







最后
一次偶然,从朋友那里得到一份“java高分面试指南”,里面涵盖了25个分类的面试题以及详细的解析:JavaOOP、Java集合/泛型、Java中的IO与NIO、Java反射、Java序列化、Java注解、多线程&并发、JVM、Mysql、Redis、Memcached、MongoDB、Spring、Spring Boot、Spring Cloud、RabbitMQ、Dubbo 、MyBatis 、ZooKeeper 、数据结构、算法、Elasticsearch 、Kafka 、微服务、Linux。
这不,马上就要到招聘季了,很多朋友又开始准备“金三银四”的春招啦,那我想这份“java高分面试指南”应该起到不小的作用,所以今天想给大家分享一下。

请注意:关于这份“java高分面试指南”,每一个方向专题(25个)的题目这里几乎都会列举,在不看答案的情况下,大家可以自行测试一下水平 且由于篇幅原因,这边无法展示所有完整的答案解析
如下图所示,应用请求会进入所有后端服务集群。如果各个服务节点都是正常的,那么服务节点便会正常响应, 对应的依赖的服务也会正常运行,一切看起来都很美好。
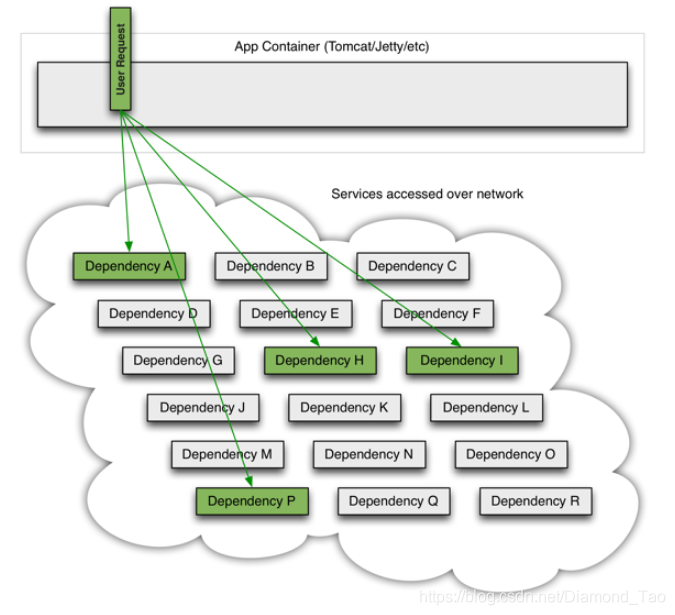
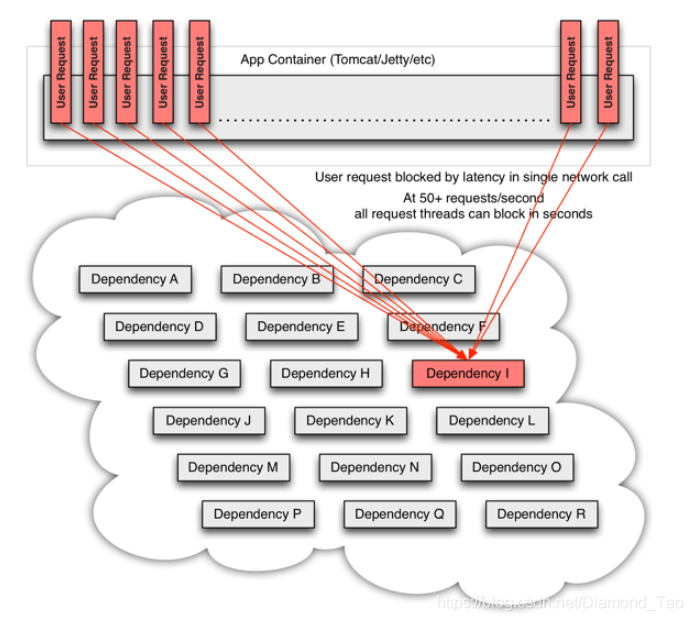
