







name VARCHAR(20),
birthday DATE
);
查看表
1. 查看某个数据库中的所有表
SHOW TABLES;
2. 查看表结构
DESC 表名;
3. 查看创建表的SQL语句
SHOW CREATE TABLE 表名;
具体操作:
查看mysql数据库中的所有表
SHOW TABLES;

查看student表的结构
DESC student;

查看student的创建表SQL语句
SHOW CREATE TABLE student;

快速创建一个表结构相同的表
CREATE TABLE 新表名 LIKE 旧表名;
具体操作:
创建s1表,s1表结构和student表结构相同
CREATE TABLE S1 LIKE STUDENT;

删除表
1. 直接删除表 DROP TABLE 表名;
2. 判断表是否存在并删除表(了解) DROP TABLE IF EXISTS 表名;
具体操作:
直接删除表s1表
DROP TABLE s1;

判断表是否存在并删除s1表
DROP TABLE IF EXISTS s1;

修改表结构
修改表结构使用不是很频繁,只需要知道下,等需要使用的时候再回来查即可
1. 添加表列 ALTER TABLE 表名 ADD 列名 类型;
具体操作:
为学生表添加一个新的字段remark,类型为varchar(20)
ALTER TABLE student ADD remark VARCHAR(20);

2. 修改列类型 ALTER TABLE 表名 MODIFY 列名 新的类型;
具体操作:将student表中的remark字段的改成varchar(100)
ALTER TABLE student MODIFY remark VARCHAR(100);

3. 修改列名 ALTER TABLE 表名 CHANGE 旧列名 新列名 类型;
具体操作:将student表中的remark字段名改成intro,类型varchar(30)
ALTER TABLE student CHANGE remark intro varchar(30);

4. 删除列 ALTER TABLE 表名 DROP 列名;
具体操作:删除student表中的字段intro
ALTER TABLE student DROP intro;

5. 修改表名 RENAME TABLE 表名 TO 新表名;
具体操作:将学生表student改名成student2
RENAME TABLE student TO student2;

6. 修改字符集 ALTER TABLE 表名 character set 字符集;
具体操作:将sutden2表的编码修改成gbk
ALTER TABLE student2 character set gbk;

3.4 DML语句
3.4.1插入记录
插入全部字段
插入全部字段
所有的字段名都写出来
INSERT INTO 表名 (字段名1, 字段名2, 字段名3…) VALUES (值1, 值2, 值3);
不写字段名 INSERT INTO 表名 VALUES (值1, 值2, 值3…);
插入部分字段
插入部分数据
INSERT INTO 表名 (字段名1, 字段名2, …) VALUES (值1, 值2, …); 没有添加数据的字段会使用NULL
1. 关键字说明
INSERT INTO 表名 – 表示往哪张表中添加数据(字段名1, 字段名2, …) ‐‐ 要给哪些字段设置值VALUES (值1, 值2, …); ‐‐ 设置具体的值
2. 注意
值与字段必须对应,个数相同,
类型相同值的数据大小必须在字段的长度范围内
除了数值类型外,其它的字段类型的值必须使用引号引起。(建议单引号)
如果要插入空值,可以不写字段,或者插入null
3. 具体操作:插入部分数据,往学生表中添加 id, name, age, sex数据
INSERT INTO student (id, NAME, age, sex) VALUES (1, ‘张三’, 20, ‘男’);

向表中插入所有字段
所有的字段名都写出来
INSERT INTO student (NAME, id, age, sex, address) VALUES (‘李四’, 2, 23, ‘女’, ‘广州’);

不写字段名
INSERT INTO student VALUES (3, ‘王五’, 18, ‘男’, ‘北京’);

DOS命令窗口操数据库乱码
当我们使用DOS命令行进行SQL语句操作如有有中文会出现乱码,导致SQL执行失败

错误原因:因为MySQL的客户端设置编码是utf8,而系统的DOS命令行编码是gbk,编码不一致导致的乱码

查看 MySQL 内部设置的编码 show variables like ‘character%’;

