







Spark Structured Streaming 概论
与以往任何时候都不同,今天的大数据处理,对于延迟性的要求越来越高,因此流处理的基本概念与工作原理,是每一个大数据从业者必备的“技能点”。
在这个模块中,按照惯例,我们还是从一个可以迅速上手的实例开始,带你初步认识 Spark 的流处理框架 Structured Streaming。然后,我们再从框架所提供的能力、特性出发,深入介绍 Structured Streaming 工作原理、最佳实践以及开发注意事项,等等。
这一节一直围绕着 Word Count 在打转,也就是通过从文件读取内容,然后以批处理的形式,来学习各式各样的数据处理技巧。而今天这一讲我们换个花样,从一个“流动的 Word Count”入手,去学习一下在流计算的框架下,Word Count 是怎么做的。
环境准备
要上手今天的实例,你只需要拥有 Spark 本地环境即可,并不需要分布式的物理集群。不过,咱们需要以“流”的形式,为 Spark 提供输入数据,因此,要完成今天的实验,我们需要开启两个命令行终端。一个用于启动 spark-shell,另一个用于开启 Socket 端口并输入数据,如下图所示。
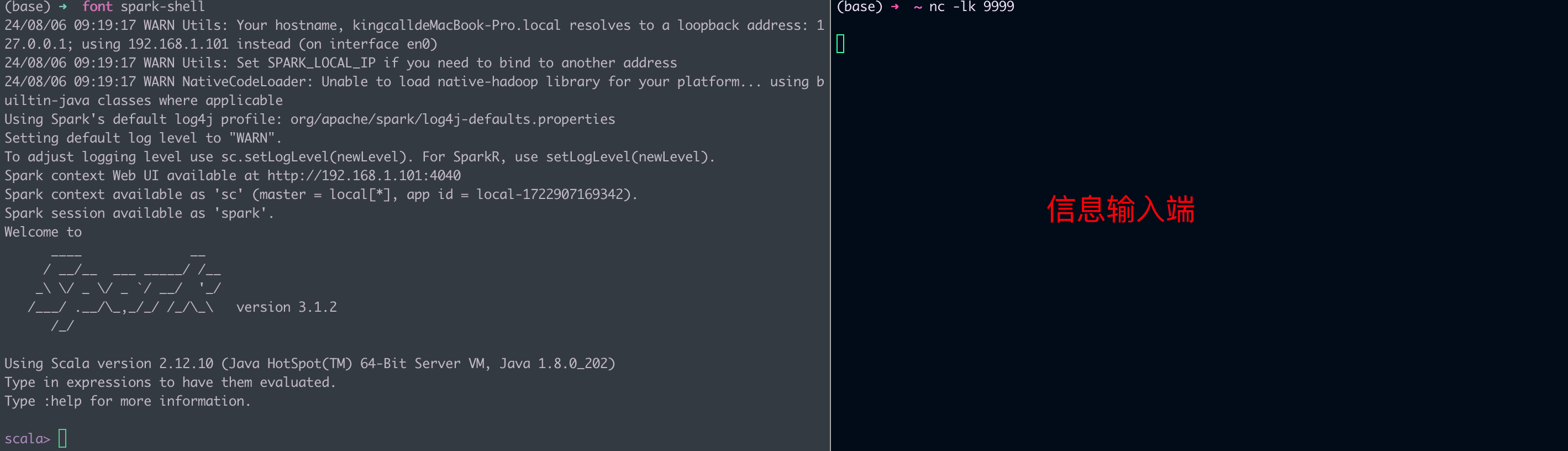
流动的 Word Count
环境准备好之后,接下来,我们具体来说一说,什么是“流动的 Word Count”。
所谓没有对比就没有鉴别,为了说清楚“流动的 Word Count”,咱们不妨拿批处理版本的 Word Count 作对比。在之前的 Word Count 中,数据以文件(wikiOfSpark.txt)的形式,一次性地“喂给”Spark,从而触发一次 Job 计算。而在“流动的 Word Count”里,数据以行为粒度,分批地“喂给”Spark,每一行数据,都会触发一次 Job 计算。
具体来说,我们使用 netcat 工具,向本地 9999 端口的 Socket 地址发送数据行。而 Spark 流处理应用,则时刻监听着本机的 9999 端口,一旦接收到数据条目,就会立即触发计算逻辑的执行。当然,在我们的示例中,这里的计算逻辑,就是 Word Count。计算执行完毕之后,流处理应用再把结果打印到终端(Console)上。
与批处理不同,只要我们不人为地中断流处理应用,理论上它可以一直运行到永远。以“流动的 Word Count”为例,只要我们不强制中断它,它就可以一直监听 9999 端口,接收来自那里的数据,并以实时的方式处理它。
首先第一步,我们在第二个用来输入数据的终端敲入命令“nc -lk 9999”,也就是使用 netcat 工具,开启本机 9999 端口的 Socket 地址。一般来说,大多数操作系统都预装了 netcat 工具,因此,不论你使用什么操作系统,应该都可以成功执行上述命令。
命令敲击完毕之后,光标会在屏幕上一直闪烁,这表明操作系统在等待我们向 Socket 地址发送数据。我们暂且把它搁置在这里,等一会流处理应用实现完成之后,再来处理它。
这里我们要提示一下就是你要先启动NC 也就是端口服务,不然Spark 可能会报错,也就是说如果你遇到了这个java.net.Connect
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









