







三、MySQL MVCC实现原理+源码分析
MySQL InnoDB引擎实现的MVCC, 主要依赖数据行的隐式字段与undo log生成的日志版本链, 再结合ReadView可见性判断机制实现.
3.1 隐式字段
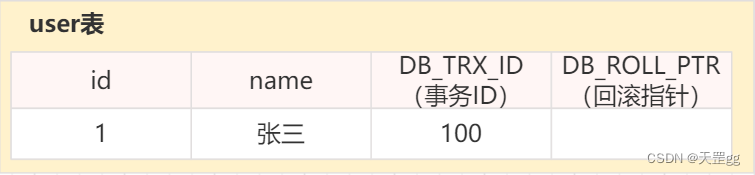
在内部,InnoDB向数据库中存储的每一行添加三个字段:
- DB_TRX_ID :6 byte,插入或更新行的最后一个事务ID. (
解读:用于MVCC的ReadView判断事务id)
此外, 删除在内部被视为更新,其中行中的一个特殊位被设置为将其标记为已删除. - DB_ROLL_PTR:7 byte,回滚指针. (
解读:用于MVCC中指向undo log记录)
指向已写入回滚段(rollback segment)的一条undo log记录, 记录着行(row)更新前的副本. - DB_ROW_ID:6 byte,隐藏的自增 ID. (
解读:对于MVCC可忽略该字段)
如果InnoDB自动生成聚集索引, 则索引包含这个行ID值. 否则, DB_ROW_ID列不会出现在任何索引中.
大概是这样:
源码验证
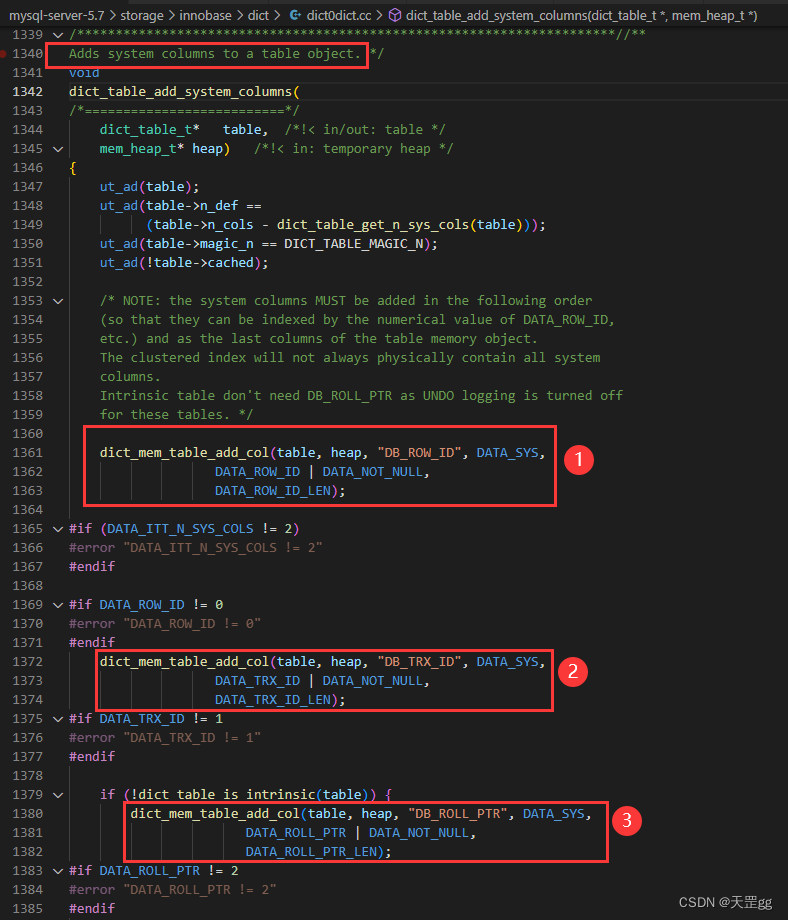
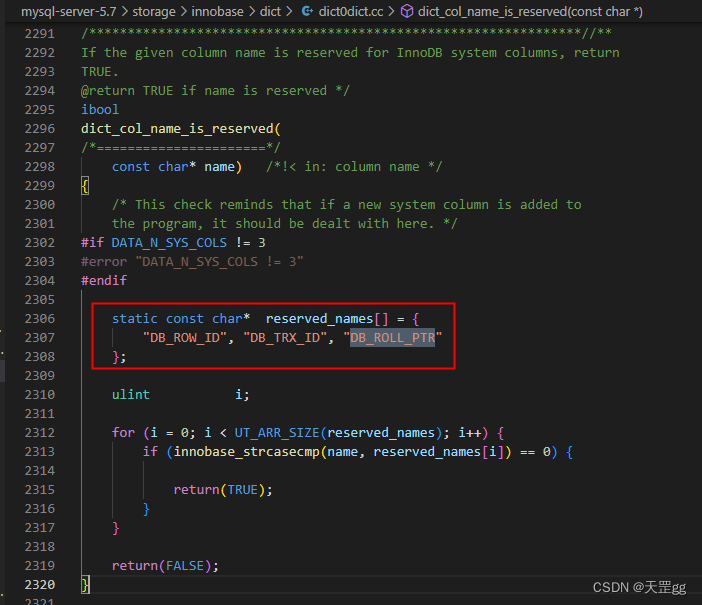
参考官方:

3.2 undo log
undo log,撤销日志。
在事务中,insert/update/delete每一个sql语句的更改都会写入undo log,当事务回滚时,可以利用 undo log 来进行回滚。
undo 日志的存储结构比较复杂, 本文不做详细解读. 最小单元的undo log都有next和start 两个字段, 形成一个双向链表, 示意图:
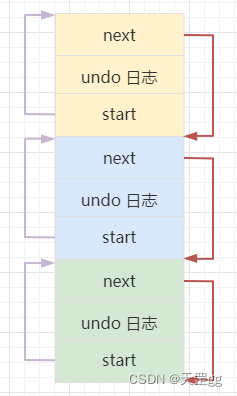
undo log格式
- insert undo log
insert undo log是指在insert操作中产生的undo log, 仅用于事务回滚. 因为insert操作的记录, 只对事务本身可见, 对其它事务不可见, 所以该日志可以在事务commit后直接删除. 不需要进行purge(后台清除线程)操作. 格式如图7-14所示. - update undo log
update undo log是对delete和update操作产生的的undo log. 该undo log可能需要提供MVCC机制, 因此不能在事务commit后就进行删除. 提交时放入undo log链表,等待purge线程(后台清除线程)进行最后的删除. 格式如图7-15所示.
注:图片来源于姜承尧老师的《MySQL技术内幕 InnoDB存储引擎 第2版》
*表示对存储的字段进行了压缩
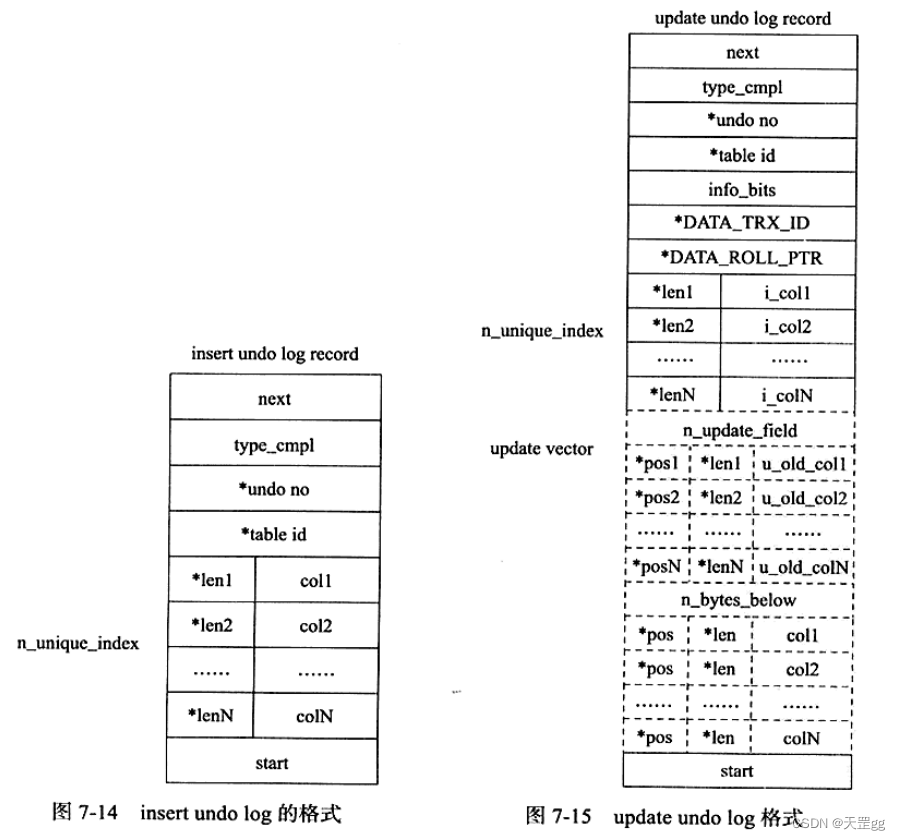
- insert undo log 格式解读
| 字段 | 说明 |
|---|---|
| next | 2字节, 下一个undo log的位置. |
| type_cmpl | 1字节, undo类型. insert un log值固定为11 |
| undo_no | undo编号 |
| table_id | table.id |
| lenN + colN | 所有列的长度和数据(插入到聚集索引中的) |
| start | 2字节, 本条undo log开始的位置. |
- update undo log 格式解读
next、start、undo_no、table_id、lenN + colN和之前的insert undo log相同, 不做重复说明.