但是现实总是很残酷的,如果依赖的某个服务节点出现异常,比如此时服务正在进行full GC,无法响应外部请求。因此此时的用户请求会被阻塞住。如下图所示,用户请求分别调用服务A、H、I以及P服务来完成某项业务流程,但是此时服务I出现异常或者服务I集群的某个节点出现了异常,虽然两者的连接还保持着,但是所有发送过去的业务请求都出现timeout。那么此时调用方的工作线程就会被阻塞住,导致调用方出现线程不断被被占用的情况。

在流量较大的场景下,由于后端某些节点的异常,服务提供者不可用,如下图的依赖I服务不可用,请求无法正常返回,那么调用方会不断进行重试进一步加大流量,最终导致调用方线程资源耗尽,导致服务调用者不可用。服务调用者也可能是上游服务的服务提供方,由于请求资源不断被占用,同时导致上游依赖应用同步被影响,最后故障点会蔓延到整个平台中。
2、问题破解
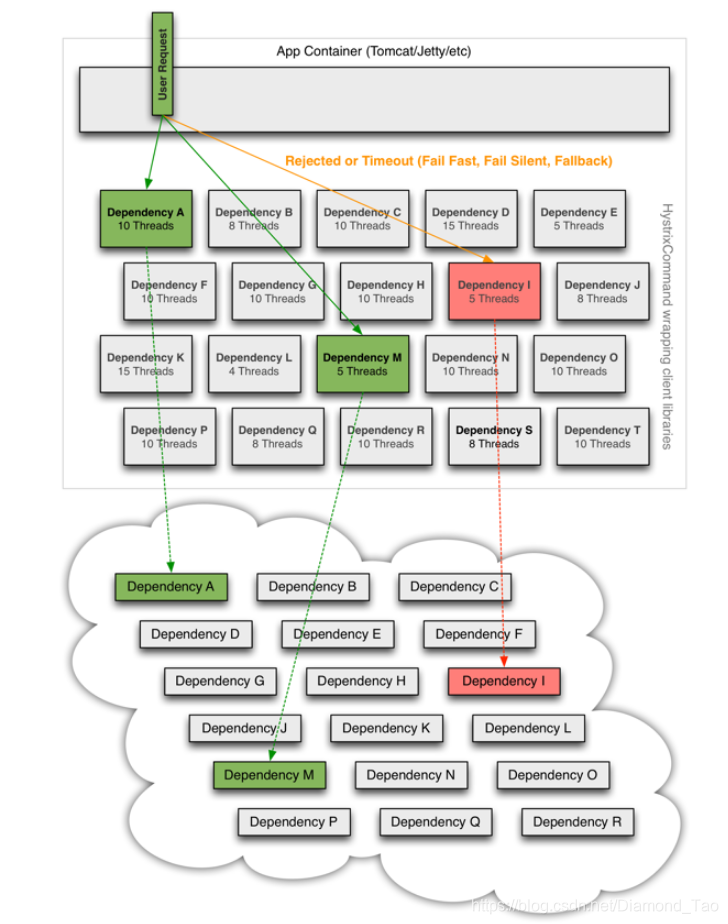
既然微服务架构中某个节点的异常可能导致整个平台的不可用,有什么好的解决方案可以解决这个问题呢?如果说这个故障节点就像是病毒传播的一号病人一样,那么只要及时的发现以及隔离它,避免异常节点的进一步影响发散,是不是就可以解决微服务架构各个服务之间的依赖调用异常导致的问题。基于此的分析,我们希望借助Hystrix实现如下的几点核心逻辑:
资源隔离:限制调用服务使用的资源,当某一下游服务出现问题时,不会影响整个服务调用链。
