






前言
======
又到一年双11,相信大部分同学都曾经有这个疑问:支撑起淘宝双11这么大的流量,需要用到哪些核心技术?性能优化系列的第二篇我想跟大家探讨一下这个话题。
完整的双11链路是非常长的,我当前也没这个实力跟大家去探讨完整的链路,本文只跟大家探讨其中的一个核心环节:商品浏览。
商品浏览是整个链路中流量最大的或者至少是之一,这个大家应该不会有疑问,因为几乎每个环节都需要商品浏览。
阿里云公布的2020年双11订单创建峰值是58.3万笔/秒,而我们在下单前经常会点来点去看这个看那个的,因此商品浏览肯定至少在百万QPS级别。
废话不多说,直接开怼。
正文
======
1、MySQL硬抗
不知道有没有老铁想过用MySQL硬抗双11百万QPS,反正我是没有,不过我们还是用数据来说说为什么不可能这么做。
根据MySQL官方的基准测试,MySQL在通常模式下的性能如下图所示:

当然这个数据仅供参考,实际性能跟使用的机器配置、数据量、读写比例啥的都有影响。
首先,淘宝的数据量肯定是比较大的,这个毋庸置疑,但是无论怎么分库分表,由于成本等原因,肯定每个库还是会有大量的数据。
我当前所在的业务刚好数据量也比较大,我们DBA给的建议是单库QPS尽量控制在5000左右,实际上有可能到1万也没问题,但是此时可能存在潜在风险。
DBA给的这个建议值是比较稳健保守的,控制在这个值下基本不会出问题,因此我们尽量按DBA的建议来,毕竟他们在这方面会更专业一些。
如果按照单库抗5000来算,即使多加几个从库,也就抗个十来万QPS顶天了,要抗百万QPS就根本不可能了,流量一进来,DB肯定马上跪成一片灰烬。
有同学可能会想,能不能无限加从库硬怼?
这个是不行的,因为从库是需要占用主库资源的,看过我之前MySQL面试题的同学应该知道,主库需要不断和从库进行通信,传输binlog啥的,从库多了主库会受影响,无限加从库最后的结果肯定是将主库怼挂了,我们这边的建议值是从库数量尽量不要超过20个,超了就要想其他法子来优化。
2、分布式缓存(Tair)硬抗
上分布式缓存硬抗应该是大部分老哥会想到的,我们也用数据来分析一下可行性。
阿里用的分布式缓存是自研的 Tair,不知道的可以理解为 Redis 吧,对外其实也是说的 Redis 企业版。
Tair官方自称性能约为同规格社区版实例的3倍。阿里云官网上,Tair企业版性能增强-集群版当前的实例规格如下图所示:
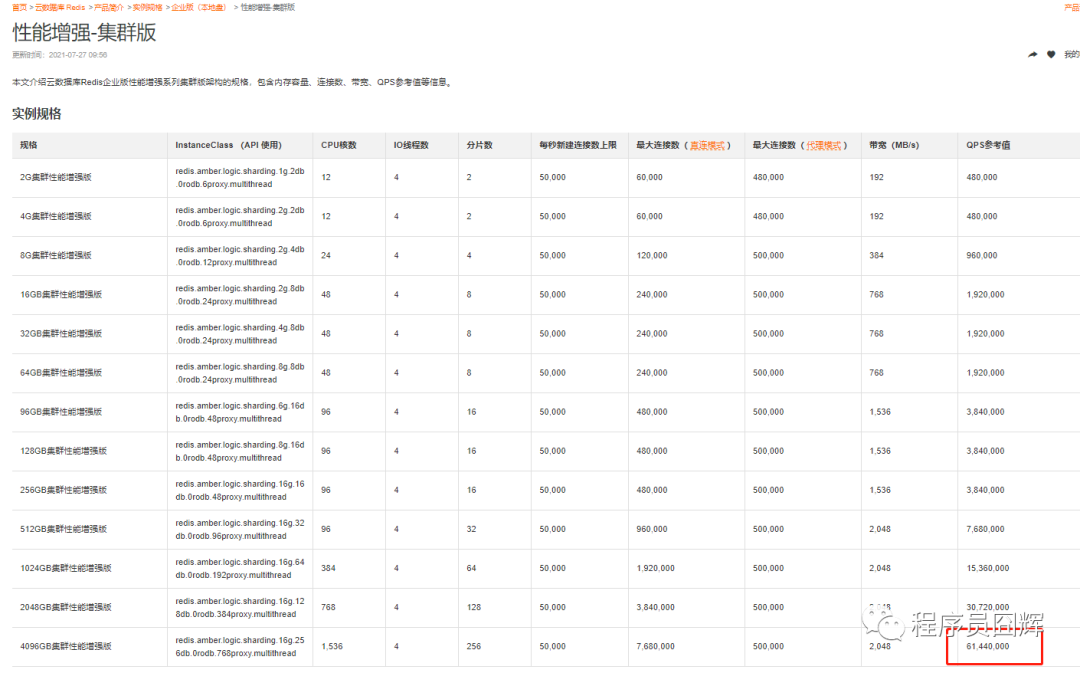
右下角最猛的【4096GB集群性能增强版】的QPS参考值超过6000万+,没错,我数了好几遍,就是6000万,我的龟龟,太变态了。
直接把【4096GB集群性能增强版】怼上去就解决了,还要啥优化。如果一个解决不了,大不了就两个嘛。
分布式缓存确实是大多数情况下抗读流量的主力,所以用Tair硬抗的方案肯定是没大问题的,但是我们需要思考下是否存在以一些细节问题,例如:
-
分布式缓存通常放在服务端,上游通过RPC来调用获取商品信息,百万级的流量瞬间打进来,是否会直接将RPC的线程池打挂?
-
缓存里的信息通常是先查询DB再写到缓存里,百万级的流量瞬间打进来,是否会直接将DB打挂?
-
是否存在热点商品,导致Tair单节点扛不住?
-
…
这些问题我们接下来一一讨论。
3、客户端分布式缓存
分布式缓存放在服务端,我们称之为服务端分布式缓存,但是要使用服务端分布式缓存需要上游进行RPC调用,请求量太大会带来隐患,同时带来了额外的网络请求耗时。
为了解决这个问题,我们引入客户端分布式缓存,所谓客户端分布式缓存就是将请求Tair的流程集成在SDK里,如果Tair存在数据,则直接返回结果,无需再请求到服务端。
这样一来,商品信息只要在Tair缓存里,请求到客户端就会结束流程,服务端的压力会大大降低,同时实现也比较简单,只是将服务端的Tair请求流程在SDK里实现一遍。
4、缓存预热
为了解决缓存为空穿透到DB将DB打挂的风险,可以对商品进行预热,提前将商品数据加载到Tair缓存中,将请求直接拦截在Tair,避免大量商品数据同时穿透DB,打挂DB。
具体预热哪些商品了?
这个其实不难选择,将热点商品统计出来即可,例如以下几类:
1)在双11零点付款前,大部分用户都会将要买的商品放到购物车,因此可以对购物车的数据进行一个统计,将其中的热点数据计算出来即可。
2)对一些有参与优惠或秒杀活动的商品进行统计,参与活动的商品一般也会被抢购的比较厉害。
3)最近一段时间销量比较大的商品,或者浏览量比较大的商品。
4)有参与到首页活动的商品,最近一段时间收藏夹的商品等等…
淘宝背后有各种各样的数据,统计出需要预热的商品并不难。
通过预热,可以大大降低DB被穿透的风险。
5、客户端本地缓存
阿里云官网的数据【4096GB集群性能增强版】的QPS参考值超过6000万+,但是这个值是在请求分布比较均匀的情况下的参考值,256个分片上每个分片二三十万这样。
通常个别分片高一点也没事,五六十万估计也ok,但是一般不能高太多,否则可能出现带宽被打满、节点处理不过来等情况,导致整个集群被打垮。
这个时候就需要祭出我们的最终神器了,也就是本地缓存。本地缓存的性能有多牛逼了,我们看下这张图。
这张图是caffeine(一个高性能Java缓存框架)官方提供的本地测试结果,并不是服务器上的测试结果。
测试运行在 MacBook Pro i7-4870HQ CPU @ 2.50GHz (4 core) 16 GB Yosemite系统,简单来说,比较一般的配置,大部分服务器配置应该都会比这个高。
在这个基准测试中, 8 线程对一个配置了最大容量的缓存进行并发读。

