







[root@hedy temp]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ba5374d6245c wurstmeister/zookeeper “/bin/sh -c '/usr/…” About an hour ago Up About an hour 22/tcp, 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp temp_zookeeper_1
2c58f46bb772 wurstmeister/kafka:2.11-0.11.0.3 “start-kafka.sh” About an hour ago Up About an hour 0.0.0.0:9092->9092/tcp temp_kafka1_1
- 执行以下命令可以查看topic001的基本情况:
docker exec temp_kafka1_1 \
kafka-topics.sh \
–describe \
–topic topic001 \
–zookeeper zookeeper:2181
看到的信息如下:
Topic:topic001 PartitionCount:2 ReplicationFactor:1 Configs:
Topic: topic001 Partition: 0 Leader: 1001 Replicas: 1001 Isr: 1001
Topic: topic001 Partition: 1 Leader: 1001 Replicas: 1001 Isr: 1001
源码下载
接下来的实战是编写生产消息和消费消息的两个应用的源码,您可以选择直接从GitHub下载这两个工程的源码,地址和链接信息如下表所示:
| 名称 | 链接 | 备注 |
| :-- | :-- | :-- |
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
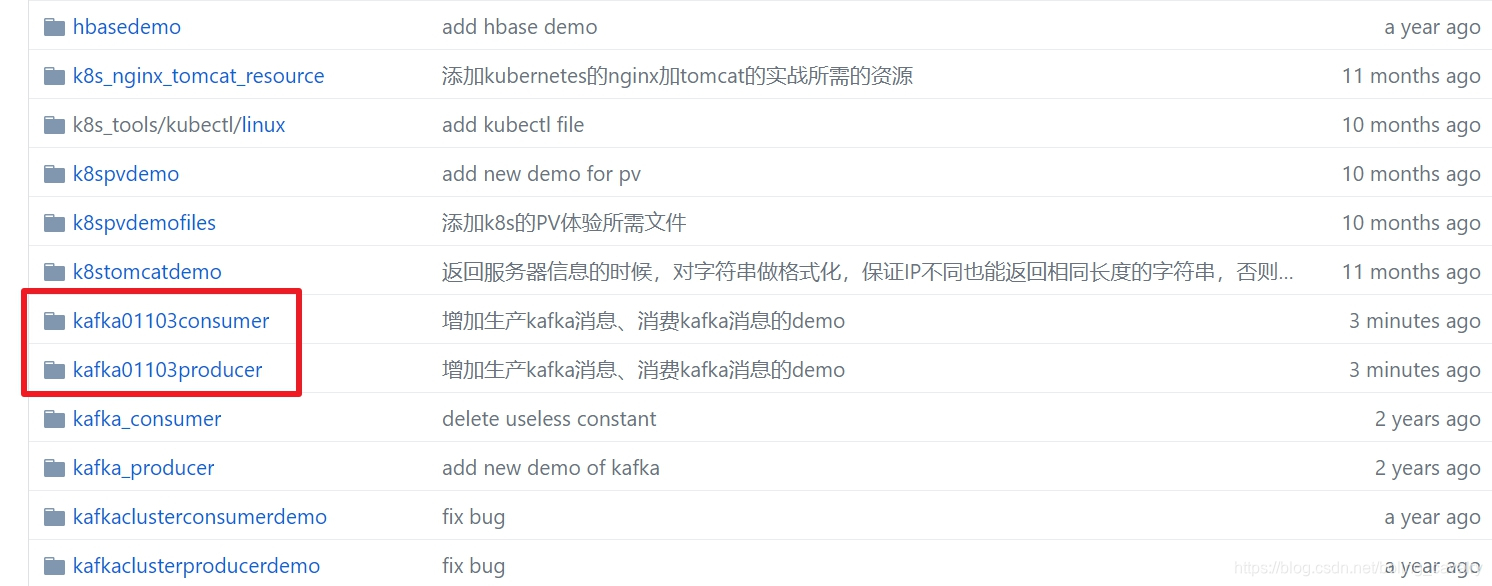
这个git项目中有多个文件夹,本章源码在kafka01103consumer和kafka01103producer这两个文件夹下,如下图红框所示:
接下来开始编码:
开发生产消息的应用
- 创建一个maven工程,pom.xml内容如下:
<project xmlns=“http://maven.apache.org/POM/4.0.0” xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”
xsi:schemaLocation=“http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd”>
4.0.0
org.springframework.boot
spring-boot-starter-parent
1.5.9.RELEASE
com.bolingcavalry
kafka01103producer
0.0.1-SNAPSHOT
kafka01103producer
Demo project for Spring Boot
<java.version>1.8</java.version>
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter
org.springframework.kafka
spring-kafka
1.3.8.RELEASE
com.alibaba
fastjson
1.2.28
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-maven-plugin
再次强调spring-kafka版本和kafka版本的匹配很重要;
2. 配置文件application.properties内容:
#kafka相关配置
spring.kafka.bootstrap-servers=kafka1:9092
#设置一个默认组
spring.kafka.consumer.group-id=0
#key-value序列化反序列化
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
#每次批量发送消息的数量
spring.kafka.producer.batch-size=65536
spring.kafka.producer.buffer-memory=524288
- 发送消息的业务代码只有一个MessageController类:
package com.bolingcavalry.kafka01103producer.controller;
import com.alibaba.fastjson.JSONObject;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.web.bind.annotation.*;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.UUID;
/**
-
@Description: 接收web请求,发送消息到kafka
-
@author: willzhao E-mail: zq2599@gmail.com
-
@date: 2019/1/1 11:44
*/
@RestController
public class MessageController {
@Autowired
private KafkaTemplate kafkaTemplate;
@RequestMapping(value = “/send/{name}/{message}”, method = RequestMethod.GET)
public @ResponseBody
