






目录
1 系统内存layout
(待更新)
2 内存管理器
2.3 SLAB
2.3.1 概述
Slabs manage frequently required data structures to ensure that memory managed page-by-page by the buddy system is used more efficiently and that instances of the data types can be allocated quickly and easily as a result of caching.
关于slab分配器,有以下几个关键字:
- 小块内存,slab分配器用于管理小块内存,通过/proc/slabinfo,可以获得更加直观的信息;
 filp: 每个slab由2个page构成,即8K,包含32个object,即struct file,每个size为256字节,当前系统各种共有59K个struct file结构;
filp: 每个slab由2个page构成,即8K,包含32个object,即struct file,每个size为256字节,当前系统各种共有59K个struct file结构; - Cache,slab分配器构建于page Buddy分配器上,它需要尽量避免频繁的从Buddy分配器上分配page,所以,slab本身需要缓存一部分的page;
- 碎片化,对于避免碎片化,object以slab为单位组织起来,将碎片控制在一个较小的范围内;同时维护partial slab,尽量避免申请新的slab;
对于目前的Linux Kernel中的slab分配器,可以参考连接What to choose between Slab and Slub Allocator in Linux Kernel?
Slub is the next-generation replacement memory allocator, which has been the default in the Linux kernel since 2.6.23. It continues to employ the basic "slab" model, but fixes several deficiencies in Slab's design, particularly around systems with large numbers of processors. Slub is simpler than Slab.
以下几个小节,我们将主要基于SLUB的实现。
2.3.2 Slab Freelist
每个slab内的空闲object会组成一个freelist,类似如下结构,
slab
obj
+-----------------------------------------------+
| | | | | | | | | | | | |
+-----------------------------------------------+
\__^\__^\__^\__^\__^\__^\__^\__^\__^\__^\__^freelist的创建可以参考以下函数:
allocate_slab()
---
for_each_object_idx(p, idx, s, start, page->objects) {
setup_object(s, page, p);
if (likely(idx < page->objects))
set_freepointer(s, p, p + s->size);
else
set_freepointer(s, p, NULL);
}
---
注:random freelist是将object的顺序随机话,这并不是处于对性能的考虑,而是为了安全,参考如下连接:https://mxatone.medium.com/randomizing-the-linux-kernel-heap-freelists-b899bb99c767
SLUB使用cmpxhg操作freelist,实现object的申请和释放,操作大致如下:
get_object()
{
while (1)
{
object= c->freelist;
next = *object;
if (cmpxchg(&c->freelist, object, next) == object)
break;
}
return object
}
put_object(object)
{
while (1) {
prev = c->freelsit;
*object = prev;
if (cmpxchg(&c->freelist, prev, object) == prev)
break;
}
}然而,以上代码并不够,如下:
Round 1 - CPU0: Slab [ obj0 -> obj1 -> obj2 -> obj3 ]
cmpxchg freelist (old = obj0, new = obj1) START
Round 2 - CPU1: Slab [ obj0 -> obj1 -> obj2 -> obj3 ]
Get obj0
Round 3 - CPU1: Slab [ obj1 -> obj2 -> obj3 ]
Get obj1
Round 4 - CPU1: Slab [ obj2 -> obj3 ]
Free obj0
Round 5 - CPU0: Slab [ obj0 -> obj2 -> obj3 ]
cmpxchg freelist (old = obj0, new = obj1) SUCCESS
Right Now: Slab [ obj1 -> obj2 -> obj3 ]
已经被申请走的obj1又被放回了freelist所以,为了避免这个问题,SLUB又引入了一个transaction id,并使用cmpxchg_double来完成这个操作,参考代码:
slab_alloc_node()
---
void *next_object = get_freepointer_safe(s, object);
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
object, tid,
next_object, next_tid(tid)))) {
goto redo;
}
---
这个cmpxchg_double的操作就是SLUB的核心技术。
2.3.3 Slab Cache
slab分配器的核心数据结构叫kmem_cache,这也说明cache这个功能在slab中占的比重很大;slab是一个object的集合,每个slab可以是若干个连续的page,为避免频繁从page分配器中申请和释放的开销,这些slab在完全空闲之后,并不会立即释放回系统,而是暂存在slab中。
注:Buddy子系统在核数比较多的情况下,会在zone->lock这个自旋锁上产生很严重的竞争,使得系统出现高达40%+的sys cpu利用率;类似的问题可以通过修改/proc/sys/vm/percpu_pagelist_fraction来调整pcp list的high和batch缓解。
slab cache有以下几个部分:
- per-cpu working slab,即kmem_cache_cpu.page,partitially or fully free;
- per-cpu partial slabs,即kmem_cache_cpu.partial,通过CONFIG_SLUB_CPU_PARTIAL开启(default y),partitially or fully free;
- per-node paritial slab,partitially or fully free,最多10个
那么,slab如何在这些位置之间转移呢?
- per-cpu working slab,当kmem_cache_cpu.page,我们称为slab A,没有空闲的object时,即freelist为空,则需要重新补充slab;此时有两种途径,partial list或者buddy;最开始,partial list为空,所以走buddy;
- no list,slab A被替换之后,它本身并不会被kmem_cache记录,而是需要从被申请的object获取,参考函数cache_from_object(),object本身不会保存kmem_cache信息,但是其背后的page结构体有保存;
- 当slab A中的object被释放时,参考函数__slab_free(),此时page->freelist为空,且没有被frozen,除了将object释放回之外,还会将slab frozen,并将其加入per-cpu paritial list,这是通过put_cpu_partial()完成的;成功执行了frozen操作的cpu将会最终执行put_cpu_paritial()的操作;
- 当slab A被frozen到per-cpu partial list之后,即使后续object全部释放回,它仍然会被保留在per-cpu partial list里,参考__slab_free()里面的!was_frozen条件;
- per-cpu paritial list的容量是有限制的,参考/sys/kernel/slab/filp/cpu_partial为13,超过限制之后,这些slab会被unfreeze,并加入到per-node partial list,参考函数unfreeze_partials();
- per-node partial list的容量也是有限制的,参考/sys/kernel/slab/filp/min_partial为5,超过这个限制且page->inuse为0时,page就会被释放回系统;unfreeze_paritals()转移到per-node partial list的slab并不一定是全free的,所以,per-node partial list的容量是很有可能超过min_partial的;因为slab已经被unfreeze,随着后续上面object的持续释放,当最终slab为全free时,其会被释放回系统;
2.3.4 Slab Shrink
shrink_slab()其实并不是shrink slab的cache,在Wolfgang Mauerer的《Professional Linux® Kernel Architecture》中有下面的描述:

想要清除kmem_cache中的slab cache,有两种方式,
- echo 1 > /sys/kernel/slab/filp/shrink
- 销毁这个kmem_cache
在实践中,曾出现过slab cache 50G+导致系统级OOM的例子,问题的原因是,系统会为每个memory cgroup创建一个slab的子slab,如果这些memory cgroup不删除,这些子slab连同其中的slab cache会一直占据系统的内存,由于slab cache无法被回收,最终累积到了50G+;社区曾经尝试支持slab shrinker,但是由于牵扯性能,目前仍没有进展,参考连接:https://www.spinics.net/lists/linux-mm/msg242443.html
在5系内核中,这个问题已经被解决了,参考commit:
commit 9855609bde03e2472b99a95e869d29ee1e78a751
Author: Roman Gushchin <roman.gushchin@linux.dev>
Date: Thu Aug 6 23:21:10 2020 -0700
mm: memcg/slab: use a single set of kmem_caches for all accounted allocations
This is fairly big but mostly red patch, which makes all accounted slab
allocations use a single set of kmem_caches instead of creating a separate
set for each memory cgroup.
Because the number of non-root kmem_caches is now capped by the number of
root kmem_caches, there is no need to shrink or destroy them prematurely.
They can be perfectly destroyed together with their root counterparts.
This allows to dramatically simplify the management of non-root
kmem_caches and delete a ton of code.
...............
