







Spark StructStreaming Batch mode和Continuous mode
上一节我们介绍了 Structured Streaming,并学习了流处理开发三要素,也就是 Source、流处理引擎与 Sink。

让我们把目光集中到 Structured Streaming,也就是流处理引擎本身。Structured Streaming 与 Spark MLlib 并列,是 Spark 重要的子框架之一。值得一提的是,Structured Streaming 天然能够享受 Spark SQL 提供的处理能力与执行性能,同时也能与其他子框架无缝衔接。因此,基于 Structured Streaming 这个新一代框架开发的流处理应用,天然具备优良的执行性能与良好的扩展性。
知己知彼,百战百胜。想要灵活应对不同的实时计算需求,我们就要先了解 Structured Streaming 的计算模型长啥样,搞清楚它如何应对容错、保持数据一致性。我们先从计算模型说起。
计算模型
当数据像水流一样,源源不断地流进 Structured Streaming 引擎的时候**,引擎并不会自动地依次消费并处理这些数据,它需要一种叫做 Trigger 的机制,来触发数据在引擎中的计算**。
换句话说,Trigger 机制,决定了引擎在什么时候、以怎样的方式和频率去处理接收到的数据流。Structured Streaming 支持 4 种 Trigger,如下表所示。

要为流处理设置 Trigger,我们只需基于 writeStream API,调用 trigger 函数即可。Trigger 的种类比较多,一下子深入细节,容易让你难以把握重点,所以现在你只需要知道 Structured Streaming 支持种类繁多的 Trigger 即可。
我们先把注意力,放在计算模型上面。对于流数据,Structured Streaming 支持两种计算模型,分别是 Batch mode 和 Continuous mode。所谓计算模型,本质上,它要解决的问题,就是 Spark 以怎样的方式,来对待并处理流数据。
这是什么意思呢?没有对比就没有鉴别,咱们不妨通过对比讲解 Batch mode 和 Continuous mode,来深入理解计算模型的含义。
Batch mode
我们先来说说 Batch mode,所谓 Batch mode,它指的是 Spark 将连续的数据流,切割为离散的数据微批(Micro-batch),也即小份的数据集。
形象一点说,Batch mode 就像是“抽刀断水”,两刀之间的水量,就是一个 Micro-batch。而每一份 Micro-batch,都会触发一个 Spark Job,每一个 Job 会包含若干个 Tasks。学习过基础知识与 Spark SQL 模块之后,我们知道,这些 Tasks 最终会交由 Spark SQL 与 Spark Core 去做优化与执行。
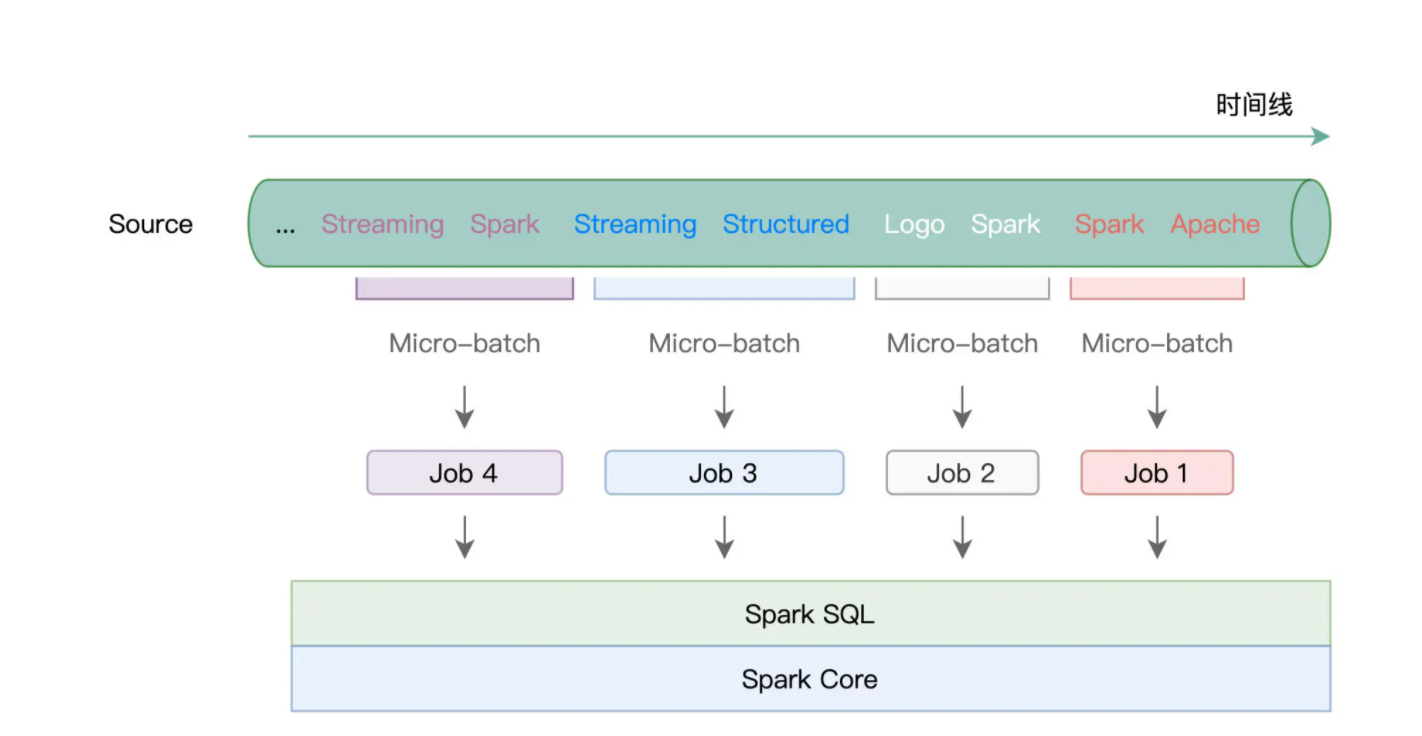
在这样的计算模型下,不同种类的 Trigger
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









