







题目
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding
Pre-training:在一个数据集上训练好一个模型,这个模型主要的任务是用在一个别的任务上面,如果这个别的任务叫做training,那么在大的数据集上训练这个任务就叫做Pre-training
Bidirectional:双向的
深的双向的transformer模型,用来做与训练的,针对的是一般的语言理解任务
摘要
BERT即Bidirectional Encoder Representations from Transformers。与ELMo和GPT不同,BERT是用来设计去训练深的双向的表示,使用没有标号的数据,联合上下文的信息。因为BERT模型的设计,使得可以只用加一个额外的一个输出层,在许多NLP的任务上就可以得到一个不错的结果,包括问答,语言推理等。(第一段)
补充:GPT其实是单向的结构,使用左边的信息来预测未来,而BERT是使用了左侧和右侧的信息,是一个双向的
ELMo使用的是RNN,而BERT使用的是transformer,EMLo在用到一些下游的任务的时候,需要对架构做一点点调整,而对于BERT而言只需要改最上层即可
BERT的好处:模型在概念上更简单,在实验上更好(第二段)
写法:当说东西比较好的时候,要有两点要说清楚,第一点是绝对精度是多少,第二点是跟别人比相对的好处是多少
导言
导言的第一段一般是说论文研究方向的一些上下文关系
预训练可以用来提升很多自然语言的任务,这些自然语言任务里面包括两类,第一类是句子层面的任务,主要用来建模这些句子之间的关系,如对句子情绪的识别或者两个句子之间的关系;第二类是词源层面的任务,包括一些实体命名的识别,如对一个词识别是不是一个实体命名,比如是不是一个人名,一个街道名等
导言的第二段一般是摘要的扩充版本
在使用预训练模型做特征表示的时候,一般有两类策略,一类是feature-based(基于特征的)和fine-tuning(基于微调的),基于特征的代表是ELMo,对每一个下游的任务,构造一个跟这个任务相关的神经网络,使用的是RNN架构,将预训练好的表示,作为一个额外的特征和输入是一起输入到这个模型里面的(即将学到的特征和输入一起放进模型中,作为一个很好的特征的表达);基于微调的代表是GPT,把预训练好的模型放到下游任务的时候不需要修改太多,预训练好的参数权重会根据新的数据集进行微调一下。
这两种方式在预训练的时候使用的都是相同的目标函数,使用的都是单向的语言模型
导言第三段(主要的想法)
现在的技术会有局限性,主要问题是标准的语言模型是单向的,比如说GPT使用的是一个从左到右的架构。如果将两个方向的信息都融合之后,应该可以提升语言处理任务方面的性能的
怎样解决?
BERT用来解决语言模型是单向的一些限制,用到的是带掩码的language model(masked language model MLM),MLM是受Cloze的启发,MLM就是每一次随机的选一些字然后将它盖住,然后目标函数是用来预测被盖住的那些字,就等价于完形填空。MLM允许看左右的信息,训练一个深的双向的transformer模型。除了这个任务,还有一个"next sentence prediction"的任务,核心思想是给两个句子,判断这两个句子在原文里面是不是相邻的
