







运行环境
sh es版本:7.12.1
ik分词器版本:7.12.1
拼音分词器:7.12.1
尽量版本一致有兼容问题

首先我们分析为什么用户输入xiao 的时候为什么下面能提示出以xiao 开头的数据?
我们在存入数据的时候需要拼音分词器对要存进es数据库的词条进行分词,这样用户就可以通过拼音搜索出对应的词条,需要额外的加一个字段存放用户输入时补全的数据,再通过 completion suggest 查询出补全的数据
1 拼音分词器的使用
拼音分词器简单使用示例
POST /_analyze
{
"text": ["小米手机"],
"analyzer": "pinyin"
}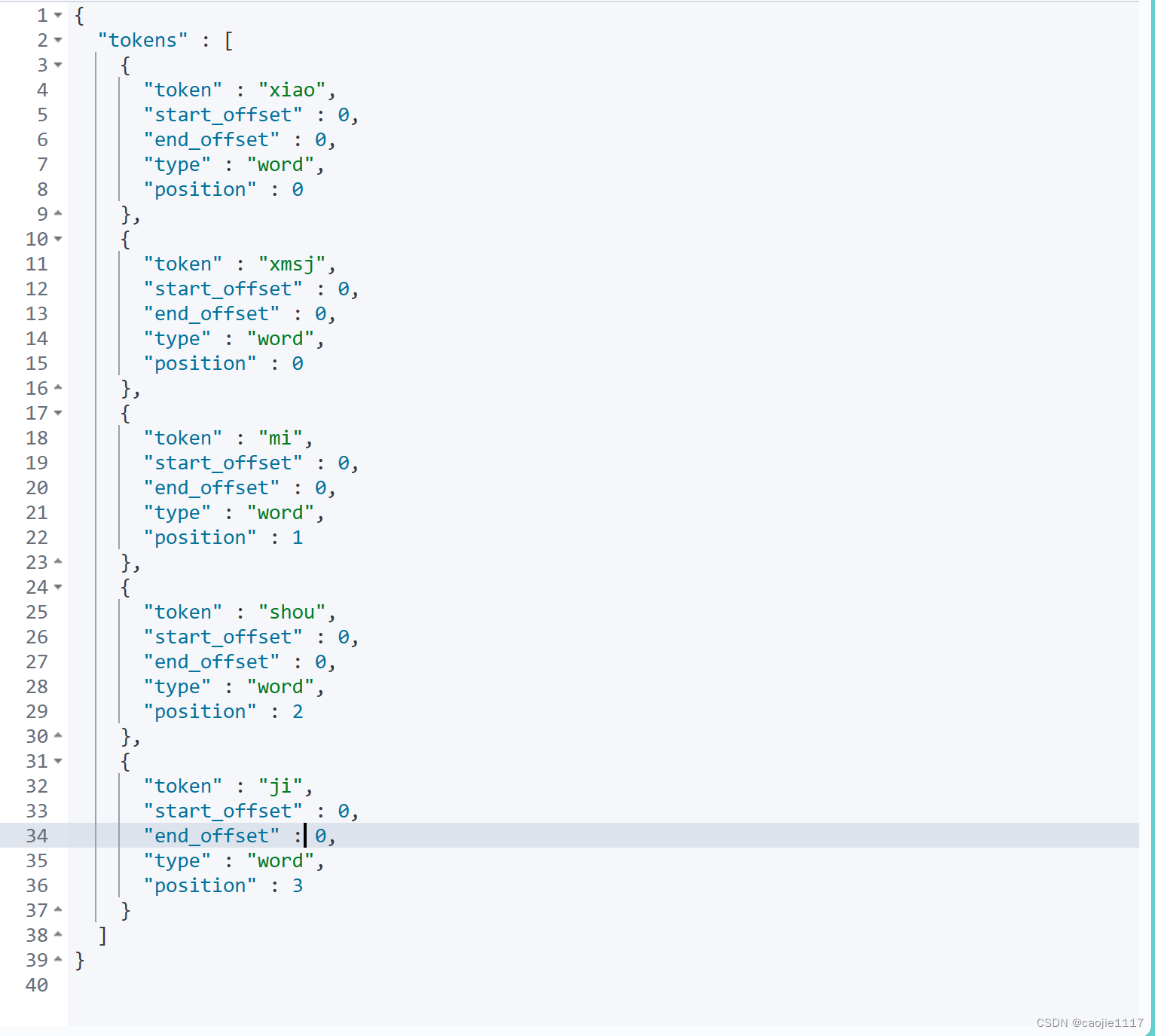 可以看到响应的结果是有缺点的,不符合我们的实际应用
可以看到响应的结果是有缺点的,不符合我们的实际应用
1.一字一分
2.汉字没有分词
3.用户用汉字查询多,这里都是拼音
1.1 解决方案 自定义分词器
自定义分词器分为三部分别是character filter 字符过滤器, tokenizer 分词器, tokenizer fliter 过滤器
character filter 字符过滤器:是分词之前对词条进行处理
tokenizer 分词器:指定分词器
fliter 过滤器:对分好词条再次进行处理

1.2 声明自定义分词器的语法如下:
创建自定义分词器的索引,自定义分词器只能在当前索引下使用
-
PUT /test:这是请求的路径,表示创建一个名为test的索引。 -
"settings":这是索引设置的参数,用于配置索引的分析器和过滤器。 -
"analysis":这是分析器和过滤器的设置。 -
"analyzer":这是分析器(analyzer)的配置,可以自定义名称。 -
"my_analyzer":这是分析器的名称,可以自定义。 -
"tokenizer": "ik_max_word":这是分析器使用的分词器(tokenizer),这里使用的是IK分词器,它可以将中文文本切分成单个词语。 -
"filter": "py":这是使用的分析器的过滤器(filter),这里使用的是名为py的过滤器。 -
"filter":这是过滤器(filter)的配置。 -
"py":这是过滤器的名称,可以自定义。 -
"type": "pinyin":这是过滤器的类型,表示要将中文转换为拼音。 -
"keep_full_pinyin": false:这是一个设置参数,表示拼音转换后是否保留完整拼音的设置,这里设置为不保留。 -
"keep_joined_full_pinyin": true:这是一个设置参数,表示拼音转换后是否保留拼音之间的连字符的设置,这里设置为保留。 -
"keep_original": true:这是一个设置参数,表示是否保留原始文本的设置,这里设置为保留。 -
"limit_first_letter_length": 16:这是一个设置参数,表示拼音转换后首字母的长度限制,这里设置为16。 -
"remove_duplicated_term": true:这是一个设置参数,表示是否去除重复的结果的设置,这里设置为去除。 -
"none_chinese_pinyin_tokenize": false:这是一个设置参数,表示是否对非中文文本进行拼音切分的设置,这里设置为不切分。 -