2.4 PER-CPU
对于per-cpu变量,我们可以将其简单的理解为一个数组,比如:
int example[NR_CPUS];
cpu0 -> example[0] cpu1 -> example[1] cpu2 -> example[2] cpu3 -> example[3]由于每个cpu都有自己的存储空间,因此,在更新的时候,不需要考虑同步;
per-cpu使用的一个经典场景是统计数据;比如,统计系统中某个事件发生的次数;最终的结果,需要遍历per-cpu变量的每个cpu的值,做sum;但是,这个遍历的过程并不是原子的,所以,这种方式缺乏准确性,这也就导致,per-cpu变量没法做计数,尤其是,需要考虑计数为某个特定的值时做某个特定的事,比如类似struct kref的功能;内核中,有一个percpu-refcount的变量,它有per-cpu和atomic两种模式,正常工作是per-cpu模式,当需要做最终清零的时候,会转换到atomic模式。
内核的per-cpu变量,是定义了一种特殊的数据类型,并提供了一套访问API。它有两种模式,即
- 静态的,即通过DEFINE_PER_CPU()宏定义的;
- 动态的,即通过alloc_percpu()申请的;
2.4.1 pcpu_chunk概述
pcpu_chunk是percpu变量的'slab';它的核心数据包括以下:
- pcpu_chunk本身,这里面主要包含这个chunk的元数据,包括,
- alloc_map,维护空间是否空闲的bitmap,每个bit代表4字节,这个是percpu变量申请的最基本单位,参考pcpu_alloc_area();
- md_blocks,pcpu_block_md数组,保存的是每个block的状态,block大小为4K;
- base_addr,chunk对应区域的基地址
- populated[],维护空间是否可用的bitmap,所谓可用,即申请了物理page;
- 虚拟地址,保存在pcpu_chunk.base_addr;pcpu_chunk有点类似于用户态程序的地址空间,刚开始时并没有对应的物理存储空间,而只有虚拟地址,只有在申请到这个区域的时候,才会做最终的申请和映射,参考函数pcpu_populate_chunk();
- 物理page,并没有一个成员保存这些page,获取这些page要从虚拟地址转换,参考接口vmalloc_to_page();
另外,有以下全局变量作为申请空间的基准:
这是从一个64核的intel机器上获取的,
pcpu_nr_units : 64 (64 cores)
pcpu_unit_pages : 64
pcpu_nr_groups : 2 (2 nodes)
pcpu_group_sizes: 8M/8M (16M, 64 * 64 * 4K)
- 整个chunk的虚拟地址和物理内存都是16M,每个cpu对应256K;
- pcpu_chunk中nr_pages和alloc_map等,都是以pcpu_units_pages为准,即256K,这是因为每个percpu变量都包含对应CPU核数倍的空间;
pcpu_chunk按照剩余空间的多少被保存在pcpu-slot[]上,
pcpu_chunk_relocate()
-> pcpu_chunk_slot()
---
if (chunk->free_bytes < PCPU_MIN_ALLOC_SIZE || chunk->contig_bits == 0)
return 0;
return pcpu_size_to_slot(chunk->free_bytes);
---
static int pcpu_size_to_slot(int size)
{
if (size == pcpu_unit_size)
return pcpu_nr_slots - 1;
return max(fls(size) - PCPU_SLOT_BASE_SHIFT + 2, 1);
}
在pcpu-slot[pcpu_nr_slots - 1]里面连接的pcpu_chunk都是全空闲的。
2.4.2 pcpu_chunk的映射
pcpu_chunk在从pcpu_create_chunk()中创建出来时,只包含了pcpu_chunk结构本身和一段虚拟地址,并没有真实的内存对应,参考代码:
pcpu_create_chunk()
---
chunk = pcpu_alloc_chunk(gfp);
vms = pcpu_get_vm_areas(pcpu_group_offsets, pcpu_group_sizes,
pcpu_nr_groups, pcpu_atom_size);
chunk->data = vms;
chunk->base_addr = vms[0]->addr - pcpu_group_offsets[0];
---
这段虚拟地址来自vmalloc区,在pcpu_get_vm_areas()中构建vm_struct时,使用的caller直接赋值为pcpu_get_vm_areas,参考代码:
pcpu_get_vm_areas()
---
/* insert all vm's */
for (area = 0; area < nr_vms; area++)
setup_vmalloc_vm(vms[area], vas[area], VM_ALLOC,
pcpu_get_vm_areas);
---所以,我们会在/proc/vmallocinfo里发现如下信息: 
真实的物理内存的申请是在申请到这块区域的时候,
pcpu_alloc()
---
page_start = PFN_DOWN(off);
page_end = PFN_UP(off + size);
pcpu_for_each_unpop_region(chunk->populated, rs, re,
page_start, page_end) {
ret = pcpu_populate_chunk(chunk, rs, re, pcpu_gfp);
spin_lock_irqsave(&pcpu_lock, flags);
pcpu_chunk_populated(chunk, rs, re, true);
spin_unlock_irqrestore(&pcpu_lock, flags);
}
---
2.4.3 pcpu_chunk的balance
参考函数pcpu_balance_workfn(),balance主要做以下两件事:
- 释放完全空闲的pcpu_chunk,触发时机参考函数free_percpu();
- 保证系统中的populated page的数量处在一定的水平,即PCPU_EMPTY_POP_PAGES_HIGH (4);触发时机包括,当populate page数量小于PCPU_EMPTY_POP_PAGES_LOW(2)时,或者出现atomic申请失败的时候,参考函数pcpu_alloc(),当atomic申请时,不会执行populate;
在补充populate page时,如果没有存在unpopulated page的pcpu_chunk,还会申请新的pcpu_chunk。
注:这里的page是包括所有cpu的page
2.4.4 percpu变量的访问
首先我们看pcpu_alloc()返回的地址是什么?
pcpu_alloc()
---
/* clear the areas and return address relative to base address */
for_each_possible_cpu(cpu)
memset((void *)pcpu_chunk_addr(chunk, cpu, 0) + off, 0, size);
ptr = __addr_to_pcpu_ptr(chunk->base_addr + off);
return ptr;
---
#define __addr_to_pcpu_ptr(addr) \
(void __percpu *)((unsigned long)(addr) - \
(unsigned long)pcpu_base_addr + \
(unsigned long)__per_cpu_start)
/* the address of the first chunk which starts with the kernel static area */
void *pcpu_base_addr __ro_after_init;返回给用户的地址,并不是原有的基于pcpu_chunk.base_addr的地址,而是做了特殊的处理;
注:这应该是为了保证对percpu变量的方式只能使用percpu提供的API
对percpu变量的指针的访问,参考代码
#define this_cpu_ptr(ptr) \
({ \
__verify_pcpu_ptr(ptr); \
SHIFT_PERCPU_PTR(ptr, my_cpu_offset); \
})
#define my_cpu_offset per_cpu_offset(smp_processor_id())
#define per_cpu_offset(x) (__per_cpu_offset[x])
setup_per_cpu_areas()
---
delta = (unsigned long)pcpu_base_addr - (unsigned long)__per_cpu_start;
for_each_possible_cpu(cpu)
__per_cpu_offset[cpu] = delta + pcpu_unit_offsets[cpu];
---
pcpu_unit_offset[]对应的是各个cpu的unit整个chunk中的偏移,比如在一个8核的cpu上,
0 1 2 3 4 5 6 7
|----+----+----+----+----+----+----+----|
\___________________ ___________________/
v
chunk (8 * unit)
3 地址空间
(待更新)
4 内存回收
4.1 Watermark

high和low水线决定的是kswapd的工作,即free pages低于low时开始,达到high时停止;min决定的是direct reclaim,即普通的申请操作在free pages低于min时,必须进行direct reclaim,只有特别的操作,比如内存回收过程中的内存申请才可以使用min水线以下的内存。
注:在64bit系统上,不需要highmem,所以本小节不考虑highmem相关的代码
4.1.1 如何计算watermark
查看当前系统各个zone的水线可以通过/proc/zoneinfo;watermark的计算,参考如下函数
__setup_per_zone_wmarks()
---
unsigned long pages_min = min_free_kbytes >> (PAGE_SHIFT - 10)
...
for_each_zone(zone) {
u64 tmp;
tmp = (u64)pages_min * zone->managed_pages;
do_div(tmp, lowmem_pages);
zone->watermark[WMARK_MIN] = tmp;
tmp = max_t(u64, tmp >> 2,
mult_frac(zone->managed_pages,
watermark_scale_factor, 10000));
zone->watermark[WMARK_LOW] = min_wmark_pages(zone) + tmp;
zone->watermark[WMARK_HIGH] = min_wmark_pages(zone) + tmp * 2;
}
---
其中有两个关键的因子:
- min_free_kbytes,即/proc/sys/vm/min_free_kbytes,该参数决定的是整个系统的min水线线;计算zone的min水线,只需考虑全局和zone的内存的比例即可;
- watermark_scale_factor,即/proc/sys/vm/watermark_scale_factor,该参数决定的是low和high的值;值越高,则kswapd会越早介入,回收的也越多;
4.1.2 watermark如何工作
参考函数__alloc_pages_nodemask(),进入时,alloc_flags被赋值为ALLOC_WMARK_LOW,然后进入get_page_from_freelist(),
get_page_from_freelist()
---
mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK];
if (!zone_watermark_fast(zone, order, mark,
ac_classzone_idx(ac), alloc_flags)) {
...
}
---
此时,使用的watermark为low;如果申请内存失败的话,会进入__alloc_pages_slowpath(),alloc_flags会被gfp_to_alloc_flags()重新赋值,其中包括ALLOC_WMARK_MIN,同时,唤醒kswapd,
__alloc_pages_slowpath()
---
if (gfp_mask & __GFP_KSWAPD_RECLAIM)
wake_all_kswapds(order, gfp_mask, ac);
---
__GFP_KSWAPD_RECLAIM为比较普遍的flags,比较严格的GFP_NOWAIT、GFP_ATOMIC
都带有这个flags。在min水线依然申请不到内存时,有些申请操作可以击穿min水线,参考函数
static inline int __gfp_pfmemalloc_flags(gfp_t gfp_mask)
{
if (unlikely(gfp_mask & __GFP_NOMEMALLOC))
return 0;
if (gfp_mask & __GFP_MEMALLOC)
return ALLOC_NO_WATERMARKS;
if (in_serving_softirq() && (current->flags & PF_MEMALLOC))
return ALLOC_NO_WATERMARKS;
if (!in_interrupt()) {
if (current->flags & PF_MEMALLOC)
return ALLOC_NO_WATERMARKS;
else if (oom_reserves_allowed(current))
return ALLOC_OOM;
}
return 0;
}
其中有两个关键的flag,
- __GFP_MEMALLOC,其comment已经解释的很清楚了,如下:
%__GFP_MEMALLOC allows access to all memory. This should only be used when
the caller guarantees the allocation will allow more memory to be freed
very shortly e.g. process exiting or swapping. Users either should
be the MM or co-ordinating closely with the VM (e.g. swap over NFS).
- PF_MEMALLOC,该flag主要给进程上下文使用,通过memalloc_noreclaim_save()赋值,其调用者包括,__perform_reclaim()、__node_reclaim()等,同时kswapd本身是带有这个flag的;
注:内存回收有关的路径都需要PF_MEMALLOC;比较特殊的场景是ceph-nbd,其在client端包括一个内核态的nbd设备驱动还有一个用户态的处理程序,用来和ceph后端通信;在系统需要回收脏页的时候,数据需要通过nbd用户态程序发给后端,但是此时nbd程序因为无法申请到内存而进入回收,于是造成了死锁,一种比较hack的解决的方式即是给这些nbd程序赋予PF_MEMALLOC
4.1.3 watermark是绝对的吗?
申请内存时会绝对按照watermark规定的数量操作吗?答案是否定的,有以下几个场景,
- lowmem_reserve,内存的zone有high->low->dma->dma32(注,64bit系统上没有high);当高位zone申请不到时,会尝试向低位zone申请,以为越低位内存资源越珍贵,lowmem_reserve就是为了防止高位将低位资源耗尽,在zone_watermark_ok()中,需要考虑lowmem_reserve的值。
- ALLOC_HARDER与ALLOC_HIGH,参考代码:
__zone_watermark_ok()
---
const bool alloc_harder = (alloc_flags & (ALLOC_HARDER|ALLOC_OOM));
if (alloc_flags & ALLOC_HIGH)
min -= min / 2;
if (likely(!alloc_harder)) {
...
} else {
if (alloc_flags & ALLOC_OOM)
min -= min / 2;
else
min -= min / 4;
}
---
ALLOC_HIGH来自__GFP_HIGH,ALLOC_HARDER则来自__GFP_ATOMIC,参考函数
gfp_to_alloc_flags()
4.1.4 kswapd启停的条件
我们已经知道了,wamtermark low和high决定了kswapd的启停,但事实上, 决定kswapd启停的不仅仅是watermark,还有其他条件;参考函数pgdat_balanced(),
pgdat_balanced()
---
for (i = 0; i <= classzone_idx; i++) {
zone = pgdat->node_zones + i;
mark = high_wmark_pages(zone);
if (zone_watermark_ok_safe(zone, order, mark, classzone_idx))
return true;
}
---
我们看到,除了high watermark,还有一个order参数,而__zone_water_mark_ok()除了检查watermark,还要检查是不是有对应order的page。order来自pgdat->kswapd_order,wakeup_kswapd()会设置这个值,不过kswapd每次执行完回收之后,会把kswapd_order清空,所以,也不至于在碎片化的系统上一直执行kswad回收。
另外,kswapd在high watermark满足之后, 会进入“浅睡眠”模式,参考当初提交patch的comment,
After kswapd balances all zones in a pgdat, it goes to sleep. In the
event of no IO congestion, kswapd can go to sleep very shortly after the
high watermark was reached. If there are a constant stream of allocations
from parallel processes, it can mean that kswapd went to sleep too quickly
and the high watermark is not being maintained for sufficient length time.
