







class FiveSpider(scrapy.Spider):
name = “five”
start_urls = [“https://news.163.com/”]
# 储存导航栏模块的url
model_urls=[]
# 初始化浏览器对象
def __init__(self):
# 初始化浏览器
s = Service("D:\Program Files (x86)\chrome\chromedriver.exe")
self.bro = webdriver.Chrome(service=s)
#### 1.1 setting.py基本设置
在setting.py 关闭ROBOTSTXT\_OBEY和日志信息,填写USER\_AGENTH和日志信息
ROBOTSTXT_OBEY = False
LOG_LEVEL=‘ERROR’
USER_AGENT=“Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0”
### 2.定位爬取导航栏模块的URL
建立一个model\_urls来储存爬取的url,通过F12和xpath定位到模块的标签,在循环通过request对模块发起请求
def parse(self, response):
# 定位导航栏各个模块的url
li_list=response.xpath('//*[@id="index2016_wrap"]/div[3]/div[2]/div[2]/div[2]/div/ul/li')
# 将需要爬取的导航栏模块的下标储存在列表中
alist=[1,2]
for index in alist:
model_url=li_list[index].xpath('./a/@href').extract_first()
self.model_urls.append(model_url)
# 向爬取的url发起请求,并回调到parse_model()方法中
for url in self.model_urls:
yield scrapy.Request(url=url,callback=self.parse_model)
### 3.获取新闻URL和标题
首先通过F12发现标题和响应详情页内容URL结构层次,都在一个DIV标签内,然后便通过xpath定位,并将其储存到item对象中
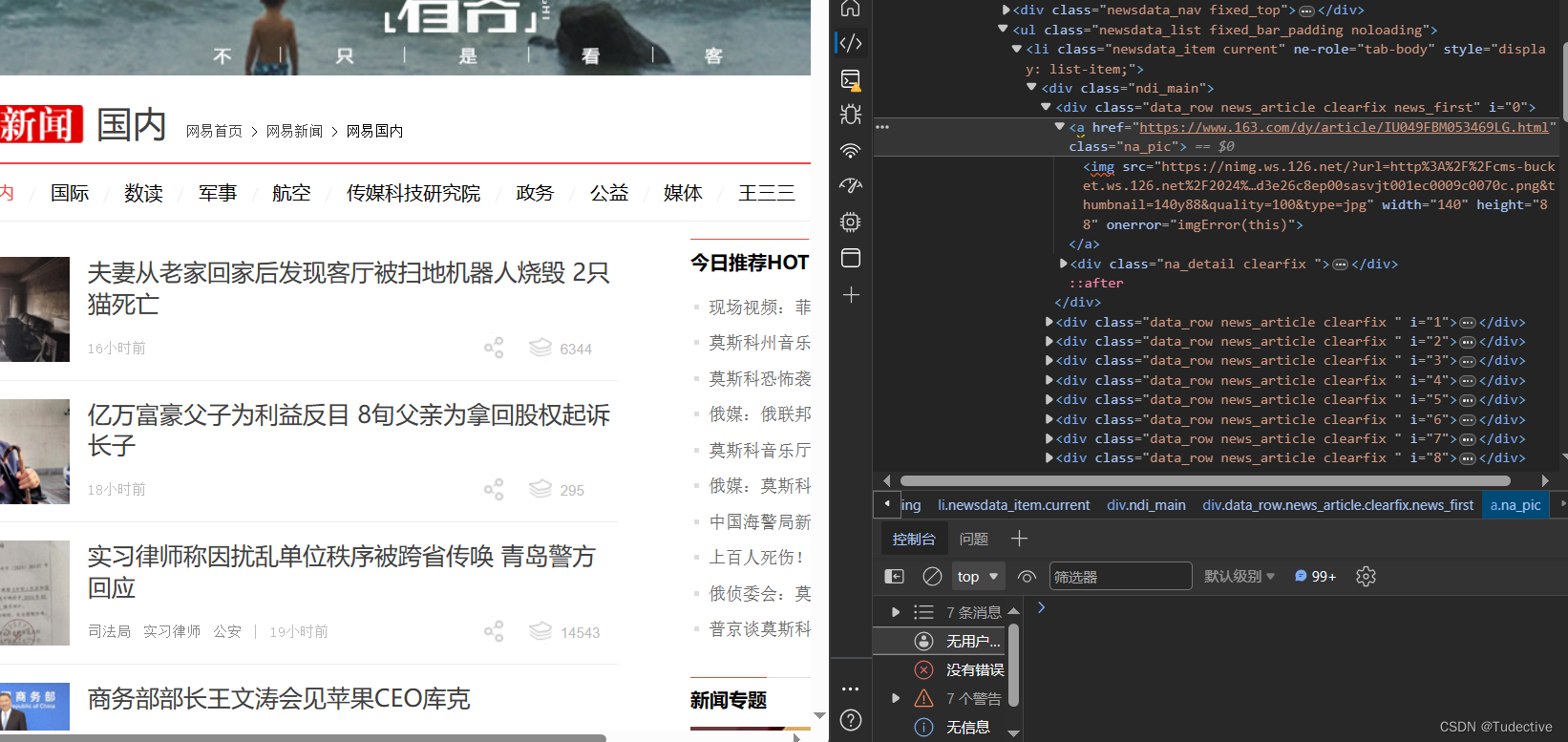
item对象中所存储的值
import scrapy
class FivebloodItem(scrapy.Item):
# define the fields for your item here like:
# 设置item中储存的response的内容
title = scrapy.Field()
