







Spark MLlib 特征工程(下)
前面我们提到,典型的特征工程包含如下几个环节,即预处理、特征选择、归一化、离散化、Embedding 和向量计算,如下图所示。
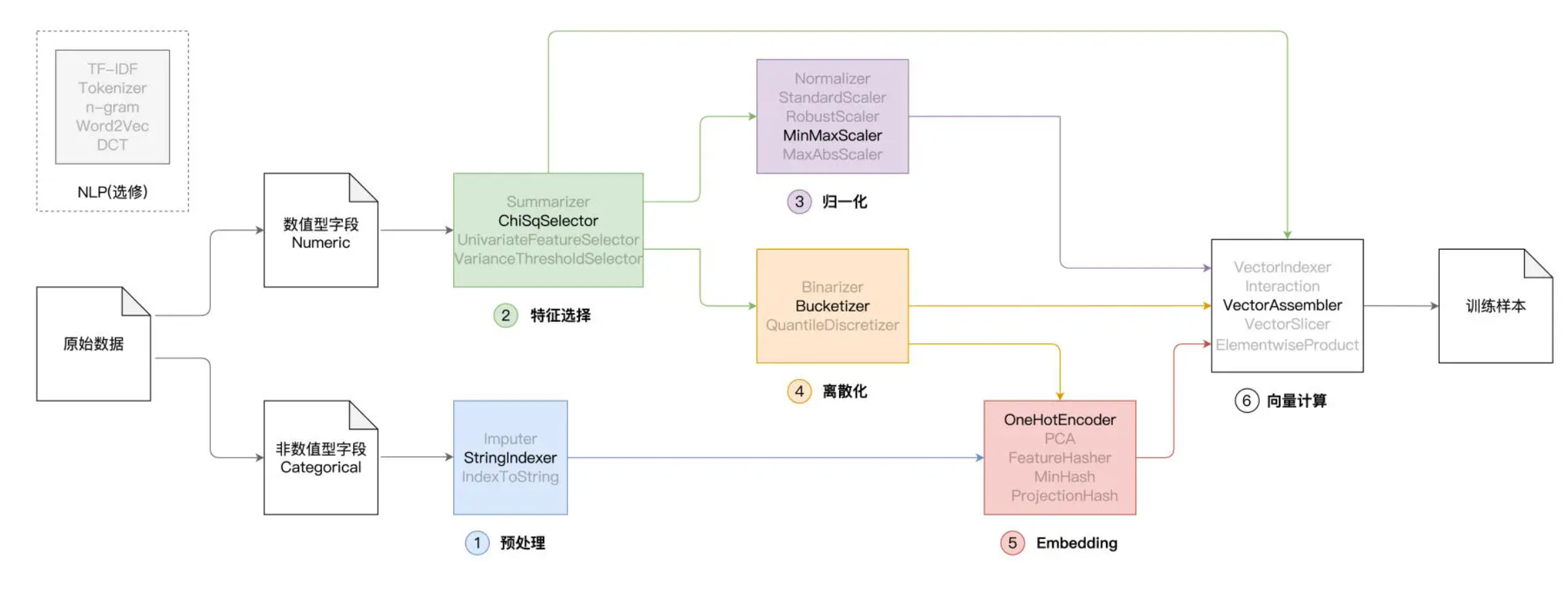
在上一讲,我们着重讲解了其中的前 3 个环节,也就是预处理、特征选择和归一化,今天这一讲,咱们继续来说说剩下的离散化、Embedding 与向量计算。
特征工程
离散化:Bucketizer
与归一化一样,离散化也是用来处理数值型字段的。离散化可以把原本连续的数值打散,从而降低原始数据的多样性(Cardinality)。举例来说,“BedroomAbvGr”字段的含义是居室数量,在 train.csv 这份数据样本中,“BedroomAbvGr”包含从 1 到 8 的连续整数。
现在,我们根据居室数量,把房屋粗略地划分为小户型、中户型和大户型
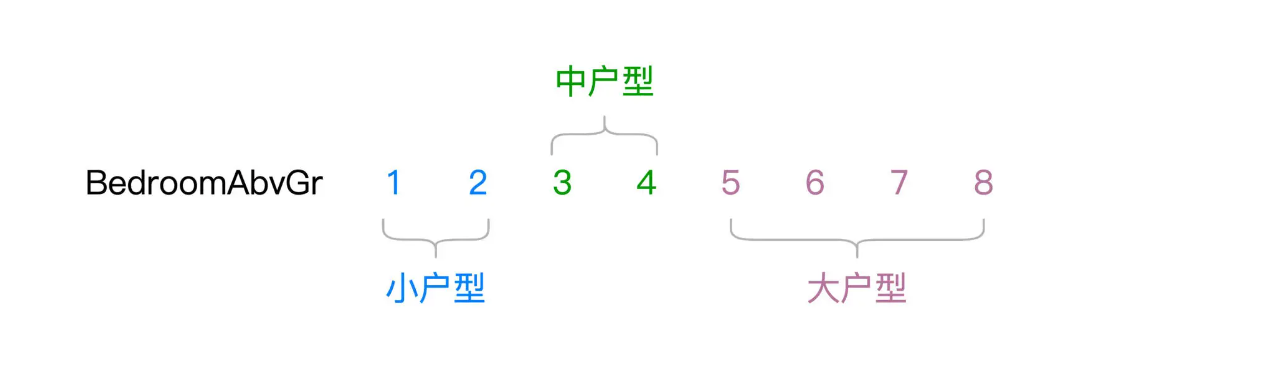
不难发现,“BedroomAbvGr”离散化之后,数据多样性由原来的 8 降低为现在的 3。那么问题来了,原始的连续数据好好的,为什么要对它做离散化呢?离散化的动机,主要在于提升特征数据的区分度与内聚性,从而与预测标的产生更强的关联。
就拿“BedroomAbvGr”来说,我们认为一居室和两居室对于房价的影响差别不大,同样,三居室和四居室之间对于房价的影响,也是微乎其微。但是,小户型与中户型之间,以及中户型与大户型之间,房价往往会出现跃迁的现象。换句话说,相比居室数量,户型的差异对于房价的影响更大、区分度更高。因此,把“BedroomAbvGr”做离散化处理,目的在于提升它与预测标的之间的关联性。
那么,在 Spark MLlib 的框架下,离散化具体该怎么做呢?与其他环节一样,Spark MLlib 提供了多个离散化函数,比如 Binarizer、Bucketizer 和 QuantileDiscretizer。我们不妨以 Bucketizer 为代表,结合居室数量“BedroomAbvGr”这个字段,来演示离散化的具体用法。
// 原始字段
val fieldBedroom: String = "BedroomAbvGrInt"
// 包含离散化数据的目标字段
val fieldBedroomDiscrete: String = "BedroomDiscrete"
// 指定离散 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 28
28

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









