







自动构图技术首先需要识别画面中的主体,淘宝中的商品类别多种多样,想通过物体检测识别出主体所在的bbox难度比较大,观察有好货的图片发现商品在图像中是比较显著的,于是我们通过显著性检测来识别主体所在区域。

显著性检测是模拟人眼对视野中的画面能够迅速捕捉到最显著部分,这种视觉显著性和物体类别以及物体在画面中的位置都有关系。不同于通用物体检测,显著性检测数据集无需类别,而类似图像分割,GT是一个张mask,显著性算法的结果也是一个mask,然后通过求外接矩形可以获取bbox。
我们使用的是CPD(Cascaded Partial Decoder for Fast and Accurate Salient Object Detectio)显著性检测算法,该算法在保证精确达到SOTA水平的同时计算效率也非常高,下图(a)是比较常见的显著性检测算法,提取网络结构的浅层和深层特征,并对这些特征进行反卷积,然后融合得到最终的显著性图,(b)是CPD算法的流程,作者实验发现前两层特征对结果的提升几乎没有影,但是却花费很多计算时间。CPD直接从第3层的feature开始,然后通过HAM全局注意力模块提升结果的完整性。

利用显著性检测,我们实现了对有好货封面图的三种自动构图:主体突出裁剪,1:1裁剪,4:3裁剪,满足有好货场景下对不同长宽比图像的需求。
▐ 图像增强
自动构图是处理图像空间问题,图像增强是为了让画面看起来更加有质感,逼格更高。
常用的图像增强技术有超分,图像修复,我们在此基础上还实验了人物背景虚化,模拟手机人像功能。
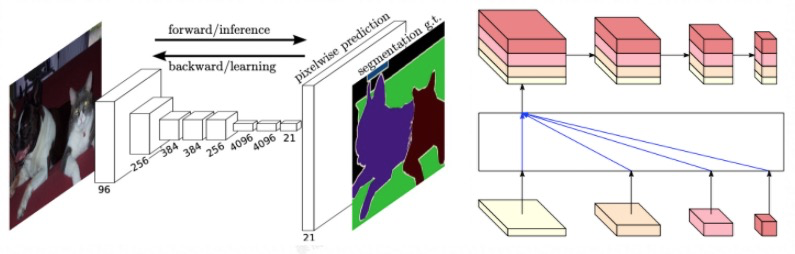
图像分割是计算机视觉的经典问题,近几年随着HRNet这种强大的backbone的出现以及数据集的增长,人像分割的效果已经逐步达到可用的程度。我们基于FCN经典全卷积网络和HRNet backbone训练人像分割然后结和图像matting技术实现人像抠图,然后对背景进行模糊处理达到背景虚化的效果。

左侧是原图,右侧为背景虚化结果
图像修复主要用在老照片还原,比如下图所示多年之前拍摄的图像清晰度低,画面有许多噪点,颜色失真。图像修复包括多个任务,比如清晰度提升,区域修复,颜色校正等。我们使用Bringing Old Photos Back to Life论文中的方法,基于双VAE(variational autoencoder)学习合成的老照片到原图的映射函数。

下图为图像修复的效果,相比原图清晰度和颜色都更加逼真。

左侧是原图,右侧为图像修复结果
视频5s动态封面图
短视频内容在淘内占比越来越多,视频的开头是一些预定义好的片头,比如商家logo,视频软件特效等,无法在视频开头给予用户一个直观且吸引眼球的效果。众所周知一张好的视频封面图往往会提升视频点击率,而动态封面图可以提供更加丰富的信息。首猜短视频自动播放时如果先播视频里最有价值的部分,那么这次曝光带来的转化会更好。因此我们搭建一套智能动态封面图生产算法,来帮助商家选取这样的动态封面提升视频内容的投放效率。
动态封面图项目经历了几个阶段:
-
基于经验知识的无监督生产:根据美观度,清晰度,相关性等几个维度打分,结合镜头切分来生产;
-
通过线上的A/B测试收集用户行为数据,然后基于pair-wise learning学习视频的highlight分数;
-
基于视频与文本相关性端到端学习的一些尝试
▐ 启发式阶段
结合产品同学和我们的观察,首先选择一些比较显著的维度,比如画面是否清晰美观,画面和标题是否相关等,最后综合各模型的分数选择得分最高的部分。