服务熔断:当失败率达到阀值自动触发熔断,熔断器触发后原有的请求链路被切断,请求无法正常触达服务提供方。
服务降级:超时、资源不足等异常触发熔断后,需要调用预设的降级接口返回兜底数据,提升平台容错能力。
3、实现原理
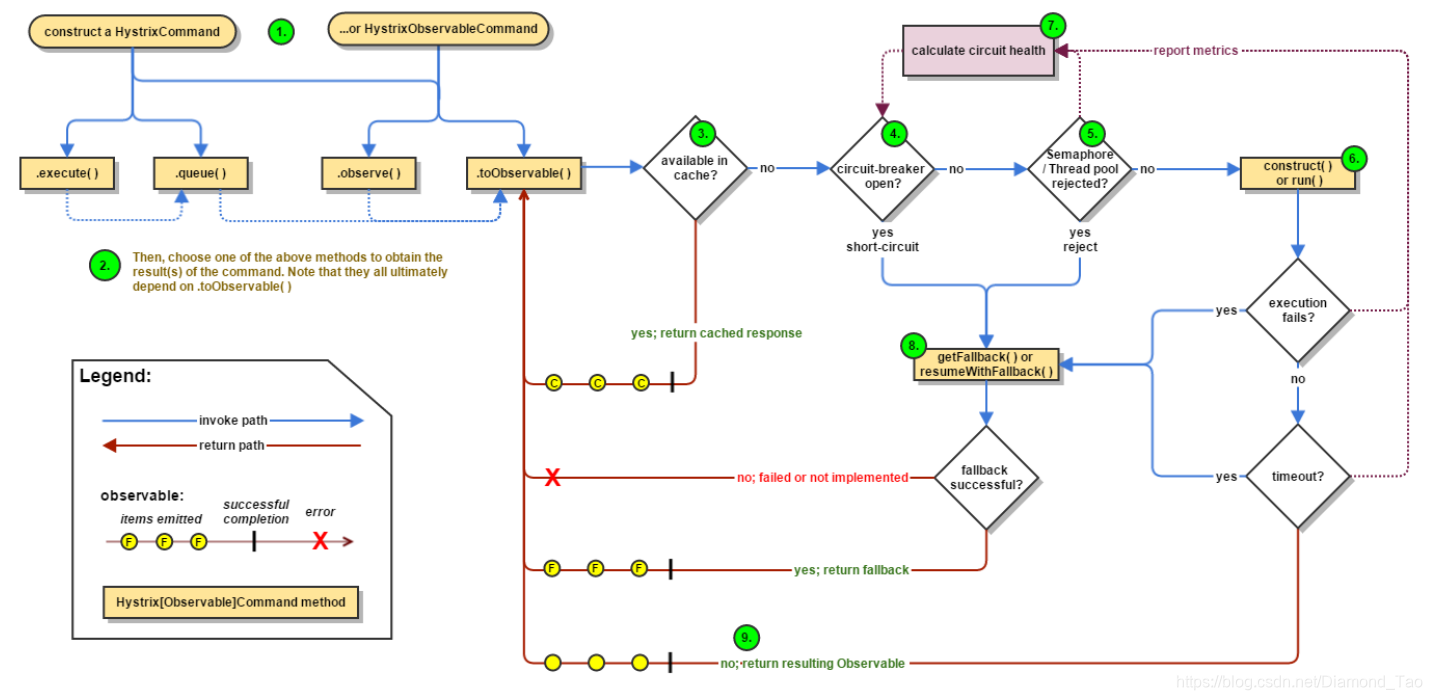
(1)业务流程
如果想要实现异常情况的熔断保护,首先我们得有个断路器,由它作为调用流量的开关。大致的运行逻辑如下图所示,服务调用时判断断路器是否打开,如果打开了则进行降级操作,果没有打开则判断信号量以及线程池是否拒绝,如果拒绝则同样执行降级流程。如果正常则上报自己的健康状态。执行正常流程看是否成功,失败了则执行降级流程。如果成功了,则上报监控数据,如果超时同样是执行降级策略。
(2)断路器原理分析
断路器的作用实际就是之前文章中说到的微服务架构中的保险丝一样,起到保护系统的作用。当对下游服务调用异常量达到设定阈值后,将断路器打开,触发熔断操作,避免流量继续堆积。
断路器涉及到的主要设计点主要包括两项,一个是断路器的控制逻辑(控制断路器开关的打开和关闭),另一个是触发断路操作的阈值判断与数据统计(统计数据作为断路器的操作判断)。对于断路器本身来说表面上看就是断路器的开关打开或者关闭来控制是否走降级逻辑,实际上核心的逻辑是如何判断什么时候该开以及什么时候该关。

断路器逻辑控制