"mappings":这是索引的映射(mapping)设置。 -
"properties":这是映射中的字段属性设置。 -
"name":这是字段名称,可以自定义。 -
"type": "text":这是字段的类型,表示该字段包含文本内容。 -
"analyzer": "my_analyzer":这是字段的分析器设置,表示使用之前定义的my_analyzer分析器来处理该字段的文本内容。
PUT /test
{
"settings": {//配置
"analysis": {//分析
"analyzer": { // 自定义分词器
"my_analyzer": { // 分词器名称
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": { // 自定义tokenizer filter
"py": { // 过滤器名称
"type": "pinyin", // 过滤器类型,这里是pinyin
"keep_full_pinyin": false,//如果设置为true,则会将完整的拼音保留下来
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}加入两条数据
POST /test/_doc/1
{
"id": 1,
"name": "狮子"
}
POST /test/_doc/2
{
"id": 2,
"name": "虱子"
}模拟用户搜索
GET /test/_search
{
"query": {
"match": {
"name": "掉入狮子笼咋办"
}
}
}响应结果
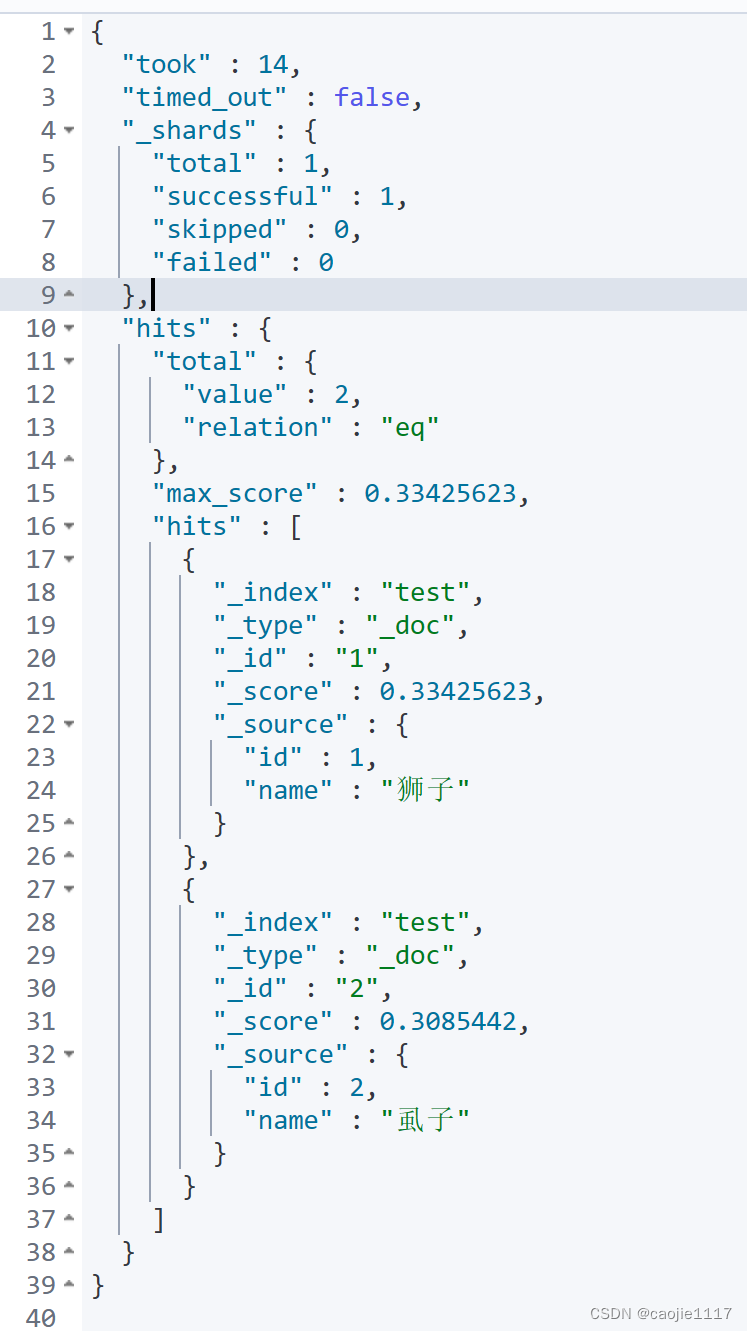
当用户查询:掉入狮子笼咋办时返回的数据同音字一并返回了,还是有缺陷
解决办法
我们在创建索引时指定分词时用自定义分词,用户搜索时用ik分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}再看结果

2 completion suggest 查询
es提供了completion suggest 查询来实现自动补全的功能,这个查询会匹配用户输入开头的词条并返回
参与补全查询的字段必须是completion类型的
字段里内容就是补全的多个词条
2.1 completion suggest示例
# 自动补全的索引库
PUT /test2
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}添加数据
# 示例数据
POST test2/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST test2/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test2/_doc
{
"title": ["Nintendo", "switch"]
}2.2 suggest 查询语法
-
"suggest":这是一个建议(suggestion)查询的参数,用于实现搜索建议功能。 -
"title_suggest":这是建议查询的名称,可以自定义。 -
"text": "s":这是用户输入的搜索文本,表示用户输入的内容是"s"。 -
"completion":这是建议查询的类型,表示希望通过补全(completion)的方式提供搜索建议。 -