图像清晰度是一个比较主观的感受,同样一副图在手机上是清晰的,但是放在电脑上看就不清楚了。一副图像中不同区域的清晰度也可能不同,比如下面人体部分是清洗的,但是背景是模糊的,手机上的人像模式可以方便的拍出这种效果。用模型来学习这种比较偏主观的任务是比较难的,所以我们采取整图加patch分别打分的模式来判断清晰度,打分方法使用传统计算机视觉里的拉普拉斯算子。

美观度模型我们尝试了NIMA中所使用的AVA数据集来进行美观度的学习,但是可能由于电商视频与AVA中占主流的风景人文摄影存在一定的差异,我们直接用来预测画面美观度的偏差会比较大,于是我们使用淘内数据标注了一批美观/不美观数据训练二分类模型,使用分类模型的softmax概率作为视频画面帧的分数。
在服饰等行业的视频中经常会出现一些材质和细节特写。这些镜头不方便用户对商品形成整体上的认知,业务同学反馈不适合出现在动态封面图中,于是我们用商品主图作为整体图片的样本,然后对这些图片做随机位置的固定大小的剪切来形成细节图片的样本构建了一个百万级别的图片分类数据集。
首猜短视频业务可以挂载相关的商品,如果封面图和挂载商品不相关会给人比较差的体验。利用淘内的海量商品及类目体系,我们训练了一个商品分类模型。我们选取了淘宝上非虚拟非O2O的一级类目的商品,并以一级类目作为分类目标训练了一个resnet50模型。如果一个视频帧如果被分类模型判定为存在某品类商品,那么就认为这一帧中出现了该品类的商品,于是我们以视频所关联的商品所属类目的softmax概率作为相关性的分数。这一看似简单的假设,相对高效地解决了相关性的问题,选取的封面基本保证了商品的出现。
另外我们实验了镜头切换的影响,结论和我们的设想一致:在过短的时间内进行多次切换会影响用户体验,对ctr有负向作用。所以第一阶段的动态视频封面图包括