This patch makes kswapd go to sleep as a two-stage process. It first
tries to sleep for HZ/10. If it is woken up by another process or the
high watermark is no longer met, it's considered a premature sleep and
kswapd continues work. Otherwise it goes fully to sleep.
这种睡眠机制的目的是尽量维持内存水线在high,进而可以避免直收的发生。
4.2 node reclaim
参考连接
NUMA (Non-Uniform Memory Access): An Overview - ACM Queue
The impact of reclaim on the system can therefore vary. In a NUMA system multiple types of memory will be allocated on each node. The amount of free space on each node will vary. So if there is a request for memory and using memory on the local node would require reclaim but another node has enough memory to satisfy the request without reclaim, the kernel has two choices:
• Run a reclaim pass on the local node (causing kernel processing overhead) and then allocate node- local memory to the process.
• Just allocate from another node that does not need a reclaim pass. Memory will not be node local, but we avoid frequent reclaim passes. Reclaim will be performed when all zones are low on free memory. This approach reduces the frequency of reclaim and allows more of the reclaim work to be done in a single pass.
For small NUMA systems (such as the typical two-node servers) the kernel defaults to the second approach. For larger NUMA systems (four or more nodes) the kernel will perform a reclaim in order to get node-local memory whenever possible because the latencies have higher impacts on process performance.
There is a knob in the kernel that determines how the situation is to be treated in /proc/sys/vm/zone_reclaim. A value of 0 means that no local reclaim should take place. A value of 1 tells the kernel that a reclaim pass should be run in order to avoid allocations from the other node. On boot- up a mode is chosen based on the largest NUMA distance in the system.
4.3 GFP flags
本小节主要看下几个常见的gfp flags的作用及其如何在代码中发挥作用;
- __GFP_KSWAPD_RECLAIM,在低于low水线时,唤醒kswapd;
- __GFP_DIRECT_RECLAIM,可以进行直接回收,没有该flag的话,禁止执行该操作,参考函数__alloc_pages_slowpath();
- __GFP_IO,指在内存回收的过程中可以执行swap out,参数函数shrink_page_list();
- __GFP_FS,指在内存回收的过程中可以执行write out,或者可以在shrink_slab()时回收文件系统中的对象,参考函数super_cache_scan();
- __GFP_HARDWALL,在cpuset存在情况下,禁止从其他node申请内存,参考函数__cpuset_node_allowed();
- __GFP_HIGH,在4.1.3小节中有提到,可以压低1/2的low或者min水线;
- __GFP_ATOMIC,同样在4.1.3小节中,可以压低1/4的low或者min水线;
申请内存时基本都是以上flag的组合,需要特别说明的是:
#define GFP_ATOMIC (__GFP_HIGH|__GFP_ATOMIC|__GFP_KSWAPD_RECLAIM)
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
#define GFP_NOWAIT (__GFP_KSWAPD_RECLAIM)
#define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
- GFP_ATOMIC,不允许进行直接回收,但是可以唤醒kswapd,而且可以降低3/4的low或者min watermark,所以,尽量少用GFP_ATOMIC;
- GFP_NOWAIT,回收行为与GFP_ATOMIC类似,但是,优先级比较低;
- GFP_KERNEL和GFP_USER只差一个__GFP_HARDWALL;GFP_USER通常用在申请用户态匿名页;
4.4 active和inactive
(2) (1)
| |
v (3) v (4)
|-----------| -> |-----------| -> evict
active inactive
|
v
(2)
(1) 进入inactive list
(2) page 升级进入 active list
(3) page 降级进入inactive list
(4) page 继续降级被回收本小节提到主要针对file page cache,anon page和swap将单辟一节讲解。
4.4.1 page的lru状态
lru中的page有三种状态,0、Referenced和Active,每次访问都会推进page状态,到Active时,则意味着可以进入Active list了,换句话说两次访问才能保证一个page进入Active list。
page cache主要有两种访问方式:
- read(),通过调用mark_page_accessed(),推进page的状态,参考函数generic_file_buffered_read();一个新创建的page cache虽然初始状态为0,但是马上就会被访问并被mark_page_accessed(),但是预读的page并不会马上被访问,它会继续保持0状态直到下次被访问;
- mmap(),此时无法直接调用类似mark_page_accessed()的函数推进page状态(通过pagefault的方式低效掉令人发指);于是推进page状态的任务延后到了shrink_inactive_list(),page_check_references()会通过page_referenced_one()检测页表项中的young状态位,来判断该page在过去是否被访问过;
page_check_references()
---
referenced_ptes = page_referenced(page, 1, sc->target_mem_cgroup,
&vm_flags);
referenced_page = TestClearPageReferenced(page);
if (referenced_ptes) {
SetPageReferenced(page);
if (referenced_page || referenced_ptes > 1)
return PAGEREF_ACTIVATE;
/*
* Activate file-backed executable pages after first usage.
*/
if (vm_flags & VM_EXEC)
return PAGEREF_ACTIVATE;
}
return PAGEREF_KEEP;
---
4.4.2 active list
升入active list的条件是苛刻的,主要由以下三种方式:
- 通过read() -> generic_file_buffered_read()调用mark_page_accessed()两次;
- shrink_page_list()通过page_check_references()检查mmap page的访问情况,两次检测到被访问则升级;不过,这里的"访问"与read()有很大不同;read()被调用两次就是访问两次,但是访问mmap的地址两次却只能被vmscan检测为一次,第二次需要在vmscan清除目录项young标记之后,再次访问。另外,当page的多个映射都被访问或者mapping是可执行的,其可以直接升级到active list,这部分最主要针对的是系统中的共享库。
- 另外一种情况与workingset机制有关,其可以追踪被evict的page的“年龄”,如果“年龄”还小,则认为比较热,在最开始加入page cache时,直接升入active;
workingset的中的年龄,即lruec->inactive_age,其计数了inactive_list中
activate和evict两个事件,以此作为事件基准;同时,将相关信息保存进xarray
中原page保存的位置。参考mm/workingset.c中的comment
1. The sum of evictions and activations between any two points in
time indicate the minimum number of inactive pages accessed in
between.
2. Moving one inactive page N page slots towards the tail of the
list requires at least N inactive page accesses.
判断是否热的基准,参考函数
workingset_refault()
---
refault = atomic_long_read(&lruvec->inactive_age);
active_file = lruvec_lru_size(lruvec, LRU_ACTIVE_FILE, MAX_NR_ZONES);
refault_distance = (refault - eviction) & EVICTION_MASK;
if (refault_distance <= active_file) {
return true;
}
return false;
---从active list降级却相对简单,
shrink_page_list()
---
if (page_referenced(page, 0, sc->target_mem_cgroup,
&vm_flags)) {
nr_rotated += hpage_nr_pages(page);
if ((vm_flags & VM_EXEC) && page_is_file_cache(page)) {
list_add(&page->lru, &l_active);
continue;
}
}
ClearPageActive(page); /* we are de-activating */
list_add(&page->lru, &l_inactive);
---除了依旧被优待的可执行文件的page cache之外,其他一律无条件降级;之后,在inactive list里或升级或者Evict,则需要各自的"奋斗"了。
4.4.2 inactive list
在inactive list中page的去留,参考函数page_check_references(),总结起来就是:
- 没有mapping的,只有Referenced且Dirty的page可以避免Evict;
- 有mapping的,看对应pte的young标记,如果有,则至少可以keep,如果没有,同上;
对于可以被回收的page,主要分成以下情况:
Dirty,针对dirty page的回收策略,除了没有Referenced标记之外,还有以下策略,参考代码comment,
来自shrink_page_list()注释:
Only kswapd can writeback filesystem pages to avoid risk of stack overflow.
But avoid injecting inefficient single-page IO into flusher writeback as
much as possible: only write pages when we've encountered many dirty pages,
and when we've already scanned the rest of the LRU for clean pages and see
the same dirty pages again (PageReclaim).
总结起来就是:
- 只有kswapd可以通过shrink_page_list()将脏页回写,即调用pageout(),直接回收不可以;因为直接回收的栈已经很深了,如果再执行pageout,有可能出现栈溢出;
- 同时,即使是kswapd也尽量避免执行pageout,因为pageout()每次每次只执行一个page的writeback,这与__writeback_single_inode()批量写出连续page(磁盘空间上也大概率是连续的)比起来,效率低也性能也很差;而且,还会向磁盘输出随机小IO。
- kswapd执行pageout()的条件是,参考代码:
if (page_is_file_cache(page) && (!current_is_kswapd() || !PageReclaim(page) || !test_bit(PGDAT_DIRTY, &pgdat->flags))) { inc_node_page_state(page, NR_VMSCAN_IMMEDIATE); SetPageReclaim(page); goto activate_locked; } if (references == PAGEREF_RECLAIM_CLEAN) goto keep_locked; if (!may_enter_fs) goto keep_locked; if (!sc->may_writepage) goto keep_locked;kswapd执行pageout()的条件,总结起来就是:
- PGDAT_DIRTY,该flag的设置条件为对整个node执行shrink_node()之后,统计结果显示:nr_unqueued_dirty == nr_taken,其中nr_taken是isolate_lru_page()的返回值,nr_unqueued_dirty是nr_taken中dirty且!writeback的数量,两者相等即代表,此次shrink_node()遇到都是dirty且还没有writeback的page;
- PageReclaim,inactive_list可认为是一个环,在设置过一次,并在此遇到,就代表已经scan了一圈;
- PAGEREF_RECLAIM_CLEAN,page_check_references()的返回值,代表该page存在Referenced标记;
- may_enter_fs,gfp中包含__GFP_FS标记;
- scan_control.may_writepage,do_try_to_free_pages()在调用shrink_zones的时候如果一次没有获得所需的page,会尝试多次,每次给scan_control.priority减1,当scan_control.priority < 10时,may_writepage会被设置为1;
Writeback,Writeback标记,代表的是这个page已经被回写,但是还没有完成;shrink_page_list()对writeback page的处理有一段长长的注释,但归根结底,shrink_page_list()处理page的首要目的还是回收,既然是被shrink_page_list()scan到,说明这个page已经是冷的;不论是kswapd还是直接回收,都会给page设置Reclaim标记,PageReclaim()标记在end_page_writeback()中被处理,如下
end_page_writeback()
---
if (PageReclaim(page)) {
ClearPageReclaim(page);
rotate_reclaimable_page(page);
}
if (!test_clear_page_writeback(page))
BUG();
---
被标记Reclaim的page会被移动到inactive_list的队尾,在下一次scan时会被回收掉;但是,这种方法是异步的并不能满足即时需求,因为page的writeback还取决于存储设备的处理速度;一旦跟不上前端dirty page的速度,有可能造成dirty page堆积最终OOM;shrink_page_list()的处理方法是:
- 对于kswapd,它并不是一个"利益相关者",所以,在kswapd发现Writeback的page太多时,只是把它们放进active_list,以给后端存储设备更多的时间;
- 而对于直接回收的发起者,同时很可能是page dirtier,它需要被限制,方法有两种:
- 对于来自全局的直接回收,或者cgroup v2的memcg直接回收,因为有dirty limit机制在,所以,此处不需要特殊处理;
- 对于cgroup v1的memcg的回收者,则需要在page上等待writeback完成,借此对page做出限制
Mapped,对于这种类型的page需要借助rmap解除page的mapping,这是个开销相对较大的操作,其通过scan_control.may_unmap控制,不过,除了node_reclaim()中做了开关处理,其他回收操作都没有特殊处理。
注:是否有必要像may_write那样用scan_control.priority控制may_unmap,尤其是,对于可能执行文件或者共享库的page cache的回收,进一步收紧;这有利于降低延时敏感型业务的长尾。
4.4.3 active与inactive list的大小
我们知道active list中的page会降级到inactive list中,但是,这个事情发生在什么时候?参考函数shrink_list(),
shrink_list()
---
if (is_active_lru(lru)) {
if (inactive_list_is_low(lruvec, is_file_lru(lru), sc, true))
shrink_active_list(nr_to_scan, lruvec, sc, lru);
return 0;
}
return shrink_inactive_list(nr_to_scan, lruvec, sc, lru);
---
inactive_list_is_low()负责控制什么时候从active_list向inactive_list输送page;方法是控制inactive list和active list的大小比例,其算法为:
inactive_list_is_low()
---
/*
* When refaults are being observed, it means a new workingset
* is being established. Disable active list protection to get
* rid of the stale workingset quickly.