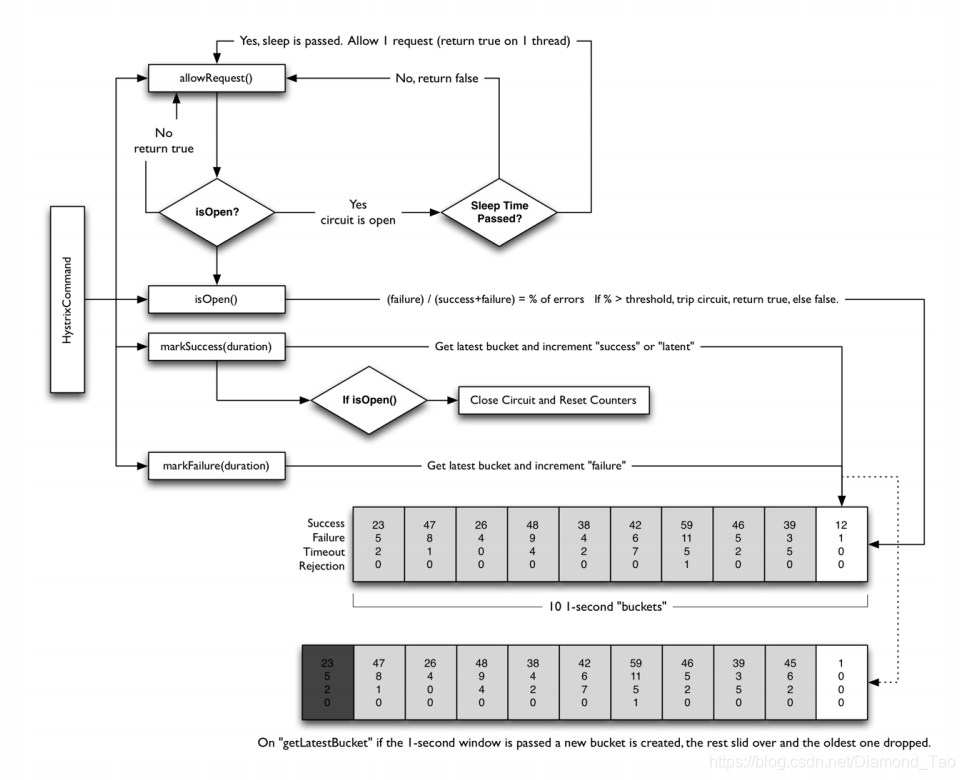
断路器的状态转换和注册中心的服务是否在线有点类似,都涉及到状态的变化,只不过断路器多了个半打开的状态。因此实际上还需要对服务是否恢复正常进行判断的过程。大致流程如上图所示,断路器的初始状态是关闭状态,一旦请求失败情况达到了阈值便会打开断路器。断路器打开后需要进行探测,探测什么时候异常恢复之后还是要将断路器进行关闭的。但是在打开断路器之后不会立马进行探测,而是需要经历个窗口期,不然立马重试必然还是失败,这个窗口期就相当于给别人一个恢复的时间窗口。
当过了窗口期之后,将一些请求进行放开,让其完成正常的下游业务调用,进行请求试探,如果成功则关闭断路器,如果失败则继续维持当前断路器的OPEN状态。当然至于探测这块不是说一次成功或者失败就改变断路器现有的状态,这里可以设置对应的状态变更策略。
阈值统计
阈值以及数据统计是进行开关打开的判断依据,因此如何统计数据是非常关键的设计。如果阈值统计不够准确有效,那么实际无法起到该有的作用,如果断路器过于敏感,偶尔的调用异常就打开断路器(网络抖动等),势必会严重影响正常的业务流程。如果断路器过于迟钝,该打开的时候不打开,那么可能导致异常在全平台的传播。
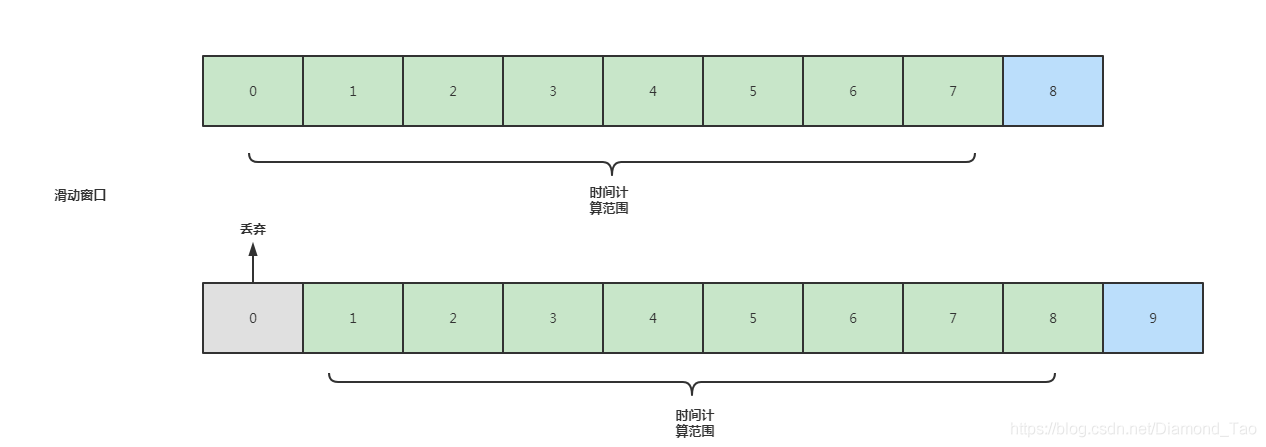
