







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
}
/**
- @desc重写hashCode
*/
@Override
public int hashCode(){
int nameHash = name.toUpperCase().hashCode();
return nameHash ^ age;
}
/**
- @desc 覆盖equals方法
*/
@Override
public boolean equals(Object obj){
if(obj == null){
return false;
}
//如果是同一个对象返回true,反之返回false
if(this == obj){
return true;
}
//判断是否类型相同
if(this.getClass() != obj.getClass()){
return false;
}
Person person = (Person)obj;
return name.equals(person.name) && age==person.age;
}
}
}
运行结果:
p1.equals(p2) : true; p1(68545) p2(68545)
p1.equals(p4) : false; p1(68545) p4(68545)
set:[aaa - 200, eee - 100]
结果分析:
这下,equals()生效了,HashSet中没有重复元素。
比较p1和p2,我们发现:它们的hashCode()相等,通过equals()比较它们也返回true。所以,p1和p2被视为相等。
比较p1和p4,我们发现:虽然它们的hashCode()相等;但是,通过equals()比较它们返回false。所以,p1和p4被视为不相等。
原则
1.同一个对象(没有发生过修改)无论何时调用hashCode()得到的返回值必须一样。 如果一个key对象在put的时候调用hashCode()决定了存放的位置,而在get的时候调用hashCode()得到了不一样的返回值,这个值映射到了一个和原来不一样的地方,那么肯定就找不到原来那个键值对了。
**2.hashCode()的返回值相等的对象不一定相等,通过hashCode()和equals()必须能唯一确定一个对象。**不相等的对象的hashCode()的结果可以相等。hashCode()在注意关注碰撞问题的时候,也要关注生成速度问题,完美hash不现实。
**3.一旦重写了equals()函数(重写equals的时候还要注意要满足自反性、对称性、传递性、一致性),就必须重写hashCode()函数。**而且hashCode()的生成哈希值的依据应该是equals()中用来比较是否相等的字段。
如果两个由equals()规定相等的对象生成的hashCode不等,对于hashMap来说,他们很可能分别映射到不同位置,没有调用equals()比较是否相等的机会,两个实际上相等的对象可能被插入不同位置,出现错误。其他一些基于哈希方法的集合类可能也会有这个问题
4.说说Object类下面有几种方法呢?
====================
Object有几种方法呢?
Java语言是一种单继承结构语言,Java中所有的类都有一个共同的祖先。这个祖先就是Object类。
如果一个类没有用extends明确指出继承于某个类,那么它默认继承Object类。
Object的方法我们在平时基本都会用到,但如果没有准备被忽然这么一问,还是有点懵圈的。
分析
Object类是Java中所有类的基类。位于java.lang包中,一共有13个方法。如下图:
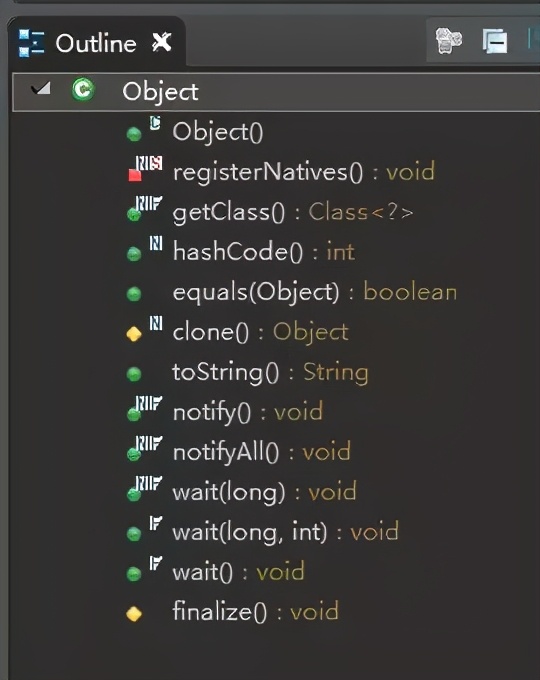
具体解答
1.Object()
这个没什么可说的,Object类的构造方法。(非重点)
2.registerNatives()
为了使JVM发现本机功能,他们被一定的方式命名。例如,对于
java.lang.Object.registerNatives,对应的C函数命名为Java_java_lang_Object_registerNatives。
通过使用registerNatives(或者更确切地说,JNI函数RegisterNatives),可以命名任何你想要你的C函数。(非重点)
3.clone()
clone()函数的用途是用来另存一个当前存在的对象。只有实现了Cloneable接口才可以调用该方法,否则抛出
CloneNotSupportedException异常。(注意:回答这里时可能会引出设计模式的提问)
4.getClass()
final方法,用于获得运行时的类型。该方法返回的是此Object对象的类对象/运行时类对象Class。效果与Object.class相同。(注意:回答这里时可能会引出类加载,反射等知识点的提问)
5.equals()
equals用来比较两个对象的内容是否相等。默认情况下(继承自Object类),equals和是一样的,除非被覆写(override)了。(注意:这里可能引出更常问的“equals与的区别”及hashmap实现原理的提问)
6.hashCode()
该方法用来返回其所在对象的物理地址(哈希码值),常会和equals方法同时重写,确保相等的两个对象拥有相等的hashCode。(同样,可能引出hashmap实现原理的提问)
7.toString()
toString()方法返回该对象的字符串表示,这个方法没什么可说的。
8.wait()
导致当前的线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法。(引出线程通信及“wait和sleep的区别”的提问)
9.wait(long timeout)
导致当前的线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者超过指定的时间量。(引出线程通信及“wait和sleep的区别”的提问)
10.wait(long timeout, int nanos)
导致当前的线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者其他某个线程中断当前线程,或者已超过某个实际时间量。(引出线程通信及“wait和sleep的区别”的提问)
11.notify()
唤醒在此对象监视器上等待的单个线程。(引出线程通信的提问)
12. notifyAll()
唤醒在此对象监视器上等待的所有线程。(引出线程通信的提问)
13.finalize()
当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。(非重点,但小心引出垃圾回收的提问)
5.Redis中是如何实现分布式锁的?