"field": "title":这是需要进行建议的字段名称,表示希望对title字段进行建议。 -
"skip_duplicates": true:这是一个可选参数,表示在搜索建议中是否跳过重复结果。 -
"size": 10:这是可选参数,表示希望返回的建议结果数量,这里设置为10个。
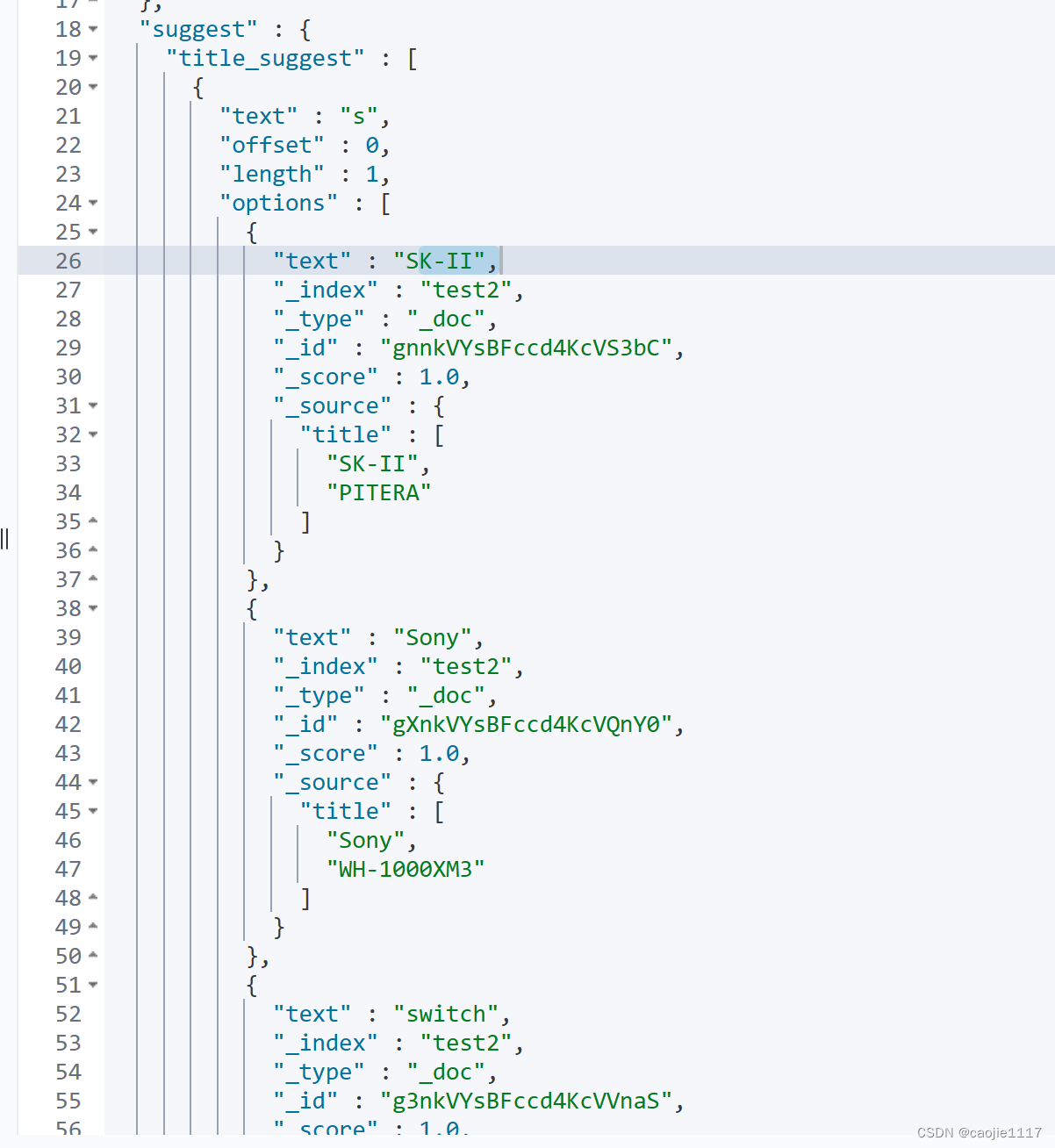
# 自动补全查询
GET /test2/_search
{
"suggest": {
"title_suggest": {
"text": "s",
"completion": {
"field": "title",
"skip_duplicates": true,
"size": 10
}
}
}
}查询结果如下, 我们只需要取suggest下的title_suggest下的 options下的text字段就是我们要补全的数据
 2.3 RestAPI实现自动补全
2.3 RestAPI实现自动补全


3 自动补全实现综合案例
3.1 创建hotel自定义分词器索引
# 酒店数据索引库
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}3.2 添加数据库数据
/*
Navicat Premium Data Transfer
Source Server : mysql
Source Server Type : MySQL
Source Server Version : 50528
Source Host : localhost:3306
Source Schema : hotel
Target Server Type : MySQL
Target Server Version : 50528
File Encoding : 65001
Date: 22/10/2023 14:04:32
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for tb_hotel
-- ----------------------------
DROP TABLE IF EXISTS `tb_hotel`;
CREATE TABLE `tb_hotel` (
`id` bigint(20) NOT NULL COMMENT '酒店id',
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店名称',
`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店地址',
`price` int(10) NOT NULL COMMENT '酒店价格',
`score` int(2) NOT NULL COMMENT '酒店评分',
`brand` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '酒店品牌',
`city` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '所在城市',
`star_name` varchar(16) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '酒店星级,1星到5星,1钻到5钻',