*/
refaults = lruvec_page_state(lruvec, WORKINGSET_ACTIVATE);
if (file && lruvec->refaults != refaults) {
inactive_ratio = 0;
} else {
gb = (inactive + active) >> (30 - PAGE_SHIFT);
if (gb)
inactive_ratio = int_sqrt(10 * gb);
else
inactive_ratio = 1;
}
return inactive * inactive_ratio < active;
---workingset,直译为工作集;LRU的基本设定是cache的时间局部性,我们可以把workingset理解为,为完成一个任务而具有时间局部性一组page cache,它们在LRU list中很可能是连续的;所以,我们可以把active和inactive list看做是一个个workingset,另外,refaults的部分虽然已经不在LRU list中,但是也应该被考虑在内。
active inactive refaults
| [wset 0] - [wset 1] | -> | [wset 2] [wset 3] | -> | [wset 4] [wset 5] |
\________________________ _______________________/ \_________ _________/
v v
In memory Out of memory如上,wset 0 ~ 5会依次被访问,当wset5被重新访问的时候, inactive_list_is_low()会清空active list以重新装填,此时inactive_ratio为0;
在其他情况下,如果cache size小于1G,则inactive : active = 1,否则,inactive则至少是active的3倍大;不过,这种情况都是在发生kswapd或者direct relcaim发生的时候,如果没有内存压力,并不会维持这种关系。
4.6 vmscan中的几个数量
4.5.1 回收多少?
scan_control.nr_to_reclaim设定的是每次执行回收的目标量,参数几个常见回收函数:
- Direct reclaim,try_to_free_pages(),SWAP_CLUSTER_MAX(32);
- Memcg reclaim,即memcg的limit in bytes无法满足时,回收自己的内存,try_to_free_mem_cgroup_pages(),max(nr_pages,SWAP_CLUSTER_MAX)
- kswapd,因为是后台回收,所以设定的数量较多,参考代码
kswapd_shrink_node() --- sc->nr_to_reclaim = 0; for (z = 0; z <= sc->reclaim_idx; z++) { zone = pgdat->node_zones + z; if (!managed_zone(zone)) continue; sc->nr_to_reclaim += max(high_wmark_pages(zone), SWAP_CLUSTER_MAX); } ---
4.5.2 扫描多少?
有两个问题需要解决,
- 扫描多少个memcg
- 每个memcg扫描多少个page
对于第一个问题,
我们可以参考函数shrink_node(),其中包含一个使用mem_cgroup_iter()的循环,即
shrink_node()
---
memcg = mem_cgroup_iter(root, NULL, &reclaim);
do {
shrink_node_memcg(pgdat, memcg, sc, &lru_pages);
node_lru_pages += lru_pages;
shrink_slab(sc->gfp_mask, pgdat->node_id,
memcg, sc->priority);
if (!global_reclaim(sc) &&
sc->nr_reclaimed >= sc->nr_to_reclaim) {
mem_cgroup_iter_break(root, memcg);
break;
}
} while ((memcg = mem_cgroup_iter(root, memcg, &reclaim)));
---
其中mem_cgroup_iter(),会遍历memcg的层级结构,其使用了css_next_descendant_pre(),遍历路径如下:

css_next_descendant_pre()的基本原则是,先沿着树枝的左边,达到叶子节点,然后,遍历同级。
不过,在遍历memcg的时候,因为可能同时存在多个reclaimer,为了保证各个memcg的公平性,避免一个memcg被重复回收,mem_cgroup_iter()维护了per-root & per-priority的iterator,然后通过cmpxchg()使多个reclaimer可以共享一个iterator。
综上,在全局的范围内,多个reclaimer会遍历所有的memcg一遍。
对于第二问题,
执行回收时,我们需要从inactive list的默认降级一些page,当inactive list的数量不足时,我们也需要从active list降级,那么这个数量由scan_contro.nr_to_scan决定,参考函数get_scan_count(),在不考虑swap的情况下,
get_scan_count()
---
for_each_evictable_lru(lru) {
int file = is_file_lru(lru);
size = lruvec_lru_size(lruvec, lru, sc->reclaim_idx);
scan = size >> sc->priority;
...
}
---
scan_control.priority的处理比较简单,参考代码:
do_try_to_free_pages()
---
do {
sc->nr_scanned = 0;
shrink_zones(zonelist, sc);
if (sc->nr_reclaimed >= sc->nr_to_reclaim)
break;
if (sc->priority < DEF_PRIORITY - 2)
sc->may_writepage = 1;
} while (--sc->priority >= 0);
---
当scan_control.priority的值为0时,vmscan会遍历Memcg LRU上所有的page。
4.6 OOM
OOM用来回收用户态进程的堆栈内存;OOM分为全局OOM和Memory cgroup OOM,本小节,我们主要关注全局OOM。
4.6.1 何时OOM
关于OOM的条件,我们可以关注should_reclaim_retry(),该函数主要用于决定,是否放弃回收,即:
- 执行了MAX_RECLAIM_RETRIES(16)没有任何进展的回收;每个memcg在一轮中,只会被scan一次,如果算上优先级scan_control.priority的话,在一次do_try_to_free_pages()中,memcg中的page是有可能被scan两次的,如果在加上这16次retry的话,对于order=0的page来说,大部分的page都有可能被回收掉;当然,也不排除有个别访问频繁非常高的page;对于有Dirty page并且没有__GFP_FS的reclaimer,同样也很有可能遭遇这种情况。
- 即使回收掉LRU上所有的page,也不足以满足min water mark;这种情况就是大部分page都被申请为匿名页,也没有swap分区;
那么,大块内存的申请会导致OOM吗?参考__alloc_page_may_oom()
_alloc_pages_may_oom()
---
/* The OOM killer will not help higher order allocs */
if (order > PAGE_ALLOC_COSTLY_ORDER) // 3
goto out;
---
也就是说,32K以上的page不会触发OOM。
4.6.2 任务选择
OOM score的计算在函数oom_badness(),
oom_badness()
---
adj = (long)p->signal->oom_score_adj;
points = get_mm_rss(p->mm) + get_mm_counter(p->mm, MM_SWAPENTS) +
mm_pgtables_bytes(p->mm) / PAGE_SIZE;
/* Normalize to oom_score_adj units */
adj *= totalpages / 1000;
points += adj;
return points > 0 ? points : 1;
---
其中oom_score_adj的范围是(-1000, 1000) ;可以通过/proc/<pid>/oom_score_adj调整。当一个进程的oom_score_adj是999的时候,它的points将接近totalpages,此时,无论其他任务占用多少内存,都不会被选择。例如:

例如,上图中的stress占内存非常高,但是最终OOM选择了dfget,因为它的oom_score_adj是999。
注:oom dump打印的是oom_score_adj而不是计算出的结果。参考函数dump_tasks()
另外,从oom_badness()我们也可以看到,其统计内存所占内存的时候,主要考虑了rss、swap和pagetable,这些也是杀掉任务所能获得的内存数量。
注:任务的代码段等都属于page cache
4.7 Shrinker
系统中,除了page cache和用户态的堆栈,还有一些内核态的可回收的内存对象,比如inode cache和dentry cache;模块可以通过注册shrinker的方式,将自己占用的可回收的内存,在系统需要的时候,归还给系统。
4.7.1 工作方式
shrinker在注册时,需要提供两个回调函数,即:
- count_objects,返回该shrinker中可以被释放的对象数量;
- scan_objects,执行回收操作,类似shrinker_page_list
count_objects在返回freeable之后,do_shrink_slab()会根据当前的内存紧张程度决定回收多少,即priority:
do_shrink_slab()
---
if (shrinker->seeks) {
delta = freeable >> priority;
delta *= 4;
do_div(delta, shrinker->seeks);
} else {
/*
* These objects don't require any IO to create. Trim
* them aggressively under memory pressure to keep
* them from causing refetches in the IO caches.
