







1p = 1/4
2MaxLevel = 64
2.3.2 节点包含的平均指针数目
Skip List属于空间换时间的数据结构,这里的空间指的就是每个节点包含的指针数目,这一部分是额外的内内存开销,可以用来度量空间复杂度。random()是个随机数,因此产生越高的节点层数,概率越低(Redis标准源码中的晋升率数据1/4,相对来说Skip List的结构是比较扁平的,层高相对较低)。其定量分析如下:
-
level = 1 概率为1-p
-
level >=2 概率为p
-
level = 2 概率为p(1-p)
-
level >= 3 概率为p^2
-
level = 3 概率为p^2(1-p)
-
level >=4 概率为p^3
-
level = 4 概率为p^3(1-p)
-
……
得出节点的平均层数(节点包含的平均指针数目):
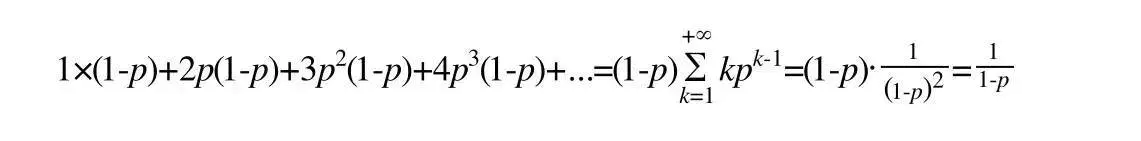
所以Redis中p=1/4计算的平均指针数目为1.33
2.3.3 时间复杂度计算
以下推算来自论文内容
假设p=1/2,在以p=1/2生成的16个元素的跳过列表中,我们可能碰巧具有9个元素,1级3个元素,3个元素3级元素和1个元素14级(这不太可能,但可能会发生)。我们该怎么处理这种情况?如果我们使用标准算法并在第14级开始我们的搜索,我们将会做很多无用的工作。那么我们应该从哪里开始搜索?此时我们假设SkipList中有n个元素,第L层级元素个数的期望是1/p个;每个元素出现在L层的概率是p^(L-1), 那么第L层级元素个数的期望是 n * (p^L-1);得到1 / p =n * (p^L-1)
11 / p = n * (p^L-1)
2n = (1/p)^L
3L = log(1/p)^n
所以我们应该选择MaxLevel = log(1/p)^n
定义:MaxLevel = L(n) = log(1/p)^n
推算Skip List的时间复杂度,可以用逆向思维,从层数为i的节点x出发,返回起点的方式来回溯时间复杂度,节点x点存在两种情况:
-
节点x存在(i+1)层指针,那么向上爬一级,概率为p,对应下图situation c.
-
节点x不存在(i+1)层指针,那么向左爬一级,概率为1-p,对应下图situation b.