贡献
1、双向信息的重要性
2、一个比较好的预训练任务就不需要对特定的任务做特定的改动
3、代码和模型
结论
使用非监督的预训练是比较好的,使得资源不多的任务也能够享受深度神经网络,主要工序就是把前人的结果拓展到深的双向的架构上面,使得同样的一个预训练模型,能够处理大量的不同的自然语言任务。
相关工作
非监督的基于特征的工作(第一段)
非监督的基于微调的工作(第二段)
在有标号的数据(大量的数据)上做迁移学习,在有标号的数据上训练好模型然后在别的任务上使用,在视觉方面的使用较多,在ImageNet上训练好模型,然后在别的任务上使用。但是在NLP结果不是很理想
BERT及一系列的工作证明,使用没有标号的大量的数据集训练成模型比有标号相对来说小点的数据上训练模型效果更好
BERT
Bert中由两个步骤,一个是预训练(pre-training),一个是微调(fine-tuning).
pre-training是在一个没有标号的数据上训练的,在微调的时候使用一个Bert模型,权重初始化为在预训练上的权重,所有的权重在微调的时候都会参与训练,使用的是有标号的数据,每一个下游的任务都会创建一个Bert模型,使用预训练好的模型作为初始化,但是下游任务会根据自己的数据训练自己的模型。
补充:在写论文的时候,用到的技术要做一个简短的说明
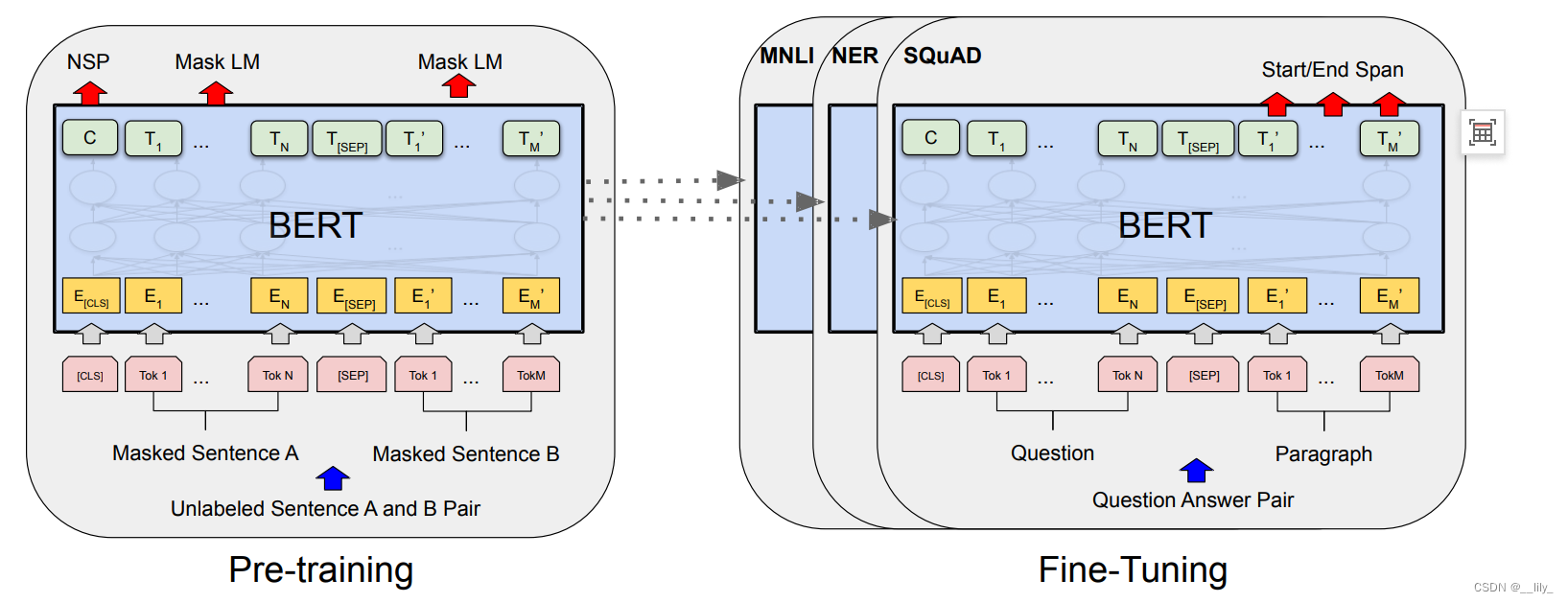
模型架构
Bert的架构其实就是一个多层双向的transformer的编码器,基于原始的论文和代码没有太大的改动。
L:transformer blocks
H:隐藏层的大小 (embedding 的维度,一个token用768维的向量表示)
A:自注意力机制多头中头的个数
BERT base(L=12,H=768,A=12 total parameters=110M),BERT large(24,1024,16,340M)
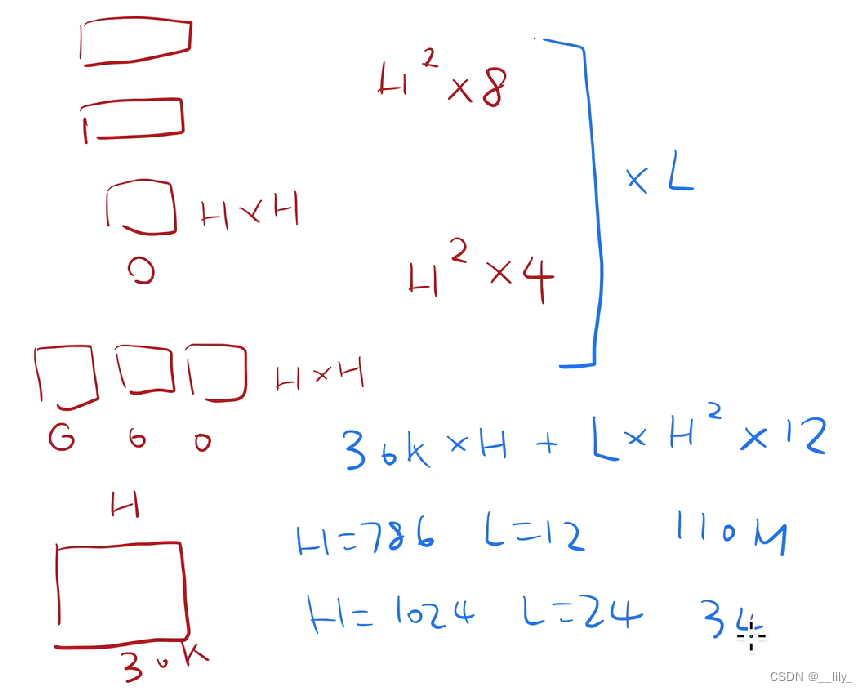
H=768(上图李沐老师手误)
输入和输出
对于一些下游任务,有些任务是处理一个句子,有些任务是处理两个句子,为了使Bert能够处理这些任务,输入既可以是一个句子,也可以是一个句子对。
Bert的输入是一个sequence,这个sequence可以是一个句子也可以是两个句子。对于transformer的输入是一个序列对,encoder和decoder分别会输入一个序列,而对于Bert只有encoder,所以会将两个序列合成为一个序列
序列的构成:使用的方法是WordPiece embeddings,如果一个词出现的概率不大的话,应该切开看子序列,如果子序列出现的概率比较大,那么看这个子序列即可,这样可以把一个相对来说比较长的词切成一个个片段。
怎样把两个句子放在一起?
序列的第一个词永远是一个特殊的记号——[CLS],作用是输出代表整个序列的信息,整个句子层面的信息,因为使用的是transformer的架构,会去看句子里所有词的信息,所以[CLS]位于第一位也可以看到所有的信息。
区分两个句子:一是在每个句子的后面放一个特殊的词——[SEP],第二是学习一个嵌入层,表示这是第一个句子还是第二个句子