*/
delta = freeable / 2;
}
---其中,shrinker->seeks是shrinker的注册方提供的,表示的是,其中被回收对象对IO的依赖程度;值越大,标识对象被回收之后需要的IO越多;比如:raid5 stripe cache的seeks为DEFAULT_SEEKS * conf->raid_disks * 4。
shrinker中最著名的是文件系统的inode cache和dentry cache;具体参考代码alloc_super()
s->s_shrink.seeks = DEFAULT_SEEKS;
s->s_shrink.scan_objects = super_cache_scan;
s->s_shrink.count_objects = super_cache_count;
s->s_shrink.batch = 1024;
s->s_shrink.flags = SHRINKER_NUMA_AWARE | SHRINKER_MEMCG_AWARE;
super_cache_count()
---
if (sb->s_op && sb->s_op->nr_cached_objects)
total_objects = sb->s_op->nr_cached_objects(sb, sc);
total_objects += list_lru_shrink_count(&sb->s_dentry_lru, sc);
total_objects += list_lru_shrink_count(&sb->s_inode_lru, sc);
---
super_cache_scan()
---
if (sb->s_op->nr_cached_objects)
fs_objects = sb->s_op->nr_cached_objects(sb, sc);
inodes = list_lru_shrink_count(&sb->s_inode_lru, sc);
dentries = list_lru_shrink_count(&sb->s_dentry_lru, sc);
total_objects = dentries + inodes + fs_objects + 1;
if (!total_objects)
total_objects = 1;
/* proportion the scan between the caches */
dentries = mult_frac(sc->nr_to_scan, dentries, total_objects);
inodes = mult_frac(sc->nr_to_scan, inodes, total_objects);
fs_objects = mult_frac(sc->nr_to_scan, fs_objects, total_objects);
/*
* prune the dcache first as the icache is pinned by it, then
* prune the icache, followed by the filesystem specific caches
*
* Ensure that we always scan at least one object - memcg kmem
* accounting uses this to fully empty the caches.
*/
sc->nr_to_scan = dentries + 1;
freed = prune_dcache_sb(sb, sc);
sc->nr_to_scan = inodes + 1;
freed += prune_icache_sb(sb, sc);
if (fs_objects) {
sc->nr_to_scan = fs_objects + 1;
freed += sb->s_op->free_cached_objects(sb, sc);
}
---
4.7.2 Per-Cgroup
shrinker如何实现per-cgroup呢?有两个基础组件:
- shrinker bitmap,memcg中有一个bitmap,用于标记存在freeable内存的shrinker,
shrink_slab_memcg() --- for_each_set_bit(i, info->map, shrinker_nr_max) { struct shrink_control sc = { .gfp_mask = gfp_mask, .nid = nid, .memcg = memcg, }; shrinker = idr_find(&shrinker_idr, i); ... ret = do_shrink_slab(&sc, shrinker, priority); --- - per-cgroup lru list,inode cache和dentry cache都是基于lib/list_lru.c实现的,参考如下代码
static inline struct list_lru_one * list_lru_from_memcg_idx(struct list_lru *lru, int nid, int idx) { if (list_lru_memcg_aware(lru) && idx >= 0) { struct list_lru_memcg *mlru = xa_load(&lru->xa, idx); return mlru ? &mlru->node[nid] : NULL; } return &lru->node[nid].lru; }
5 Writeback
5.1 writeback Basis
5.1.1 Dirty
如果APP向一个page中写入数据,这个page之后会发生什么?我们可以参考代码
iomap_set_page_dirty()
---
lock_page_memcg(page);
newly_dirty = !TestSetPageDirty(page);
if (newly_dirty)
__set_page_dirty(page, mapping, 0);
unlock_page_memcg(page);
if (newly_dirty)
__mark_inode_dirty(mapping->host, I_DIRTY_PAGES);
---
其中有两个核心函数:
- __set_page_dirty(),其主要做两件事,第一,更新address_space.i_pages中该page的tag为PAGECACHE_TAG_DIRTY,这个flag之后将用来识别需要writeout的page;第二,调用account_page_dirtied()更新统计数据,另外,还会inode_attach_wb();PAGECACHE_TAG_DIRTY会在clear_page_dirty_for_io()和set_page_writebac()之后被清除。
- __mark_inode_dirty(),将这个inode交给writeback子系统; 需要特别说明的是,writeback的单位并不是page,而是inode;参考__writeback_single_inode();__mark_inode_dirty()会给inode->i_state设置I_DIRTY_INODE、I_DIRTY_PAGES和I_DIRTY_TIME等flag;
注:
- __mark_inode_dirty()还会调用文件系统dirty_inode方法,ext4的dirty_inode会给inode的修改记日志;
- 对于mmap的page的写,需要触发page fault来感知其dirty状态,具体的操作,可以参考clear_page_dirty_for_io()中的page_mkclean()
inode的writeback由__writeback_single_inode()完成,其依次做三件事:
- do_writepages(),调用writepages方法将所有的脏页提交到块设备;
- Clear I_DIRTY_INODE和I_DIRTY_PAGES,
__writeback_single_inode() --- /* * Some filesystems may redirty the inode during the writeback * due to delalloc, clear dirty metadata flags right before * write_inode() */ spin_lock(&inode->i_lock); dirty = inode->i_state & I_DIRTY; //I_DIRTY_INODE | I_DIRTY_PAGES inode->i_state &= ~dirty; if (mapping_tagged(mapping, PAGECACHE_TAG_DIRTY)) inode->i_state |= I_DIRTY_PAGES; spin_unlock(&inode->i_lock); --- - write_inode(),对于ext4这种日志FS,因为在dirty_inode方法中已经给inode记录了日志,write_inode方法只需要保证日志commit即可保证inode修改落盘;对于WB_SYNC_NONE,甚至不需要commit日志;对于ext2,其只有write_inode方法,其直接将inode结构落盘;
在__writeback_single_inode()执行完之后,inode依然有可能处于dirty状态,参考requeue_inode(),除了有新的操作导致inode处于dirty状态之外,还有一种可能是
Filesystems can dirty the inode during writeback operations, such as delayed allocation during submission or metadata updates after data IO completion.
wbc->nr_to_write耗尽;nr_to_write来自writeback_chunk_size(),
writeback_chunk_size()
---
if (work->sync_mode == WB_SYNC_ALL || work->tagged_writepages)
pages = LONG_MAX;
else {
pages = min(wb->avg_write_bandwidth / 2,
global_wb_domain.dirty_limit / DIRTY_SCOPE);
pages = min(pages, work->nr_pages);
pages = round_down(pages + MIN_WRITEBACK_PAGES,
MIN_WRITEBACK_PAGES);
}
---
5.1.2 bdi_writeback
bdi_writeback是writeback的总控结构;
抛开cgroup writeback,bdi_writeback是per request queue的,而非per filesystem;这是因为通过分区,同一个块设备上可以同时有多个文件系统;一个bdi_writeback可以避免多个文件系统刷脏页时的HDD seek。
bdi_writeback中用来保存inode的list,有b_dirty、b_io、b_more_io和b_dirty_time四个,为什么需要这么多?
b_dirty、b_io和b_more_io中b_more_io的起源有明确的commit,参考
commit 0e0f4fc22ece8e593167eccbb1a4154565c11faa
Author: Ken Chen <kenchen@google.com>
Date: Tue Oct 16 23:30:38 2007 -0700writeback: fix periodic superblock dirty inode flushing
Current -mm tree has bucketful of bug fixes in periodic writeback path.
However, we still hit a glitch where dirty pages on a given inode aren't
completely flushed to the disk, and system will accumulate large amount of
dirty pages beyond what dirty_expire_interval is designed for.
The problem is __sync_single_inode() will move an inode to sb->s_dirty list
even when there are more pending dirty pages on that inode. If there is
another inode with a small number of dirty pages, we hit a case where the loop
iteration in wb_kupdate() terminates prematurely because wbc.nr_to_write > 0.
Thus leaving the inode that has large amount of dirty pages behind and it has
to wait for another dirty_writeback_interval before we flush it again. We
effectively only write out MAX_WRITEBACK_PAGES every dirty_writeback_interval.
If the rate of dirtying is sufficiently high, the system will start
accumulate a large number of dirty pages.
So fix it by having another sb->s_more_io list on which to park the inode
while we iterate through sb->s_io and to allow each dirty inode which resides
on that sb to have an equal chance of flushing some amount of dirty pages.
在2007年,b_dirty和b_io还在superblock里,名为s_dirty和s_io;
Before
newly dirtied s_dirty s_io
=============> gf edcBA
After
newly dirtied s_dirty s_io
=============> BAg fedc
|
+--> dequeue for IO
引入s_more_io之前,BA会被redirty,因为时间戳被更新,BA可能需要等到下一个kupdate周期;引入s_more_io的目的是为了避免BA从头排队;结合当前的代码(LTS v4.19.154),三个list的如下
Before
newly dirtied b_dirty b_io b_more_io
=============> gf edc BA
After
newly dirtied b_dirty b_io b_more_io
=============> g fBAedc
|
+--> dequeue for IO
将inode加入b_more_io的一个主要条件是wbc->nr_to_write <= 0,即分配的slice(参考writeback_chunk_size() slice ~= avg_write_bandwidth/2)耗尽;slice机制是处于公平性的考虑,让所有的dirty inode都有机会写出一定的脏数据。但是,从上面的结果看,其事实上主要保证了处于b_io上的inode的公平性。
那么为什么不直接将slice用完的inode放到b_io的队尾?还是处于公平性的考虑;
A b_io refill will setup a _fixed_ work set with all currently eligible
inodes and start a new round of walk through b_io. The "fixed" work set
means no new inodes will be added to the work set during the walk.
Only when a complete walk over b_io is done, new inodes that are
eligible at the time will be enqueued and the walk be started over.
This procedure provides fairness among the inodes because it guarantees
each inode to be synced once and only once at each round. So all inodes
will be free from starvations.
from commit 424b351fe1901fc909fd0ca4f21dab58f24c1aac当b_io中的inode被sync一遍之后,就会退出,然后查看是否有已经符合标准的新的inode,即新的一轮的b_io是 fBAedc,这里引入了f,而不是来回处理edcBA;b_io这个独立的list的意义也应该就是为此。
5.1.3 writeback inode
此处的inode是指文件系统的inode元数据本身;在__mark_inode_dirty()中我们可以看到调用dirty_inode,在__writeback_single_inode()中有write_inode,他们分别是做什么的呢?
只有__mark_inode_dirty()带有I_DIRTY_INODE flag时,才会调用dirty_inode方法;这个场景调用很少,典型的例如:generic_file_direct_write()和__generic_write_end(),当文件size变化后,会调用mark_inode_dirty(I_DIRTY);
我们分别取ext2、ext4和xfs举例分析;
注:WB_SYNC_ALL的的注释为Wait on every mapping,在代码中也主要用于标识需要等待write IO完成
- ext2,非日志文件系统;无dirty_inode方法,有write_inode方法,ext2_write_inode(),其中将in-core inode中的数据同步到了on-disk inode的buffer中,并调用mark_buffer_dirty()将on-disk inode的bh重新转交给了writeback子系统,在WB_SYNC_ALL的情况下,会等待bh writeback完成;可以参考ext2的fsync方法。
- ext4,日志文件系统,有dirty_inode方法,其创建一个新的jbd2 handle,从in-core inode更新过on-disk inode的buffer之后,将其转交给jbd2子系统;但是,有write_inode方法,在WB_SYNC_ALL且非for_sync的情况下,会等待日志提交;
- xfs,日志文件系统,非linux原生,自己维护元数据buffer,有dirty_inode方法,但是只关注time相关操作,只是转交给了自己的日志系统;无dirty_inode方法。
ext2与ext4&xfs的关键差别是,ext4和xfs是日志文件系统,它们有元数据更新事务性的保证;每一笔元数据更新,都及时送入了日志系统,日志commit之后,自动更新到相关on-disk inode;
注:我们之所以说"送入",是因为无论是jbd2还是xfslog,都是delayed log,日志会在系统中短暂停留,然后延时落盘;当然,元数据更新的事务性在这个过程中是得到保证的。之后,日志系统在log commit之后,会将元数据的更新落盘。
所以,在ext2_write_inode()需要自己调用mark_bh_dirty()将元数据交给writeback子系统,而ext4_write_inode()中,只是需要等待日志commit即可。
ext4的dirty_inode中,只将inode本身更新送入jbd2,主要目的是,方便其他位置,如sync、fsync、iput_final->write_inode_now()->write_inode等位置通过jbd2,确认inode更新落盘;xfs的dirty_inode方法作用也类似,主要是将inode放入日志系统
但是xfs为什么没有write_inode方法呢?
