







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
-
获取一行,写到net_buffer。这块内存的大小是由参数net_buffer_length定义,默认16k
-
重复获取行,直到net_buffer写满,调用网络接口发出去
-
若发送成功,就清空net_buffer,然后继续取下一行,并写入net_buffer
-
若发送函数返回EAGAIN或WSAEWOULDBLOCK,就表示本地网络栈(socket send buffer)写满了,进入等待。直到网络栈重新可写,再继续发送
查询结果发送流程:
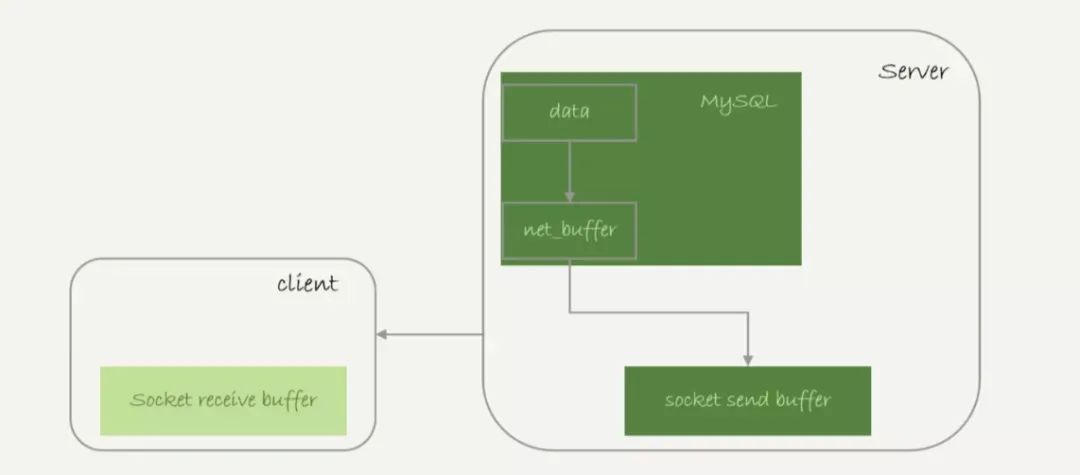
可见:
-
一个查询在发送过程中,占用的MySQL内部的内存最大就是net_buffer_length这么大,不会达到200G
-
socket send buffer 也不可能达到200G(默认定义/proc/sys/net/core/wmem_default),若socket send buffer被写满,就会暂停读数据的流程
所以MySQL其实是“边读边发”。这意味着,若客户端接收得慢,会导致MySQL服务端由于结果发不出去,这个事务的执行时间变长。
比如下面这个状态,就是当客户端不读socket receive buffer内容时,在服务端show processlist看到的结果。
服务端发送阻塞:

若看到State一直是“Sending to client”,说明服务器端的网络栈写满了。
若客户端使用–quick参数,会使用mysql_use_result方法:读一行处理一行。假设某业务的逻辑较复杂,每读一行数据以后要处理的逻辑若很慢,就会导致客户端要过很久才取下一行数据,可能就会出现上图结果。
因此,对于正常的线上业务来说,若一个查询的返回结果不多,推荐使用mysql_store_result接口,直接把查询结果保存到本地内存。
当然前提是查询返回结果不多。如果太多,因为执行了一个大查询导致客户端占用内存近20G,这种情况下就需要改用mysql_use_result接口。
若你在自己负责维护的MySQL里看到很多个线程都处于“Sending to client”,表明你要让业务开发同学优化查询结果,并评估这么多的返回结果是否合理。
若要快速减少处于这个状态的线程的话,可以将net_buffer_length设置更大。
有时,实例上看到很多查询语句状态是“Sending data”,但查看网络也没什么问题,为什么Sending data要这么久?
一个查询语句的状态变化是这样的:
-
MySQL查询语句进入执行阶段后,先把状态设置成 Sending data
-
然后,发送执行结果的列相关的信息(meta data) 给客户端
-
再继续执行语句的流程
-
执行完成后,把状态设置成空字符串
即“Sending data”并不一定是指“正在发送数据”,而可能是处于执行器过程中的任意阶段。比如,你可以构造一个锁等待场景,就能看到Sending data状态。
读全表被锁:
| session 1 | session2 |
| begin select * from t where id=1 for update | 启动事务 |
| select * from t lock in share mode (blocked) |
Sending data状态

可见session2是在等锁,状态显示为Sending data。
-
仅当一个线程处于“等待客户端接收结果”的状态,才会显示"Sending to client"
-
若显示成“Sending data”,它的意思只是“正在执行”
所以,查询的结果是分段发给客户端,因此扫描全表,查询返回大量数据,并不会把内存打爆。
以上是server层的处理逻辑,在InnoDB引擎里又是怎么处理?
2、全表扫描对InnoDB的影响
InnoDB内存的一个作用,是保存更新的结果,再配合redo log,避免随机写盘。
内存的数据页是在Buffer Pool (简称为BP)管理,在WAL里BP起加速更新的作用。
BP还能加速查询。
由于WAL,当事务提交时,磁盘上的数据页是旧的,若这时马上有个查询来读该数据页,是不是要马上把redo log应用到数据页?
不需要。因为此时,内存数据页的结果是最新的,直接读内存页即可。这时查询无需读磁盘,直接从内存取结果,速度很快。所以,Buffer Pool能加速查询。
而BP对查询的加速效果,依赖于一个重要的指标,即:内存命中率。
可以在show engine innodb status结果中,查看一个系统当前的BP命中率。一般情况下,一个稳定服务的线上系统,要保证响应时间符合要求的话,内存命中率要在99%以上。
执行show engine innodb status ,可以看到“Buffer pool hit rate”字样,显示的就是当前的命中率。比如下图命中率,就是100%。

若所有查询需要的数据页都能够直接从内存得到,那是最好的,对应命中率100%。
InnoDB Buffer Pool的大小是由参数 innodb_buffer_pool_size确定,一般建议设置成可用物理内存的60%~80%。
在大约十年前,单机的数据量是上百个G,而物理内存是几个G;现在虽然很多服务器都能有128G甚至更高的内存,但是单机的数据量却达到了T级别。
所以,innodb_buffer_pool_size小于磁盘数据量很常见。若一个 Buffer Pool满了,而又要从磁盘读入一个数据页,那肯定是要淘汰一个旧数据页的。
3、InnoDB内存管理
使用的最近最少使用 (Least Recently Used, LRU)算法,淘汰最久未使用数据。
基本LRU算法
InnoDB管理BP的LRU算法,是用链表实现的:
-
state1,链表头部是P1,表示P1是最近刚被访问过的数据页
-
此时,一个读请求访问P3,因此变成状态2,P3被移到最前
最后
终极手撕架构师的学习笔记:分布式+微服务+开源框架+性能优化

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
18)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-WuI34c1h-1713383609418)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









