








1.2.2 聚合结果排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序。
我们可以指定order属性,自定义聚合的排序方式:
GET /hotel/_search
{
“size”: 0,
“aggs”: {
“brandAgg”: {
“terms”: {
“field”: “brand”,
“order”: {
“_count”: “asc” // 按照_count升序排列
},
“size”: 20
}
}
}
}
1.2.3 限定聚合范围
默认情况下,Bucket聚合是对索引库的所有文档做聚合,但真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。
我们可以限定要聚合的文档范围,只要添加query条件即可:
GET /hotel/_search
{
“query”: {
“range”: {
“price”: {
“lte”: 200 // 只对200元以下的文档聚合
}
}
},
“size”: 0,
“aggs”: {
“brandAgg”: {
“terms”: {
“field”: “brand”,
“size”: 20
}
}
}
}
这次,聚合得到的品牌明显变少了:
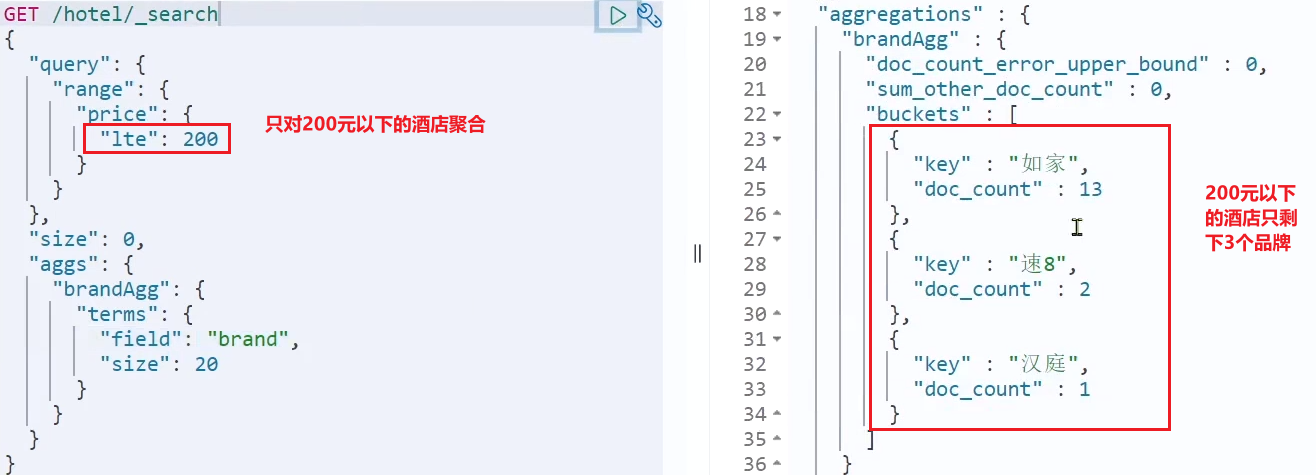
1.2.4.Metric聚合语法
上节课,我们对酒店按照品牌分组,形成了一个个桶。现在我们需要对桶内的酒店做运算,获取每个品牌的用户评分的min、max、avg等值。
这就要用到Metric聚合了,例如stat聚合:就可以获取min、max、avg等结果。
GET /hotel/_search
{
“size”: 0,
“aggs”: {
“brandAgg”: {
“terms”: {
“field”: “brand”,
“size”: 20
},
“aggs”: { // 是brands聚合的子聚合,也就是分组后对每组分别计算
“score_stats”: { // 聚合名称
“stats”: { // 聚合类型,这里stats可以计算min、max、avg等