解决方案:修改client、connection、results的编码为GBK,保证和DOS命令行编码保持一致
1. 单独设置
set character_set_client=gbk;
set character_set_connection=gbk;
set character_set_results=gbk;
2. 快捷设置
set names gbk;
注意:以上2种方式为临时方案,退出DOS命令行就失效了,需要每次都配置
3. 修改MySQL安装目录下的my.ini文件,重启服务所有地方生效。此方案将所有编码都修改了

蠕虫复制
什么是蠕虫复制:在已有的数据基础之上,将原来的数据进行复制,插入到对应的表中 语法格式:INSERT INTO表名1 SELECT * FROM 表名2; 作用:将表名2中的数据复制到表名1中set character_set_client=gbk; set character_set_connection=gbk;set character_set_results=gbk;set names gbk;
具体操作:创建student2表,student2结构和student表结构一样
CREATE TABLE student2 LIKE student;
将student表中的数据添加到student2表中
INSERT INTO student2 SELECT * FROM student;
注意:如果只想复制student表中name,age字段数据到student2表中使用如下格式 INSERT INTOstudent2(NAME, age) SELECT NAME, age FROM student;

3.4.2更新表记录
1. 不带条件修改数据 UPDATE 表名 SET 字段名=值;
2. 带条件修改数据 UPDATE 表名 SET 字段名=值 WHERE 字段名=值;
3. 关键字说明
UPDATE: 修改数据
SET: 修改哪些字段
WHERE: 指定条件
4. 具体操作:
不带条件修改数据,将所有的性别改成女
UPDATE student SET sex=‘女’;

带条件修改数据,将id号为2的学生性别改成男
UPDATE student SET sex=‘男’ WHERE id=2;

一次修改多个列,把id为3的学生,年龄改成26岁,address改成北京
UPDATE student SET age=26, address=‘北京’ WHERE id=3;

3.4.3删除表记录
1. 不带条件删除数据 DELETE FROM 表名;
2. 带条件删除数据 DELETE FROM 表名 WHERE 字段名=值;
3. truncate删除表记录 TRUNCATE TABLE 表名;
truncate和delete的区别:
delete是将表中的数据一条一条删除
truncate是将整个表摧毁,重新创建一个新的表,新的表结构和原来表结构一模一样

4. 具体操作:
带条件删除数据,删除id为3的记录
DELETE FROM student WHERE id=3;

不带条件删除数据,删除表中的所有数据
DELETE FROM student;

3.5DQL
查询不会对数据库中的数据进行修改.只是一种显示数据的方式 准备数据
CREATE TABLE student3 (
id int, name varchar(20),
age int, sex varchar(5),
address varchar(100),
math int, english int
);
INSERT INTO student3(id,NAME,age,sex,address,math,english) VALUES (1,‘马云’,55,‘男’,‘杭州’,66,78),(2,‘马化腾’,45,‘女’,‘深圳’,98,87),(3,‘马景涛’,55,‘男’,‘香港’,56,77),(4,‘柳岩’,20,‘女’,‘湖南’,76,65),(5,‘柳青’,20,‘男’,‘湖南’,86,NULL),(6,‘刘德华’,57,‘男’,‘香港’,99,99),(7,‘马德’,22,‘女’,‘香港’,99,99),(8,‘德玛西亚’,18,‘男’,‘南京’,56,65);
3.5.1简单查询
查询表所有数据
1. 使用*表示所有列 SELECT * FROM 表名; 具体操作:
SELECT * FROM student3;

2. 写出查询每列的名称 SELECT 字段名1, 字段名2, 字段名3, … FROM 表名; 具体操作:
SELECT id, NAME ,age, sex, address, math, english FROM student3;

查询指定列
查询指定列的数据,多个列之间以逗号分隔 SELECT 字段名1, 字段名2… FROM 表名;
具体操作: 查询student3表中的id , name , age , sex , address 列
SELECT id, NAME ,age, sex, address FROM student3;