启发式阶段生产的动态封面在多个场景中落地。在哇哦视频的列表页中进行了AB测试,对比从头播放原视频,动态视频封面获得1%以上ctr增长,平均单视频播放时长增长近3%。另外在天猫搜索中也上线了动态视频封面,AB测试pv增长约3%,点击增长约2%,成交笔数增长约3%,视频相关query的用户uv也增长了约1%。
▐ 用户行为加持
启发式算法的结果上线后取得了一定的业务收益,证明动态封面图的价值,下一步我们借助线上用户行为数据来提升效果。
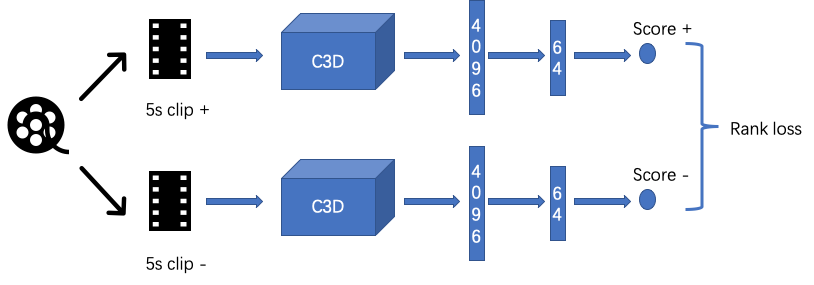
启发式模型仅考虑了视频帧本身的图像信息,却忽略了视频本身所包含的时序和结构信息,因而我们使用了一个C3D卷积网络来训练这样的一个可以直接评估一个视频片段是否highlight的模型。我们期望这一模型可以直接在原视频上进行一个窗口的滑动,评价每个5秒片段(首猜动态封面图时长固定)的质量,从而直接帮助我们的5秒封面的选取。我们采用C3D模型作为预训练的特征,然后以两层FC来进行片段分数的评估,以正负样本对的分数相对高低作为pair-wise学习的优化目标。在我们所构建的约25万pair的数据集上,算法可以很快的收敛,准确率约0.71。
具体细节参考https://topic.atatech.org/articles/157014
我们所使用的C3D模型相对来说结构还是较为简洁,但是实际上每个滑动窗口都只能使用当前窗口的局部信息,也没有考虑到视频所附带的文本等side information。很自然地,我们想到了使用transformer架构来对视频帧信息进行编码,并引入了视频的标题文本特征来辅助片段的选择。
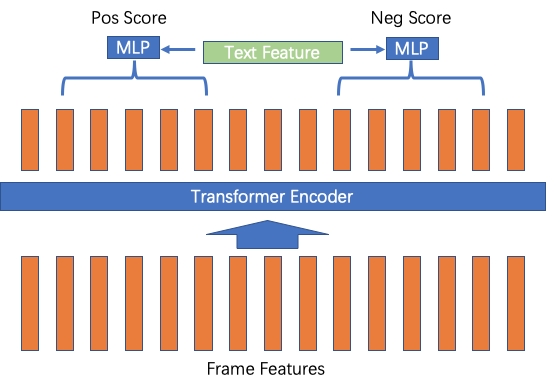
