







- 点击页面上的重试按钮;
NFS Gateway启动失败
- 发现NFS Gateway服务有问题,检查日志:
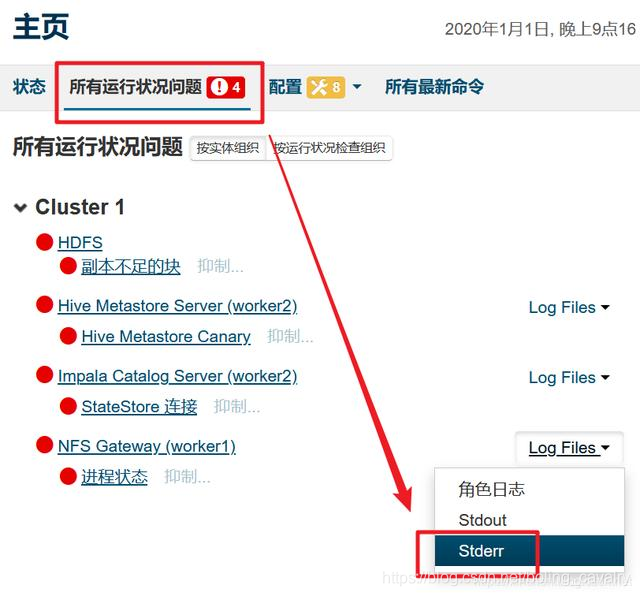
- 日志如下,在worker1节点上,portmap和rpcbind这两个服务不存在导致的:
No portmap or rpcbind service is running on this host. Please start portmap or rpcbind service before attempting to start the NFS Gateway role on this host.
- 于是安装所需服务:
yum install -y nfs-utils rpcbind
- 启动服务:
systemctl start rpcbind
- 再次启动:
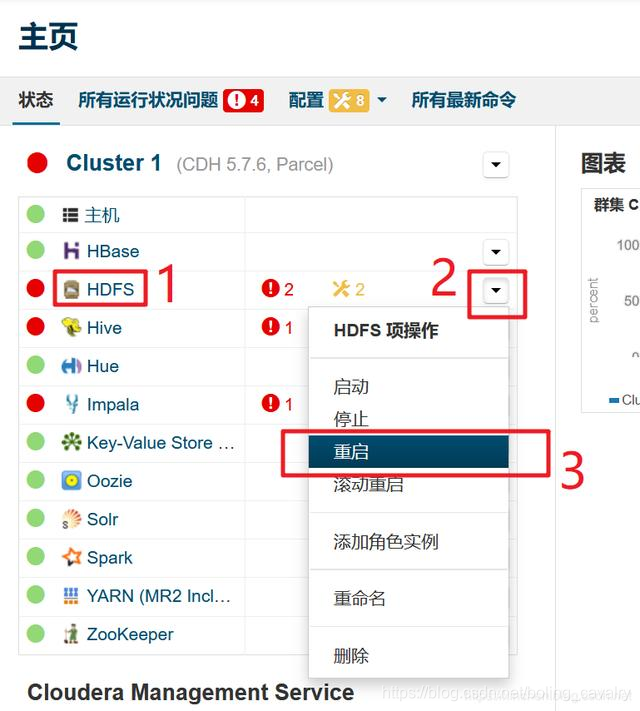
- 等待HDFS服务重启完成后,如下图,可见NFS Gateway问题已经消失:
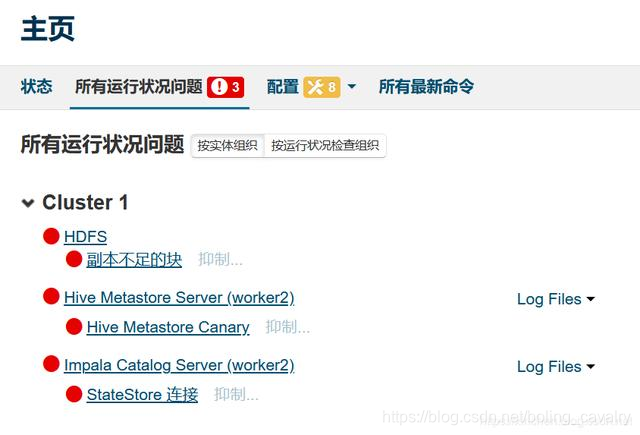
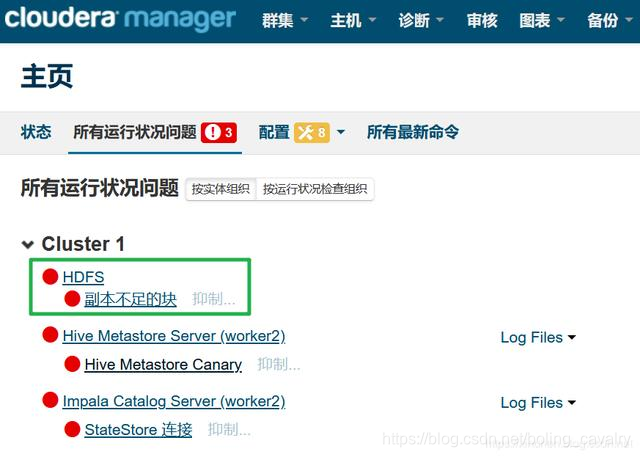
HDFS副本不足的块
- 问题如下图绿框所示:
- 目前只有一个datanode,可以增加一个,如下图,进入HDFS的实例页面,点击"添加角色实例":
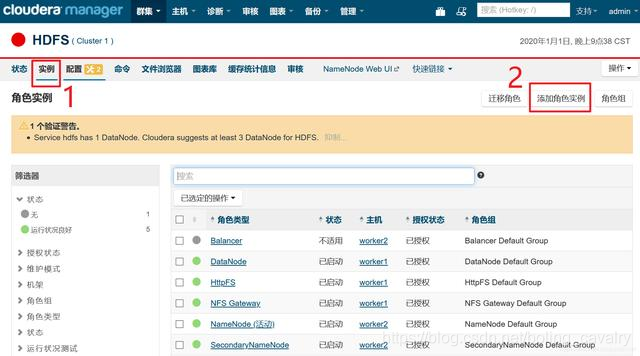
- 点击下图红框位置,增加一个DataNode:
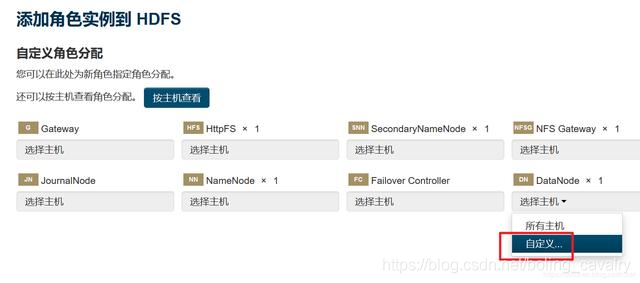
- 如下图,确保worker1和worker2都选上:

- 勾选后,点击红框2中的按钮,在下拉菜单中点击“启动”:
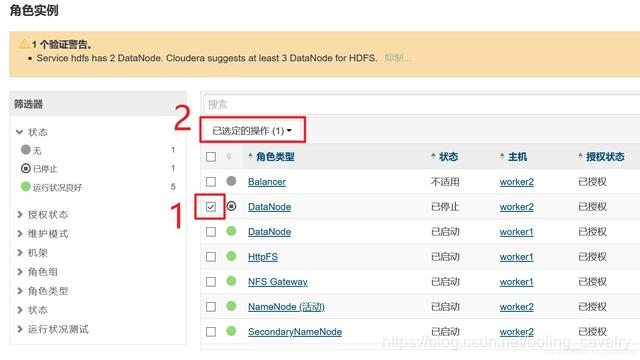
- 现在有了两个DataNode,所以副本数可以设置为2,如下图红框所示,按照顺序找出参数进行设置,记得点击右下角的"保存更改"按钮:
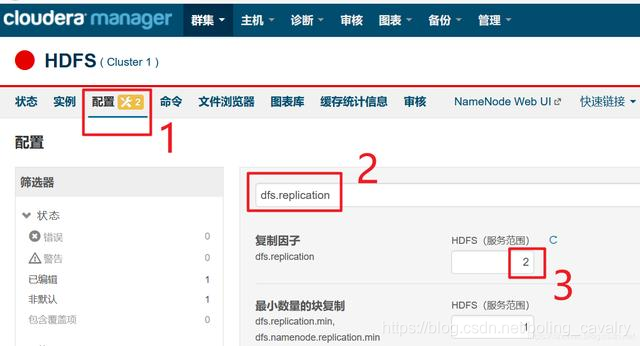
- 上述设置完成后,新写入hdfs的文件副本数为2,如果要将之前已经写入的文件的副本数也调整为2,请SSH登录worker1节点,执行以下命令切换到hdfs账号:
su - hdfs
- 以hdfs账号的身份执行以下命令,即可完成副本数设置:
hadoop fs -setrep -R 2 /
- 返回管理页面,可见HDFS的状态变成了健康:
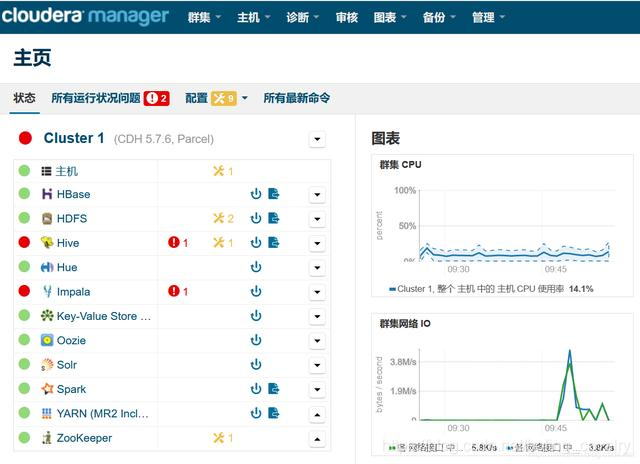
Hive报错
- 如下图红框所示,Hive启动失败,日志中提示Version information not found in metastore
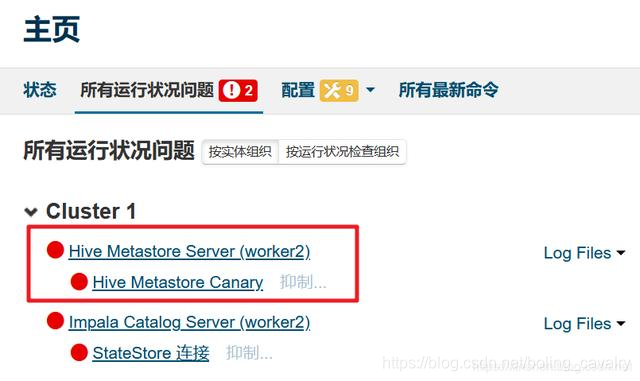
-
从上图可见Hive服务在worker2上,于是SSH登录worker2,将/usr/share/java目录下的mysql-connector-java.jar文件复制到这个目录下:/opt/cloudera/parcels/CDH-5.7.6-1.cdh5.7.6.p0.6/lib/hive/lib/
-
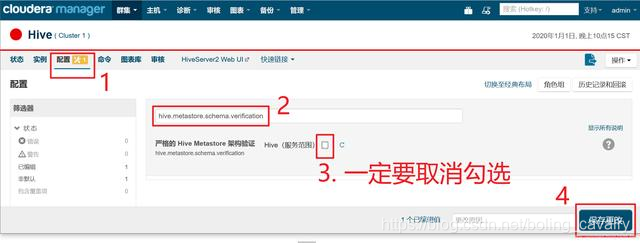
在Hive的配置页面,搜索"hive.metastore.schema.verification",如下图,确保红框3中的复选框取消勾选:
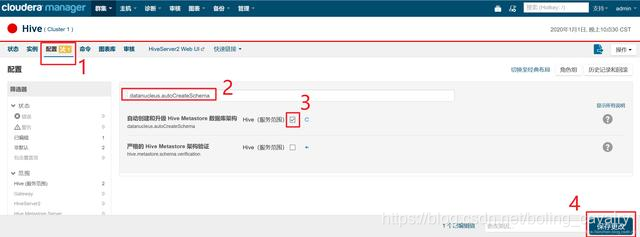
- 修改配置datanucleus.autoCreateSchema,如下图,确保红框3中的复选框被选中:
- 重启完成后,Hive状态为健康:
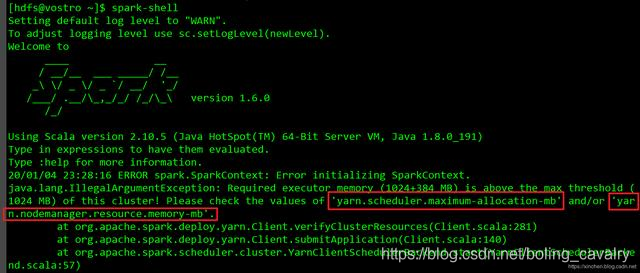
spark-shell执行失败
- 在worker1或者worker2上执行spark-shell命令进入spark控制台时,会产生内存相关的错误,需要调整YARM相关的内存参数:
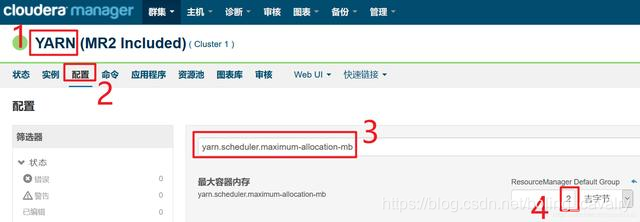
- 在YARN的配置页面,调整yarn.scheduler.maximum-allocation-mb和yarn.nodemanager.resource.memory-mb这两个参数的值,原有的值都是1G,现在都改成2G,如下图:
-
重启YARN;
-
重启Spark;
-
执行spark-shell命令之前,先执行命令su - hdfs切换到hdfs账号;
-
这次终于成功进入spark-shell交互模式:
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,不论你是刚入门Java开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!**
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!















 426
426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









