







FLATMEM:平坦内存模型DISCONTIGMEM:不连续内存模型SMARSEMEM:稀疏内存模型
Linux内核为了用统一的代码获取最大程度的兼容性,对物理内存的定义方面,引入了:内存结点(node)、内存区域(zone),内存页(page)的概念,下面我们来一一探究。
更多干货可见:高级工程师聚集地,助力大家更上一层楼!
1、内存节点node
内存节点的引入,是Linux为了最大程度的提高兼容性,将UMA和NUMA系统统一起来,对于UMA而言是只有一个节点的系统。
下面的代码部分,我们尽可能的只保留暂时用的到的部分,不涉及太多的体系架相关的细节。
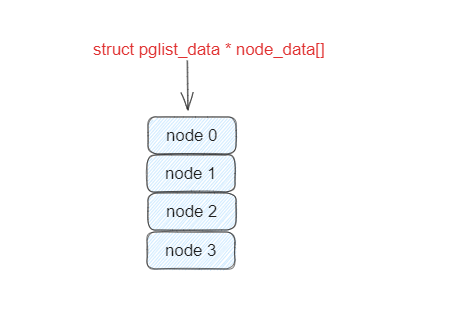
在Linux内核中,我们使用 typedef struct pglist_data pg_data_t表示一个节点
/\*
\* On NUMA machines, each NUMA node would have a pg\_data\_t to describe
\* it's memory layout. On UMA machines there is a single pglist\_data which
\* describes the whole memory.
\*
\* Memory statistics and page replacement data structures are maintained on a
\* per-zone basis.
\*/
typedef struct pglist\_data {
...
int node_id;
struct page \*node_mem_map;
unsigned long node_start_pfn;
unsigned long node_present_pages; /\* total number of physical pages \*/
unsigned long node_spanned_pages; /\* total size of physical page
range, including holes \*/
...
} pg\_data\_t;
node_id:每个节点都有自己的IDnode_mem_map:当前节点的struct page数组,用来管理这个节点的所有的页node_start_pfn:这个节点的起始页号node_present_pages:这个节点的真正可用的物理内存的页面数node_spanned_pages:这个节点所包含的物理内存的页面数,包括不连续的内存空洞
例如,64M 物理内存隔着一个 4M 的空洞,然后是另外的 64M 物理内存。
这样换算成页面数目就是,16K 个页面隔着 1K 个页面,然后是另外 16K 个页面。
这种情况下,
node_spanned_pages就是 33K 个页面,node_present_pages就是 32K 个页面。
内核使用了一个大小为 MAX_NUMNODES ,类型为 struct pglist_data 的全局数组 node_data[] 来管理所有的 NUMA 节点。
2、内存区域zone
2.1 各区域的布局
每一个节点,都被分成了一个个区域zone,我们看一下zone的定义:
enum zone\_type {
#ifdef CONFIG\_ZONE\_DMA
ZONE_DMA,
#endif
#ifdef CONFIG\_ZONE\_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG\_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG\_ZONE\_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
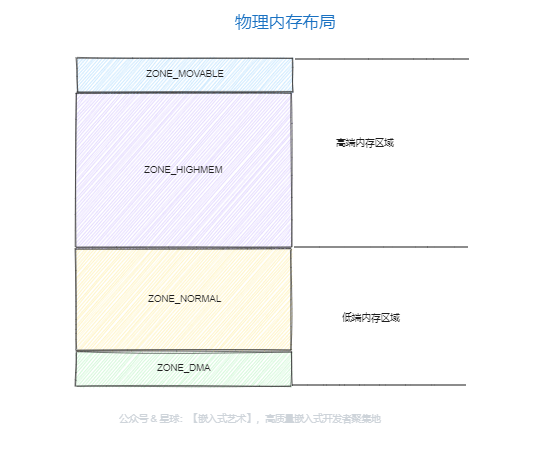
ZONE_DMA:用作DMA的内存。
DMA是这样一种机制:要把外设的数据读入内存或把内存的数据传送到外设,原来都要通过CPU控制完成,但是这会占用CPU,影响CPU处理其他事情,所以有了DMA模式。
CPU只需向DMA控制器下达指令,让DMA控制器来处理数据的传送,数据传送完毕再把信息反馈给CPU,这样就可以解放CPU。
ZONE_DMA32:对于 64 位系统,有两个 DMA 区域。除了上面说的 ZONE_DMA,还有 ZONE_DMA32。
ZONE_NORMAL:直接映射区,也就i是之前讲的从物理内存到虚拟内存的内核区域,通过加上一个常量直接映射。
ZONE_HIGHMEM:高端内存区
ZONE_MOVABLE:可移动区域,通过将物理内存划分为可移动分配区域和不可移动分配区域来避免内存碎片。
2.2 各区域的管理
上面我们大致了解了,每个zone的布局情况,下面我们来看看内核是如何对其进行管理的。
接着上面介绍的
pglist_data结构体
/*
* On NUMA machines, each NUMA node would have a pg_data_t to describe
* it's memory layout. On UMA machines there is a single pglist_data which
* describes the whole memory.