String send(@PathVariable(“name”) final String name, @PathVariable(“message”) final String message) {
SimpleDateFormat simpleDateFormat=new SimpleDateFormat(“yyyy-MM-dd HH:mm:ss”);
String timeStr = simpleDateFormat.format(new Date());
JSONObject jsonObject = new JSONObject();
jsonObject.put(“name”, name);
jsonObject.put(“message”, message);
jsonObject.put(“time”, timeStr);
jsonObject.put(“timeLong”, System.currentTimeMillis());
jsonObject.put(“bizID”, UUID.randomUUID());
String sendMessage = jsonObject.toJSONString();
ListenableFuture future = kafkaTemplate.send(“topic001”, sendMessage);
future.addCallback(o -> System.out.println("send message success : " + sendMessage),
throwable -> System.out.println("send message fail : " + sendMessage));
return “send message to [” + name + “] success (” + timeStr + “)”;
}
}
-
编码完成后,在pom.xml所在目录执行命令mvn clean package -U -DskipTests,即可在target目录下发现文件kafka01103producer-0.0.1-SNAPSHOT.jar,将此文件复制到192.168.1.102机器上;
-
登录192.168.1.102,在文件kafka01103producer-0.0.1-SNAPSHOT.jar所在目录执行命令java -jar kafka01103producer-0.0.1-SNAPSHOT.jar,即可启动生产消息的应用;
开发消费消息的应用
- 创建一个maven工程,pom.xml内容如下:
<project xmlns=“http://maven.apache.org/POM/4.0.0” xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”
xsi:schemaLocation=“http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd”>
4.0.0
org.springframework.boot
spring-boot-starter-parent
1.5.9.RELEASE
com.bolingcavalry
kafka01103consumer
0.0.1-SNAPSHOT
kafka01103consumer
Demo project for Spring Boot
<java.version>1.8</java.version>
org.springframework.boot
spring-boot-starter
org.springframework.kafka
spring-kafka
1.3.8.RELEASE
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-maven-plugin
再次强调spring-kafka版本和kafka版本的匹配很重要;
2. 配置文件application.properties内容:
#kafka相关配置
spring.kafka.bootstrap-servers=192.168.1.101:9092
#设置一个默认组
spring.kafka.consumer.group-id=0
#key-value序列化反序列化
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
#每次批量发送消息的数量
spring.kafka.producer.batch-size=65536
spring.kafka.producer.buffer-memory=524288
- 消费消息的业务代码只有一个Consumer类,收到消息后,会将内容内容和消息的详情打印出来:
@Component
public class Consumer {
@KafkaListener(topics = {“topic001”})
public void listen(ConsumerRecord<?, ?> record) {
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
if (kafkaMessage.isPresent()) {
Object message = kafkaMessage.get();
System.out.println(“----------------- record =” + record);
System.out.println(“------------------ message =” + message);
}
}
}
-
编码完成后,在pom.xml所在目录执行命令mvn clean package -U -DskipTests,即可在target目录下发现文件kafka01103consumer-0.0.1-SNAPSHOT.jar,将此文件复制到192.168.1.104机器上;