| 字段 | 说明 |
|---|---|
| DATA_TRX_ID | 旧记录的事务id(关键:用于MVCC的ReadView判断事务id) |
| DATA_ROLL_PTR | 旧记录的回滚指针(关键:用于MVCC中指向前一个undo log记录) |
| type_cmpl | 12 TRX_UNDO_UPD_EXIST_REC 更新non-delete-mark的记录13 TRX_UNDO_UPD_DEL_REC 将delete的记录标识为not delete 14 TRX_UNDO_UPD_DEL_MARK_REC 将记录标为delete |
| update_vector | 表示update操作导致发生改变的列. (不做详细解读) |
undo log源码验证
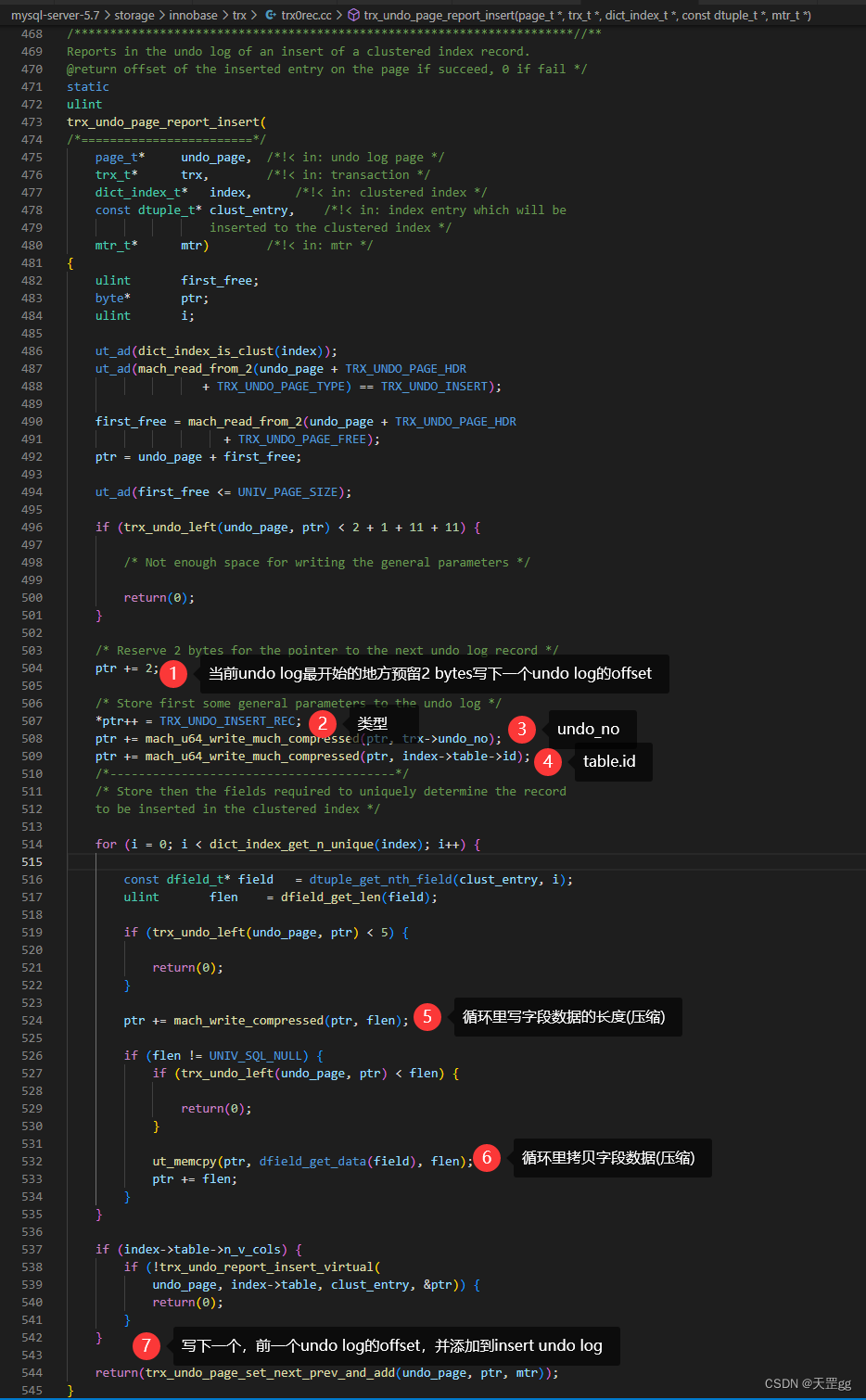
写insert undo log源码