“field”: “score” // 聚合字段,这里是score
}
}
}
}
}
}
这次的score_stats聚合是在brandAgg的聚合内部嵌套的子聚合。因为我们需要在每个桶分别计算。
另外,我们还可以给聚合结果做个排序,例如按照每个桶的酒店平均分做排序:
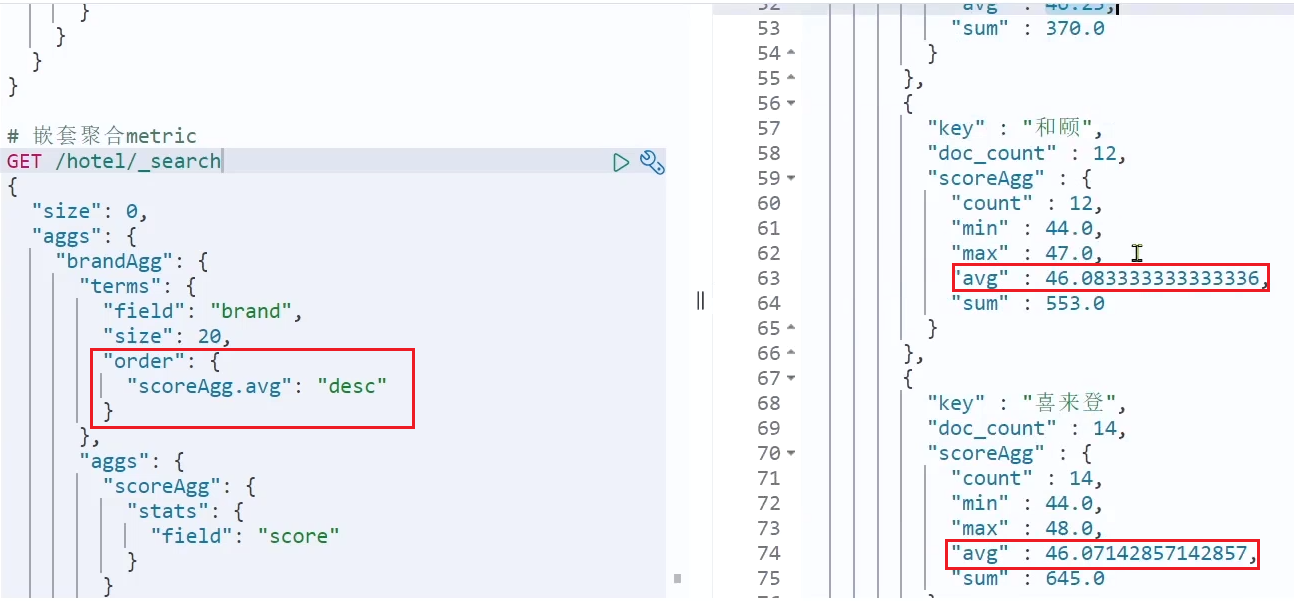
1.2.5 总结
aggs代表聚合,与query同级,此时query的作用是?
- 限定聚合的的文档范围
聚合必须的三要素:
-
聚合名称
-
聚合类型
-
聚合字段
聚合可配置属性有:
-
size:指定聚合结果数量 -
order:指定聚合结果排序方式 -
field:指定聚合字段
1.3 RestAPI实现聚合
聚合条件与query条件同级别,因此需要使用request.source()来指定聚合条件。
聚合条件的语法:
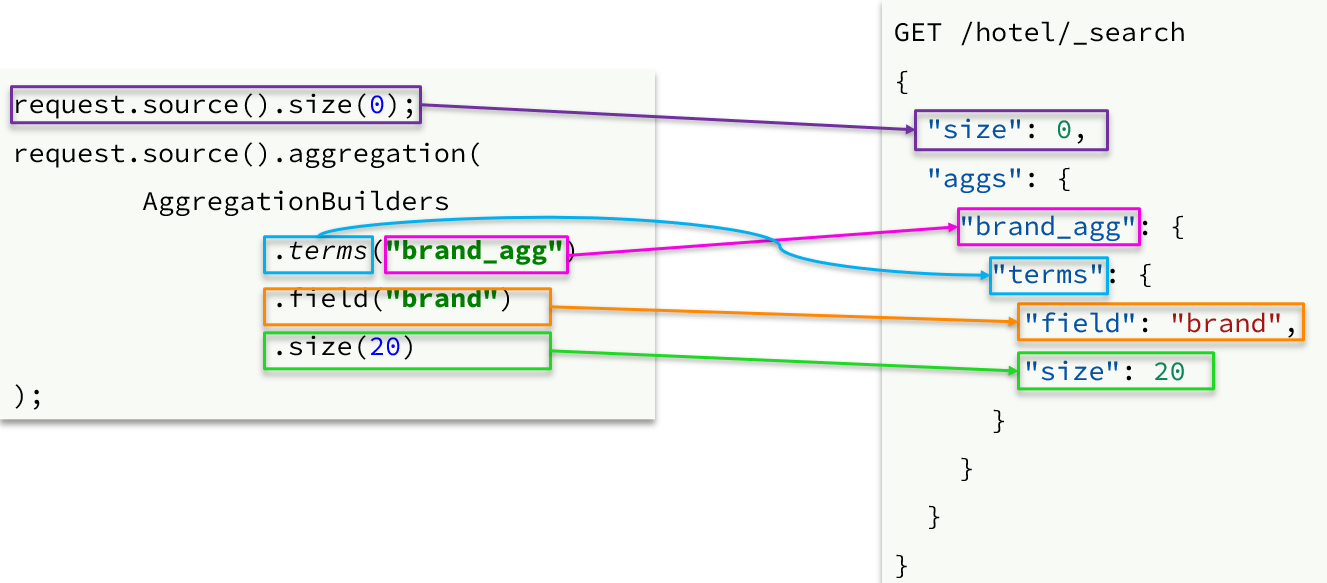
聚合的结果也与查询结果不同,API也比较特殊。不过同样是JSON逐层解析:
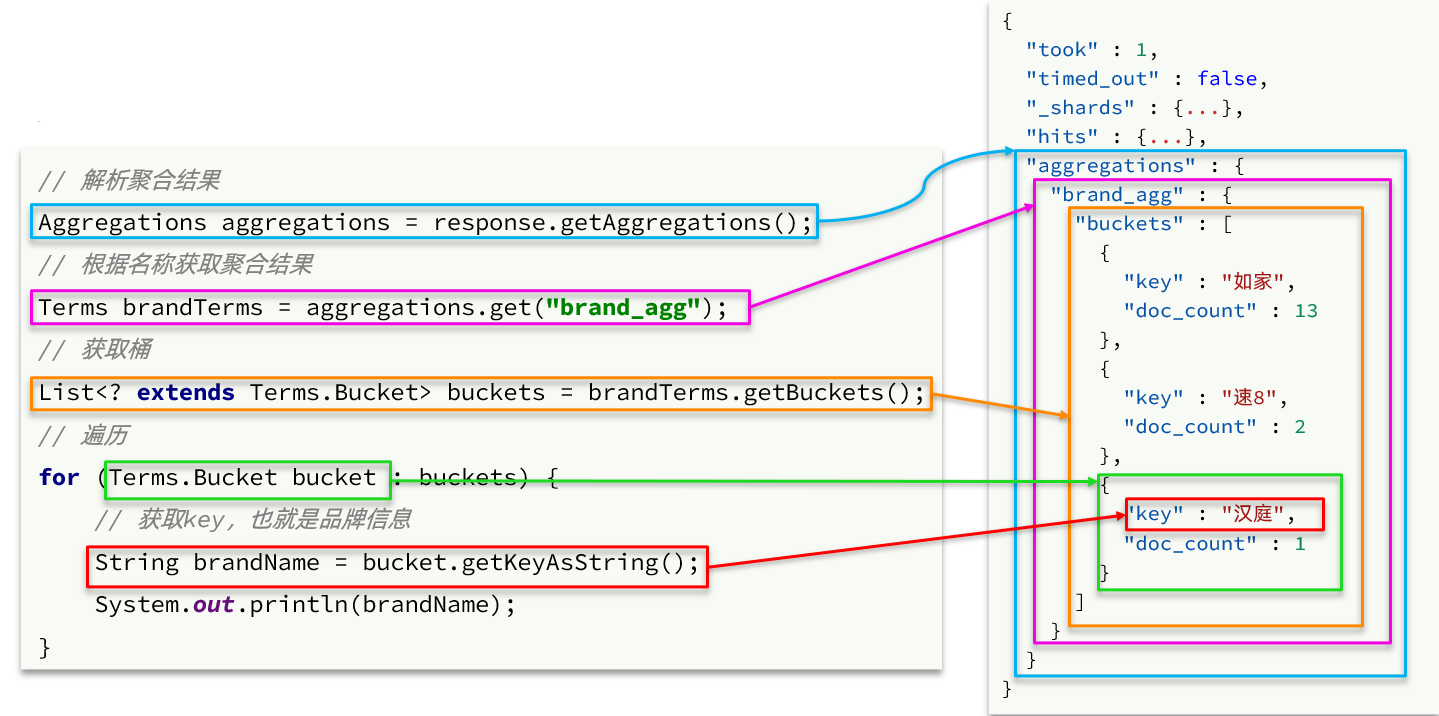
代码如下:
//聚合
@Test
void testAggregation() throws IOException {
//1.准备Request
SearchRequest request = new SearchRequest(“hotel”);
//2.准备DSL
request.source().size(0);
request.source().aggregation(AggregationBuilders
.terms(“brandAgg”)
.field(“brand”)
.size(20)
);
//3.发出请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析结果
Aggregations aggregations = response.getAggregations();
//4.1根据聚合名称获取聚合结果
Terms brandTerms = aggregations.get(“brandAgg”);