===================
分布式锁常见的三种实现方式:
-
数据库乐观锁;
-
基于Redis的分布式锁;
-
基于ZooKeeper的分布式锁。
本地面试考点是,你对Redis使用熟悉吗?Redis中是如何实现分布式锁的。
要点
Redis要实现分布式锁,以下条件应该得到满足
互斥性
- 在任意时刻,只有一个客户端能持有锁。
不能死锁
- 客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
容错性
- 只要大部分的Redis节点正常运行,客户端就可以加锁和解锁。
实现
可以直接通过 set key value px milliseconds nx 命令实现加锁, 通过Lua脚本实现解锁。
//获取锁(unique_value可以是UUID等)
SET resource_name unique_value NX PX 30000
//释放锁(lua脚本中,一定要比较value,防止误解锁)
if redis.call(“get”,KEYS[1]) == ARGV[1] then
return redis.call(“del”,KEYS[1])
else
return 0
end
代码解释
-
set 命令要用 set key value px milliseconds nx,替代 setnx + expire 需要分两次执行命令的方式,保证了原子性,
-
value 要具有唯一性,可以使用UUID.randomUUID().toString()方法生成,用来标识这把锁是属于哪个请求加的,在解锁的时候就可以有依据;
-
释放锁时要验证 value 值,防止误解锁;
-
通过 Lua 脚本来避免 Check And Set 模型的并发问题,因为在释放锁的时候因为涉及到多个Redis操作 (利用了eval命令执行Lua脚本的原子性);
加锁代码分析
首先,set()加入了NX参数,可以保证如果已有key存在,则函数不会调用成功,也就是只有一个客户端能持有锁,满足互斥性。其次,由于我们对锁设置了过期时间,即使锁的持有者后续发生崩溃而没有解锁,锁也会因为到了过期时间而自动解锁(即key被删除),不会发生死锁。最后,因为我们将value赋值为requestId,用来标识这把锁是属于哪个请求加的,那么在客户端在解锁的时候就可以进行校验是否是同一个客户端。
解锁代码分析
将Lua代码传到jedis.eval()方法里,并使参数KEYS[1]赋值为lockKey,ARGV[1]赋值为requestId。在执行的时候,首先会获取锁对应的value值,检查是否与requestId相等,如果相等则解锁(删除key)。
存在的风险
如果存储锁对应key的那个节点挂了的话,就可能存在丢失锁的风险,导致出现多个客户端持有锁的情况,这样就不能实现资源的独享了。
-
客户端A从master获取到锁
-
在master将锁同步到slave之前,master宕掉了(Redis的主从同步通常是异步的)。 主从切换,slave节点被晋级为master节点
-
客户端B取得了同一个资源被客户端A已经获取到的另外一个锁。导致存在同一时刻存不止一个线程获取到锁的情况。
redlock算法出现
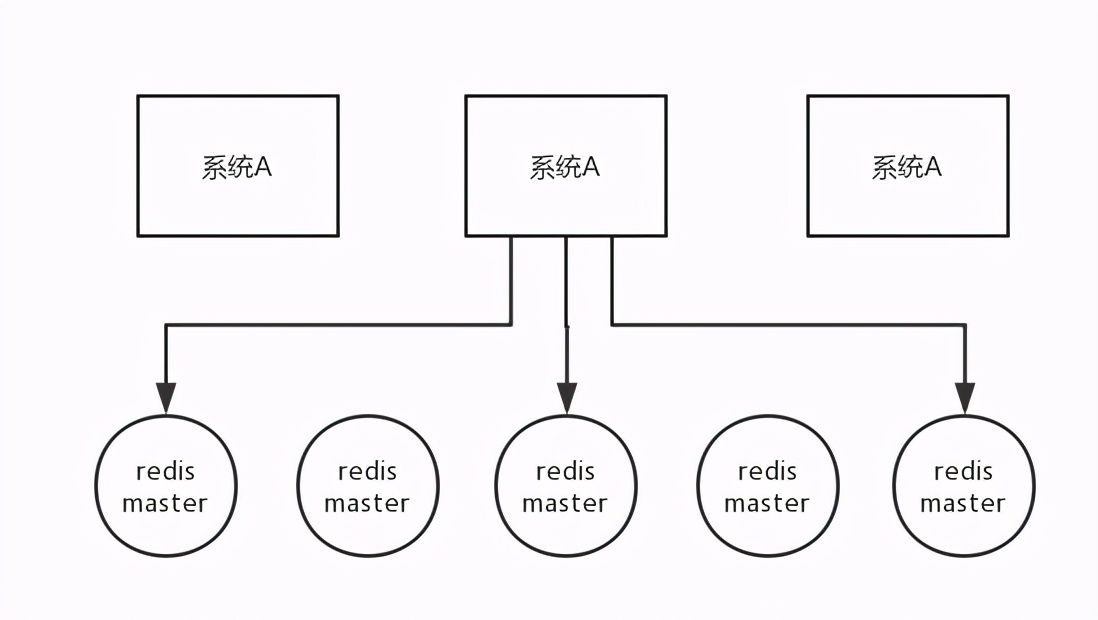
这个场景是假设有一个 redis cluster,有 5 个 redis master 实例。然后执行如下步骤获取一把锁:
-
获取当前时间戳,单位是毫秒;
-
跟上面类似,轮流尝试在每个 master 节点上创建锁,过期时间较短,一般就几十毫秒;
-