既然不能通过一次的调用成功或者失败来判断,那么我们可以把统计的周期拉长,通过几个周期来判断。同时为了保证判断的时效性,统计的周期需要不断更新。如上图所示,一开始的统计周期是0-7,过了一个时间节点后统计周期就是1-8,时间间隔不变但是统计的开始时间和结束时间是实时更新的,这就类似一个滑动窗口,随着时间的推移不断向前行进,保障统计的时效。
(3)隔离设计
Hystrix通过隔离的方式来限制异常节点访问对平台的影响,这个就类似于之前我文章提到的船舱内的隔板,限制异常影响范围。主要包括线程池隔离以及信号量隔离。
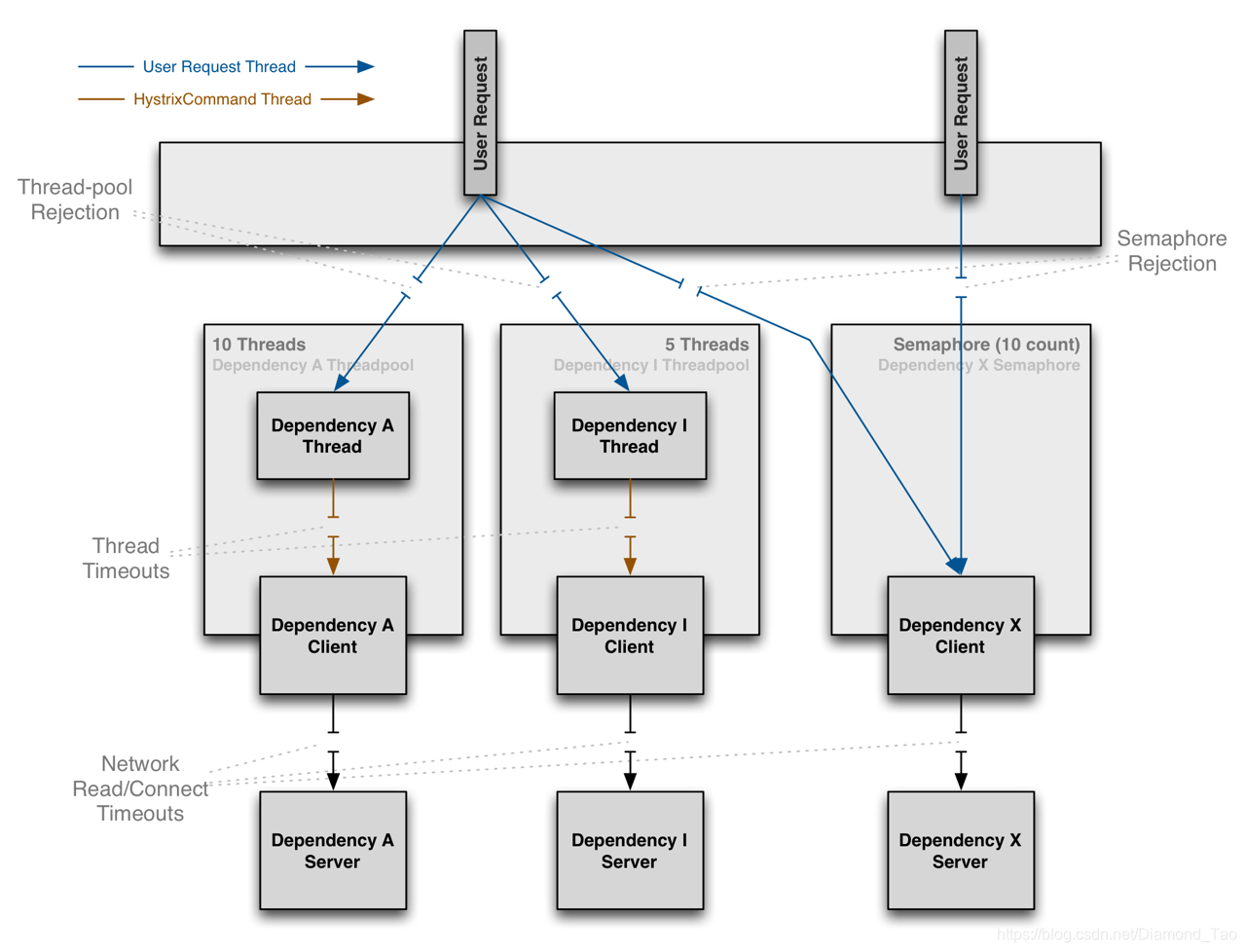
线程隔离
如上图所示,在线程隔离的实现方式中,通过将用户请求线程与Hystrix组件线程进行隔离,如果出现服务提供方不可用的情况,阻塞的线程是线程池冲分配的线程,将资源隔离的影响降到最低。组件包装依赖调用逻辑,每个调用conmand在单独线程池中执行,限制线程资源占用。
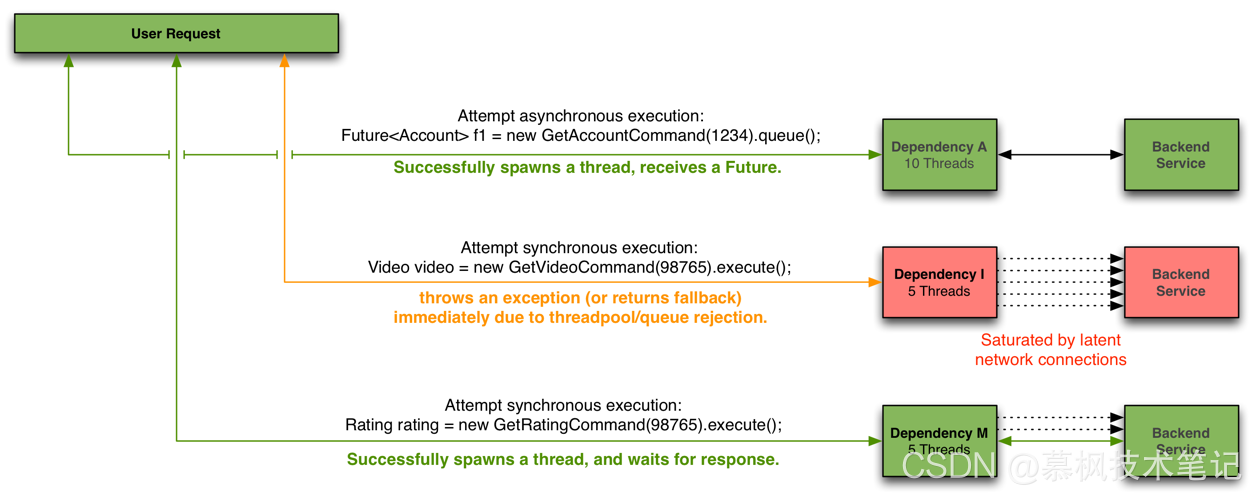
通过发送请求线程与执行请求的线程资源隔离,可有效防止发生级联故障。当线程池或请求队列饱和时,Hystrix将拒绝服务,使得服务请求线程可以fast-fail,从而避免服务节点问题导致的依赖异常扩散。
信号量隔离