//4.2获取buckets
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
//4.3遍历
for (Terms.Bucket bucket : buckets) {
//4.4获取key
String key = bucket.getKeyAsString();
System.out.println(key);
}
}
当用户在搜索框输入字符时,我们应该提示出与该字符有关的搜索项,如图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uKEANYwe-1637384192176)(C:\Users\30287\Desktop\Java学习视频\day03-Docker\day07-Elasticsearch03\讲义\assets\image-20210723204936367.png)]](https://img-blog.csdnimg.cn/a053e3b400b74d3db4514a010794764a.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBATEwuTEVCUk9O,size_20,color_FFFFFF,t_70,g_se,x_16)
这种根据用户输入的字母,提示完整词条的功能,就是自动补全了。
因为需要根据拼音字母来推断,因此要用到拼音分词功能。
2.1 拼音分词器
要实现根据字母做补全,就必须对文档按照拼音分词。插件地址:https://github.com/medcl/elasticsearch-analysis-pinyin
使用 docker volume inspect es-plugins 查看插件目录,将下载的文件解压上传,重启 Elasticsearch
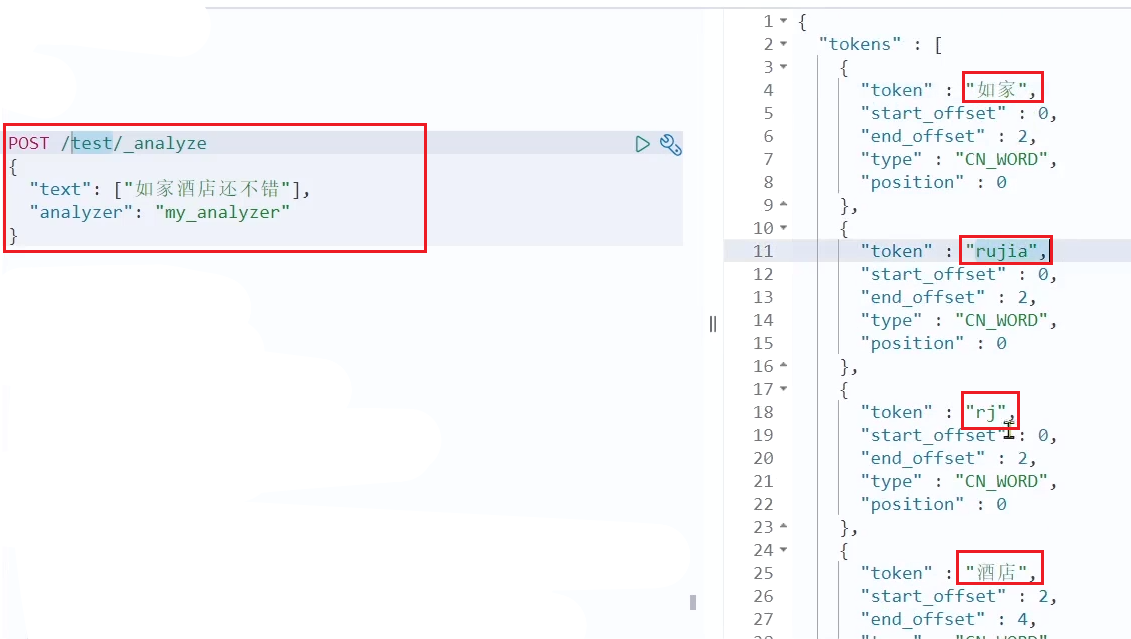
测试用法如下:
POST /_analyze
{
“text”: “如家酒店还不错”,
“analyzer”: “pinyin”
}
结果:

2.2 自定义分词器