尝试在大多数节点上建立一个锁,比如 5 个节点就要求是 3 个节点 n / 2 + 1;
-
客户端计算建立好锁的时间,如果建立锁的时间小于超时时间,就算建立成功了;
-
要是锁建立失败了,那么就依次之前建立过的锁删除;
-
只要别人建立了一把分布式锁,你就得不断轮询去尝试获取锁。
Redisson实现
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还实现了可重入锁(Reentrant Lock)、公平锁(Fair Lock、联锁(MultiLock)、 红锁(RedLock)、 读写锁(ReadWriteLock)等,还提供了许多分布式服务。
Redisson提供了使用Redis的最简单和最便捷的方法。Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。
Redisson 分布式重入锁用法
Redisson 支持单点模式、主从模式、哨兵模式、集群模式,这里以单点模式为例:
// 1.构造redisson实现分布式锁必要的Config
Config config = new Config();
config.useSingleServer().setAddress(“redis://127.0.0.1:5379”).setPassword(“123456”).setDatabase(0);
// 2.构造RedissonClient
RedissonClient redissonClient = Redisson.create(config);
// 3.获取锁对象实例(无法保证是按线程的顺序获取到)
RLock rLock = redissonClient.getLock(lockKey);
try {
/**
-
4.尝试获取锁
-
waitTimeout 尝试获取锁的最大等待时间,超过这个值,则认为获取锁失败
-
leaseTime 锁的持有时间,超过这个时间锁会自动失效(值应设置为大于业务处理的时间,确保在锁有效期内业务能处理完)
*/
boolean res = rLock.tryLock((long)waitTimeout, (long)leaseTime, TimeUnit.SECONDS);
if (res) {
//成功获得锁,在这里处理业务
}
} catch (Exception e) {
throw new RuntimeException(“aquire lock fail”);
}finally{
//无论如何, 最后都要解锁
rLock.unlock();
}
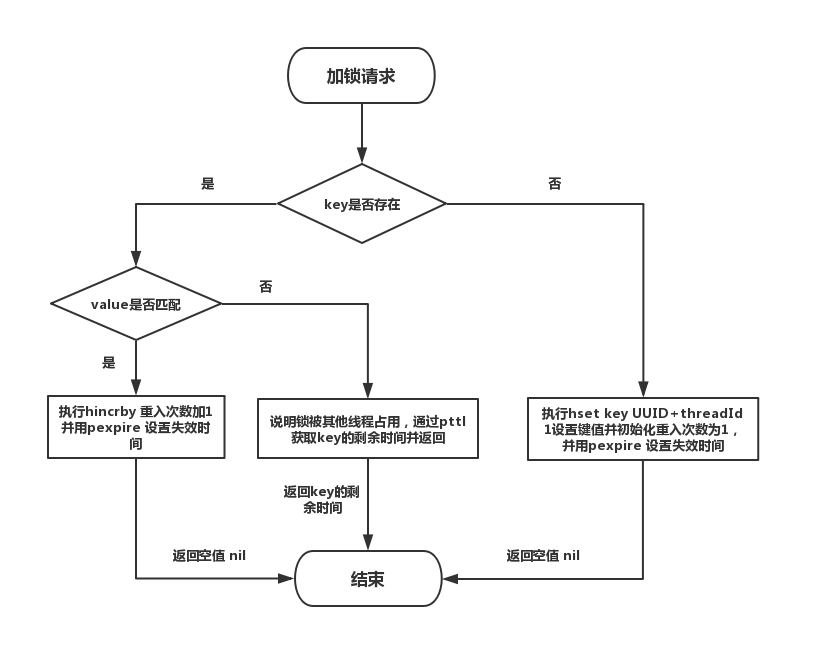
加锁流程图
解锁流程图
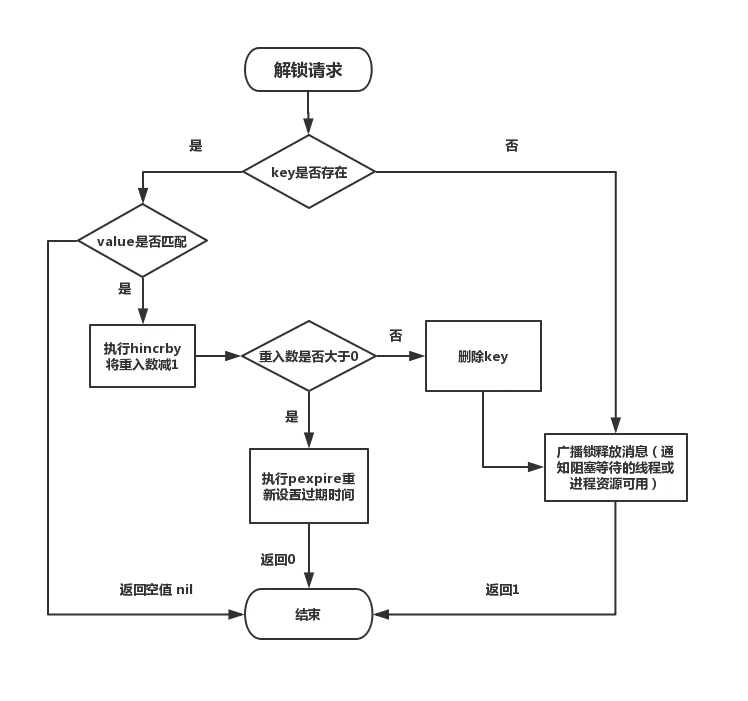
我们可以看到,RedissonLock是可重入的,并且考虑了失败重试,可以设置锁的最大等待时间, 在实现上也做了一些优化,减少了无效的锁申请,提升了资源的利用率。
需要特别注意的是,RedissonLock 同样没有解决 节点挂掉的时候,存在丢失锁的风险的问题。而现实情况是有一些场景无法容忍的,所以 Redisson 提供了实现了redlock算法的 RedissonRedLock,RedissonRedLock 真正解决了单点失败的问题,代价是需要额外的为 RedissonRedLock 搭建Redis环境。
所以,如果业务场景可以容忍这种小概率的错误,则推荐使用 RedissonLock, 如果无法容忍,则推荐使用 RedissonRedLock。
6.单例模式有几种写法?