别名查询
1. 查询时给列、表指定别名需要使用AS关键字
2. 使用别名的好处是方便观看和处理查询到的数据 SELECT 字段名1 AS 别名, 字段名2 AS 别名… FROM 表名;
SELECT 字段名1 AS 别名, 字段名2 AS 别名… FROM 表名 AS 表别名;
注意:
查询给表取别名目前还看不到效果,需要到多表查询的时候才能体现出好处 AS关键字可以省略
3. 具体操作:查询sudent3表中name 和 age 列,name列的别名为”姓名”,age列的别名为”年龄”
SELECT NAME AS 姓名,age 年龄 FROM student3;

查询sudent3表中name和age列,student3表别名为s
SELECT NAME, age FROM student3 AS s;

查询给表取别名目前还看不到效果,需要到多表查询的时候才能体现出好处
清除重复值
为了演示重复值,我们再插入一条记录,
INSERT INTO student3 (id,NAME,age) VALUES(9,‘马云’,12);
1. 查询指定列并且结果不出现重复数据 SELECT DISTINCT 字段名 FROM 表名;
2. 具体操作:
查询name列并且结果不出现重复name

查询name,age列并且结果不出现重复name和age
SELECT DISTINCT NAME, age FROM student3;

测试完成之后 , 把刚刚插入的记录删除DELETE FROM student3 WHERE id = 9;
查询结果参与运算
1. 某列数据和固定值运算 SELECT 列名1 + 固定值 FROM 表名;
2. 某列数据和其他列数据参与运算 SELECT 列名1 + 列名2 FROM 表名;
注意: 参与运算的必须是数值类型
3. 具体例子:查询每个人的总成绩
SELECT NAME, math + english FROM student3;

结果确实将每条记录的math和english相加,有两个小问题
1.效果不好看
2.柳青的成绩为null我们来把这两个问题解决下
查询math + english的和使用别名”总成绩”
SELECT NAME, math + english 总成绩 FROM student3;

null值处理
注意 : null参与算术运算结果还是null.
ifnull(表达式1,表达式2) : 若表达式1的值为null,则返回表达式2的结果;若表达式1的值不为null,则返回表达式1的值因为english一列中有null值 , 我们可以使用ifnull解决 , 写法ifnull(english,0), 意思为若english值为null , 按0处理 ; 否则还是使用原来english的值.
SELECT NAME, math + IFNULL(english,0) 总成绩 FROM student3;
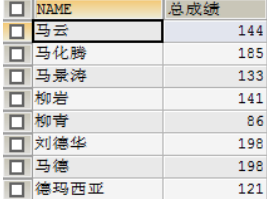
查询所有列与math + english的和并使用别名”总成绩”
SELECT *, math + IFNULL(english,0) 总成绩 FROM student3;

查询姓名、年龄,将每个人的年龄增加10岁
SELECT NAME, age + 10 FROM student3;

第四章 DQL语句
=========
4.1条件查询
4.1.1 比较运算符
>大于 <小于 <=小于等于 >=大于等于 =等于 <>、!=不等于
具体操作:查询math分数大于80分的学生
SELECT * FROM student3 WHERE math>80;

查询english分数小于或等于80分的学生
SELECT * FROM student3 WHERE english<=80;

查询age等于20岁的学生
SELECT * FROM student3 WHERE age=20;

查询age不等于20岁的学生
SELECT * FROM student3 WHERE age!=20;
SELECT * FROM student3 WHERE age<>20;

4.1.2 逻辑运算符
and(&&) 多个条件同时满足 or(||) 多个条件其中一个满足 not(!) 不满足
具体操作:查询age大于35且性别为男的学生(两个条件同时满足)
SELECT * FROM student3 WHERE age>35 AND sex=‘男’;

查询age大于35或性别为男的学生(两个条件其中一个满足)
SELECT * FROM student333 WHERE age>35 OR sex=‘男’;

查询id是1或3或5的学生
SELECT * FROM student3 WHERE id=1 OR id=3 OR id=5;

in关键字 语法格式:SELECT 字段名 FROM 表名 WHERE 字段 in (数据1, 数据2…); in里面的每个数据都会作为一次条件,只要满足条件的就会显示
具体操作:查询id是1或3或5的学生
SELECT * FROM student3 WHERE id IN (1,3,5);
查询id不是1或3或5的学生
SELECT * FROM student3 WHERE id NOT IN (1,3,5);

