







对爬虫爬取数据时的分页进行一下总结。分页是爬取到所有数据的关键,一般有这样几种形式:
1、已知记录数,分页大小(pagesize, 一页有多少条记录)
-
已知总页数(在页面上显示出总页数)
-
页面上没有总记录数,总页数,但能从分页条中找到总页数
-
滚动分页,知道总页数
-
滚动分页,不知道总页数
以上前三种情况比较简单,基本上看一下加载分页数据时的地址栏,或者稍微用Chrome – network分析一下,就可以了解分页的URL。
一、页面分析,获取分页URL
典型的如豆瓣图书、电影排行榜的分页。
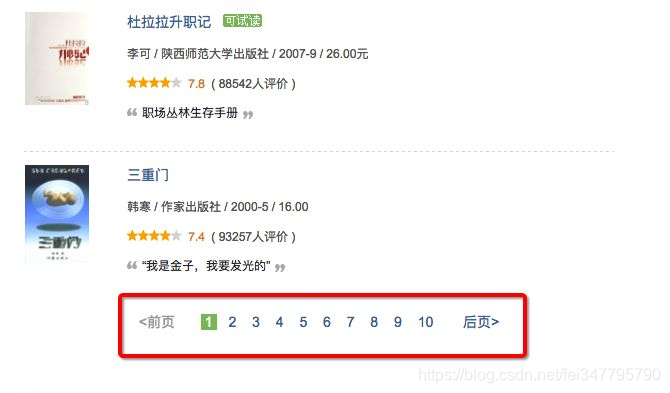
对于像以下这种分页,没有显示总记录数,但从分页条上看到有多少页的,一般的处理方法有两种:一是先把最后一页的页码抓取下来;二是一页一页的访问抓取,直到没有“下一页”。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2990
2990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