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音,需要对拼音分词器做个性化定制,形成自定义分词器。
elasticsearch中分词器(analyzer)的组成包含三部分:
-
character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符 -
tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart -
tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
文档分词时会依次由这三部分来处理文档:
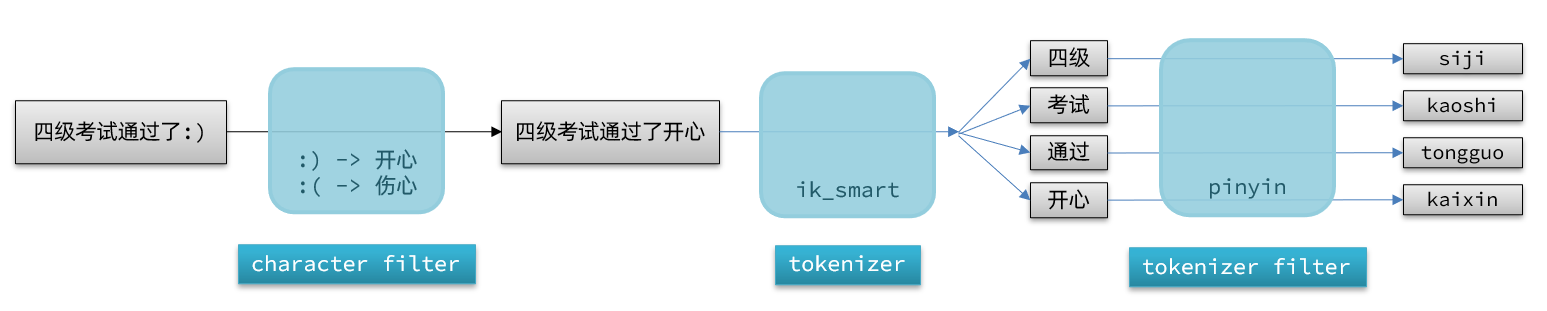
声明自定义分词器的语法如下:
PUT /test
{
“settings”: {
“analysis”: {
“analyzer”: { // 自定义分词器
“my_analyzer”: { // 分词器名称
“tokenizer”: “ik_max_word”,
“filter”: “py”
}
},
“filter”: { // 自定义tokenizer filter
“py”: { // 过滤器名称
“type”: “pinyin”, // 过滤器类型,这里是pinyin
“keep_full_pinyin”: false,
“keep_joined_full_pinyin”: true,
“keep_original”: true,
“limit_first_letter_length”: 16,
“remove_duplicated_term”: true,
“none_chinese_pinyin_tokenize”: false
}
}
}
},
“mappings”: {
“properties”: {
“name”: {
“type”: “text”,
“analyzer”: “my_analyzer”,
“search_analyzer”: “ik_smart”
}
}
}
}
测试:
总结:
如何使用拼音分词器?
-
①下载pinyin分词器
-
②解压并放到elasticsearch的plugin目录