*
* Memory statistics and page replacement data structures are maintained on a
* per-zone basis.
*/
typedef struct pglist_data {
...
int node_id;
struct page *node_mem_map;
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
...
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
...
} pg_data_t;
nr_zones:用于统计NUMA节点内包含的物理内存区域个数,不是每个NUMA节点都会包含以上介绍的所有物理内存区域,NUMA节点之间所包含的物理内存区域个数是不一样的。
事实上只有第一个
NUMA节点可以包含所有的物理内存区域,其它的节点并不能包含所有的区域类型,因为有些内存区域比如:ZONE_DMA,ZONE_DMA32必须从物理内存的起点开始。这些在物理内存开始的区域可能已经被划分到第一个NUMA节点了,后面的物理内存才会被依次划分给接下来的NUMA节点。因此后面的NUMA节点并不会包含ZONE_DMA,ZONE_DMA32区域。
ZONE_NORMAL、ZONE_HIGHMEM和ZONE_MOVABLE是可以出现在所有NUMA节点上的。
node_zones[MAX_NR_ZONES]:node_zones该数组包括了所有的zone物理内存区域node_zonelists[MAX_ZONELISTS]:是struct zonelist类型的数组,它包含了备用NUMA节点和这些备用节点中的物理内存区域。
下面我们看一下
struct zone结构体
struct zone {
......
struct pglist\_data \*zone_pgdat;
struct per\_cpu\_pageset __percpu \*pageset;
unsigned long zone_start_pfn;
/\*
\* spanned\_pages is the total pages spanned by the zone, including
\* holes, which is calculated as:
\* spanned\_pages = zone\_end\_pfn - zone\_start\_pfn;
\*
\* present\_pages is physical pages existing within the zone, which
\* is calculated as:
\* present\_pages = spanned\_pages - absent\_pages(pages in holes);
\*
\* managed\_pages is present pages managed by the buddy system, which
\* is calculated as (reserved\_pages includes pages allocated by the
\* bootmem allocator):
\* managed\_pages = present\_pages - reserved\_pages;
\*
\*/
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char \*name;
......
/\* free areas of different sizes \*/
struct free\_area free_area[MAX_ORDER];
/\* zone flags, see below \*/
unsigned long flags;
/\* Primarily protects free\_area \*/
spinlock\_t lock;
......
} ____cacheline_internodealigned_in_
zone_start_pfn:表示属于这个zone的第一个页spanned_pages:看注释我们可以知道,spanned_pages = zone_end_pfn - zone_start_pfn,表示该区域的所有物理内存的页面数,包括内存空洞present_pages:看注释我们可以知道,present_pages = spanned_pages - absent_pages(pages in holes),表示该区域真实存在的物理内存页面数,不包括空洞managed_pages:看注释我们可以知道,managed_pages = present_pages - reserved_pages,被伙伴系统管理的所有页面数。per_cpu_pageset:用于区分冷热页,
什么叫冷热页呢?咱们讲 x86 体系结构的时候讲过,为了让 CPU 快速访问段描述符,在 CPU 里面有段描述符缓存。CPU 访问这个缓存的速度比内存快得多。同样对于页面来讲,也是这样的。如果一个页被加载到 CPU 高速缓存里面,这就是一个热页(Hot Page),CPU 读起来速度会快很多,如果没有就是冷页(Cold Page)。由于每个 CPU 都有自己的高速缓存,因而 per_cpu_pageset 也是每个 CPU 一个。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数嵌入式工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年嵌入式&物联网开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上嵌入式&物联网开发知识点,真正体系化!