============
“你知道茴香豆的‘茴’字有几种写法吗?”
纠结单例模式有几种写法有用吗?有点用,面试中经常选择其中一种或几种写法作为话头,考查设计模式和coding style的同时,还很容易扩展到其他问题。
这里讲解几种笔者常用的写法,但切忌生搬硬套,去记“茴香豆的写法”。编程最大的乐趣在于“know everything, control everything”。
JDK版本:oracle java 1.8.0_102
大体可分为4类,下面分别介绍他们的基本形式、变种及特点。
饱汉模式
饱汉是变种最多的单例模式。我们从饱汉出发,通过其变种逐渐了解实现单例模式时需要关注的问题。
基础的饱汉
饱汉,即已经吃饱,不着急再吃,饿的时候再吃。所以他就先不初始化单例,等第一次使用的时候再初始化,即“懒加载”。
// 饱汉
// UnThreadSafe
public class Singleton1 {
private static Singleton1 singleton = null;
private Singleton1() {
}
public static Singleton1 getInstance() {
if (singleton == null) {
singleton = new Singleton1();
}
return singleton;
}
}
饱汉模式的核心就是懒加载。好处是更启动速度快、节省资源,一直到实例被第一次访问,才需要初始化单例;小坏处是写起来麻烦,大坏处是线程不安全,if语句存在竞态条件。
写起来麻烦不是大问题,可读性好啊。因此,单线程环境下,基础饱汉是笔者最喜欢的写法。但多线程环境下,基础饱汉就彻底不可用了。下面的几种变种都在试图解决基础饱汉线程不安全的问题。
饱汉 - 变种 1
最粗暴的犯法是用synchronized关键字修饰getInstance()方法,这样能达到绝对的线程安全。
// 饱汉
// ThreadSafe
public class Singleton1_1 {
private static Singleton1_1 singleton = null;
private Singleton1_1() {
}
public synchronized static Singleton1_1 getInstance() {
if (singleton == null) {
singleton = new Singleton1_1();
}
return singleton;
}
}
变种1的好处是写起来简单,且绝对线程安全;坏处是并发性能极差,事实上完全退化到了串行。单例只需要初始化一次,但就算初始化以后,synchronized的锁也无法避开,从而getInstance()完全变成了串行操作。性能不敏感的场景建议使用。
饱汉 - 变种 2
变种2是“臭名昭著”的DCL 1.0。
针对变种1中单例初始化后锁仍然无法避开的问题,变种2在变种1的外层又套了一层check,加上synchronized内层的check,即所谓“双重检查锁”(Double Check Lock,简称DCL)。
// 饱汉
// UnThreadSafe
public class Singleton1_2 {
private static Singleton1_2 singleton = null;
public int f1 = 1; // 触发部分初始化问题
public int f2 = 2;
private Singleton1_2() {
}
public static Singleton1_2 getInstance() {
// may get half object