我们对视频进行均匀抽帧后,将视频帧特征输入到transformer中对每一帧特征进行encode,之后依然是以滑动窗口的方式对5秒内的帧特征进行concat后,引入文本特征,使用mlp来进行分数预测。在这一框架下,我们可以使用不同的标注数据和训练方式:对于标注了用户5秒的视频,我们可以定义用户所选取的片段标记为1,其它为0,而直接使用交叉熵来训练;也可以使用随机选取负样本的方式,来使用hinge loss来pairwise地训练;对于线上投放过的样本,我们也可以直接预测对应样本的ctr,做一个ctr预测的任务;如果某些视频有多个样本进行了投放,我们也可以用这些不同一ctr样本来进行pairwise训练。在一个以ctr高低来进行pair-wise训练的数据集上,基于transformer的模型相对c3d模型,可以将pair对的排序正确率从0.62提升到0.75左右,改善非常明显。
▐ 端到端学习
经过启发式学习和利用用户行为优化两个阶段,我们接下来尝试用端到端的方式,直接从源视频中找到最精彩的片段作为视频动态封面图。现有最大的highlight数据集Video2Gif,包含120K个动图,以及超过80K个的视频,总体包括了7379小时,但是该数据集主要是从影视剧中选择的,和我们的场景差别比较大,而且我们的动态封面图还有对应的标题信息,需要考虑视频和文本相关性,这一特性Video2Gif数据是没有的,所以我们建立了自己的highlight数据集。
我们先在首猜场景下用时尚服饰/箱包/电子数码/美妆个护/运动户外/玩具/家居日这7个行业下的热门PGC视频,以及视频的标题及对应的商品标题作为源数据,使用达人上传的5秒封面作为数据集的groundtruth。我们的task是结合视频标题与原视频,选取5秒视频片段。
算法流程为:视频帧用resnet50抽取视觉特征,利用双向GRU来对帧特征进行编码;文本使用w2v获得词向量之后,并利用双向GRU进行编码,利用CoEvo模块进行迭代优化;对于文本特征,我们对所有词构建了一个图,并且计算词与词之间的相似性,并通过相邻边关系来汇聚成词的新的特征向量,降低文本中与整体语义不相关的词的权重。