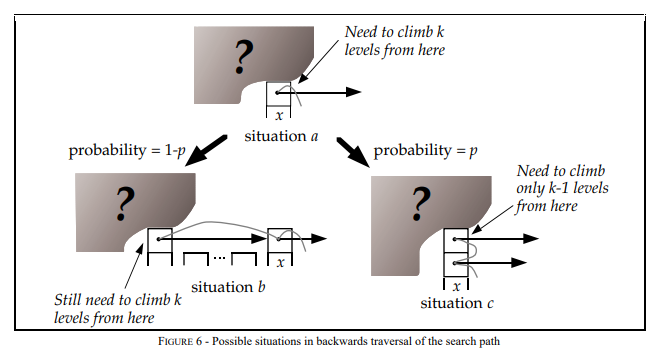
设C(k) = 在无限列表中向上攀升k个level的搜索路径的预期成本(即长度)那么推演如下:
1C(0)=0
2C(k)=(1-p)×(情况b的查找长度) + p×(情况c的查找长度)
3C(k)=(1-p)(C(k)+1) + p(C(k-1)+1)
4C(k)=1/p+C(k-1)
5C(k)=k/p
上面推演的结果可知,爬升k个level的预期长度为k/p,爬升一个level的长度为1/p。
由于MaxLevel = L(n), C(k) = k / p,因此期望值为:(L(n) – 1) / p;将L(n) = log(1/p)^n 代入可得:(log(1/p)^n - 1) / p;将p = 1 / 2 代入可得:2 * log2^n - 2,即O(logn)的时间复杂度。
三、Skip List特性及其实现
3.1 Skip List特性
Skip List跳跃列表通常具有如下这些特性
-
Skip List包含多个层,每层称为一个level,level从0开始递增
-
Skip List 0层,也就是最底层,应该包含所有的元素
-
每一个level/层都是一个有序的列表
-
level小的层包含level大的层的元素,也就是说元素A在X层出现,那么 想X>Z>=0的level/层都应该包含元素A
-
每个节点元素由节点key、节点value和指向当前节点所在level的指针数组组成
3.2 Skip List查询
假设初始Skip List跳跃列表中已经存在这些元素,他们分布的结构如下所示:
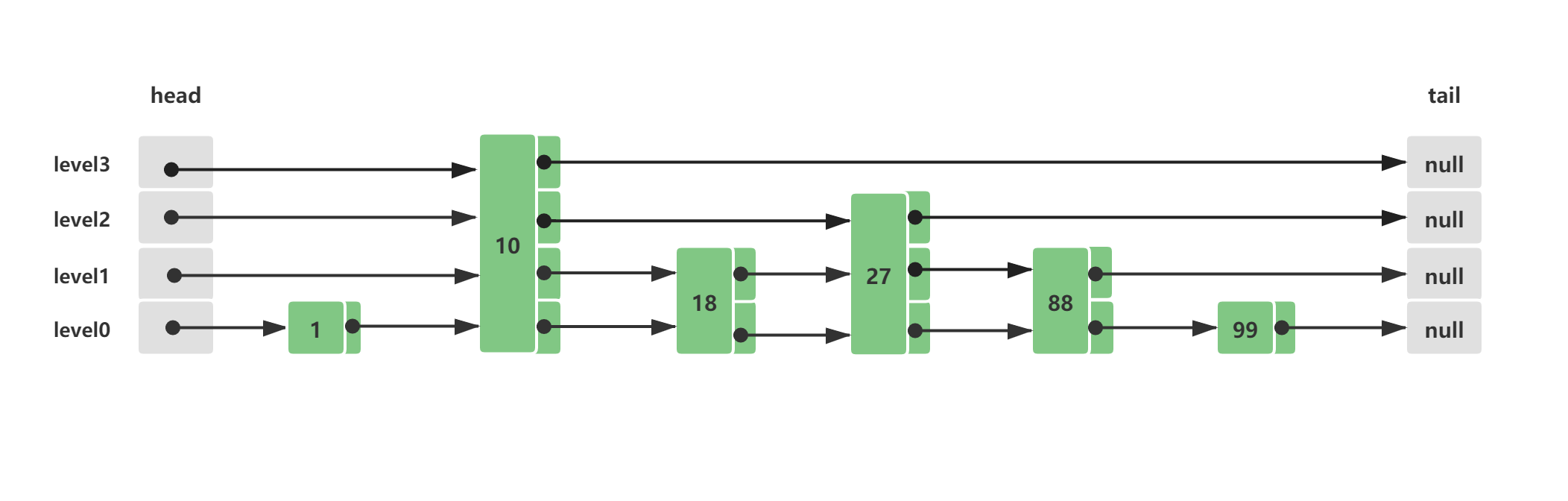
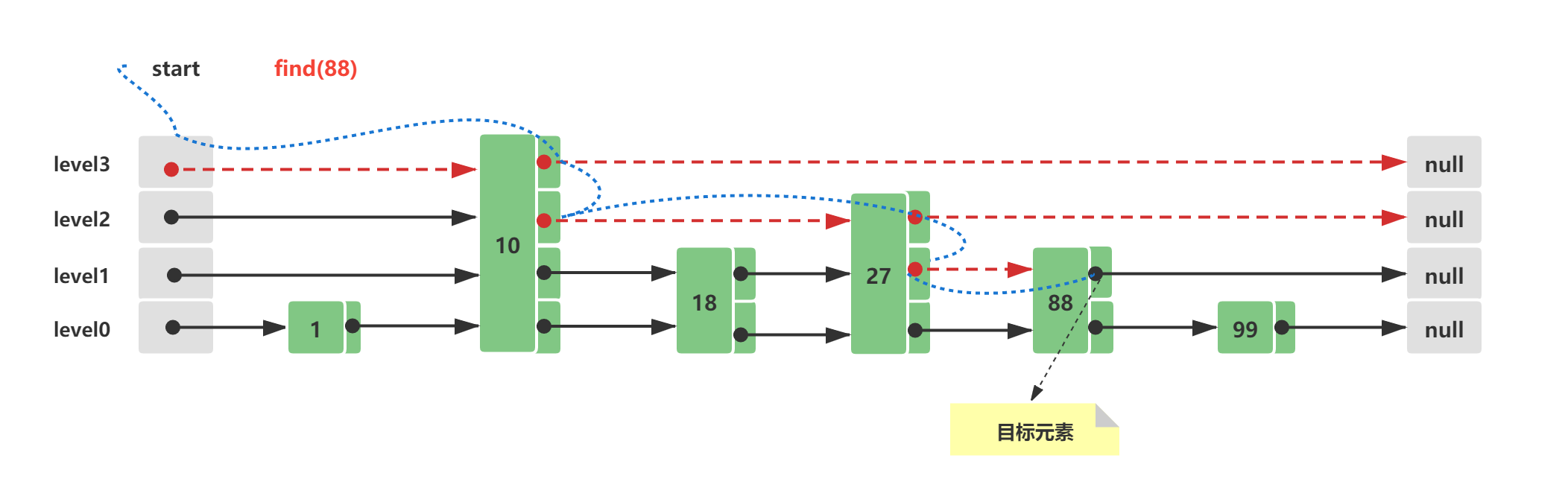
此时查询节点88,它的查询路线如下所示:
-
从Skip List跳跃列表最顶层level3开始,往后查询到10 < 88 && 后续节点值为null && 存在下层level2
-
level2 10往后遍历,27 < 88 && 后续节点值为null && 存在下层level1
-
level1 27往后遍历,88 = 88,查询命中
3.3 Skip List插入
Skip List的初始结构与2.3中的初始结构一致,此时假设插入的新节点元素值为90,插入路线如下所示:
-
查询插入位置,与Skip List查询方式一致,这里需要查询的是第一个比90大的节点位置,插入在这个节点的前面, 88 < 90 < 100
-
构造一个新的节点Node(90),为插入的节点Node(90)计算一个随机level,这里假设计算的是1,这个level时随机计算的,可能时1、2、3、4…均有可能,level越大的可能越小,主要看随机因子x ,层数的概率大致计算为 (1/x)^level ,如果level大于当前的最大level3,需要新增head和tail节点