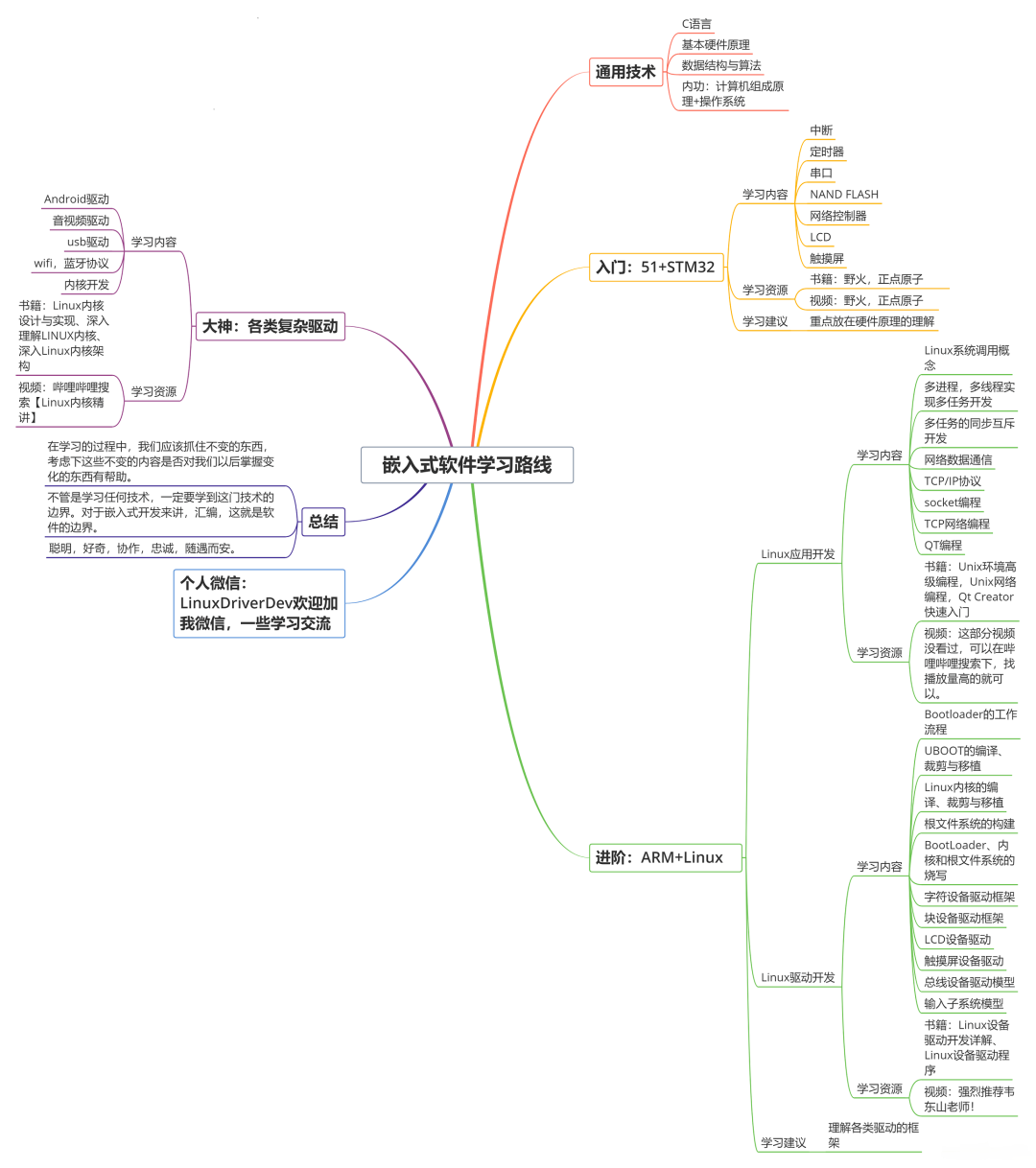
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以+V:Vip1104z获取!!! (备注:嵌入式)

最后
资料整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下小编~
你的支持,我的动力;祝各位前程似锦,offer不断,步步高升!!!
纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
如果你觉得这些内容对你有帮助,可以+V:Vip1104z获取!!! (备注:嵌入式)
最后
资料整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下小编~
你的支持,我的动力;祝各位前程似锦,offer不断,步步高升!!!














 957
957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