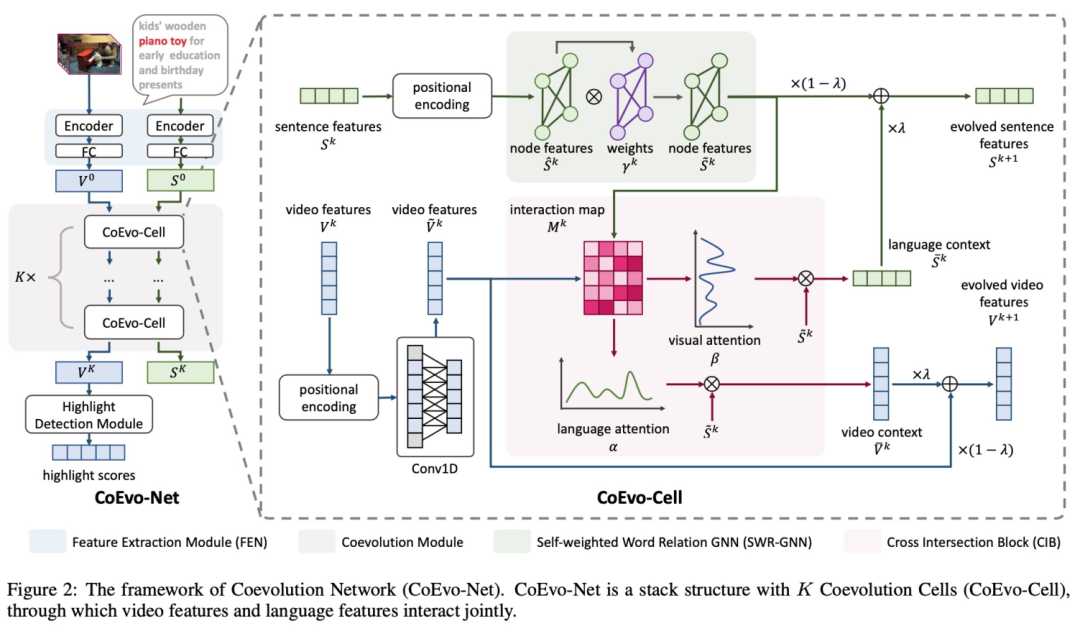
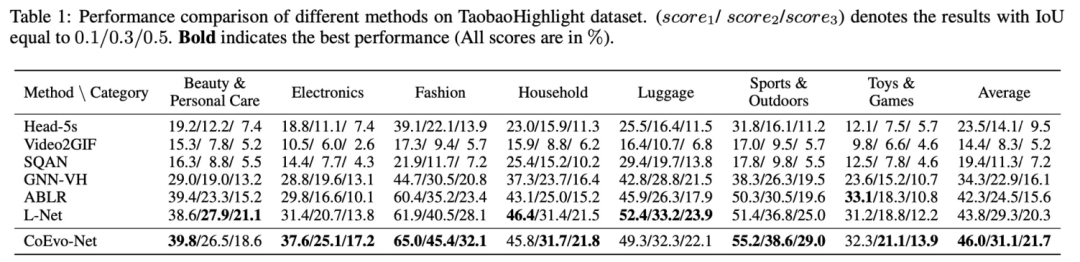
我们以IoU作为模型预测highlight位置准确度的指标,如上表所示,整体性能指标优于SOTA,但是线上ctr没有涨,我们分析可能是使用数据集不合理,模型的GT是用户选择的, 和ctr指标不太一致。于是我们又重新构建数据集。让外包人工选择了一批highlight数据,给定原视频,以及备选的N个5秒片段,外包同学选择最精彩并且和文本最相关的一个片段。基于video localization方法的思路,提出基于图卷积的分层聚合视频精彩片段检测模型,利用图结构对信息聚合的有效性进行设计,主要包含两个阶段,视频多模态信息融合阶段和基于图卷积网络的精彩片段聚合阶段,并引入了特征重构误差,来帮助我们选取highlight。
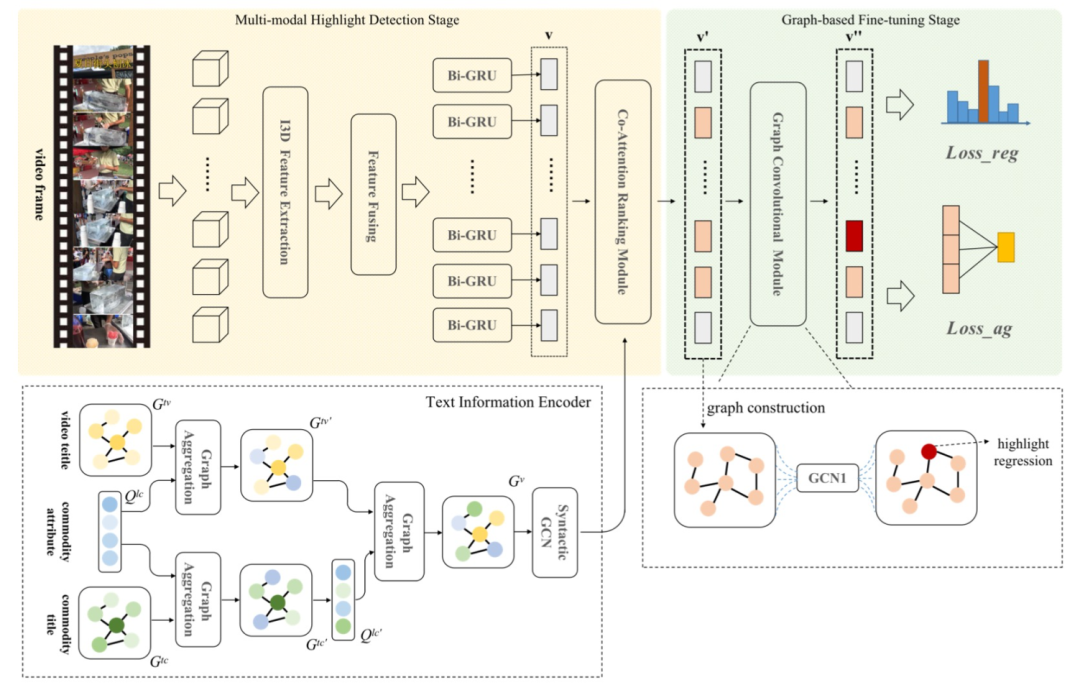
我们同样以IoU指标作为衡量highlight预测位置的准确度的指标,较SOTA算法也有所提升。
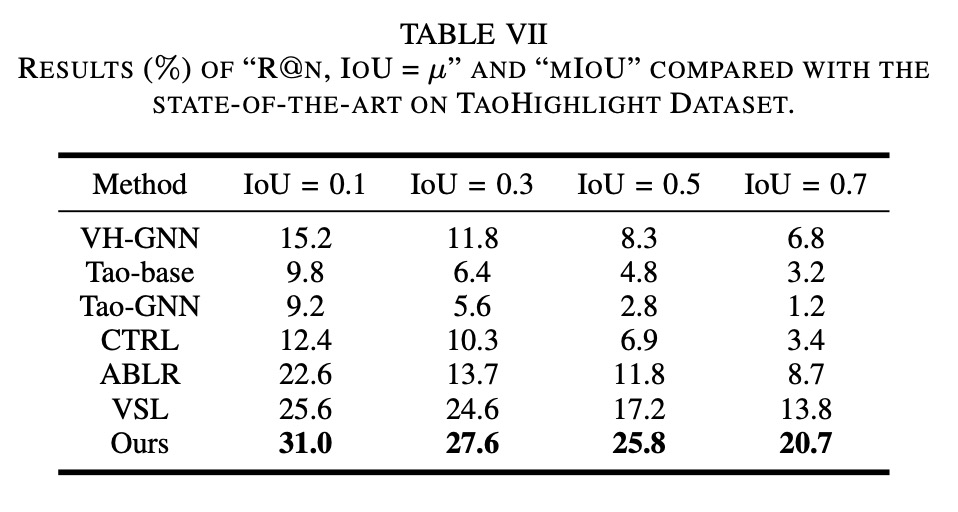
模型上线之后发现,我们发现线上的ctr指标依然不达预期,但是动态封面图的完播率有一定提升。通过大量case review我们发现动态封面图点击率比较高的是比较新奇,情节不太完整的,而相关性太好,把视频的关键因素全展现完的highlight,由于已经满足了用户对信息的获取,反而不会带来ctr的提升。虽然ctr没有提升而视频封面图完播率提升了,说明用户从动态封面图里获取了更多有效信息,避免点击非兴趣相关的内容,用户体验其实是正向的。由此可见评价算法的指标应该是多元化的,只关注单一指标,可能会有损用户体验,算法设计既要考虑效率也要考虑体验。