if (singleton == null) {
synchronized (Singleton1_2.class) {
if (singleton == null) {
singleton = new Singleton1_2();
}
}
}
return singleton;
}
}
变种2的核心是DCL,看起来变种2似乎已经达到了理想的效果:懒加载+线程安全。可惜的是,正如注释中所说,DCL仍然是线程不安全的,由于指令重排序,你可能会得到“半个对象”,即”部分初始化“问题。
饱汉 - 变种 3
变种3专门针对变种2,可谓DCL 2.0。
针对变种3的“半个对象”问题,变种3在instance上增加了volatile关键字,原理见上述参考。
// 饱汉
// ThreadSafe
public class Singleton1_3 {
private static volatile Singleton1_3 singleton = null;
public int f1 = 1; // 触发部分初始化问题
public int f2 = 2;
private Singleton1_3() {
}
public static Singleton1_3 getInstance() {
if (singleton == null) {
synchronized (Singleton1_3.class) {
// must be a complete instance
if (singleton == null) {
singleton = new Singleton1_3();
}
}
}
return singleton;
}
}
多线程环境下,变种3更适用于性能敏感的场景。但后面我们将了解到,就算是线程安全的,还有一些办法能破坏单例。
当然,还有很多方式,能通过与volatile类似的方式防止部分初始化。读者可自行阅读内存屏障相关内容,但面试时不建议主动装B。
饿汉模式
与饱汉相对,饿汉很饿,只想着尽早吃到。所以他就在最早的时机,即类加载时初始化单例,以后访问时直接返回即可。
// 饿汉
// ThreadSafe
public class Singleton2 {
private static final Singleton2 singleton = new Singleton2();
private Singleton2() {
}
public static Singleton2 getInstance() {
return singleton;
}
}
饿汉的好处是天生的线程安全(得益于类加载机制),写起来超级简单,使用时没有延迟;坏处是有可能造成资源浪费(如果类加载后就一直不使用单例的话)。
值得注意的时,单线程环境下,饿汉与饱汉在性能上没什么差别;但多线程环境下,由于饱汉需要加锁,饿汉的性能反而更优。
Holder模式
我们既希望利用饿汉模式中静态变量的方便和线程安全;又希望通过懒加载规避资源浪费。Holder模式满足了这两点要求:核心仍然是静态变量,足够方便和线程安全;通过静态的Holder类持有真正实例,间接实现了懒加载。
// Holder模式
// ThreadSafe
public class Singleton3 {
private static class SingletonHolder {
private static final Singleton3 singleton = new Singleton3();
private SingletonHolder() {
}
}
private Singleton3() {
}
/**
- 勘误:多写了个synchronized。。
