请准备好接收。
(6)主节点根据子节点发送的偏移量,将复制积压缓冲区的数据发送给子节点。
那复制积压缓冲区到底是怎么来根据偏移量来计算要发送哪些缓存数据的呢?我们接着往下看。
复制积压缓冲区
复制积压缓冲区有几个特点:
-
固定长度的队列。
-
最近传播的写命令,默认为 1 MB 大小,可调节大小。
-
队列中的每个字节都有对应的复制偏移量进行标识。如下图所示,每一个字节对应一个偏移量。

复制积压缓冲区
从节点重新连上主节点后,会发送 psync 命令,携带着偏移量 offset。比如 offset = 125,然后主节点拿着这个 125 去复制积压缓冲区找,125 正好在里面,然后就会执行部分复制的操作,将 125 以后的缓冲数据发送给从节点。
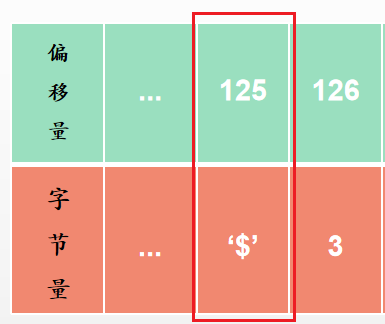
偏移量在复制积压缓冲区
如果 offset =10,主节点拿着这个 10 去复制积压缓冲区找,发现队列中最早的 offset 是 100,所以 100 之前的字节都被覆盖了,那么子节点就不能通过复制积压缓冲区拿到完整数据,所以只能通过全量复制的方式来同步。这个时候主节点就会发送一个 +FULLRESYNC的命令给子节点,告诉子节点,兄弟,你来得太晚了,只能使用全量同步的方式了。
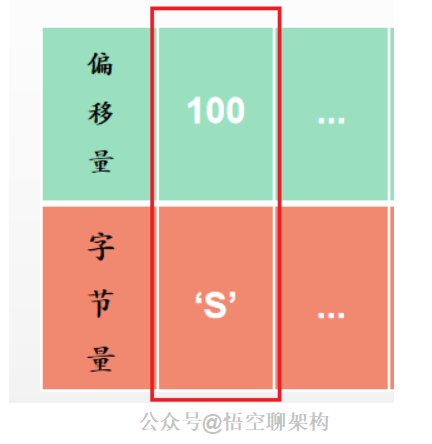
偏移量在在复制积压缓冲区
所以为了合理设置复制积压缓冲区的大小,有个计算公式推荐给大家:
2 * 恢复连接的时间(s) * 主节点写缓冲区的速度(MB/s)。
比如从节点需要 10 s 才能连上主节点,而主节点在这期间每秒产生 5 MB 的写数据,那么复制积压缓冲区的大小可以设置为 100 MB。(2 * 10 s * 5 MB/s = 100 MB)
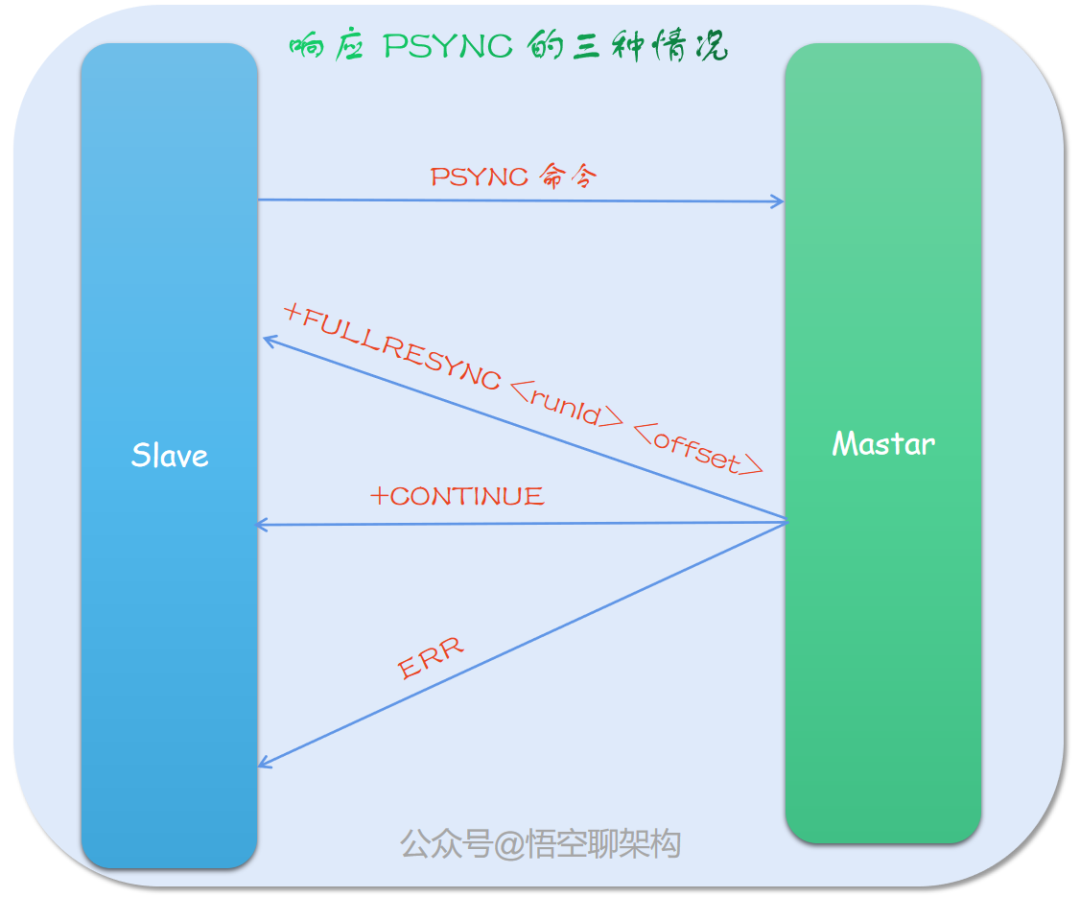
主节点响应从节点 psync 命令
在上面提到从节点不管是全量复制还是部分复制,最开始都会发送一个 psync 命令给主节点,那么主节点会根据这个命令携带的参数 runId 和 offset,来决定如何响应。
原理图如下所示:
-