4.1.3 范围
BETWEEN 值1 AND 值2 表示从值1到值2范围,包头又包尾 比如:age BETWEEN 80 AND 100 相当于: age>=80 &&age<=100
具体操作:查询english成绩大于等于75,且小于等于90的学生
SELECT * FROM student3 WHERE english>=75 AND english<=90;
SELECT * FROM student3 WHERE english BETWEEN 75 AND 90;

4.1.4 like
LIKE表示模糊查询 SELECT * FROM 表名 WHERE 字段名 LIKE ‘通配符字符串’; 满足通配符字符串规则的数据就会显示出来 所谓的通配符字符串就是含有通配符的字符串 MySQL通配符有两个: %: 表示0个或多个字符(任意个字符) _: 表示一个字符
具体操作:查询姓马的学生
SELECT * FROM student3 WHERE NAME LIKE ‘马%’;

查询姓名中包含’德’字的学生
SELECT * FROM student3 WHERE NAME LIKE ‘%德%’;
查询姓马,且姓名有三个字的学生
SELECT * FROM student3 WHERE NAME LIKE ‘马__’;

4.2排序
通过ORDER BY子句,可以将查询出的结果进行排序(排序只是显示方式,不会影响数据库中数据的顺序) SELECT字段名 FROM 表名 WHERE 字段=值 ORDER BY 字段名 [ASC|DESC]; ASC: 升序, 默认是升序 DESC: 降序
4.2.1单列排序
单列排序就是使用一个字段排序
具体操作:查询所有数据,使用年龄降序排序
SELECT * FROM student3 ORDER BY age DESC;

4.2.2组合排序
组合排序就是先按第一个字段进行排序,如果第一个字段相同,才按第二个字段进行排序,依次类推。 上面的例子中,年龄是有相同的。当年龄相同再使用math进行排序 SELECT 字段名 FROM 表名 WHERE 字段=值 ORDER BY 字段名1 [ASC|DESC], 字段名2 [ASC|DESC];
具体操作:查询所有数据,在年龄降序排序的基础上,如果年龄相同再以数学成绩降序排序
SELECT * FROM student3 ORDER BY age DESC, math DESC;

4.3 聚合函数
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个结果值。另外聚合函数会忽略空值
五个聚合函数: count: 统计指定列记录数,记录为NULL的不统计 sum: 计算指定列的数值和,如果不是数值类型,那么计算结果为0 max: 计算指定列的最大值 min: 计算指定列的最小值 avg: 计算指定列的平均值,如果不是数值类型,那么计算结果为0
聚合函数的使用:写在 SQL语句SELECT后 字段名的地方 SELECT 字段名… FROM 表名; SELECT COUNT(age)FROM 表名;
具体操作:查询学生总数
SELECT COUNT(english) FROM student3;

我们发现对于NULL的记录不会统计

我们可以利用IFNULL()函数,如果记录为NULL,给个默认值,这样统计的数据就不会遗漏
ELECT COUNT(IFNULL(english,0)) FROM student3;

SELECT COUNT(*) FROM student3;

查询年龄大于40的总数
SELECT COUNT(*) FROM student3 WHERE age>40;

查询数学成绩总分
SELECT SUM(math) FROM student3;

查询数学成绩平均分
SELECT AVG(math) FROM student3;

查询数学成绩最高分
SELECT MAX(math) FROM student3;

查询数学成绩最低分
SELECT MIN(math) FROM student3;

4.4 分组
分组查询是指使用 GROUP BY语句对查询信息进行分组,相同数据作为一组 SELECT 字段1,字段2… FROM 表名GROUP BY 分组字段 [HAVING 条件];GROUP BY怎么分组的?将分组字段结果中相同内容作为一组 SELECT * FROM student3 GROUP BY sex;这句话会将sex相同的数据作为一组

GROUP BY将分组字段结果中相同内容作为一组,并且返回每组的第一条数据,所以单独分组没什么用处。分组的目的就是为了统计,一般分组会跟聚合函数一起使用。分组后聚合函数的作用?不是操作所有数据,而是操作一组数据。 SELECT SUM(math), sex FROM student3 GROUPBY sex; 效果如下:
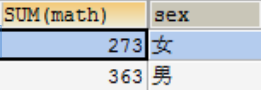
实际上是将每组的math进行求和,返回每组统计的结果