Token Embedding 词源的embedding
Segment Embedings 第一句话还是第二句话
Positon Embeddings 输入是每个词源的位置信息,对应的向量表示是通过学习得来的
Pre-training BERT
”完形填空“
对于一个输入的词源序列,如果是由WordPiece生成的话,会有15%的概率随机替换成掩码[mask],除去特殊的词源。
在预训练的时候,会看到这个mask,在微调的时候不用这个目标函数,就没有这个mask,那么在微调和预训练的时候看到的数据会有不同。解决方法:对这15%的掩码的词中,80%被替换成[MASK],10%不变(微调的时候真实看到的数据),10%随机替换为其它的词(加入噪音)

预测下一个句子(Next Sentence Prediction NSP)
在处理Q&A和语言推理方面,学习句子层面的信息,输入序列里有两个句子,有50%概率B句子就是在A句子之后(IsNext),还有50%的概率B是随机选出的(NotNext)

训练的数据集
是一篇篇的文章,而不是随机打乱的句子
Fine-tuning BERT
在做下游任务的时候,根据特定的任务设计问题的输入和输出,模型其实不怎么需要变,主要是怎么把输入改成我想要的句子对
实验
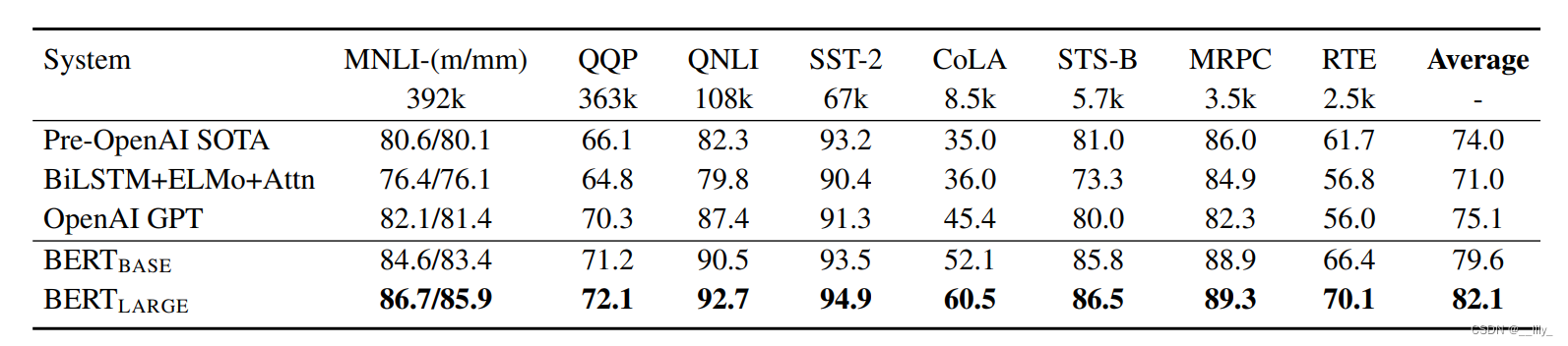















 701
701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









