







Spark UI如何高效地定位性能问题(下)
上一讲,我们一起梳理了 Spark UI 的一级入口。其中 Executors、Environment、Storage 是详情页,开发者可以通过这 3 个页面,迅速地了解集群整体的计算负载、运行环境,以及数据集缓存的详细情况。不过 SQL、Jobs、Stages,更多地是一种罗列式的展示,想要了解其中的细节,还需要进入到二级入口。
所谓二级入口,它指的是,通过一次超链接跳转才能访问到的页面。对于 SQL、Jobs 和 Stages 这 3 类入口来说,二级入口往往已经提供了足够的信息,基本覆盖了“体检报告”的全部内容。因此,尽管 Spark UI 也提供了少量的三级入口(需要两跳才能到达的页面),但是这些隐藏在“犄角旮旯”的三级入口,往往并不需要开发者去特别关注。
接下来,我们就沿着 SQL -> Jobs -> Stages 的顺序,依次地去访问它们的二级入口,从而针对全局 DAG、作业以及执行阶段,获得更加深入的探索与洞察。
SQL 详情页
在 SQL Tab 一级入口,我们看到有 3 个条目,分别是 count(统计申请编号)、count(统计中签编号)和 save。前两者的计算过程,都是读取数据源、缓存数据并触发缓存的物化,相对比较简单,因此,我们把目光放在 save 这个条目上。
点击图中的“save at:27”,即可进入到该作业的执行计划页面,如下图所示。