入口函数:trx_undo_page_report_insert
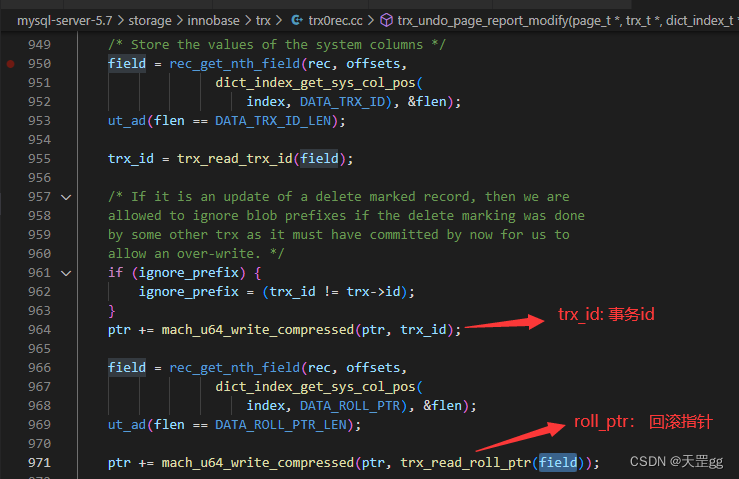
写update undo log源码
入口函数:trx_undo_page_report_modify
这里只贴最关键的写trx_id和roll_ptr:
写undo log源码
不管是insert undo log还是update undo log,
它们只有一处调用:trx_undo_report_row_operation
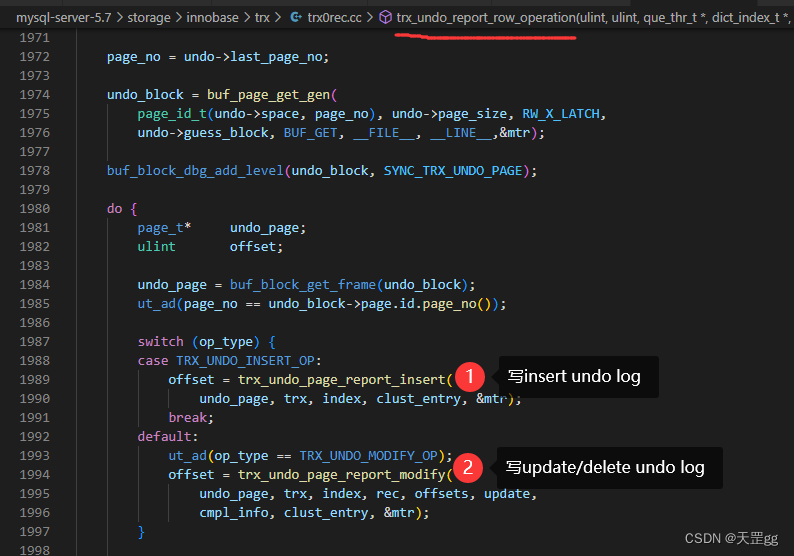
最后写完undo log构建当前undo log的roll_ptr
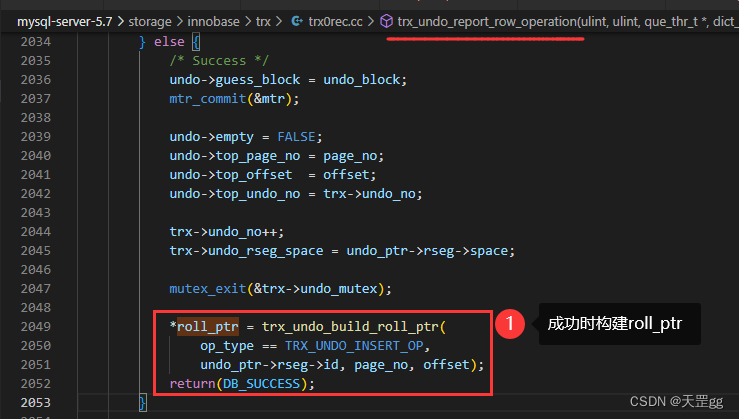
roll_ptr是如何指向insert undo log的?