注意事项:当我们使用某个字段分组,在查询的时候也需要将这个字段查询出来,否则看不到数据属于哪组的查询的时候没有查询出分组字段

查询的时候查询出分组字段

具体步骤:按性别分组
SELECT sex FROM student3 GROUP BY sex;


查询男女各多少人
1.查询所有数据,按性别分组。 2.统计每组人数SELECT sex, COUNT(*) FROM student3 GROUP BY sex;

查询年龄大于25岁的人,按性别分组,统计每组的人数
1.先过滤掉年龄小于25岁的人。2.再分组。3.最后统计每组的人数SELECT sex, COUNT(*) FROM student3 WHERE age > 25 GROUP BY sex;

查询年龄大于25岁的人,按性别分组,统计每组的人数,并只显示性别人数大于2的数据 有很多同学可能会将SQL语句写出这样:
SELECT sex, COUNT(*) FROM student3 WHERE age > 25 GROUP BY sex WHERE COUNT(*) >2;
注意: 并只显示性别人数>2的数据属于分组后的条件,对于分组后的条件需要使用having子句
SELECT sex, COUNT(*) FROM student3 WHERE age > 25 GROUP BY sex HAVING COUNT(*) >2;只有分组后人数大于2的`男`这组数据显示出来

having与where的区别
having是在分组后对数据进行过滤.
where是在分组前对数据进行过滤
having后面可以使用聚合函数
where后面不可以使用聚合函数
准备数据:
INSERT INTO student3(id,NAME,age,sex,address,math,english) VALUES (9,‘唐僧’,25,‘男’,‘长安’,87,78),(10,‘孙悟空’,18,‘男’,‘花果山’,100,66),(11,‘猪八戒’,22,‘男’,‘高老庄’,58,78),(12,‘沙僧’,50,‘男’,‘流沙河’,77,88),(13,‘白骨精’,22,‘女’,‘白虎岭’,66,66),(14,‘蜘蛛精’,23,‘女’,‘盘丝洞’,88,88);
4.5 limit语句
LIMIT是限制的意思,所以LIMIT的作用就是限制查询记录的条数。 SELECT *|字段列表 [as 别名] FROM 表名[WHERE子句] [GROUP BY子句][HAVING子句][ORDER BY子句][LIMIT子句]; 思考:limit子句为什么排在最后? 因为前面所有的限制条件都处理完了,只剩下显示多少条记录的问题了!
LIMIT语法格式: LIMIT offset,length; 或者limit length; offset是指偏移量,可以认为是跳过的记录数量,默认为0 length是指需要显示的总记录数
具体步骤:查询学生表中数据,从第三条开始显示,显示6条
我们可以认为跳过前面2条,取6条数据
SELECT * FROM student3 LIMIT 2,6;

LIMIT的使用场景:分页 比如我们登录京东,淘宝,返回的商品信息可能有几万条,不是一次全部显示出来。是一页显示固定的条数。 假设我们一每页显示5条记录的方式来分页,SQL语句如下:
‐ 每页显示5条
‐‐ 第一页: LIMIT 0,5; 跳过0条,显示5条
‐‐ 第二页: LIMIT 5,5; 跳过5条,显示5条
‐‐ 第三页: LIMIT 10,5; 跳过10条,显示5条
SELECT * FROM student3 LIMIT 0,5;SELECT * FROM student3 LIMIT 5,5;SELECT * FROM student3 LIMIT 10,5;

注意:
如果第一个参数是0可以简写:
SELECT * FROM student3 LIMIT 0,5;
SELECT * FROM student3 LIMIT 5;
LIMIT 10,5; – 不够5条,有多少显示多少
第五章 数据库备份
=========
5.1 备份应用场景
在服务器进行数据传输、数据存储和数据交换,就有可能产生数据故障。比如发生意外停机或存储介质损坏。这时,如果没有采取数据备份和数据恢复手段与措施,就会导致数据的丢失,造成的损失是无法弥补与估量的。
5.2 source命令备份与还原
备份格式: mysqldump -u用户名 -p密码 数据库 > 文件的路径
还原格式: SOURCE 导入文件的路径;
注意:还原的时候需要先登录MySQL,并选中对应的数据库
具体操作:备份day22数据库中的数据
mysqldump ‐uroot ‐proot day22 > C:\work\课改\MYSQL课改资料\Day02‐MYSQL多表查询\code\bak.sql