public synchronized static Singleton3 getInstance() {
return SingletonHolder.singleton;
}
*/
public static Singleton3 getInstance() {
return SingletonHolder.singleton;
}
}
相对于饿汉模式,Holder模式仅增加了一个静态内部类的成本,与饱汉的变种3效果相当(略优),都是比较受欢迎的实现方式。同样建议考虑。
枚举模式
用枚举实现单例模式,相当好用,但可读性是不存在的。
基础的枚举
将枚举的静态成员变量作为单例的实例:
// 枚举
// ThreadSafe
public enum Singleton4 {
SINGLETON;
}
代码量比饿汉模式更少。但用户只能直接访问实例Singleton4.SINGLETON——事实上,这样的访问方式作为单例使用也是恰当的,只是牺牲了静态工厂方法的优点,如无法实现懒加载。
丑陋但好用的语法糖
Java的枚举是一个“丑陋但好用的语法糖”。
枚举型单例模式的本质
通过反编译打开语法糖,就看到了枚举类型的本质,简化如下:
// 枚举
// ThreadSafe
public class Singleton4 extends Enum {
…
public static final Singleton4 SINGLETON = new Singleton4();
…
}
本质上和饿汉模式相同,区别仅在于公有的静态成员变量。
用枚举实现一些trick
这一部分与单例没什么关系,可以跳过。如果选择阅读也请认清这样的事实:虽然枚举相当灵活,但如何恰当的使用枚举有一定难度。一个足够简单的典型例子是TimeUnit类,建议有时间耐心阅读。
上面已经看到,枚举型单例的本质仍然是一个普通的类。实际上,我们可以在枚举型型单例上增加任何普通类可以完成的功能。要点在于枚举实例的初始化,可以理解为实例化了一个匿名内部类。为了更明显,我们在Singleton4_1中定义一个普通的私有成员变量,一个普通的公有成员方法,和一个公有的抽象成员方法,如下:
// 枚举
// ThreadSafe
public enum Singleton4_1 {
SINGLETON(“enum is the easiest singleton pattern, but not the most readable”) {
public void testAbsMethod() {
print();
System.out.println(“enum is ugly, but so flexible to make lots of trick”);
}
};
private String comment = null;
Singleton4_1(String comment) {
this.comment = comment;
}
public void print() {
System.out.println(“comment=” + comment);
}
abstract public void testAbsMethod();
public static Singleton4_1 getInstance() {
return SINGLETON;
}
}
这样,枚举类Singleton4_1中的每一个枚举实例不仅继承了父类Singleton4_1的成员方法print(),还必须实现父类Singleton4_1的抽象成员方法testAbsMethod()。
总结
上面的分析都忽略了反射和序列化的问题。通过反射或序列化,我们仍然能够访问到私有构造器,创建新的实例破坏单例模式。此时,只有枚举模式能天然防范这一问题。反射和序列化笔者还不太了解,但基本原理并不难,可以在其他模式上手动实现。