入口函数:btr_cur_ins_lock_and_undo
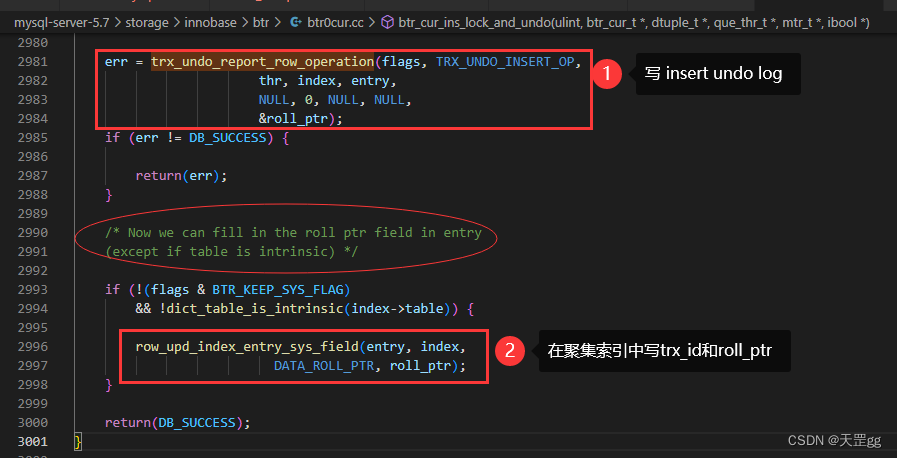
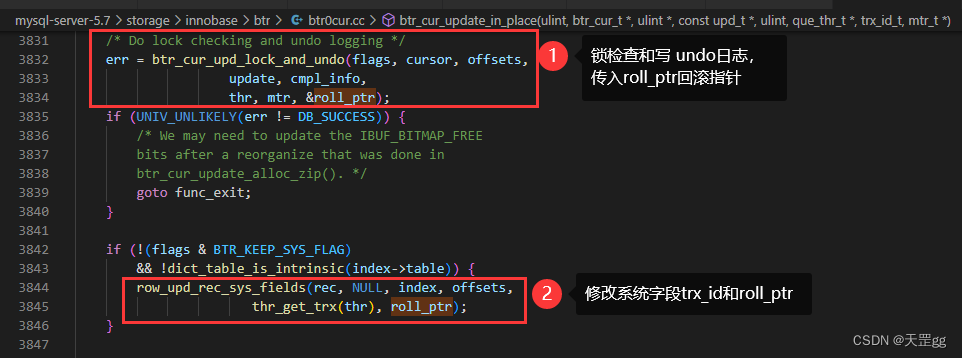
调用row_upd_index_entry_sys_field设置聚集索引中的trx_id和roll_ptr
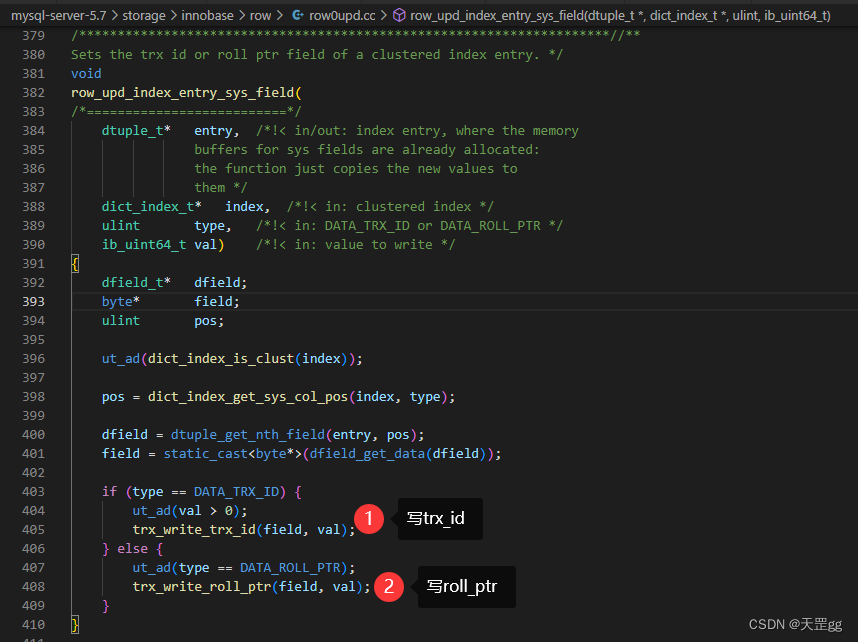
roll_ptr是如何指向update undo log的?