参考ext4_write_inode,其只有在WB_SYNC_ALL & !for_sync的时候才会发挥作用,主要调用方是iput_final()->write_inode_now();但是xfs并并不会在iput_final()中调用write_inode_now(),因为xfs自己维护了inode cache,参考xfs_iget(),generic_drop_inode()中的inode_unhashed()返回true,
综上,在writeback过程中,确实会写inode元数据,即
- ext2,通过调用ext2_write_inode方法,将in-core inode写入on-disk inode buffer,并将对应bh转交给writeback子系统;
- ext4 的on-disk元数据,由在日志commit之后,会被转交给writeback子系统;
- xfs的元数据由自己维护,而不是同时系统的writeback
ext2和ext4的元数据的脏页,最终都又还给了writeback子系统,不过对应的inode变成了block device的。
5.1.4 bdev inode
上一小节提到,对于ext2和ext4,元数据的writeback最终落到了block device的inode身上,那么block device的inode的writeback是怎么进行的呢?
首先,我们需要关注一个函数,
inode_to_bdi()
---
sb = inode->i_sb;
#ifdef CONFIG_BLOCK
if (sb_is_blkdev_sb(sb))
return I_BDEV(inode)->bd_bdi;
#endif
return sb->s_bdi;
---
block_device的bd_bdi来自
__blkdev_get()
---
if (!bdev->bd_openers) {
...
if (bdev->bd_bdi == &noop_backing_dev_info)
bdev->bd_bdi = bdi_get(disk->queue->backing_dev_info);
...
}
---
也就说,block device inode也使用其request_queue的bdi,这是合理的,一个块设备上的所有的脏数据都应该由一个wb writeback。
5.1.5 dirty time
在writeback中,数据、inode本身和time做了单独处理,其中time的特殊处理源自文件系统的lazytime选项,其目的是减少在访问文件过程中造成的IO开销,参考commit comment:
commit 0ae45f63d4ef8d8eeec49c7d8b44a1775fff13e8
Author: Theodore Ts'o <tytso@mit.edu>
Date: Mon Feb 2 00:37:00 2015 -0500
vfs: add support for a lazytime mount option
Add a new mount option which enables a new "lazytime" mode. This mode
causes atime, mtime, and ctime updates to only be made to the
in-memory version of the inode. The on-disk times will only get
updated when (a) if the inode needs to be updated for some non-time
related change, (b) if userspace calls fsync(), syncfs() or sync(), or
(c) just before an undeleted inode is evicted from memory.
This is OK according to POSIX because there are no guarantees after a
crash unless userspace explicitly requests via a fsync(2) call.
For workloads which feature a large number of random write to a
preallocated file, the lazytime mount option significantly reduces
writes to the inode table. The repeated 4k writes to a single block
will result in undesirable stress on flash devices and SMR disk
drives. Even on conventional HDD's, the repeated writes to the inode
table block will trigger Adjacent Track Interference (ATI) remediation
latencies, which very negatively impact long tail latencies --- which
is a very big deal for web serving tiers (for example).
Google-Bug-Id: 18297052
Signed-off-by: Theodore Ts'o <tytso@mit.edu>
Signed-off-by: Al Viro <viro@zeniv.linux.org.uk>
generic_update_time()中,如果文件系统没有设置SB_LAZYTIME,就会给__mark_inode_dirty()传入I_DIRTY_SYNC | I_DIRTY_TIME,如果设置了,则只传入I_DIRTY_TIME;之后,__mark_inode_dirty()会调用dirty_inode,xfs_fs_dirty_inode()和ext4_drity_inode()中, 会检查如果只设置了I_DIRTY_TIME,则只直接退出,不做任何处理。
在in-core inode中被修改的time,通过以下函数调用mark_inode_dirty_sync(),update到on-disk inode中,
- __writeback_single_inode()
- iput()
- vfs_fsync_range()
mark_inode_dirty_sync()在调用dirty_inode时,带着I_DIRTY_SYNC。
注:lazytime只是延迟更新,且atime、mtime和ctime都涉及到;noatime是直接放弃更新atime,
mount option: noatime -> MNT_NOATIME
touch_atime()
---
if (!atime_needs_update(path, inode))
return;
...
update_time(inode, &now, S_ATIME);
...
---
5.2 发起Writeback
当前内核中(基于v4.19.154),主要有以下几种writeback,参考enum wb_reason;
- WB_REASON_BACKGROUND,
- WB_REASON_VMSCAN,
- WB_REASON_SYNC,
- WB_REASON_PERIODIC,
- WB_REASON_LAPTOP_TIMER,
- WB_REASON_FREE_MORE_MEM,
- WB_REASON_FS_FREE_SPACE,
- WB_REASON_FORKER_THREAD,
本小节我们主要看它们分别何时发起,何时结束。
5.2.1 Background
wb_check_background_flush()是wb_do_writeback()的常备项,只要writeback kworker运行,发生background writeback的必要条件是
wb_over_bg_thresh()
---
if (gdtc->dirty > gdtc->bg_thresh)
return true;
if (wb_stat(wb, WB_RECLAIMABLE) >
wb_calc_thresh(gdtc->wb, gdtc->bg_thresh))
return true;
---
除了全局的dirty > bg_thresh条件外,还有wb级别thresh的判定;其中WB_RECLAIMABLE统计数据的来源来自:
account_page_dirtied()
---
inc_wb_stat(wb, WB_RECLAIMABLE);
---
clear_page_dirty_for_io()
---
if (TestClearPageDirty(page)) {
dec_lruvec_page_state(page, NR_FILE_DIRTY);
dec_wb_stat(wb, WB_RECLAIMABLE);
ret = 1;
}
---__wb_calc_thresh()会依据wb的writeback完成的数量占全局的比例,比例划分出其应该占得的全局background thresh的量。
wb_over_bg_thresh()不仅控制这background writeback的开始,还会控制其结束,如下:
wb_writeback()
---
/*
* For background writeout, stop when we are below the
* background dirty threshold
*/
if (work->for_background && !wb_over_bg_thresh(wb))
break;
---
5.2.2 Periodic
和Background类似,Periodic也是wb_writeback()的常备项,参考函数wb_check_old_data_flush(),之前称为kupdate writeback,与其有关的两个变量为:
- dirty_writeback_interval,kupdate writeback执行的间隔,默认为50s,对应/proc/sys/vm/dirty_writeback_centisecs;
- dirty_exprire_interval,inode的超时时间,默认30s,对应/proc/sys/vm/dirty_expire_centisecs;
Periodic或者说Kupdate writeback的触发有两个时机:
- __mark_inode_dirty(),只有dirty inode,就需要一个periodic writeback,保证在对应段时间之后让inode落盘;
- wb_workfn(),结束时,如果依然有dirty inode,需要调度一个priodic writeback
5.2.3 Sync
在POSIX的官方说明文档中,对sync的描述是这样的,
https://pubs.opengroup.org/onlinepubs/009695299/functions/sync.html
The sync() function shall cause all information in memory that updates file systems to be scheduled for writing out to all file systems.
The writing, although scheduled, is not necessarily complete upon return from sync().
其中并没有规定,写操作必须完成。
但是,fsync的规定比较严格,
https://pubs.opengroup.org/onlinepubs/009695299/functions/fsync.html
The fsync() function shall request that all data for the open file descriptor named by fildes is to be transferred to the storage device associated with the file described by fildes. The nature of the transfer is implementation-defined. The fsync() function shall not return until the system has completed that action or until an error is detected.