下面继续忽略反射和序列化的问题,做个总结回味一下:
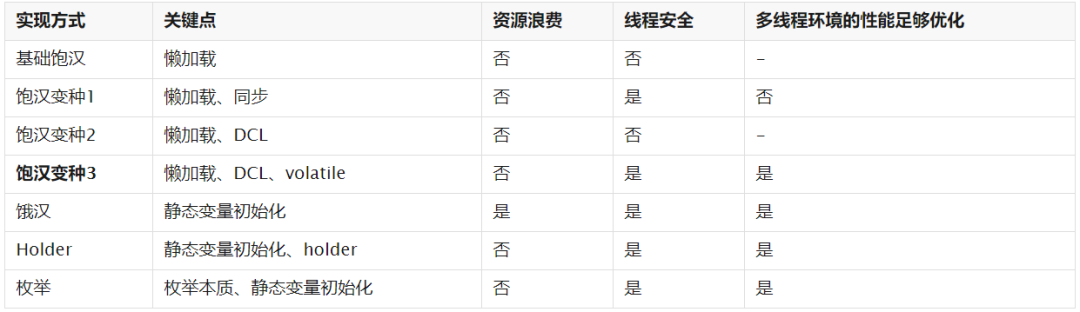
单例模式是面试中的常考点,写起来非常简单。
7.消息队列中,如何保证消息的顺序性?
===================
问:如何保证消息的顺序性?
面试官心理分析
其实这个也是用 MQ 的时候必问的话题,第一看看你了不了解顺序这个事儿?第二看看你有没有办法保证消息是有顺序的?这是生产系统中常见的问题。
面试题剖析
我举个例子,我们以前做过一个 mysql binlog 同步的系统,压力还是非常大的,日同步数据要达到上亿,就是说数据从一个 mysql 库原封不动地同步到另一个 mysql 库里面去(mysql -> mysql)。常见的一点在于说比如大数据 team,就需要同步一个 mysql 库过来,对公司的业务系统的数据做各种复杂的操作。
你在 mysql 里增删改一条数据,对应出来了增删改 3 条 binlog 日志,接着这三条 binlog 发送到 MQ 里面,再消费出来依次执行,起码得保证人家是按照顺序来的吧?不然本来是:增加、修改、删除;你楞是换了顺序给执行成删除、修改、增加,不全错了么。
本来这个数据同步过来,应该最后这个数据被删除了;结果你搞错了这个顺序,最后这个数据保留下来了,数据同步就出错了。
先看看顺序会错乱的俩场景:
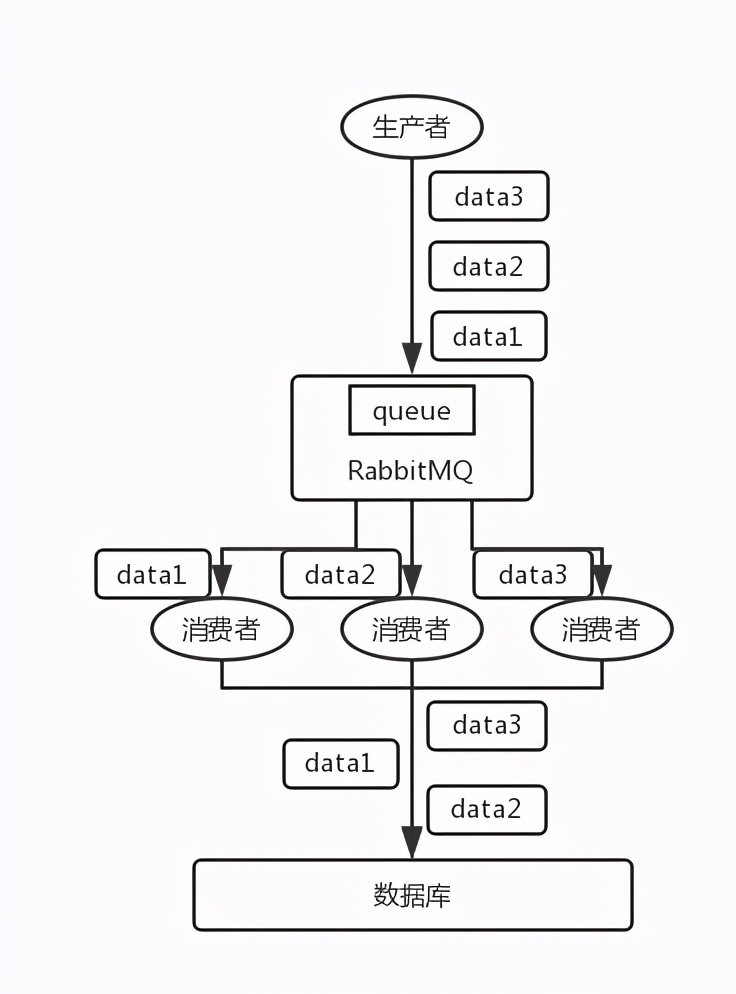
- RabbitMQ:一个 queue,多个 consumer。比如,生产者向 RabbitMQ 里发送了三条数据,顺序依次是 data1/data2/data3,压入的是 RabbitMQ 的一个内存队列。有三个消费者分别从 MQ 中消费这三条数据中的一条,结果消费者2先执行完操作,把 data2 存入数据库,然后是 data1/data3。这不明显乱了。
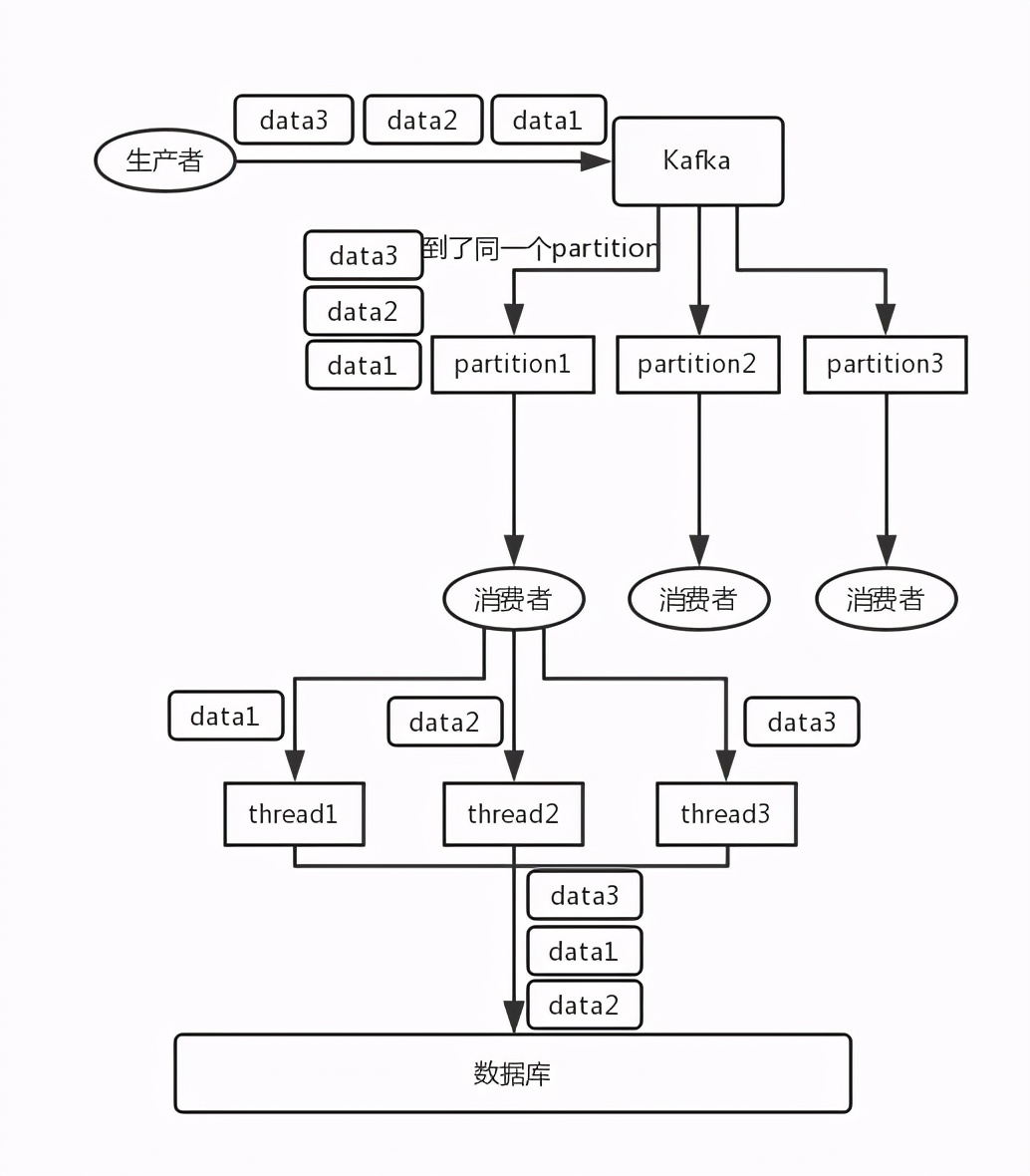
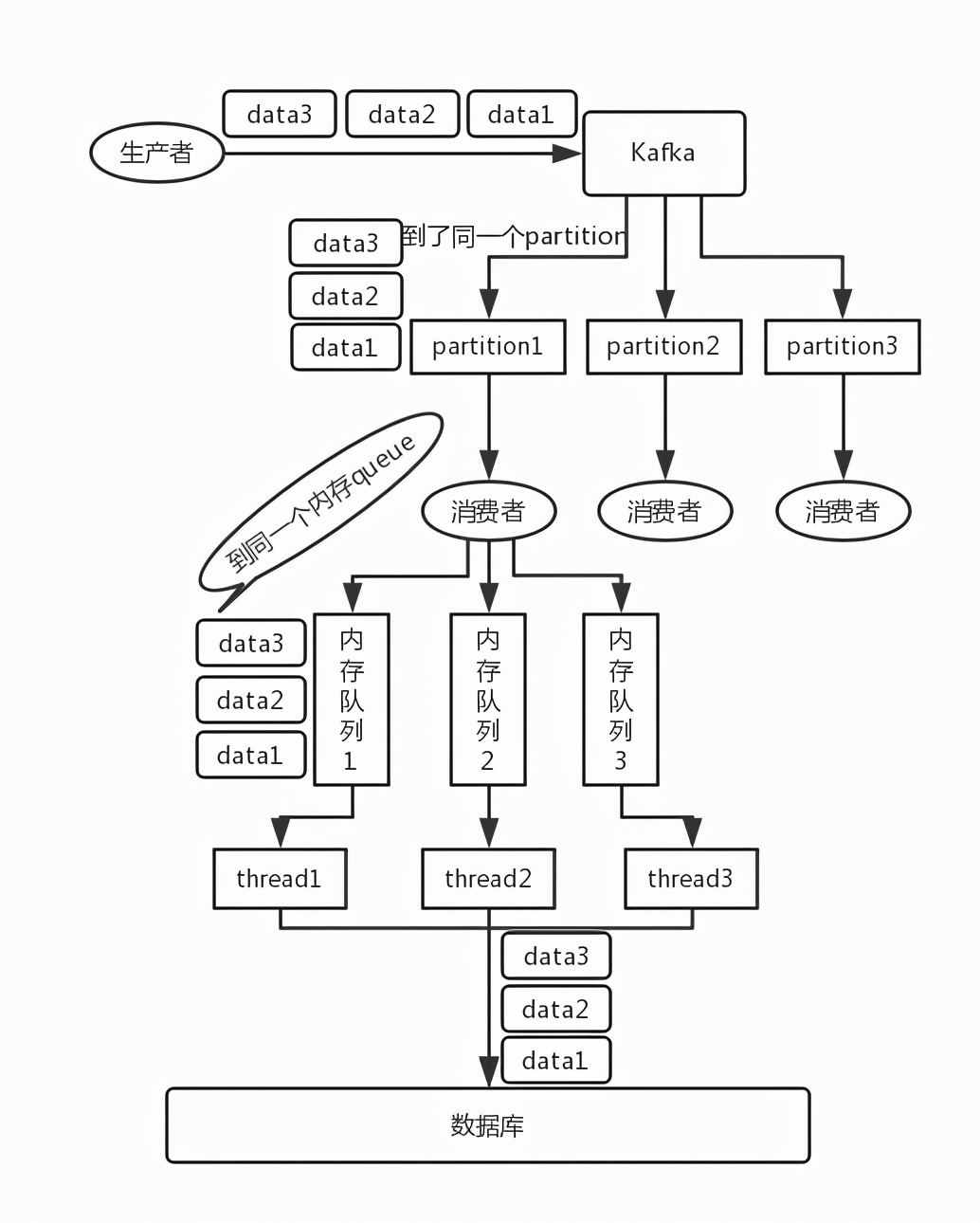
- Kafka:比如说我们建了一个 topic,有三个 partition。生产者在写的时候,其实可以指定一个 key,比如说我们指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到同一个 partition 中去,而且这个 partition 中的数据一定是有顺序的。消费者从 partition 中取出来数据的时候,也一定是有顺序的。到这里,顺序还是 ok 的,没有错乱。接着,我们在消费者里可能会搞多个线程来并发处理消息。因为如果消费者是单线程消费处理,而处理比较耗时的话,比如处理一条消息耗时几十 ms,那么 1 秒钟只能处理几十条消息,这吞吐量太低了。而多个线程并发跑的话,顺序可能就乱掉了。
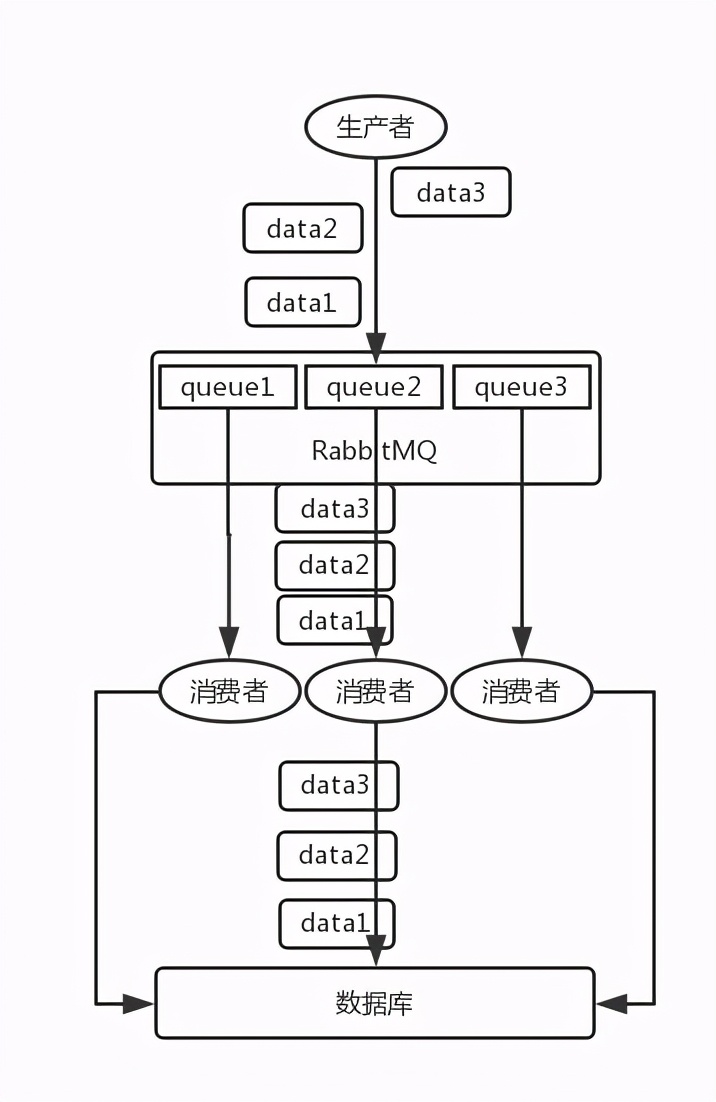
解决方案
RabbitMQ
拆分多个 queue,每个 queue 一个 consumer,就是多一些 queue 而已,确实是麻烦点;或者就一个 queue 但是对应一个 consumer,然后这个 consumer 内部用内存队列做排队,然后分发给底层不同的 worker 来处理。
Kafka
-
一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。
-
写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
8.你能说说Spring框架中Bean的生命周期吗?
