







- 非分片表
一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。
- ER 表
关系型数据库是基于实体关系模型之上,通过其描述了真实世界中事物与关系,Mycat 中的 ER 表即是来源于此。根据这一思路,提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上,即子表依赖于父表,通过表分组保证数据 join 不会跨库操作。
表分组是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的重要一条规则。
- 全局表
一个真实的业务系统中,往往存在大量的类似字典表的表,这些表基本上很少变动,字典表具有以下几个特性:
-
变动不频繁
-
数据量总体变化不大
-
数据规模不大,很少有超过数十万条记录
对于这类的表,在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较棘手的问题,所以 MyCat 中通过数据冗余来解决这类表的 join ,即所有的分片都有一份数据的拷贝,所有将字典表或者符合字典表特性的一些表定义为全局表。
数据冗余是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的另外一条重要规则。
分片节点
数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节点(dataNode)。
节点主机
数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。
分片规则
前面讲了数据切分,一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度。
MyCat 提供的分片规则有如下几种:
-
分片枚举
-
固定分片 hash 算法
-
范围约定
-
取模
-
按日期(天)分片
-
取模范围约束
-
截取数字做 hash 求模范围约束
-
应用指定
-
截取数字 hash 解析
-
一致性 hash
-
按单月小时拆分
-
范围求模分片
-
日期范围 hash 分片
-
冷热数据分片
-
自然月分片
实践
==
这里向大家简单介绍 5 种规则。
global
有一些表,数据量不大,也不怎么修改,主要是查询操作,例如系统配置表,这一类表我们可以使用 global 这种分片规则。global 的特点是,该表会在所有的库中都创建,而且每一个库中都保存了该表的完整数据。具体配置方式,就是在 schema.xml 的 table 节点中添加一个 type 属性,值为 global:

配置完成后,重启 mycat
./bin/mycat restart
重启完成后,要删除之前已经创建的 t_user 表,然后重新创建表,创建完成后,向表中插入数据,可以看到,db1、db2 以及 db3 中都有数据了。
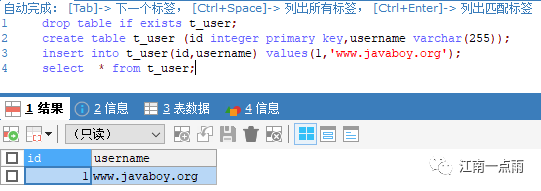
这里 虽然查询出来的记录只有一条,实际上 db1、db2 以及 db3 中都有该条记录。
总结:global 适合于 数据量不大、以查询为主、增删改较少的表。
sharding-by-intfile
sharding-by-intfile 这个是枚举分片,就是在数据表中专门设计一个字段,以后根据这个字段的值来决定数据插入到哪个 dataNode 上。
注意,在配置 sharding-by-intfile 规则时,一定要删除 type=“global” ,否则配置不会生效。具体配置如下:

配置完成后,还需要指定枚举的数据。枚举的数据可以在 rule.xml 中查看。
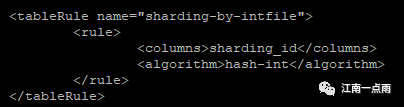
在 rule.xml 文件中,首先找到 tableRule 的名字为 sharding-by-intfile 的节点,这个节点中定义了两个属性,一个是 columns 表示一会在数据表中定义的枚举列的名字(数据表中一会需要创建一个名为 sharding_id 的列,这个列的值决定了该条数据保存在哪个数据库实例中),这个名字可以自定义;另外一个属性叫做 algorithm ,这是指 sharding-by-intfile 所对应的算法名称。根据这个名称,可以找到具体的算法:

还是在 rule.xml 文件中,我们找到了 hash-int ,class 表示这个算法对应的 Java 类的路径。第一个属性 mapFile 表示相关的配置文件,从这个文件名可以看出,这个文件 就在 conf 目录下。
打开 conf 目录下的 partition-hash-int.txt 文件,内容如下:
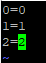
前面的数字表示枚举的值 ,后面的数字表示 dataNode 的下标,所以前面的数字可以自定义,后面的数字不能随意定义。
配置完成后,重启 MyCat ,然后进行测试:
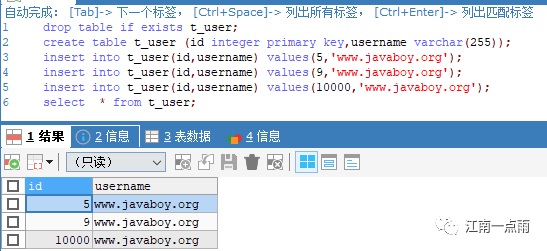
drop table if exists t_user;
create table t_user (id integer primary key,username varchar(255),sharding_id integer);
insert into t_user(id,username,sharding_id) values(1,‘www.javaboy.org’,0);
insert into t_user(id,username,sharding_id) values(1,‘www.javaboy.org’,1);
insert into t_user(id,username,sharding_id) values(1,‘www.javaboy.org’,2);
select * from t_user;
执行完后,sharding_id 对应值分别为 0 、1 、2 的记录分别插入到 db1 、db2 以及 db3 中。
auto-sharding-long
auto-sharding-long 表示按照既定的范围去存储数据。就是提前规划好某个字段的值在某个范围时,相应的记录存到某个 dataNode 中。
配置方式,首先修改路由规则:

然后去 rule.xml 中查看对应的算法了规则相关的配置:
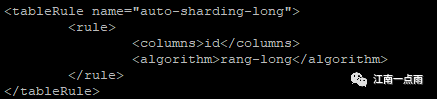
可以看到,默认是按照 id 的范围来划分数据的存储位置的,对应的算法就是 rang-long 。
继续查看,可以找到算法对应的类,以及相关的配置文件,这个配置文件也在 conf 目录下,打开该文件:
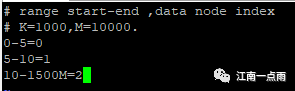
如上配置,表示 当 id 的取值在 0-5之间时,将数据存储到 db1 中,当 id 在 5-10 之间时,存储到 db2 中,当 id 的取值在 10-1500W 之间时,存储到 db3 中。
配置完成后,重启 MyCat ,测试:

mod-long
取模:根据表中的某一个字段,做取模操作。根据取模的结果将记录存放在不同的 dataNode 上。这种方式不需要再添加额外字段。

然后去 rule.xml 中配置一下 dataNode 的个数。
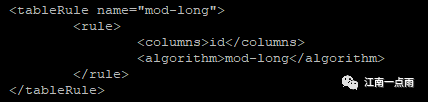
可以看到,取模的字段是 id ,取模的算法名称是 mod-long ,再看具体的算法:

在具体的算法中,配置了 dataNode 的个数为 3。
然后保存退出,重启 MyCat,进行测试:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

总结
阿里伤透我心,疯狂复习刷题,终于喜提offer 哈哈~好啦,不闲扯了

1、JAVA面试核心知识整理(PDF):包含JVM,JAVA集合,JAVA多线程并发,JAVA基础,Spring原理,微服务,Netty与RPC,网络,日志,Zookeeper,Kafka,RabbitMQ,Hbase,MongoDB,Cassandra,设计模式,负载均衡,数据库,一致性哈希,JAVA算法,数据结构,加密算法,分布式缓存,Hadoop,Spark,Storm,YARN,机器学习,云计算共30个章节。

2、Redis学习笔记及学习思维脑图
3、数据面试必备20题+数据库性能优化的21个最佳实践

《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
*,负载均衡,数据库,一致性哈希,JAVA算法,数据结构,加密算法,分布式缓存,Hadoop,Spark,Storm,YARN,机器学习,云计算共30个章节。
[外链图片转存中…(img-iCLqdiZf-1713710717619)]
2、Redis学习笔记及学习思维脑图
[外链图片转存中…(img-D7S892W3-1713710717620)]
3、数据面试必备20题+数据库性能优化的21个最佳实践
[外链图片转存中…(img-Z6OJ2L3u-1713710717620)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!

















 1293
1293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