-
节点构造完毕后,需要将其插入列表中,插入十分简单步骤 -> Node(88).next = Node(90); Node(90).prev = Node(80); Node(90).next = Node(100); Node(100).prev = Node(90);
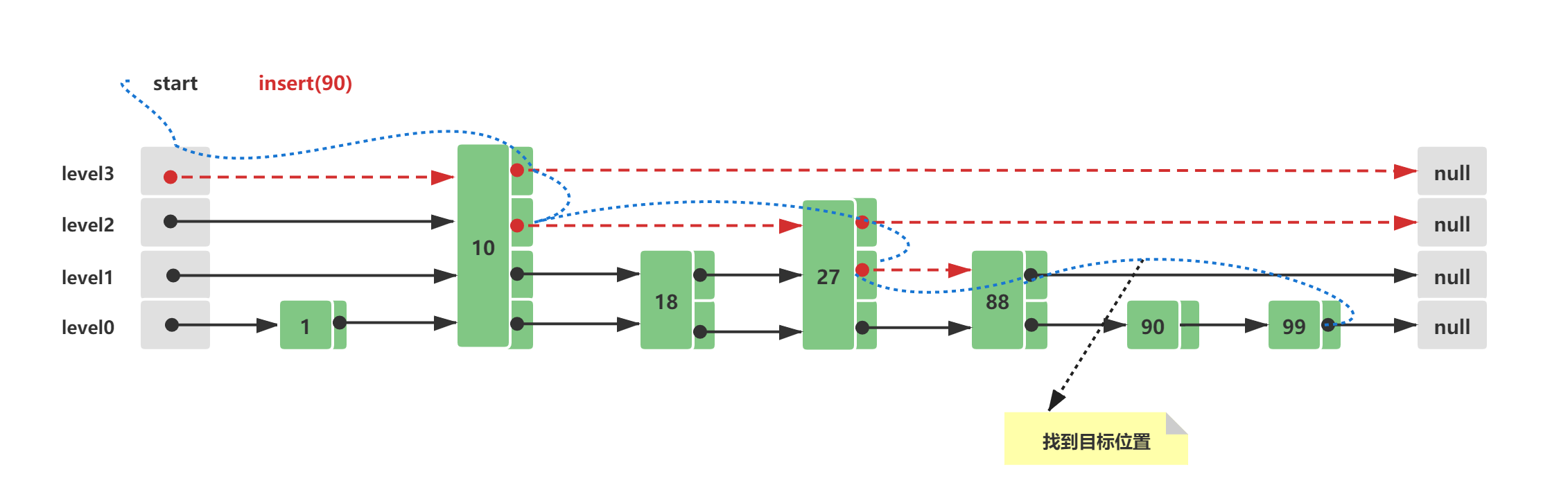
3.4 Skip List删除
删除的流程就是查询到节点,然后删除,重新将删除节点左右两边的节点以链表的形式组合起来即可,这里不再画图
四、手写实现一个简单Skip List
实现一个Skip List比较简单,主要分为两个步骤:
-
定义Skip List的节点Node,节点之间以链表的形式存储,因此节点持有相邻节点的指针,其中prev与next是同一level的前后节点的指针,down与up是同一节点的多个level的上下节点的指针
-
定义Skip List的实现类,包含节点的插入、删除、查询,其中查询操作分为升序查询和降序查询(往后和往前查询),这里实现的Skip List默认节点之间的元素是升序链表
3.1 定义Node节点
Node节点类主要包括如下重要属性:
-
score -> 节点的权重,这个与Redis中的score相同,用来节点元素的排序作用
-
value -> 节点存储的真实数据,只能存储String类型的数据
-
prev -> 当前节点的前驱节点,同一level
-
next -> 当前节点的后继节点,同一level
-
down -> 当前节点的下层节点,同一节点的不同level
-
up -> 当前节点的上层节点,同一节点的不同level
1package com.liziba.skiplist;
2
3/**
4 *
5 * 跳表节点元素
6 *
7 *
8 * @Author: Liziba
9 * @Date: 2021/7/5 21:01
10 */
11public class Node {
12
13 /** 节点的分数值,根据分数值来排序 */
14 public Double score;
15 /** 节点存储的真实数据 */
16 public String value;
17 /** 当前节点的 前、后、下、上节点的引用 */
18 public Node prev, next, down, up;
19
20 public Node(Double score) {
21 this.score = score;
22 prev = next = down = up = null;
23 }