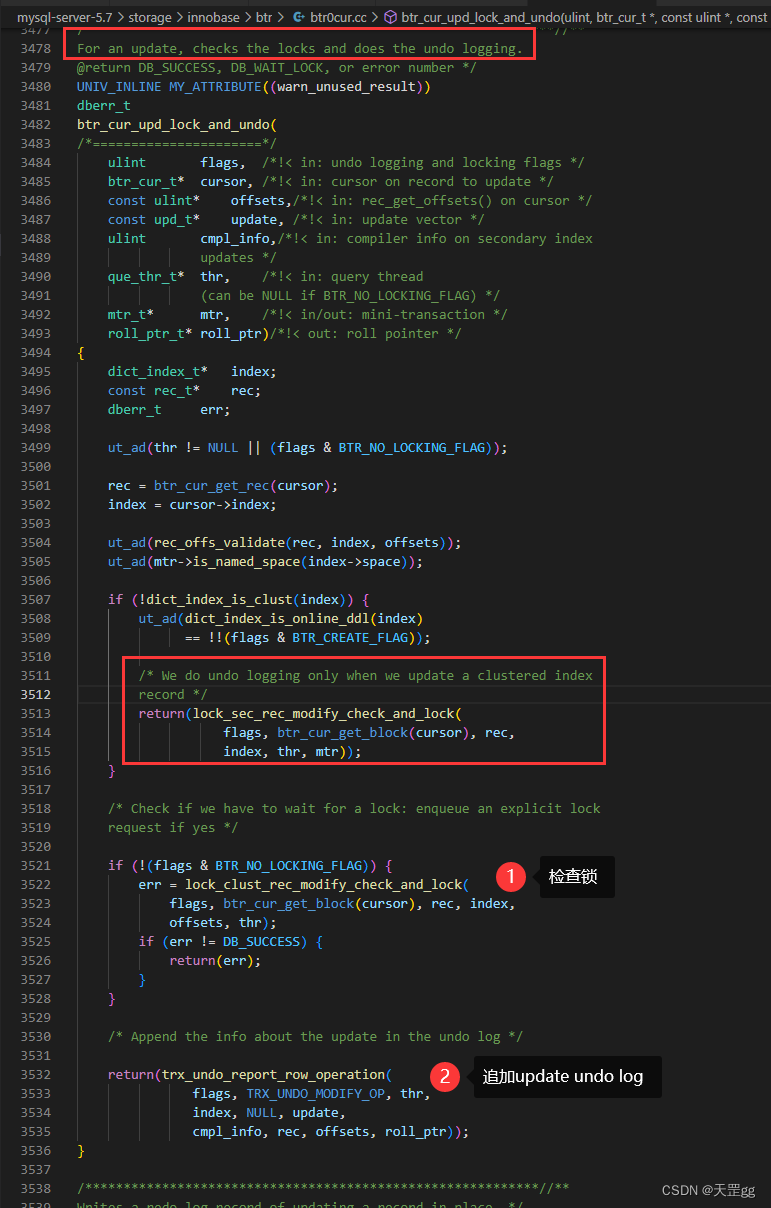
我们已知写undo log的统一入口是 trx_undo_report_row_operation , 我们先看调用它的函数: btr_cur_upd_lock_and_undo
从注释可以看出:对于更新,检查锁并追加undo log
另外,如果不是聚集索引就不会写undo log,看红框 We do undo logging only when we update a clustered index record(只有在更新聚集索引记录时,才写undo log)
咱们再找btr_cur_upd_lock_and_undo的引用,就找到了btr_cur_update_in_place:
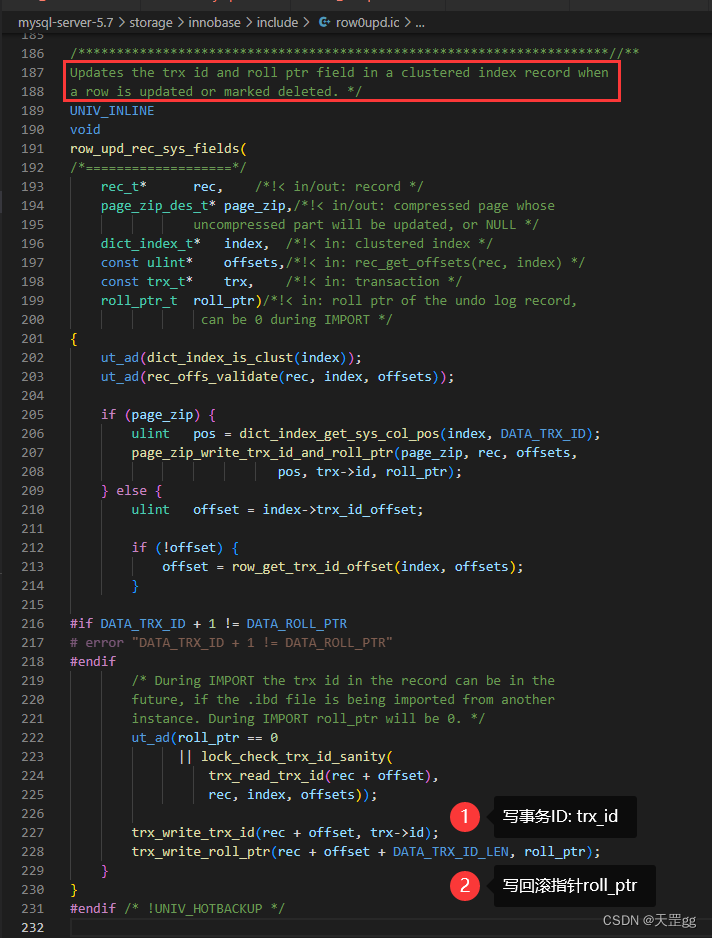
row_upd_rec_sys_fields
Updates the trx id and roll ptr field in a clustered index record when a row is updated or marked deleted.