content = scrapy.Field()
# pass
然后就要将item数据传递到详情页中去
解析每个版面中新闻的内容和标题
def parse_model(self,response):
div_list=response.xpath('/html/body/div/div[3]/div[3]/div[1]/div[1]/div/ul/li/div/div')
for div in div_list:
title=div.xpath('.//h3/a/text()').extract_first()
new_detail_url=div.xpath('./a/@href').extract_first()
# 创建item对象,将数据解析到item中去
item=FivebloodItem()
item['title']=title
# 通过meta参数,把item这个字典只给‘key’,将parse_model的response传递给parse_detail中去
yield scrapy.Request(url=new_detail_url,callback=self.parse_detail,meta={'item':item})
### 4.获取详情页的内容
这里注意一下extract()和extract\_first()的区别,由于内容里边可能第一个列表不会包含全部的内容,所以使用extract()返回内容列表
解析新闻内容
def parse_detail(self, response):
# extract():这个方法返回的是一个数组list,,里面包含了多个string,如果只有一个string,则返回['ABC']这样的形式。
# extract_first():这个方法返回的是一个string字符串,是list数组里面的第一个字符串。
content=response.xpath('//*[@id="content"]/div[2]//text()').extract()
# 将列表内容转换为字符串
content=" ".join(content)
# 消除里边的空格和换行符
content=content.replace('\n', '').replace('\r', '')
# 储存到item中去
item=response.meta['item']
item['content']=content
# 最终将所有response存储到item中,由item提交到管道类中去
yield item
在详情页网址中的去F12定位到内容的标签地址