可以看到,caffeine支持每秒操作数差不多是1.5亿,而另一个常见的缓存框架Guava差不多也有2000多万的样子。
而在服务器上测试结果如下:
服务器配置是单插槽 Xeon E5-2698B v3 @ 2.00GHz (16 核, 禁用超线程),224 GB,Ubuntu 15.04。

最后
为什么我不完全主张自学?
①平台上的大牛基本上都有很多年的工作经验了,你有没有想过之前行业的门槛是什么样的,现在行业门槛是什么样的?以前企业对于程序员能力要求没有这么高,甚至十多年前你只要会写个“Hello World”,你都可以入门这个行业,所以以前要入门是完全可以入门的。
②现在也有一些优秀的年轻大牛,他们或许也是自学成才,但是他们一定是具备优秀的学习能力,优秀的自我管理能力(时间管理,静心坚持等方面)以及善于发现问题并总结问题。
如果说你认为你的目标十分明确,能做到第②点所说的几个点,以目前的市场来看,你才真正的适合去自学。
除此之外,对于绝大部分人来说,报班一定是最好的一种快速成长的方式。但是有个问题,现在市场上的培训机构质量参差不齐,如果你没有找准一个好的培训班,完全是浪费精力,时间以及金钱,这个需要自己去甄别选择。
我个人建议线上比线下的性价比更高,线下培训价格基本上没2W是下不来的,线上教育现在比较成熟了,此次疫情期间,学生基本上都感受过线上的学习模式。相比线下而言,线上的优势以我的了解主要是以下几个方面:
①价格:线上的价格基本上是线下的一半;
②老师:相对而言线上教育的师资力量比线下更强大也更加丰富,资源更好协调;
③时间:学习时间相对而言更自由,不用裸辞学习,适合边学边工作,降低生活压力;
④课程:从课程内容来说,确实要比线下讲的更加深入。
应该学哪些技术才能达到企业的要求?(下图总结)


基本上没2W是下不来的,线上教育现在比较成熟了,此次疫情期间,学生基本上都感受过线上的学习模式。相比线下而言,线上的优势以我的了解主要是以下几个方面:
①价格:线上的价格基本上是线下的一半;
②老师:相对而言线上教育的师资力量比线下更强大也更加丰富,资源更好协调;
③时间:学习时间相对而言更自由,不用裸辞学习,适合边学边工作,降低生活压力;
④课程:从课程内容来说,确实要比线下讲的更加深入。
应该学哪些技术才能达到企业的要求?(下图总结)
[外链图片转存中…(img-XQzhtf5F-1714206641669)]
[外链图片转存中…(img-TPlDkjuA-1714206641669)]















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