24
25 public Node(Double score, String value) {
26 this.score = score;
27 this.value = value;
28 }
29}
3.2 SkipList节点元素的操作类
SkipList主要包括如下重要属性:
-
head -> SkipList中的头节点的最上层头节点(level最大的层的头节点),这个节点不存储元素,是为了构建列表和查询时做查询起始位置的,具体的结构请看2.3中的结构
-
tail -> SkipList中的尾节点的最上层尾节点(level最大的层的尾节点),这个节点也不存储元素,是查询某一个level的终止标志
-
level -> 总层数
-
size -> Skip List中节点元素的个数
-
random -> 用于随机计算节点level,如果 random.nextDouble() < 1/2则需要增加当前节点的level,如果当前节点增加的level超过了总的level则需要增加head和tail(总level)
1package com.liziba.skiplist;
2
3import java.util.Random;
4
5/**
6 *
7 * 跳表实现
8 *
9 *
10 * @Author: Liziba
11 */
12public class SkipList {
13
14 /** 最上层头节点 */
15 public Node head;
16 /** 最上层尾节点 */
17 public Node tail;
18 /** 总层数 */
19 public int level;
20 /** 元素个数 */
21 public int size;
22 public Random random;
23
24 public SkipList() {
25 level = size = 0;
26 head = new Node(null);
27 tail = new Node(null);
28 head.next = tail;
29 tail.prev = head;
30 }
31
32 /**
33 * 查询插入节点的前驱节点位置
34 *
35 * @param score
36 * @return
37 */
38 public Node fidePervNode(Double score) {
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Android工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Android移动开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip204888 (备注Android)