我们都知道线程池的引入会带来一定的资源消耗,因为涉及到线程池内部的线程资源调度。因此比较适合引入线程池带来的好处多于资源调用损耗的场景。在一般的场景下,使用更加轻量级的隔离方式会更加适合,那么信号量正是这种轻量级的隔离方式,不存在线程上下文切换所带来的性能开销。从隔离设计的第一张图中我们可以看出使用线程池时,发送请求的线程和执行依赖服务的线程不是同一个,线程池的使用方式就是将它们进行了隔离。而使用信号量时,发送请求的线程和执行依赖服务的线程是同一个线程, 都是发起请求的线程,信号量隔离限制对某个资源调用的并发数。
总结
本文主要对微服务架构中服务容错降级进行背景问题分析,阐述了服务容错组件Hystrix组件在服务容错、降价以及熔断方面的设计内容。相信大家对于服务容错这块内容有了更加深刻的理解。在后面的文章中,笔者将对Hystrix组件在开发的微服务应用中具体的应用进行说明,请大家敬请期待。
最后
针对最近很多人都在面试,我这边也整理了相当多的面试专题资料,也有其他大厂的面经。希望可以帮助到大家。
下面的面试题答案都整理成文档笔记。也还整理了一些面试资料&最新2021收集的一些大厂的面试真题(都整理成文档,小部分截图)

最新整理电子书

0ff254613a03fab5e56a57acb)收录**















 489
489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