全量复制,响应 +FULLRESYNC。
-
部分复制,响应 +CONTINUE。根据从节点发送 runId 是否和主节点相同,offset 偏移量是否在复制积压缓冲区来判断是响应全能量复制还是部分复制。
-
使用旧版全量复制,响应 -ERR。说明主服务器的版本低于 Redis 2.8,识别不了 PSYNC 命令。
复制时如何保持连接
说完上面主从节点的连接的结构,接下来的问题是这些节点如何在复制时保持连接呢?
也就是说主节点和从节点如何知道对方还存活着?其实就是通过心跳检测,这个在服务注册和服务发现里面经常提到。而主节点和从节点都会向对方发送心跳检测的命令。
主节点发送命令:
主节点会每隔 10 秒对从节点发送 ping 命令(也就是 10 秒一次心跳),从节点接收到 ping 命令后,会进行响应,所以这个 ping 命令可以用来判断从节点的存活性和连接状态。10 秒检测一次是可以调整的,用参数 repl-ping-slave-period 控制发送频率。

从节点发送命令:
而从节点也会每隔 1 秒发送一个命令给主节点。这个命令还挺拗口,叫做 REPLCONF ACK {offset} ,作用就是给主节点上报自身当前的复制偏移量的,这个偏移量用来检查复制数据是否丢失,如果丢失,主节点将补发丢失的数据。

补发丢失数据的操作和部分复制操作的区别:
-
补发丢失数据操作在主从服务器没有断线的情况下执行。
-
而部分复制操作是在主从服务器断线后重连之后执行。
从节点发送这个命令还可以实时检测主从节点的网络状态,类似于我们在命令行窗口 ping 服务器 ip,如果 ping 不通,则表示双方的网络连接有问题。
另外从节点的命令还可以用来计算主从的通信延迟,正常的延迟在 0~1 秒之间,如果超过了默认的 60 秒,则判定从节点下线,断开复制,等重新上线后,复制继续。而断开期间丢失的数据,则可能需要全量复制或部分复制,取决于从节点的 offset 偏移量在不在复制积压缓冲区。
















 1077
1077











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