我们先看下fsync的实现:
vfs_fsync_range()
---
if (!datasync && (inode->i_state & I_DIRTY_TIME))
mark_inode_dirty_sync(inode);
return file->f_op->fsync(file, start, end, datasync);
---
不同的文件系统,fsync实现有差别:
- ext2,参考generic_file_sync(),里面总共分四步:
- file_write_and_wait_range(),其中调用do_writepages()刷出脏页,然后调用__filemap_fdatawait_range(),等待所有writeback的page完成;
- sync_mapping_buffers(),issue and wait所有的文件系统所在的块设备上的dirty bh落盘;
- sync_inode_metadata(),它会调用write_single_inode() with nr_to_write = 0,最终只会将inode 写出,并等待完成;
- blkdev_issue_flush();
- ext4,参考ext4_sync_file(),里面总共两步:
- file_write_and_wait_range(),同上;
- jbd2_complet_transaction(),等日志提交;日志提交之后,虽然元数据在日志里, 但是已经保证落盘,且掉电不丢失;需要特别说明的是,sync日志使用的trans id是保存在ext4_inode_info的i_datasync_id或者i_sync_id;
syncfs并不是POSIX标准的接口,在linux中,其语义与fsync类似,不过,它针对的是整个文件系统;在sync_filesystem()中,它调用了两次__sync_filesystem(),第一次wait = 0,第二次wait = 1,之所以分两次,是处于性能上的考虑,第一次__sync_filesystem()可以保证尽量多的将IO发出,进而提高并发量;sync_filesystem()有以下一个点要关注:
- 刷数据的时候,为了避免Livelock,wb_writeback()会在开始时,取一个时间戳,以此为时间界限,识别需要writeback的inode;
- __sync_filesystem()也会调用文件系统的sync_fs接口,对于ext4来说,它会获取一个最近的trans id,然后等待这个transaction commit;
- __sync_filesystem()还会调用__sync_blockdev();对于ext4来说,__sync_blockdev()是没有必要的,因为日志提交就代表元数据落盘;但是对于ext2来说, __sync_blockdev()就是必不可少了了;
注:__writeback_single_inode()会调用ext2_write_inode(),__sync_filesystem()再被第二次调用时,会使用sync_inodes_sb(),其中for_sync = 1、sync_mode = WB_SYNC_ALL;ext2_write_inode()此时会等待bh的写完成,是不是应该再识别下for_sync ?即当这两个条件同时满足时,不必等待,等__sync_filesystem()调用__sync_blockdev()一次完成。
5.3 Dirty Throttle
Dirty Throttle的目的是限制系统中脏页的数量到一定的比例,即/proc/sys/vm/dirty_ratio,参考下图

Dirty throttle通过让APP dirty page的速度(上图中红线)与flusher的速度(上图中蓝线)一致,使系统的dirty page总量(上图中黑线)不在上升;
限制APP dirty page的速度的方法是,让其睡眠一定的时间,睡眠时间的计算方法为:
page_dirtied
pause = ---------------------------------
pos_ratio * balanced_ratelimit下面,我们分别介绍此公式的基础数据的来源和计算方法。
5.3.1 dirty thresh
全局的dirty thresh的计算公式为:
avail = free + active_file + inactive_file
dirty = NR_FILE_DIRTY + NR_FILE_WRITEBACK + NR_UNSTABLE_FILE
dirty_thresh = avail * dirty_ratio另外,还有bdi级别的dirty_thresh,其值会根据该wb的writeback完成的数据量,比例划分全局dirty thresh,参考函数__wb_calc_thresh(),数据来源参考
__wb_writeout_inc()
---
inc_wb_stat(wb, WB_WRITTEN);
wb_domain_writeout_inc(&global_wb_domain, &wb->completions,
wb->bdi->max_prop_frac);
---
除了带有BDI_CAP_STRICTLIMIT(目前只有fuse),wb_thresh并不会用在freerun的判断中。
5.3.2 pos_ratio
pos_ratio使我们在计算APP pause time的时候可以引入额外的策略;目前其包括两个方面:
- Global control line,adapts to dirtyable memory size;其计算公式为:
freerun = (limit + background) / 2 setpoint = (limit + freerun) / 2 setpoint - dirty 3 pos_ratio := 1.0 + (----------------) limit - setpoint假设limit = 200、background = 100,pos_ratio跟随dirty在freerun = 150到limit = 200变化的曲线如下;从中我们看到,其倾向于将系统的dirty page的数量控制在setpoint = 175附近。

- Bdi control line,adapts to write bandwidth,其控制公式产生的图如下左,公式会确定两个点:(1)点,f(bdi_setpoint) = 1,(2)点,f(bdi_setpoint + 8 * write_bw) = 0;


上图左显示,当达到相同的dirty page X时,write_bw越大,则pos_ratio越大,也就是说pause time会越小;公式倾向于让write_bw小的wb睡眠的时间更长。
pos_ratio的计算在wb_pos_ratio()函数。
注:bdi control line还有一个pos_ratio最低1/4的限制,上图中没有体现出来
5.3.3 writeback bw
这个wb在过去这段时间内的writeback的真实带宽;
注:之所以是wb级别,是因为每个cgroup都有一个wb,如果cgorup writeback开启,每个cgroup的写速度不同;
其依赖统计数据WB_WRITTEN,来自
end_page_writeback()
-> test_clear_page_writeback()
---
ret = TestClearPageWriteback(page);
if (ret) {
if (bdi_cap_account_writeback(bdi)) {
struct bdi_writeback *wb = inode_to_wb(inode);
__wb_writeout_inc(wb);
-> inc_wb_stat(wb, WB_WRITTEN);
}
}
---
计算公式为:
period = roundup_pow_of_two(3 * HZ);
bw = (written - wb->written_stamp) * HZ / elapsed
bw * elapsed + write_bandwidth * (period - elapsed)
write_bandwidth = ---------------------------------------------------
period
其中,elapsed的计算依赖wb->bw_time_stamp,__wb_update_bandwidth()每200ms调用一次。
5.3.3 dirty rate
dirty rate是一个wb在过去这段时间里写脏页的速度,其统计依赖上面的wb->bw_time_stamp以及统计数据WB_DIRTIED,参考代码:
account_page_dirtied()
---
if (mapping_cap_account_dirty(mapping)) {
struct bdi_writeback *wb;
inode_attach_wb(inode, page);
wb = inode_to_wb(inode);
__inc_lruvec_page_state(page, NR_FILE_DIRTY);
inc_wb_stat(wb, WB_DIRTIED);
current->nr_dirtied++;
}
---
dirty rate的计算公式为:
dirty_rate = (dirtied - wb->dirtied_stamp) * HZ / elapsed;
注:current->nr_dirtied累积了过于一段时间内当前进程写脏页的数量,进而避免每次都调用balance_dirty_pages()
5.3.3 dirty ratelimit
那么dirty ratelimit是如何计算出的呢?
首先,我们需要明确一个问题,write_bw是否会受到APP的影响?
答案是否定的,在正常的balance_dirty_pages()过程中,脏页都是由background writeback写出,这个过程会持续到wb_over_bg_thresh()返回false,即全局和wb级别的dirty < bg_thresh,而dirty rate受到限制需要在dirty > freerun ((thresh + bg_thresh ) / 2)点之后,这就避免了两者在bg_thresh附近拉锯;所以,如果APP持续输出脏页,wb_writeback()会全力写出到设备。
另外,writeback会控制每个inode writeback的chunk size,避免dirty跌出(freerun, limit)的范围,参考commit
commit 1a12d8bd7b2998be01ee55edb64e7473728abb9c
Author: Wu Fengguang <fengguang.wu@intel.com>
Date: Sun Aug 29 13:28:09 2010 -0600
writeback: scale IO chunk size up to half device bandwidth
....
XFS is observed to do IO completions in a batch, and the batch size is
equal to the write chunk size. To avoid dirty pages to suddenly drop
out of balance_dirty_pages()'s dirty control scope and create large
fluctuations, the chunk size is also limited to half the control scope.
The balance_dirty_pages() control scrope is
[(background_thresh + dirty_thresh) / 2, dirty_thresh]
which is by default [15%, 20%] of global dirty pages, whose range size
is dirty_thresh / DIRTY_FULL_SCOPE.
The adpative write chunk size will be rounded to the nearest 4MB
boundary.
rate_T : 上个周期的dirty_ratelimit
rate_T+1 : 依据rate_T重新计算的新的dirty_ratelimit
依据实际的设备的writeback bandwidth和APP的dirty page的数量的比值,来对rate_T做处理
rate_T+1 = rate_T * (write_bw / dirty_rate)
这个公式有什么问题呢?
已知,
dirty_rate = rate_T * pos_ratio * N
于是得到,
rate_T+1 = write_bw / (pos_ratio * N)
那么,这个计算周期的dirty rate就是
dirty_rate = N * pos_ratio * rate_T+1
= write_bw
pos_ratio的调节功能完全丧失了 !
于是计算公式修正为:
rate_T+1 = rate_T * (write_bw / dirty_rate) * pos_ratiodirty ratelimit的计算由函数wb_update_dirty_ratelimit()完成,其计算频率为BANDWIDTH_INTERVAL = max(HZ/5, 1),即200ms。
5.3.4 balance_dirty_pages
6 Mem Cgroup
6.1 Mem Page Counter
page_counter结构及一些列接口,用来维护一个mem_cgroup的内存使用;同时page_counter本身还维护了mem_cgroup的层级关系。Max即mem_cgroup的memory.limit_in_bytes,Usage即memory.usage_in_bytes,下面,我们看他们两个是如何工作的;
- Usage Charge,参考函数page_counter_try_charge(),它会逐级向上遍历,依次增加usage并比较usage和max,如果usage > max,就失败,就cancel之前的charge,并返回失败的mem_cgroup,调用者可能会对其进行内存回收。然后重新调用page_counter_try_charge();从usage的charge方式来看,我们可以有两个直观的结论:
- child cgroup的内存会被charge到父cgroup
- 每次usage charge需要满足上层所有父cgroup的max设置
- Max Resize,参考函数mem_cgroup_resize_max(),其调用page_counter_set_max()会检查usage和当前新的max的大小,如果usage > new_max,则失败返回EBUSY,mem_cgroup_resize_max()会调用try_to_free_mem_cgroup()回收相关cgroup的内存;从中,我们有两条结论:
- max是可以变小的,当然,如果内存无法回收,则resize max的过程会失败
- 设置max时,并不会检查层级限制
这里比较特别的是max的resize时,并不会检查层级的max,也就是父mem_cgroup的max可以小于子mem_cgroup的max;但是,这并不会影响什么,因为usage charge的会检查父mem_cgroup的max和usage。
6.2 Page and Mem Cgroup
每个page结构体都携带其所在mem_cgroup的指针和一个引用计数。
- 引用计数get,参考函数try_charge()中调用css_get_many()的位置;
- 引用计数put,参考函数uncharge_batch()中的css_put_many();
- page->mem_cgroup设置,参考commit_charge()和uncharge_page()
当相关cgroup下线之后,其相关的memcg依然可能存在于内核中,直到所有的page都被释放
7 专题
7.1 内存和Numa
7.1.1 硬件相关
Non-Uniform Memory Access (NUMA) Performance is a MESI SituationUpdating to a new version of the Linux kernel is not too difficult, but it can have surprising performance impacts. This story is one of those times.![]() https://qumulo.com/blog/non-uniform-memory-access-numa/这篇文档中介绍了一个有关Numa造成性能瓶颈的案例和原理解释,我们引用其中的图,
https://qumulo.com/blog/non-uniform-memory-access-numa/这篇文档中介绍了一个有关Numa造成性能瓶颈的案例和原理解释,我们引用其中的图,
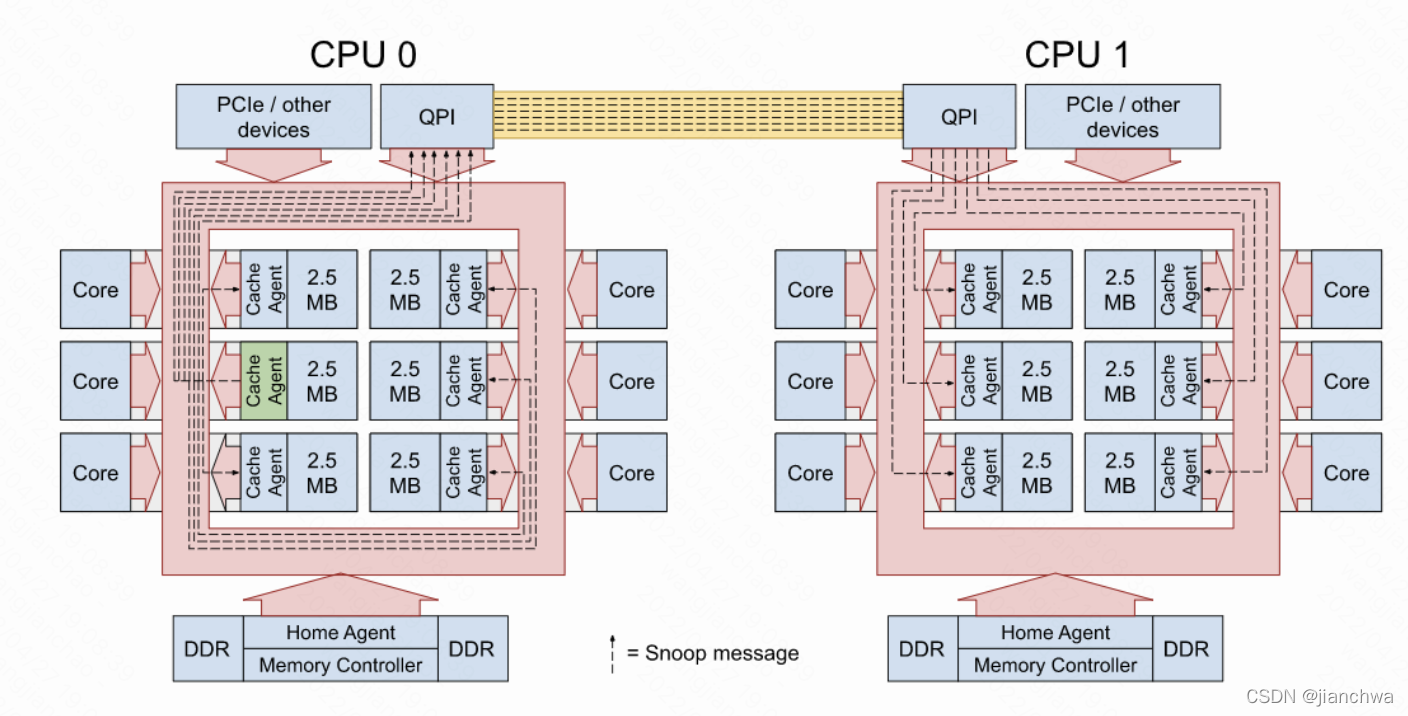
跨numa访问的性能瓶颈包括:
- 跨socket的总线带宽瓶颈,也就是上图中的QPI;
- 跨numa的cache一致性协议;
上面的文章中提到,home snoop协议对比early snoop,
- 更小的带宽开销,所以可以留出更多的带宽给读写操作;
- 更多step,所以单笔延迟可能更高;

Home Agent下,通过记录额外信息,可以避免广播,但是依然需要通信;所以,避免跨numa访问才是最优解。那么内核是怎么处理这些问题的呢?