-
③重启即可
如何自定义分词器?
-
①创建索引库时,在settings中配置,可以包含三部分
-
②character filter
-
③tokenizer
-
④filter
拼音分词器注意事项?
- 为了避免搜索到同音字,搜索时不要使用拼音分词器
总结
谈到面试,其实说白了就是刷题刷题刷题,天天作死的刷。。。。。
为了准备这个“金三银四”的春招,狂刷一个月的题,狂补超多的漏洞知识,像这次美团面试问的算法、数据库、Redis、设计模式等这些题目都是我刷到过的
并且我也将自己刷的题全部整理成了PDF或者Word文档(含详细答案解析)

66个Java面试知识点
架构专题(MySQL,Java,Redis,线程,并发,设计模式,Nginx,Linux,框架,微服务等)+大厂面试题详解(百度,阿里,腾讯,华为,迅雷,网易,中兴,北京中软等)

算法刷题(PDF)

,可以包含三部分
-
②character filter
-
③tokenizer
-
④filter
拼音分词器注意事项?
- 为了避免搜索到同音字,搜索时不要使用拼音分词器
总结
谈到面试,其实说白了就是刷题刷题刷题,天天作死的刷。。。。。
为了准备这个“金三银四”的春招,狂刷一个月的题,狂补超多的漏洞知识,像这次美团面试问的算法、数据库、Redis、设计模式等这些题目都是我刷到过的
并且我也将自己刷的题全部整理成了PDF或者Word文档(含详细答案解析)
[外链图片转存中…(img-uRZsYGrD-1714495182085)]
66个Java面试知识点
架构专题(MySQL,Java,Redis,线程,并发,设计模式,Nginx,Linux,框架,微服务等)+大厂面试题详解(百度,阿里,腾讯,华为,迅雷,网易,中兴,北京中软等)
[外链图片转存中…(img-oBck1Bj2-1714495182086)]
算法刷题(PDF)
[外链图片转存中…(img-wr6ASp1f-1714495182086)]















 1049
1049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