==========================
1、实例化一个Bean--也就是我们常说的new;
2、按照Spring上下文对实例化的Bean进行配置--也就是IOC注入;
3、如果这个Bean已经实现了BeanNameAware接口,会调用它实现的setBeanName(String)方法,此处传递的就是Spring配置文件中Bean的id值
4、如果这个Bean已经实现了BeanFactoryAware接口,会调用它实现的setBeanFactory(setBeanFactory(BeanFactory)传递的是Spring工厂自身(可以用这个方式来获取其它Bean,只需在Spring配置文件中配置一个普通的Bean就可以);
5、如果这个Bean已经实现了ApplicationContextAware接口,会调用setApplicationContext(ApplicationContext)方法,传入Spring上下文(同样这个方式也可以实现步骤4的内容,但比4更好,因为ApplicationContext是BeanFactory的子接口,有更多的实现方法);
6、如果这个Bean关联了BeanPostProcessor接口,将会调用
postProcessBeforeInitialization(Object obj, String s)方法,BeanPostProcessor经常被用作是Bean内容的更改,并且由于这个是在Bean初始化结束时调用那个的方法,也可以被应用于内存或缓存技术;
7、如果Bean在Spring配置文件中配置了init-method属性会自动调用其配置的初始化方法。
8、如果这个Bean关联了BeanPostProcessor接口,将会调用
postProcessAfterInitialization(Object obj, String s)方法、;
注:以上工作完成以后就可以应用这个Bean了,那这个Bean是一个Singleton的,所以一般情况下我们调用同一个id的Bean会是在内容地址相同的实例,当然在Spring配置文件中也可以配置非Singleton,这里我们不做赘述。
9、当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean这个接口,会调用那个其实现的destroy()方法;
10、最后,如果这个Bean的Spring配置中配置了destroy-method属性,会自动调用其配置的销毁方法。
结合代码理解一下
1、Bean的定义
Spring通常通过配置文件定义Bean。如:
<?xml version=”1.0″ encoding=”UTF-8″?><beans xmlns=”http://www.springframework.org/schema/beans”
xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance”
xsi:schemaLocation=”http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd”>
HelloWorld
这个配置文件就定义了一个标识为 HelloWorld 的Bean。在一个配置文档中可以定义多个Bean。
2、Bean的初始化
有两种方式初始化Bean。
1、在配置文档中通过指定init-method 属性来完成
在Bean的类中实现一个初始化Bean属性的方法,如init(),如:
public class HelloWorld{
public String msg=null;
public Date date=null;
public void init() {
msg=”HelloWorld”;
date=new Date();
}
……
}
然后,在配置文件中设置init-mothod属性:
**2、实现
org.springframwork.beans.factory.InitializingBean接口**
总结
面试建议是,一定要自信,敢于表达,面试的时候我们对知识的掌握有时候很难面面俱到,把自己的思路说出来,而不是直接告诉面试官自己不懂,这也是可以加分的。
以上就是蚂蚁技术四面和HR面试题目,以下最新总结的最全,范围包含最全MySQL、Spring、Redis、JVM等最全面试题和答案,仅用于参考

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
ork.org/schema/beans”
xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance”
xsi:schemaLocation=”http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd”>
HelloWorld
这个配置文件就定义了一个标识为 HelloWorld 的Bean。在一个配置文档中可以定义多个Bean。
2、Bean的初始化
有两种方式初始化Bean。
1、在配置文档中通过指定init-method 属性来完成
在Bean的类中实现一个初始化Bean属性的方法,如init(),如:
public class HelloWorld{
public String msg=null;
public Date date=null;
public void init() {
msg=”HelloWorld”;
date=new Date();
}
……
}
然后,在配置文件中设置init-mothod属性:
**2、实现
org.springframwork.beans.factory.InitializingBean接口**
总结
面试建议是,一定要自信,敢于表达,面试的时候我们对知识的掌握有时候很难面面俱到,把自己的思路说出来,而不是直接告诉面试官自己不懂,这也是可以加分的。
以上就是蚂蚁技术四面和HR面试题目,以下最新总结的最全,范围包含最全MySQL、Spring、Redis、JVM等最全面试题和答案,仅用于参考
[外链图片转存中…(img-VfNeVnW8-1713549213232)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-RufLl8zd-1713549213232)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1527
1527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