数据库中的所有表和数据都会导出成SQL语句

还原day22数据库中的数据
删除day22数据库中的所有表

登录MySQL
mysql ‐uroot ‐proot
选中数据库
use day22;
select database();

使用SOURCE命令还原数据
source C:\work\课改\MYSQL课改资料\Day02‐MYSQL多表查询\code\bak.sql
5.3 图形化界面备份与还原
备份day22数据库中的数据

包含创建数据库的语句 

还原day22数据库中的数据
删除day22数据库
数据库列表区域右键“执行SQL脚本”, 指定要执行的SQL文件,执行即可

第六章 数据库约束
=========
对表中的数据进行进一步的限制,保证数据的正确性、有效性和完整性。 约束种类:
PRIMARY KEY: 主键
UNIQUE: 唯一
NOT NULL: 非空
DEFAULT: 默认
FOREIGN KEY: 外键
6.1 主键
6.1.1 主键作用
用来唯一标识一条记录,每个表都应该有一个主键,并且每个表只能有一个主键。 有些记录的 name,age,score 字段的值都一样时,那么就没法区分这些数据,造成数据库的记录不唯一,这样就不方便管理数据

哪个字段应该作为表的主键? 通常不用业务字段作为主键,单独给每张表设计一个id的字段,把id作为主键。主键是给数据库和程序使用的,不是给最终的客户使用的。所以主键有没有含义没有关系,只要不重复,非空就行。
6.1.2 创建主键
主键:PRIMARY KEY 主键的特点:
主键必须包含唯一的值
主键列不能包含NULL值
创建主键方式:
1. 在创建表的时候给字段添加主键
字段名 字段类型 PRIMARY KEY
2. 在已有表中添加主键 ALTER TABLE 表名 ADD PRIMARY KEY(字段名);
具体操作:创建表学生表st5, 包含字段(id, name, age)将id做为主键
CREATE TABLE st5 (
id INT PRIMARY KEY, ‐‐ id是主键 NAME VARCHAR(20),
age INT
);

添加数据
INSERT INTO st5 (id, NAME) VALUES (1, ‘唐伯虎’);
INSERT INTO st5 (id, NAME) VALUES (2, ‘周文宾’);
INSERT INTO st5 (id, NAME) VALUES (3, ‘祝枝山’);
INSERT INTO st5 (id, NAME) VALUES (4, ‘文征明’);
插入重复的主键值
主键是唯一的不能重复:
Duplicate entry ‘1’ for key 'PRIMARY’INSERT INTO st5 (id, NAME) VALUES (1, ‘文征明2’);
插入NULL的主键值
主键是不能为空的:
Column ‘id’ cannot be nullINSERT INTO st5 (id, NAME) VALUES (NULL, ‘文征明3’)
注意 : 一张表中只有一个主键 , 主键可以为多个字段 , 不过我们一般增减一个字段 id 来作为主键.
6.1.3 删除主键
ALTER TABLE 表名 DROP PRIMARY KEY;
具体操作:删除st5表的主键
ALTER TABLE st5 DROP PRIMARY KEY;

6.1.4 主键自增
主键如果让我们自己添加很有可能重复,我们通常希望在每次插入新记录时,数据库自动生成主键字段的值AUTO_INCREMENT 表示自动增长(字段类型是整型数字)
具体操作:创建学生表st6, 包含字段(id, name, age)将id做为主键并自动增长
CREATE TABLE st6 (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20),
age INT
);
插入数据
主键默认从1开始自动增长
INSERT INTO st6 (NAME, age) VALUES (‘唐僧’, 22);
INSERT INTO st6 (NAME, age) VALUES (‘孙悟空’, 26);
INSERT INTO st6 (NAME, age) VALUES (‘猪八戒’, 25);
INSERT INTO st6 (NAME, age) VALUES (‘沙僧’, 20);