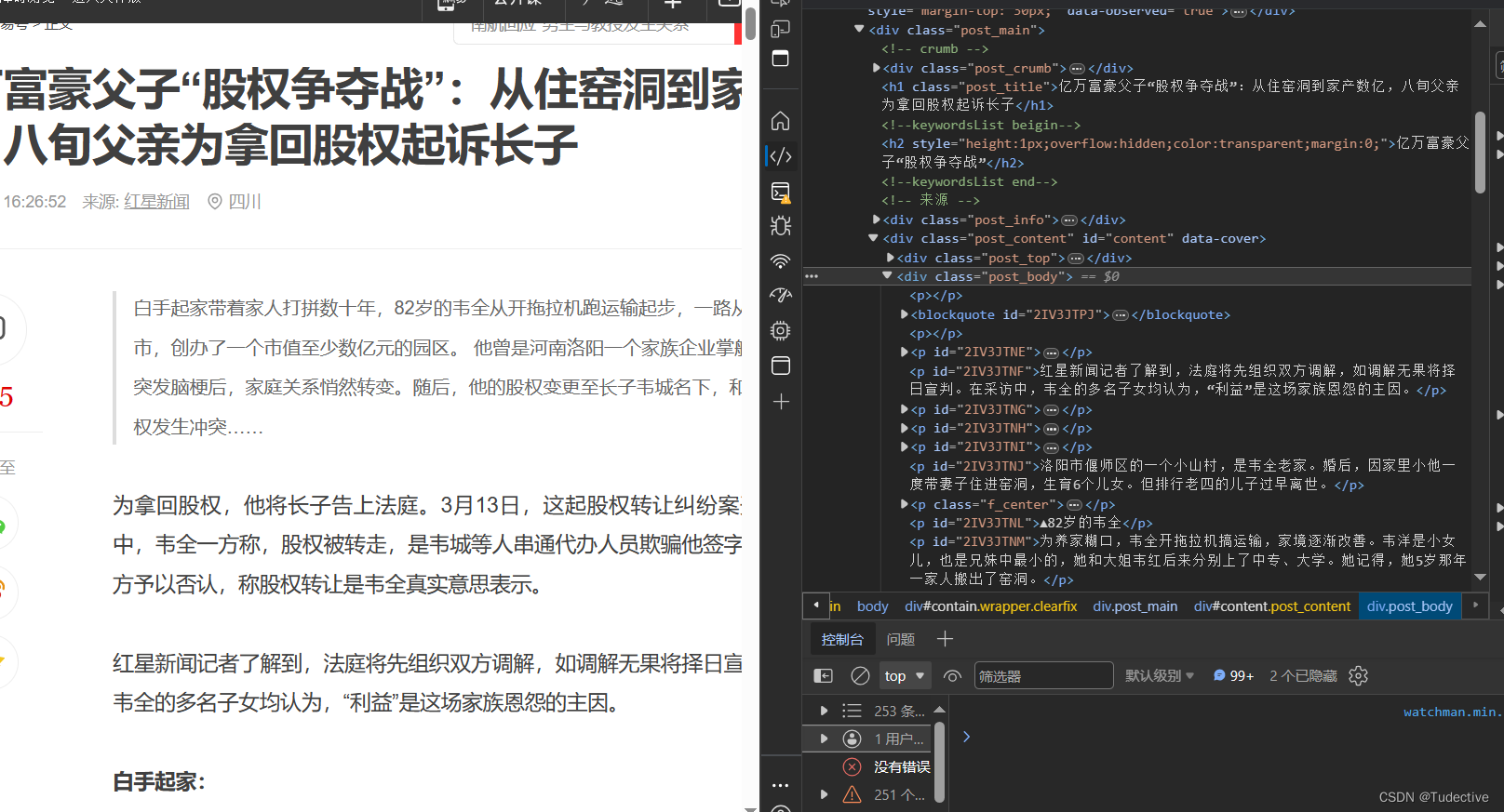
然后关闭一下开始创建的浏览器对象
关闭浏览器对象
def closed(self,spider):
self.bro.quit()
### 5.在中间件中拦截响应
详情页的内容可能是动态数据,可以对发起的请求进行拦截,scrapy有五大核心模块,想要了解可以去看看
[https://blog.csdn.net/Tudective/article/details/136952793?spm=1001.2014.3001.5502]( )
from scrapy import signals
useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
from time import sleep
import random
from scrapy.http import HtmlResponse
class FivebloodDownloaderMiddleware:
# 拦截请求
def process_request(self, request, spider):
return None
# 拦截响应
def process_response(self, request, response, spider):
# 获取在five文件中创建的爬虫类中的浏览器对象
bro=spider.bro
# 挑选出指定的响应对象进行更改,即各个模块的url
if request.url in spider.model_urls:
bro.get(request.url)
# 浏览器停留等待防止,防止加载过快,未解析到数据
sleep(5)
# 包含动态数据
page_text=bro.page_source
# HtmlResponse作为Response构造方法,能够对HTML内容进行解析
new_response=HtmlResponse(url=request.url,body=page_text,encoding='utf-8',request=request)
return new_response
else:
return response
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注:Python)
a67243c1008edf79.png)
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注:Python)
















 1864
1864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