最后
今天关于面试的分享就到这里,还是那句话,有些东西你不仅要懂,而且要能够很好地表达出来,能够让面试官认可你的理解,例如Handler机制,这个是面试必问之题。有些晦涩的点,或许它只活在面试当中,实际工作当中你压根不会用到它,但是你要知道它是什么东西。
最后在这里小编分享一份自己收录整理上述技术体系图相关的几十套腾讯、头条、阿里、美团等公司19年的面试题,把技术点整理成了视频和PDF(实际上比预期多花了不少精力),包含知识脉络 + 诸多细节,由于篇幅有限,这里以图片的形式给大家展示一部分。
还有 高级架构技术进阶脑图、Android开发面试专题资料,高级进阶架构资料 帮助大家学习提升进阶,也节省大家在网上搜索资料的时间来学习,也可以分享给身边好友一起学习。
【Android核心高级技术PDF文档,BAT大厂面试真题解析】

【算法合集】

【延伸Android必备知识点】

【Android部分高级架构视频学习资源】
**Android精讲视频领取学习后更加是如虎添翼!**进军BATJ大厂等(备战)!现在都说互联网寒冬,其实无非就是你上错了车,且穿的少(技能),要是你上对车,自身技术能力够强,公司换掉的代价大,怎么可能会被裁掉,都是淘汰末端的业务Curd而已!现如今市场上初级程序员泛滥,这套教程针对Android开发工程师1-6年的人员、正处于瓶颈期,想要年后突破自己涨薪的,进阶Android中高级、架构师对你更是如鱼得水,赶快领取吧!
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

6)]
【延伸Android必备知识点】
[外链图片转存中…(img-MStqWgIQ-1712774728346)]
【Android部分高级架构视频学习资源】
**Android精讲视频领取学习后更加是如虎添翼!**进军BATJ大厂等(备战)!现在都说互联网寒冬,其实无非就是你上错了车,且穿的少(技能),要是你上对车,自身技术能力够强,公司换掉的代价大,怎么可能会被裁掉,都是淘汰末端的业务Curd而已!现如今市场上初级程序员泛滥,这套教程针对Android开发工程师1-6年的人员、正处于瓶颈期,想要年后突破自己涨薪的,进阶Android中高级、架构师对你更是如鱼得水,赶快领取吧!
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-0uj3nrIv-1712774728347)]















 2278
2278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