`business` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '商圈',
`latitude` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '纬度',
`longitude` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '经度',
`pic` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '酒店图片',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = COMPACT;
-- ----------------------------
-- Records of tb_hotel
-- ----------------------------
INSERT INTO `tb_hotel` VALUES (36934, '7天连锁酒店(上海宝山路地铁站店)', '静安交通路40号', 336, 37, '7天酒店', '上海', '二钻', '四川北路商业区', '31.251433', '121.47522', 'https://m.tuniucdn.com/fb2/t1/G1/M00/3E/40/Cii9EVkyLrKIXo1vAAHgrxo_pUcAALcKQLD688AAeDH564_w200_h200_c1_t0.jpg');
INSERT INTO `tb_hotel` VALUES (38609, '速8酒店(上海赤峰路店)', '广灵二路126号', 249, 35, '速8', '上海', '二钻', '四川北路商业区', '31.282444', '121.479385', 'https://m.tuniucdn.com/fb2/t1/G2/M00/DF/96/Cii-TFkx0ImIQZeiAAITil0LM7cAALCYwKXHQ4AAhOi377_w200_h200_c1_t0.jpg');
INSERT INTO `tb_hotel` VALUES (38665, '速8酒店上海中山北路兰田路店', '兰田路38号', 226, 35, '速8', '上海', '二钻', '长风公园地区', '31.244288', '121.422419', 'https://m.tuniucdn.com/fb2/t1/G2/M00/EF/86/Cii-Tlk2mV2IMZ-_AAEucgG3dx4AALaawEjiycAAS6K083_w200_h200_c1_t0.jpg');
INSERT INTO `tb_hotel` VALUES (38812, '7天连锁酒店(上海漕溪路地铁站店)', '徐汇龙华西路315弄58号', 298, 37, '7天酒店', '上海', '二钻', '八万人体育场地区', '31.174377', '121.442875', 'https://m.tuniucdn.com/fb2/t1/G2/M00/E0/0E/Cii-TlkyIr2IEWNoAAHQYv7i5CkAALD-QP2iJwAAdB6245_w200_h200_c1_t0.jpg');