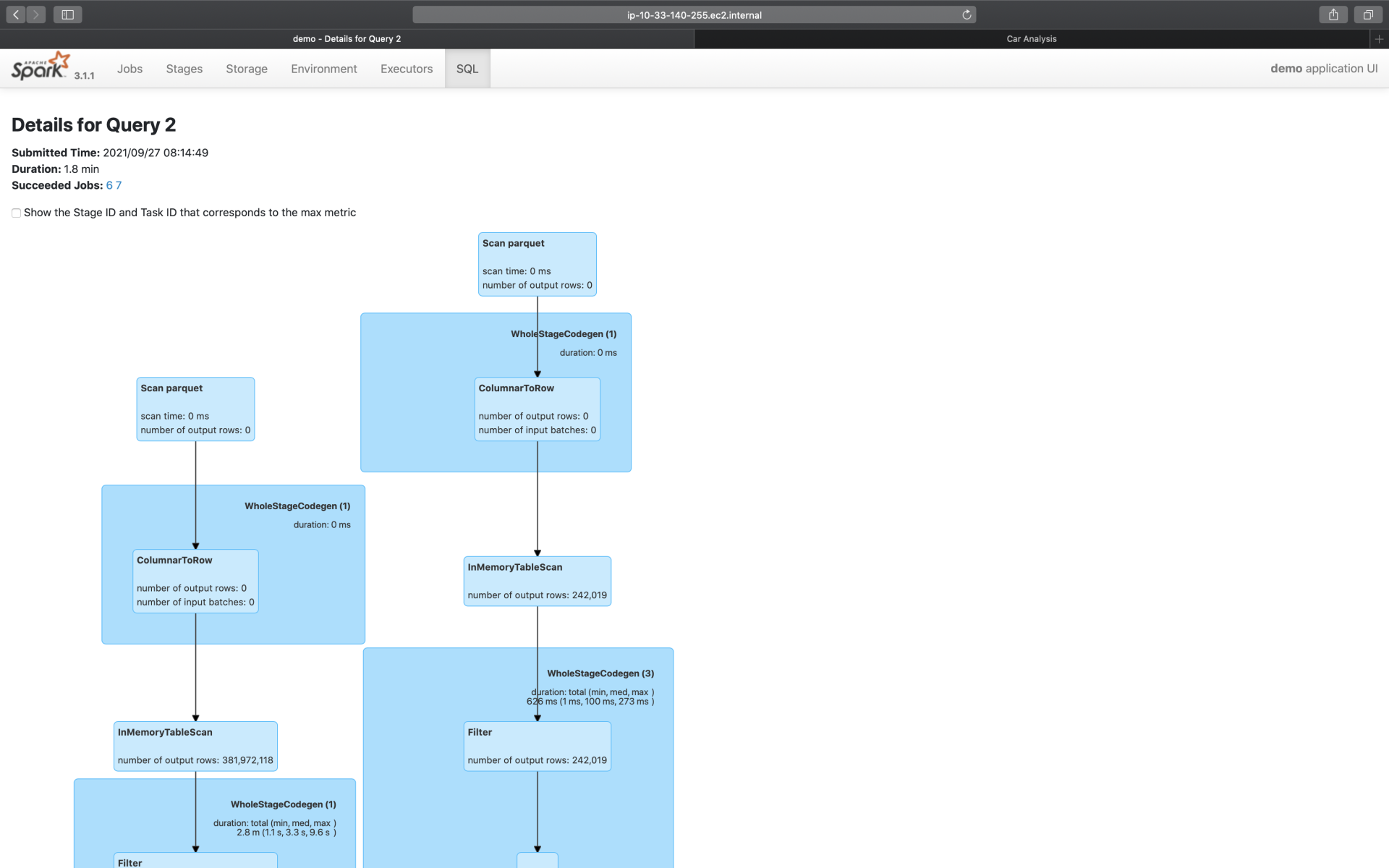
为了聚焦重点,这里我们仅截取了部分的执行计划,想要获取完整的执行计划,你可以通过访问这里来获得。为了方便你阅读,这里我手绘出了执行计划的示意图,供你参考,如下图所示。
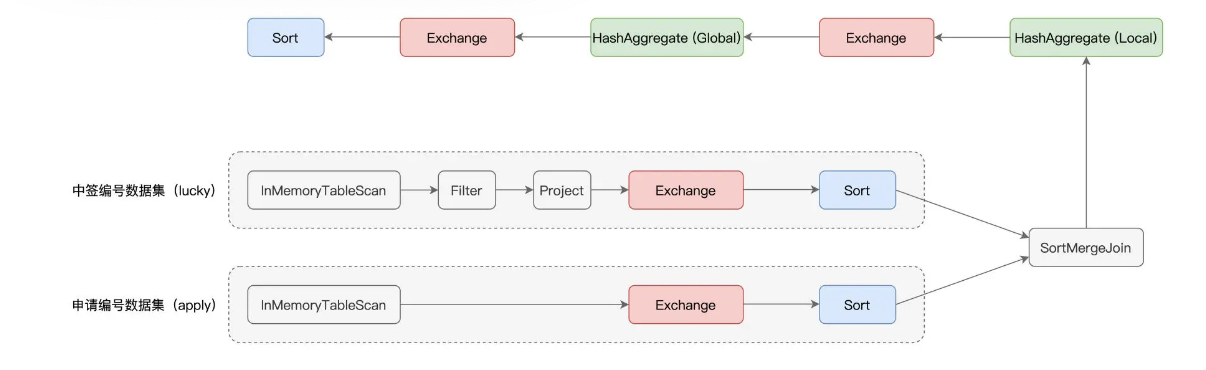
可以看到,“倍率与中签率分析”应用的计算过程,非常具有代表性,它涵盖了数据分析场景中大部分的操作,也即过滤、投影、关联、分组聚合和排序。图中红色的部分为 Exchange,代表的是 Shuffle 操作,蓝色的部分为 Sort,也就是排序,而绿色的部分是 Aggregate,表示的是(局部与全局的)数据聚合。
无疑,这三部分是硬件资源的主要消费者,同时,对于这 3 类操作,Spark UI 更是提供了详细的 Metrics 来刻画相应的硬件资源消耗。接下来,咱们就重点研究一下这 3 类操作的度量指标
Exchange
下图中并列的两个 Exchange,对应的是示意图中 SortMergeJoin 之前的两个 Exchange。它们的作用是对申请编码数据与中签编码数据做 Shuffle,为数据关联做准备。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