-
登录192.168.1.104,在文件kafka01103consumer-0.0.1-SNAPSHOT.jar所在目录执行命令java -jar kafka01103consumer-0.0.1-SNAPSHOT.jar,即可启动消费消息的应用,控制台输出如下:
2019-01-01 13:41:41.747 INFO 1422 — [ main] o.a.kafka.common.utils.AppInfoParser : Kafka version : 0.11.0.2
2019-01-01 13:41:41.748 INFO 1422 — [ main] o.a.kafka.common.utils.AppInfoParser : Kafka commitId : 73be1e1168f91ee2
2019-01-01 13:41:41.787 INFO 1422 — [ main] o.s.s.c.ThreadPoolTaskScheduler : Initializing ExecutorService
2019-01-01 13:41:41.912 INFO 1422 — [ main] c.b.k.Kafka01103consumerApplication : Started Kafka01103consumerApplication in 11.876 seconds (JVM running for 16.06)
2019-01-01 13:41:42.699 INFO 1422 — [ntainer#0-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : Discovered coordinator kafka1:9092 (id: 2147482646 rack: null) for group 0.
2019-01-01 13:41:42.721 INFO 1422 — [ntainer#0-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : Revoking previously assigned partitions [] for group 0
2019-01-01 13:41:42.723 INFO 1422 — [ntainer#0-0-C-1] o.s.k.l.KafkaMessageListenerContainer : partitions revoked:[]
2019-01-01 13:41:42.724 INFO 1422 — [ntainer#0-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : (Re-)joining group 0
2019-01-01 13:41:42.782 INFO 1422 — [ntainer#0-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : Successfully joined group 0 with generation 5
2019-01-01 13:41:42.788 INFO 1422 — [ntainer#0-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : Setting newly assigned partitions [topic001-1, topic001-0] for group 0
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

总结
上述知识点,囊括了目前互联网企业的主流应用技术以及能让你成为“香饽饽”的高级架构知识,每个笔记里面几乎都带有实战内容。
很多人担心学了容易忘,这里教你一个方法,那就是重复学习。
打个比方,假如你正在学习 spring 注解,突然发现了一个注解@Aspect,不知道干什么用的,你可能会去查看源码或者通过博客学习,花了半小时终于弄懂了,下次又看到@Aspect 了,你有点郁闷了,上次好像在哪哪哪学习,你快速打开网页花了五分钟又学会了。
从半小时和五分钟的对比中可以发现多学一次就离真正掌握知识又近了一步。

人的本性就是容易遗忘,只有不断加深印象、重复学习才能真正掌握,所以很多书我都是推荐大家多看几遍。哪有那么多天才,他只是比你多看了几遍书。
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
g-community.csdnimg.cn/images/e5c14a7895254671a72faed303032d36.jpg" alt=“img” style=“zoom: 33%;” />
总结
上述知识点,囊括了目前互联网企业的主流应用技术以及能让你成为“香饽饽”的高级架构知识,每个笔记里面几乎都带有实战内容。
很多人担心学了容易忘,这里教你一个方法,那就是重复学习。
打个比方,假如你正在学习 spring 注解,突然发现了一个注解@Aspect,不知道干什么用的,你可能会去查看源码或者通过博客学习,花了半小时终于弄懂了,下次又看到@Aspect 了,你有点郁闷了,上次好像在哪哪哪学习,你快速打开网页花了五分钟又学会了。
从半小时和五分钟的对比中可以发现多学一次就离真正掌握知识又近了一步。
[外链图片转存中…(img-u4ROWyov-1713632465446)]
人的本性就是容易遗忘,只有不断加深印象、重复学习才能真正掌握,所以很多书我都是推荐大家多看几遍。哪有那么多天才,他只是比你多看了几遍书。
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 9331
9331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









