







Spark UI如何高效地定位性能问题(上)
前面我们介绍了基础知识和 Spark SQL 这两个模块的学习,这也就意味着,我们完成了 Spark 入门“三步走”中的前两步,首先恭喜你!在学习的过程中,我们逐渐意识到,Spark Core 与 Spark SQL 作为 Spark 并驾齐驱的执行引擎与优化引擎,承载着所有类型的计算负载,如批处理、流计算、数据分析、机器学习,等等。
Spark Core 与 Spark SQL 运行得是否稳定与高效,决定着 Spark 作业或是应用的整体“健康状况”。不过,在日常的开发工作中,我们总会遇到 Spark 应用运行失败、或是执行效率未达预期的情况。对于这类问题,想找到根本原因(Root Cause),我们往往需要依赖 Spark UI 来获取最直接、最直观的线索。
如果我们把失败的、或是执行低效的 Spark 应用看作是“病人”的话,那么 Spark UI 中关于应用的众多度量指标(Metrics),就是这个病人的“体检报告”。结合多样的 Metrics,身为“大夫”的开发者即可结合经验来迅速地定位“病灶”。
这里需要说明的是,Spark UI 的讲解涉及到大量的图解、代码与指标释义,内容庞杂。因此,为了减轻你的学习负担,我按照 Spark UI 的入口类型(一级入口、二级入口)把 Spark UI 拆成了上、下两讲。一级入口比较简单、直接,我们今天这一讲,先来讲解这一部分,二级入口的讲解留到下一讲去展开。
准备工作
在正式开始介绍 Spark UI 之前,我们先来简单交代一下图解案例用到的环境、配置与代码。你可以参考这里给出的细节,去复现“倍率与中签率分析”案例 Spark UI 中的每一个界面,然后再结合今天的讲解,以“看得见、摸得着”的方式,去更加直观、深入地熟悉每一个页面与度量指标。
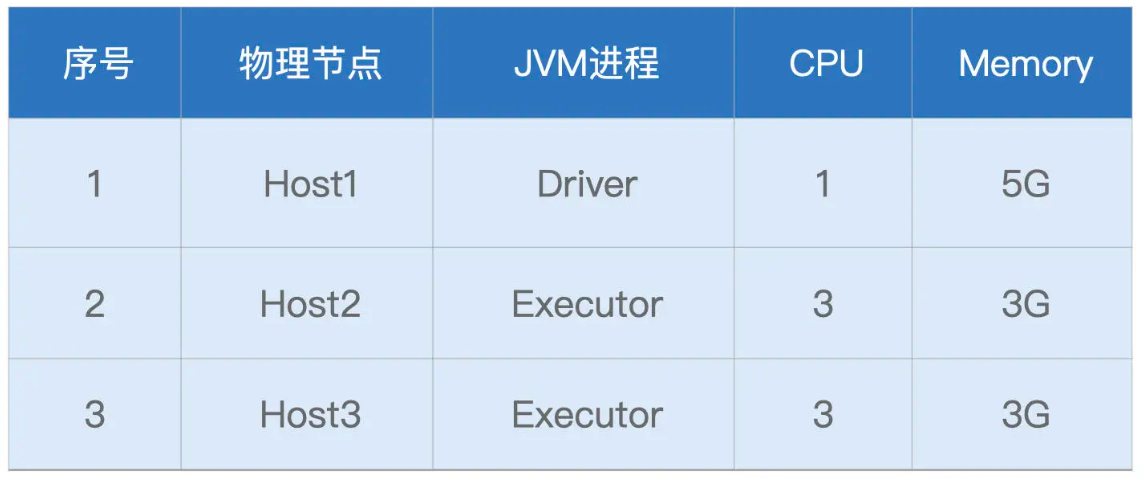
当然,如果你手头一时没有合适的执行环境,也不要紧。咱们这一讲的特点,就是图多,后面我特意准备了大量的图片和表格,带你彻底了解 Spark UI。由于小汽车摇号数据体量不大,因此在计算资源方面,我们的要求并不高,“倍率与中签率分析”案例用到的资源如下所示:
import org.apache.spark.sql.DataFrame
val rootPath: String = _
// 申请者数据
val hdfs_path_apply: String = s"${rootPath}/apply"
// spark是spark-shell中默认的SparkSession实例
// 通过read API读取源文件
val applyNumbersDF: DataFrame = spark.read.parquet(hdfs_path_apply)
// 中签者数据
val hdfs_path_lucky: String = s"${rootPath}/lucky"
// 通过read API读取源文件
val luckyDogsDF: DataFrame = spark.read.parquet(hdfs_path_lucky)
// 过滤2016年以后的中签数据,且仅抽取中签号码 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