当行被更新或标记为删除时,更新聚集索引记录中的trx-id和roll-ptr字段。
undo日志版本链演示
为了演示效果, 这里我们采用可重复读(RR)级别来演示, 演示一下undo日志版本链是如何在读写并发时读到不同版本的,
我们采用6个事务:其中1个事务insert, 2个事务update,另外3个事务分别读到3个版本的效果.
执行时间轴从上至下预览(下面有分步的undo log和回滚指针指向说明,readview看不懂先忽略,讲完readview再回头来看,
格式:readview[m_ids], m_low_limit_id 其中m_ids最小的是m_up_limit_id):

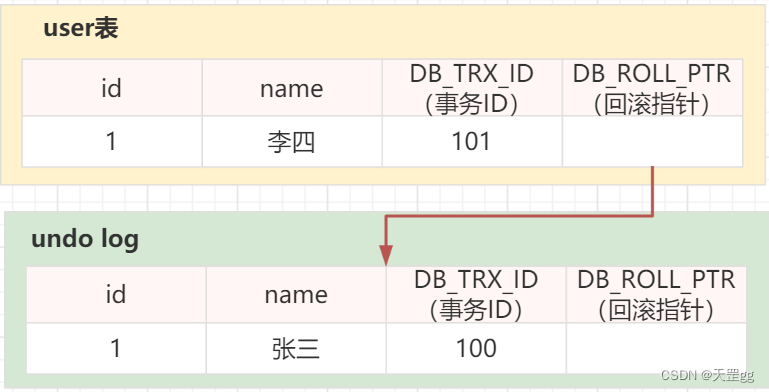
- 事务100 对user表执行 insert + 提交:
说明:这步就是为了构建原始记录
begin;
insert into user(id,name) values(1,'张三');
commit;
- 然后, 事务101 对user表执行 update + 提交:
begin;
update user set name = '李四' where id = 1;
commit;
- 同时, 事务102 在事务101提交前, 查询了该记录:
说明:有事务使用的undo log, purge线程不会清除这条记录
begin;
-- 读到的name为张三
select \* from user where id = 1;
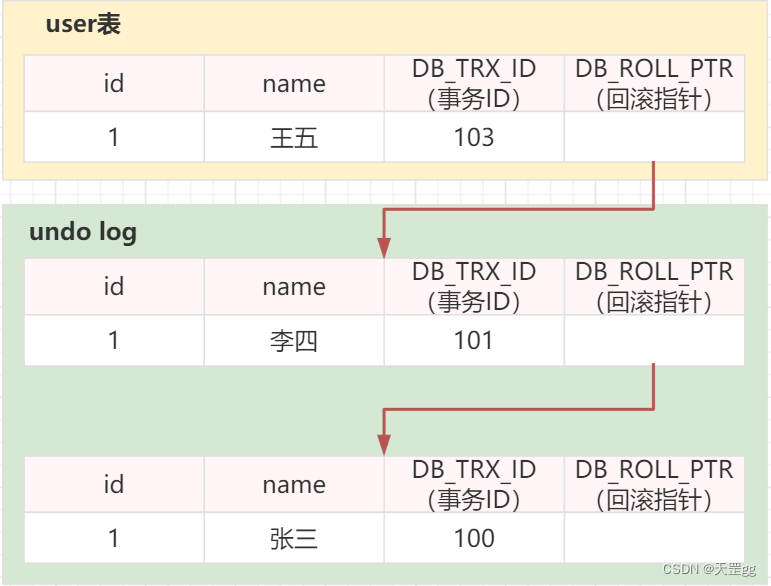
- 同时, 事务103 对user表执行 update 未提交:
begin;
update user set name = '王五' where id = 1;
- 然后, 事务102 再次读取: 在RR级别, 后面所做的更改依然不可见:
begin;
-- 读到的name为张三
select \* from user where id = 1;
-- 读到的name仍为张三
select \* from user where id = 1;
- 同时, 事务104 执行了查询, 读取到了事务101提交的“李四”(因为事务103尚未提交):
begin;
-- 读到的name为李四
select \* from user where id = 1;
commit;
- 然后, 事务103 提交, 事务105来了, 它读取到的却是“王五”. 3个事务看到了3个版本, 版本链就是这样的, 还可能会更多版本…
purge线程
上述提到的 「purge 线程],是一个周期运行的垃圾收集线程, 对于没有事务引用的undo log进行清除, 上面演示里由于都有事务读取, 所以purge线程不会清除. 但当purge线程发现undo log没有事务引用时将自动清除. 另外, 从上面我们得知, 清除的是update undo log, 因为insert undo log在事务完成时直接删除.
