







Spark MLlib模型训练—聚类系列算法
与监督学习相对,非监督学习,泛指那些数据样本中没有 Label 的机器学习问题。
以房屋数据为例,整个数据集包含 79 个字段。如果我们把“SalePrice”和“OverallQual”这两个字段抹掉,那么原始数据集就变成了不带 Label 的数据样本。你可能会好奇:“对于这些没有 Label 的样本,我们能拿他们做些什么呢?”
其实能做的事情还真不少,基于房屋数据,我们可以结合“物以类聚”的思想,使用 K-means 算法把他们进行分门别类的处理。再者,在下一讲电影推荐的例子中,我们还可以基于频繁项集算法,挖掘出不同电影之间共现的频次与关联规则,从而实现推荐。
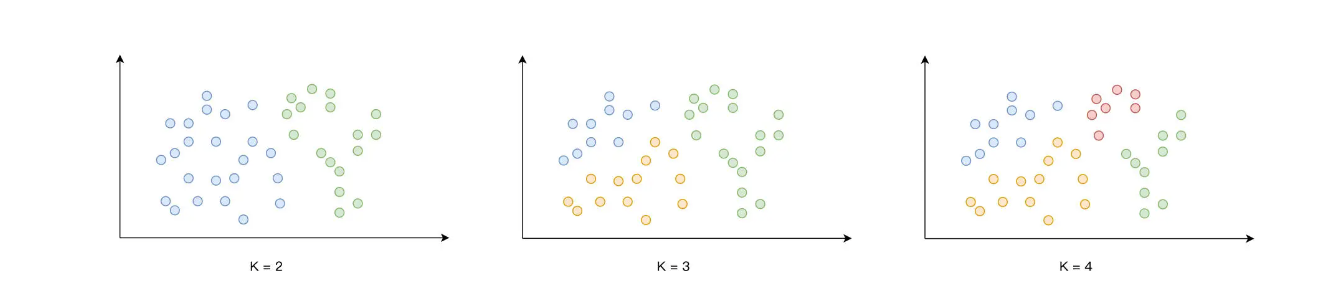
今天我们先来讲 K-mean,结合数据样本的特征向量,根据向量之间的相对距离,K-means 算法可以把所有样本划分为 K 个类别,这也是算法命名中“K”的由来。举例来说,图中的每个点,都代表一个向量,给定不同的 K 值,K-means 划分的结果会随着 K 的变化而变化。
import org.apache.spark.ml.feature.VectorAssembler
val assembler = new VectorAssembler()
// numericFields包含连续特征,oheFields为离散特征的One hot编码
.setInputCols(numericFields ++ oheFields)
.setOutputCol("features")
接下来,在第二个环节,我们来定义 K-means 模型,并使用刚刚准备好的样本,去做模型训练。可以看到,模型定义非常简单,只需实例化 KMeans 对象,并通过 setK 指定 K 值即可。
import org.apache.spark.ml.clustering.KMeans
val kmeans = new KMeans().setK(20)
val Array(trainingSet, testSet) = engineeringDF
.select("features")
.randomSplit(Array(0.7, 0.3))
val model = kmeans.fit(trainingSet)
这里,我们准备把不同的房屋划分为 20 个不同的类别。完成训练之后,我们同样需要对模型效果进行评估。由于数据样本没有 Label,因此,先前回归与分类的评估指标,不适合像 K-means 这样的非监督学习算法。
K-means 的设计思想是“物以类聚”,既然如此,那么同一个类别中的向量应该足够地接近,而不同类别中向量之间的距离,应该越远越好。因此,我们可以用距离类的度量指标(如欧氏距离)来量化 K-means 的模型效果。
import org.apache.spark.ml.evaluation.ClusteringEvaluator
val predictions = model.transform(trainingSet)
// 定义聚类评估器
val evaluator = new ClusteringEvaluator()
// 计算所有向量到分类中心点的欧氏距离
val euclidean = evaluator.evaluate(predictions)
好啦,到此为止,我们使用非监督学习算法 K-means,根据房屋向量,对房屋类型进行了划分。不过你要注意,使用这种方法划分出的类型,是没有真实含义的,比如它不能代表房屋质量,也不能代表房屋评级。既然如此,我们用 K-means 忙活了半天,图啥呢?
尽管 K-means 的结果没有真实含义,但是它以量化的形式,刻画了房屋之间的相似性与差异性。你可以这样来理解,我们用 K-means 为房屋生成了新的特征,相比现有的房屋属性,这个生成的新特征(Generated Features)往往与预测标的(如房价、房屋类型)有着更强的关联性,所以让这个新特性参与到监督学习的训练,就有希望优化 / 提升监督学习的模型效果。
这里为了大家方便学习,我给出完整的代码
// 从CSV文件创建DataFrame
val trainDF: DataFrame = spark.read.format("csv").option("header", true).load(filePath)
// 将engineeringDF定义为var变量,后续所有的特征工程都作用在这个DataFrame之上
var engineeringDF=trainDF
// 所有数值型字段,共有27个
val numericFields: Array[String] = Arra 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 367
367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