▐ 封面图加工二创
上述方法解决的是如何选择视频片段作为动态封面图,在这之后其实还可以对画面进行加工来提升画面吸引力,比如自动插入一些文字、表情或者特效到画面中等等。我们在视频动态封面图的基础上,通过创意文案、视频弹幕等方式为视频添加更多素材,传递给用户更多信息,帮助其决策,提升点击率等指标。我们将动态视频展示区分为以下文案区和弹幕区,其中文案区的内容可以来自短标题、推荐理由等,需要考虑有字体、颜色、位置、时长等,弹幕区的内容可以来自商品的正面评价,弹幕制作需要考虑字体颜色、字体样式、位置、弹幕速度等等。
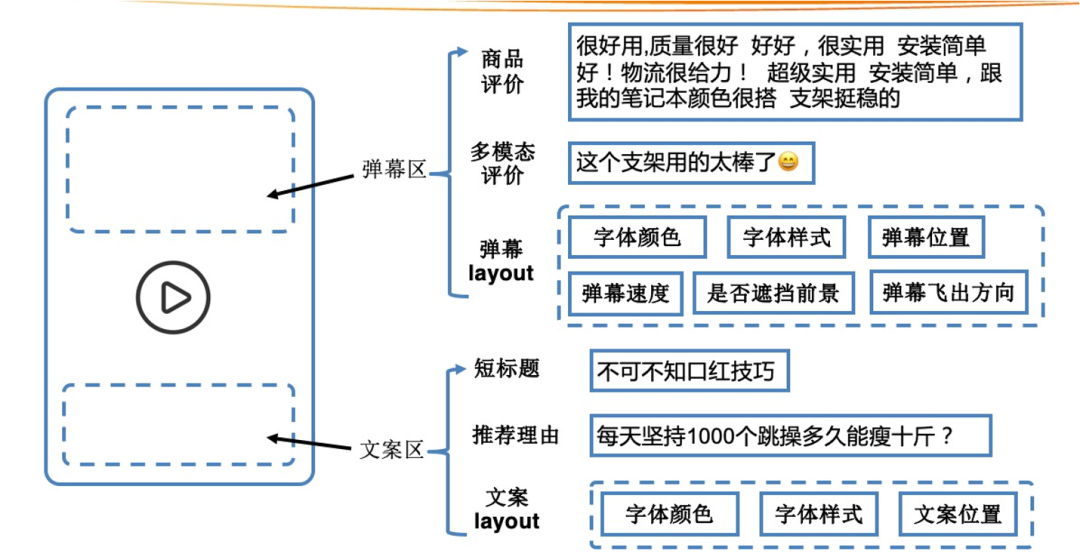
- 文案区
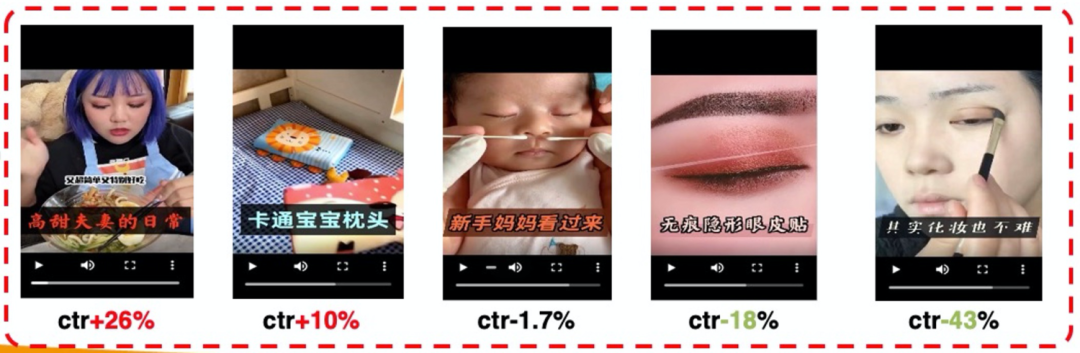
在抖音、小红书等平台中,我们发现视频的生产者都会把一些吸引人的信息制作成花字放到视频上,于是我们首先在文案区对视频花字进行了初步探索,字体颜色通过提取视频背景的主色进行适配,花字区域统一放在视频的下方,时长持续到视频片段结束为止,花字的内容也是至关重要的,我们简单通过视频短标题和人工的方式确定搜集了一批花字内容。经过上线测试发现部分ctr提升效果明显,但是也存在ctr下降明显的例子,可能原因在于算法产出的花字放置的区域、样式单一,灵活适配性不高。
- 弹幕区
我们继续研究了视频弹幕这种交互形式结合短视频的新形式,用短视频封面+弹幕的交互形式,扩展更多的决策信息给到用户。我们选取视频带有的商品正面评价作为弹幕内容,使用Color Harmonization方法确定弹幕颜色,对弹幕文字进行阴影和底色处理,其他处理还包括了调节弹幕的速度、文字密度、行数等等。