- innodb 会将所有需要清理的任务添加到 purge 队列中,可以通过 innodb_max_purge_lag 配置项设定 purge 队列的大小
- 通过show variables like ‘%purge%’ 查看purge参数
本文由 [天罡gg] 首发于csdn,转载请注明出处:https://blog.csdn.net/scm_2008/article/details/127985117
3.3、ReadView
一听到view,大家可能会联想到数据库视图,然后可能会误解为把数据库当前所有表都通过视图快照起来,其实不是,那样的话得多占空间,性能得多差啊。其实生成的ReadView里面主要保存的是用于比较可见性的事务id等。
ReadView保存在事务对象trx_t中

Readview核心字段
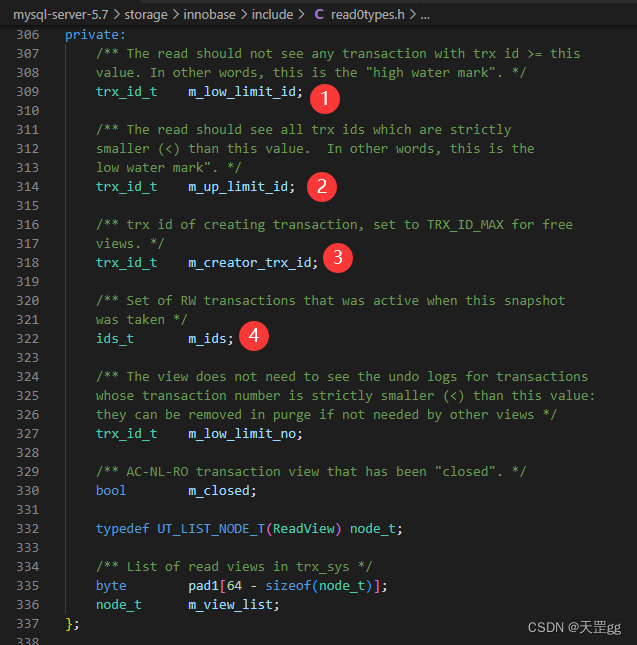
先说结论,下面再来验证
| 字段 | 说明 | 可见性说明 |
|---|---|---|
| m_low_limit_id | 尚未分配的最小事务id | >=它的, 都不可见 |
| m_up_limit_id | 最小活动未提交事务id | <它的, 都可见 |
| m_creator_trx_id | 创建readview的事务id | =它的, 都可见 |
| m_ids | 创建readview所有活动未提交的事务ids | 在m_ids里面不可见,否则可见 |
核心字段在prepare和complete里赋值
最后
总而言之,面试官问来问去,问的那些Redis知识点也就这么多吧,复习的不够到位,知识点掌握不够熟练,所以面试才会卡壳。将这些Redis面试知识解析以及我整理的一些学习笔记分享出来给大家参考学习
还有更多学习笔记面试资料也分享如下:

_id | 创建readview的事务id | =它的, 都可见 |
| m_ids | 创建readview所有活动未提交的事务ids | 在m_ids里面不可见,否则可见 |
核心字段在prepare和complete里赋值
最后
总而言之,面试官问来问去,问的那些Redis知识点也就这么多吧,复习的不够到位,知识点掌握不够熟练,所以面试才会卡壳。将这些Redis面试知识解析以及我整理的一些学习笔记分享出来给大家参考学习
还有更多学习笔记面试资料也分享如下:
[外链图片转存中…(img-ecPjruQe-1714515947153)]















 364
364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