DELETE和TRUNCATE的区别
DELETE 删除表中的数据,但不重置AUTO_INCREMENT的值。

TRUNCATE 摧毁表,重建表,AUTO_INCREMENT重置为1

6.2 唯一
在这张表中这个字段的值不能重复
6.2.1唯一约束
字段名 字段类型 UNIQUE
6.2.2 实现唯一约束
具体步骤:创建学生表st7, 包含字段(id, name),name这一列设置唯一约束,不能出现同名的学生
CREATE TABLE st7 (
id INT,
NAME VARCHAR(20) UNIQUE
);
添加一个学生
INSERT INTO st7 VALUES (1, ‘貂蝉’);
INSERT INTO st7 VALUES (2, ‘西施’);
INSERT INTO st7 VALUES (3, ‘王昭君’);
INSERT INTO st7 VALUES (4, ‘杨玉环’);
‐‐ 插入相同的名字出现name重复: Duplicate entry ‘貂蝉’ for key ‘name’
INSERT INTO st7 VALUES (5, ‘貂蝉’); ‐‐ 出现多个null的时候会怎样?因为null是没有值,所以不存在重复的问题
INSERT INTO st3 VALUES (5, NULL);INSERT INTO st3 VALUES (6, NULL);
6.3 非空
总结
无论是哪家公司,都很重视高并发高可用的技术,重视基础,重视JVM。面试是一个双向选择的过程,不要抱着畏惧的心态去面试,不利于自己的发挥。同时看中的应该不止薪资,还要看你是不是真的喜欢这家公司,是不是能真的得到锻炼。其实我写了这么多,只是我自己的总结,并不一定适用于所有人,相信经过一些面试,大家都会有这些感触。
最后我整理了一些面试真题资料,技术知识点剖析教程,还有和广大同仁一起交流学习共同进步,还有一些职业经验的分享。

VALUES (‘孙悟空’, 26);
INSERT INTO st6 (NAME, age) VALUES (‘猪八戒’, 25);
INSERT INTO st6 (NAME, age) VALUES (‘沙僧’, 20);
DELETE和TRUNCATE的区别
DELETE 删除表中的数据,但不重置AUTO_INCREMENT的值。
TRUNCATE 摧毁表,重建表,AUTO_INCREMENT重置为1
6.2 唯一
在这张表中这个字段的值不能重复
6.2.1唯一约束
字段名 字段类型 UNIQUE
6.2.2 实现唯一约束
具体步骤:创建学生表st7, 包含字段(id, name),name这一列设置唯一约束,不能出现同名的学生
CREATE TABLE st7 (
id INT,
NAME VARCHAR(20) UNIQUE
);
添加一个学生
INSERT INTO st7 VALUES (1, ‘貂蝉’);
INSERT INTO st7 VALUES (2, ‘西施’);
INSERT INTO st7 VALUES (3, ‘王昭君’);
INSERT INTO st7 VALUES (4, ‘杨玉环’);
‐‐ 插入相同的名字出现name重复: Duplicate entry ‘貂蝉’ for key ‘name’
INSERT INTO st7 VALUES (5, ‘貂蝉’); ‐‐ 出现多个null的时候会怎样?因为null是没有值,所以不存在重复的问题
INSERT INTO st3 VALUES (5, NULL);INSERT INTO st3 VALUES (6, NULL);
6.3 非空
总结
无论是哪家公司,都很重视高并发高可用的技术,重视基础,重视JVM。面试是一个双向选择的过程,不要抱着畏惧的心态去面试,不利于自己的发挥。同时看中的应该不止薪资,还要看你是不是真的喜欢这家公司,是不是能真的得到锻炼。其实我写了这么多,只是我自己的总结,并不一定适用于所有人,相信经过一些面试,大家都会有这些感触。
最后我整理了一些面试真题资料,技术知识点剖析教程,还有和广大同仁一起交流学习共同进步,还有一些职业经验的分享。
[外链图片转存中…(img-0bt6THnN-1714646326412)]















 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