完成了视频弹幕离线生成系统开发,可日均生产数十万弹幕,实现多种特效弹幕的生产,在淘宝经验上测试,对服饰、家具等类目ctr有较为明显的提升。

新展示形态探索
无论图像还是视频都是2D展示形式,如何在屏幕上可以展示出更加立体,更有冲击力的画面,来提升用户体验这是智能展示下阶段要考虑的。比如优酷在《这!就是街舞》第三季中使用的自由视角技术,用户在屏幕上滑动就可以看到其他视角的画面。
最近几年出现很多场景合成的工作,不需要3D重建也能够生成逼真的3D效果,比如DeepView,NeRF输入一个场景几张不同视角的图片来合成该场景其他视角的图像。说起来比较复杂,举个栗子,下面的视频并非是拍摄的,而是通过几十张图片实时渲染生成的,是不是感觉非常顺滑,毫无违和感。
该方法使用多平面图像(MPI)视图合成技术,将我们看到的图像分解为不同深度的多个平面层图像。通过一组图像来重建MPI,然后就可以生存该场景其他视角的画面。
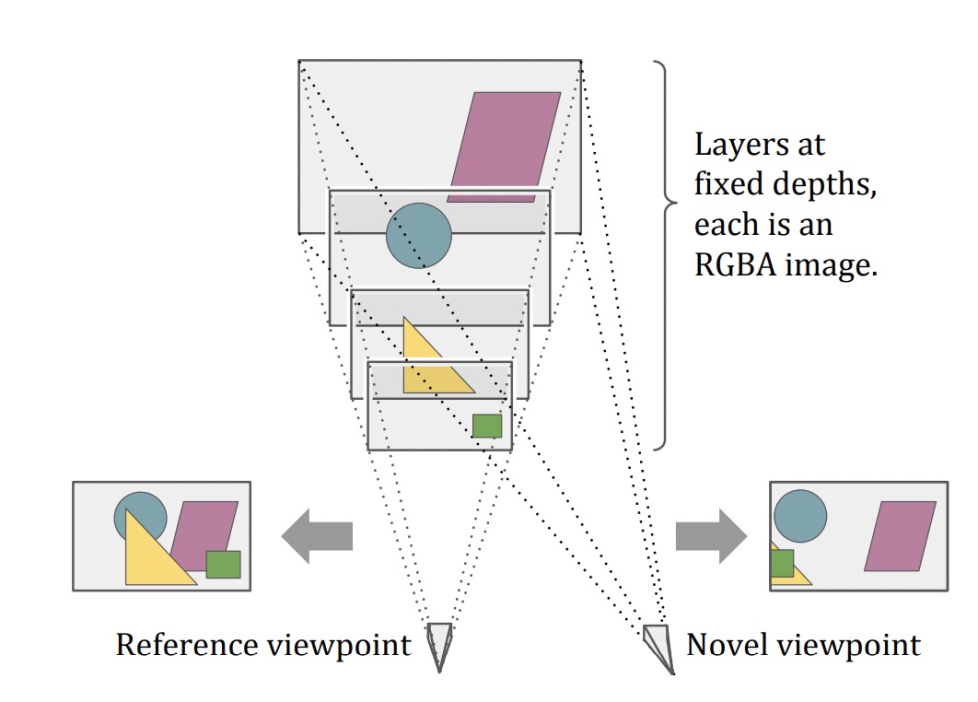
除了3D效果之外,远近,动静的对比也会达到非常好的视觉冲击力。远近对比可以通过背景虚化技术实现。动静对比的效果可以用下面这种Cinemagraph来实现。这种GIF或者视频固定大部门区域画面,只保留局部运动区域造成一种时间静止的错觉。