INSERT INTO `tb_hotel` VALUES (39106, '7天连锁酒店(上海莘庄地铁站店)', '闵行莘庄镇七莘路299号', 348, 41, '7天酒店', '上海', '二钻', '莘庄工业区', '31.113812', '121.375869', 'https://m.tuniucdn.com/fb2/t1/G2/M00/D8/11/Cii-T1ku2zGIGR7uAAF1NYY9clwAAKxZAHO8HgAAXVN368_w200_h200_c1_t0.jpg');
INSERT INTO `tb_hotel` VALUES (39141, '7天连锁酒店(上海五角场复旦同济大学店)', '杨浦国权路315号', 349, 38, '7天酒店', '上海', '二钻', '江湾、五角场商业区', '31.290057', '121.508804', 'https://m.tuniucdn.com/fb2/t1/G2/M00/C7/E3/Cii-T1knFXCIJzNYAAFB8-uFNAEAAKYkQPcw1IAAUIL012_w200_h200_c1_t0.jpg');
INSERT INTO `tb_hotel` VALUES (45845, '上海西藏大厦万怡酒店', '虹桥路100号', 589, 45, '万怡', '上海', '四钻', '徐家汇地区', '31.192714', '121.434717', 'https://m.tuniucdn.com/fb3/s1/2n9c/48GNb9GZpJDCejVAcQHYWwYyU8T_w200_h200_c1_t0.jpg');
INSERT INTO `tb_hotel` VALUES (45870, '上海临港豪生大酒店', '新元南路555号', 896, 45, '豪生', '上海', '四星级', '滴水湖临港地区', '30.871729', '121.81959', 'https://m.tuniucdn.com/fb3/s1/2n9c/2F5HoQvBgypoDUE46752ppnQaTqs_w200_h200_c1_t0.jpg');
INSERT INTO `tb_hotel` VALUES (46829, '上海浦西万怡酒店', '恒丰路338号', 726, 46, '万怡', '上海', '四钻', '上海火车站地区', '31.242977', '121.455864', 'https://m.tuniucdn.com/fb3/s1/2n9c/x87VCoyaR8cTuYFZmKHe8VC6Wk1_w200_h200_c1_t0.jpg');
INSERT INTO `tb_hotel` VALUES (47066, '上海浦东东站华美达酒店', '施新路958号', 408, 46, '华美达', '上海', '四钻', '浦东机场核心区', '31.147989', '121.759199', 'https://m.tuniucdn.com/fb3/s1/2n9c/2pNujAVaQbXACzkHp8bQMm6zqwhp_w200_h200_c1_t0.jpg');
INSERT INTO `tb_hotel` VALUES (4747 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1681
1681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