7.1.2 申请内存
我们会在哪个numa node上申请内存呢?
- 可以通过内存申请的接口参数指定numa node,比如,可以根据设备所在的numa node;
- 如果没有指定,则根据该任务运行的cpu所在的numa node,接口为numa_node_id()
- cgroup cpuset机制可以指定node节点,当指定的node节点没有内存时,
GFP_USER allocations are marked with the __GFP_HARDWALL bit, and do not allow allocations outside the current tasks cpuset unless the task has been OOM killed. GFP_KERNEL allocations are not so marked, so can escape to the nearest enclosing hardwalled ancestor cpuset.
cpuset的限制在所有手段是失效时,会被解除,参考函数__alloc_pages_cpuset_fallback();
- 如果是为写操作申请page cache, get_page_from_freelist()会尝试在node节点之间做均衡,以保证node节点都保持dirty limit的均衡;但是,dirty page spread只在第一轮get_page_from_freelist()才开启,当在__alloc_pages_slowpath()再次调用时,就没有这个限制了。
- 如果要求的numa node节点没有可用内存,则根据/proc/sys/vm/zone_reclaim_mode接口的值,为0时,尝试从其他numa节点获取内存,为1则直接在本节点执行回收,并获取内存;
注:cpuset有个spread mem的功能,可以让page cache或者slab page分配到多个node上
7.1.3 memory policy
memory policy决定的是任务该从哪个numa node节点申请内存,最典型的函数,
#ifdef CONFIG_NUMA
static inline struct page *
alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_current(gfp_mask, order);
}
#else
#define alloc_pages(gfp_mask, order) \
alloc_pages_node(numa_node_id(), gfp_mask, order)
#endif
struct page *alloc_pages_current(gfp_t gfp, unsigned order)
{
struct mempolicy *pol = &default_policy;
struct page *page;
if (!in_interrupt() && !(gfp & __GFP_THISNODE))
pol = get_task_policy(current);
/*
* No reference counting needed for current->mempolicy
* nor system default_policy
*/
if (pol->mode == MPOL_INTERLEAVE)
page = alloc_page_interleave(gfp, order, interleave_nodes(pol));
else
page = __alloc_pages_nodemask(gfp, order,
policy_node(gfp, pol, numa_node_id()),
policy_nodemask(gfp, pol));
return page;
}
memory policy包括
- MPOL_DEFAULT
- MPOL_PREFERED,取task_struct.mempolicy->v.preferred_node
- MPOL_INTERLEAVE,
interleave_nodes() --- struct task_struct *me = current; next = next_node_in(me->il_prev, policy->v.nodes); if (next < MAX_NUMNODES) me->il_prev = next; return next; --- - MPOL_BIND
- MPOL_LOCAL,取numa_node_id()
在系统启动过程中,系统的mempolicy发生了两次变化,
- init_task的mempolicy是空,从start_kernel()开始,使用的是default_policy(MPOL_PREFERED, MPOL_F_LOCAL),参考函数policy_node(),其使用的是numa_node_id();
- 至numa_policy_init(),大体上都是些early_init,numa_policy_init()会将mempolicy转变成MPOL_INTERLEAVE;
- 进入reset_init(),启动1号任务,kernel_init(),在进入init之前,调用numa_default_policy(),mempolicy清空,于是用户态任务默认都是default_policy
- reset_init()在创建kthreadd,即2号任务,执行numa_default_policy(),于是idle和所有内核线程也变回default_policy
中间短暂的interleave policy,内核文档的解释是:
However, during boot up, the system default policy will be set to interleave allocations across all nodes with “sufficient” memory, so as not to overload the initial boot node with boot-time allocations.
不过,我觉得interleave的原因也包括,让内核核心模块的内存分布在多个节点上,可以让性能更加均衡。
之后,任务的的默认mempolicy为,preferred_node_policy,参考代码
struct mempolicy *get_task_policy(struct task_struct *p)
{
struct mempolicy *pol = p->mempolicy;
int node;
if (pol)
return pol;
node = numa_node_id();
if (node != NUMA_NO_NODE) {
pol = &preferred_node_policy[node];
/* preferred_node_policy is not initialised early in boot */
if (pol->mode)
return pol;
}
return &default_policy;
}
for_each_node(nid) {
preferred_node_policy[nid] = (struct mempolicy) {
.refcnt = ATOMIC_INIT(1),
.mode = MPOL_PREFERRED,
.flags = MPOL_F_MOF | MPOL_F_MORON,
.v = { .preferred_node = nid, },
};
}
此时的preferred策略相当于local;
7.1.4 memory numa balance
然而,任务并不会老老实实的待在其分配内存的node节点上,而和可能被调度到其他node上,此时,就会产生跨numa访问;memory numa balance是基于内存迁移的方案,即把内存迁移到任务所在的node上。具体使用方法和参数,可以参考,
Automatic Non-Uniform Memory Access (NUMA) Balancing![]() https://documentation.suse.com/sles/15-SP1/html/SLES-all/cha-tuning-numactl.htmlmemory numa balance工作流程分为三步:
https://documentation.suse.com/sles/15-SP1/html/SLES-all/cha-tuning-numactl.htmlmemory numa balance工作流程分为三步:
- Scan,发起时机在task_tick_fair()->task_tick_numa(),这意味着,只有CFS任务有这个功能;scan的执行通过task work,执行时机为任务返回用户态之前(参考tracehook_notify_resume),执行函数为task_numa_work();其需要遍历所有的vma,并将其中符合条件的页表项权限改为PROT_NONE(change_prot_numa);
Shared library pages mapped by multiple processes are not migrated as it is expected they are cache replicated. Avoid hinting faults in read-only file-backed mappings or the vdso as migrating the pages will be of marginal benefit.
- Fault,被清除页表项权限的page被访问的时候,会发生page fault,参考handle_pte_fault(),
handle_pte_fault() --- if (pte_protnone(vmf->orig_pte) && vma_is_accessible(vmf->vma)) return do_numa_page(vmf); ---在do_numa_page()中,会更正页表项的权限,同时检查,page的node id是否符合mempolicy的设定,通常就是local node,如果不符合,就进入下一步,做page迁移
- Migrate,调用migrate_misplaced_page(),最终调用migrate_pages()执行page迁移;
执行memory numa balance的page,都是mmap到程序地址空间的,可以是匿名也可以是文件页,文件页的迁移比较苛刻,
- 如果被多个进程mmap,
- dirty的,或者writeback的(MIGRATE_SYNC可以)
- read-only的
7.1.5 sched numa balance
在调度方面,numa balance会统计这个任务在对应各个numa node上发生numa faults的数量,然后,将任务迁移到那个numa faults数量最多的那个numa 节点上去。
- sched numa balance的时机发生在numa page fault,相关函数为task_numa_fault(),主要包括两步,numa placement和numa migrate,执行间隔为numa_scan_period的1/16;
- numa placement用来决定task_struct.numa_preferred_nid,具体算法在task_numa_placement(),如果忽略numa group功能,可简化如下:
/* Find the node with the highest number of faults */ for_each_online_node(nid) { unsigned long faults = 0; for (priv = 0; priv < NR_NUMA_HINT_FAULT_TYPES; priv++) { long diff, f_diff, f_weight; mem_idx = task_faults_idx(NUMA_MEM, nid, priv); membuf_idx = task_faults_idx(NUMA_MEMBUF, nid, priv); /* Decay existing window, copy faults since last scan */ diff = p->numa_faults[membuf_idx] - p->numa_faults[mem_idx] / 2; p->numa_faults[membuf_idx] = 0; p->numa_faults[mem_idx] += diff; faults += p->numa_faults[mem_idx]; } if (!ng) { if (faults > max_faults) { max_faults = faults; max_nid = nid; } } }在决定出node id之后,会使用sched_setnuma()更新任务的numa_preferred_nid;
-
task_numa_migrate()会在numa_preferred_nid中选择一个合适的cpu,然后将该任务迁移过去;
注:do_numa_page()可能刚刚执行了page迁移,task_numa_fault()再把任务迁移走,这不会引起bounce吗?首先可以确定的是task_numa_fault()执行任务迁移是有一定间隔的,不会每次执行完page migrate都会发生迁移。














 480
480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