目前生成这种效果可以通过两种途径,一是输入一张图像然后用模型来估计其中的运动场信息来生成部分区域移动的效果,比如让天空,云彩和水流运动起来。
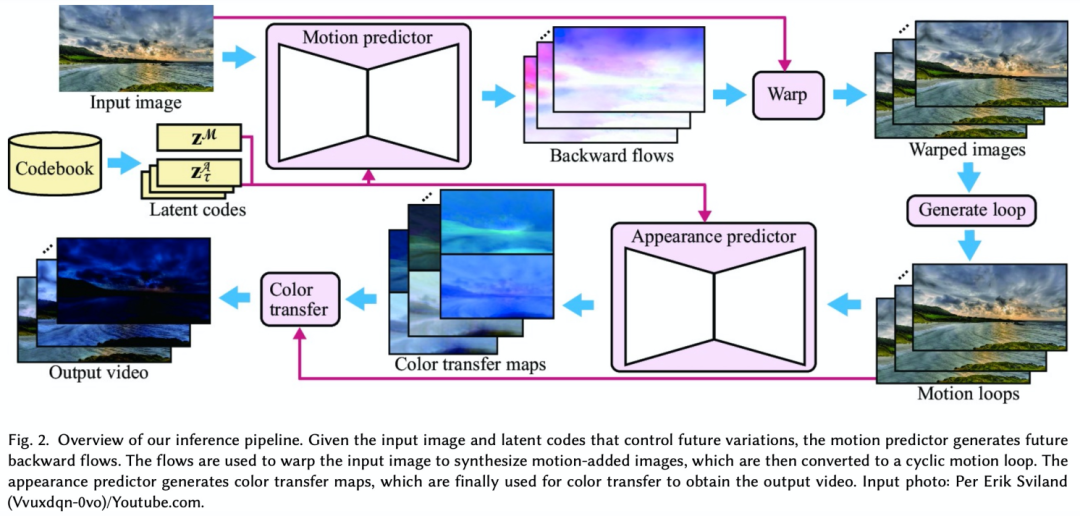
总结
不同的展示技术可以带来新的国民产品和行业,就像前几年图文时代大家都看微信公众号,随着移动互联网和宽带发展短视频这一展示形式迅速崛起,抖音和快手借助短视频在短短几年时间收获大量用户,打造成新的视频生态,对电商行业来说,直播这一展示形式极大的缩短了卖家和买家时空上的距离,提升卖货效率,而且促使专业主播这一职业的发展。可以想像的是随着3D AR/VR等更加生动逼真的展示技术的成熟,必然会有一大波新的机会出现。
✿ 拓展阅读
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

最后
针对以上面试题,小编已经把面试题+答案整理好了



面试专题

除了以上面试题+答案,小编同时还整理了微服务相关的实战文档也可以分享给大家学习



《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
730011507)]
面试专题
[外链图片转存中…(img-1hKkdIwB-1713730011507)]
除了以上面试题+答案,小编同时还整理了微服务相关的实战文档也可以分享给大家学习
[外链图片转存中…(img-inHANPkK-1713730011507)]
[外链图片转存中…(img-81lnkWRz-1713730011508)]
[外链图片转存中…(img-f5fnj3kb-1713730011508)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 4153
4153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









