







最后
手绘了下图所示的kafka知识大纲流程图(xmind文件不能上传,导出图片展现),但都可提供源文件给每位爱学习的朋友

new 接口名(){接口实现类的代码} 用一个匿名的局部内部类实现接口,同时创建了实现类的一个对象 interface IA{ void m1(); void m2(); } new IA{ public void m1(){} public void m2(){} }匿名内部类的优点:不会打断程序的思路。不需要写实现类再创建对象。大量的接口回调都会使用匿名内部类。
缺点:降低代码的可读性
二、Java高级
💃 高级篇,很重要!!面试常客!!!
1.Lambda表达式(语法糖)
# 代码的参数化-----> 形式上,代码可以直接作为参数传递。
# 只能用于函数式接口
# 增加可读性
本质上就是匿名内部类的新颖写法,如果一个接口中只有一个抽象方法,这个接口称为**“函数式接口”**。
1️⃣.语法:
# (参数表) ->{方法实现} //利用匿名颞部类创建接口的实现类对象
- 1.参数表中,参数类型也可以省略
- 2.参数表中,如果只有一个参数,圆括号也可以省略
- 3.如果方法的实现只有一条语句(无返回值),‘{}’也可以省略
- 4.如果方法实现只有一条语句,且该方法有返回值,且只有return语句,那么return和{}都可以省略。
例如:
Test 是一个interface,里面仅有一个方法test(Student s);
/\*1.匿名内部类初始写法\*/
Test t1 = new Test(){
public boolean test(Student s){
return s.getAge()==18;
}
}
/\*2.简化写法\*/
Test t2 = (Student s)->{return s.getAge()==18;};
/\*3.简化参数列表\*/
Test t3 = s->{return s.getAge()==18;};
/\*3.简化方法体\*/
Test t4 = s->s.getAge()==18;
/\*4.在参数中使用\*/
/\*4.1 以前内部类的使用方法\*/
stu = find(ss,new Test(){
public boolean test(Student s){
return s.getAge()==18;
}
});
/\*4.2 lambda 表达式参数使用\*/
stu = find(ss, s->s.getAge()==18);
2.Object类和常用类
💃 每一个开发者都在改变世界。
object类
java中所有类的父亲 如果一个类没有指定父类,默认继承Object类。
根据多态,如果我们创建一个Object类型的引用,那么可以代表任何对象!
🚆Object o = 任何对象 不包括8中基本类型
🚋 Object类中定义的方法是所有Java对象都具有的方法(public 或 protected)【11个方法】
下面介绍Object中的方法:
| 方法名 | 作用 | 用法 |
|---|---|---|
| getClass() | 获得对象的实际类型 | o1.getClass()==o2.getClass()判断o1和o2类型是否相同 |
| finalize() | 对象垃圾回收时调用 | 对象的全生命周期里最后一个方法就是finalize()。编码中没啥用😂 |
| toString() | 返回对象的字符串形式 | 通常重写此方法,打印o就是打印o.toString() |
| equals() | 判断两个对象的内容是否相同 | 首先重写equals方法,equals(e1.equals(e2)); |
| hashCode() | 返回对象的哈希码 |
注释:
- getClass 与 instanceof 的区别:instanceof判断对象是不是某一个类型。例如
a instanceof Animal不知道是狗还是猫。 - 垃圾回收:Java中有垃圾自动收集的机制,由JVM中的垃圾收集器自动回收垃圾对象,释放对应的堆空间.
❓ 什么对象会被认为是垃圾对象??
答:零引用算法,如果一个对象没有任何引用指向它,则这个对象就是垃圾对象。
❓ 垃圾对象何时被回收?
答:在不得不回收,内存耗尽,无法创建新对象时候,才会一次性回收之前被认定为垃圾对象的对象。
- System.gc(); 唤醒垃圾收集器,有延迟回收策略,sun公司JDK可能不会启动。就像是你妈叫你去洗碗,你可以不去,也可以去,仅仅是告诉你。
- toString 返回对象的字符串形式,通常重写toString()
- equals() 与
==的区别就是,==比的是对象的地址,而equals() 才是比较的真实的对象。
😲 引用之间用==判断的是地址是否相同(是否指向同一个对象)
🌏 用equals() 判断得是对象内容是否相同
Object类中的equals方法,依然比较地址,如果我们想让其比较对象内容,我们需要重写
//this 和 o对象比较内容 public boolean equals(Object o){ //判断this和o是不是同一个对象 if(this == o) return true; //判断 o是不是 null if(o == null) return false; //判断this和o是不是同一个类 if(this.getClass() != o.getClass()) return false; //对o做强制类型转换,变为this类型 Employee e = (Employee)o; //逐个比较属性,基本数据类型用==比较,对象类型用equals比 if(this.age == e.age && this.name.equals(e.name)) return true; else return false; //注意这个不是递归,两个equals不是一个,是字符串中的equals }
包装类
Object o = 任何对象,但是基本数据类型不属于对象的范围,所以Object o = 10 是错误的!所以我们需要将基本类型转换。
为8中基本数据类型 各自提供一个类。这时候Object o = 任何数据了。
| 基本类型 | 包装类 |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
| boolean | Boolean |
1️⃣ 基本类型和包装类之间的转换
- int——>Integer
/\* 不一定要用构造方法获得对象,可以用静态方法,用构造方法会造成内存的浪费。而且Integer类提供的静态方法还能直接返回Integer的;\*/ Integer a = Integer.valueOf(i); Integer b = Integer.valueOf(i); // a==bInteger.valueOf(i); 获得一个Integer对象
Integer类内部会预先创建-128 ~ 127 256个对象,如果在这个区间内,不会产生新对象。
- Integer——>int
a.intValue(); //拆箱
- 从jdk5开始,自动装箱拆箱,由编译器自动处理基本类型和包装类型的转换。
2️⃣ 基本类型和String之间的转换
- int——> String
int i =12;
String s=i+“”; 或者 String s=String.valueOf(i);
- String——>int(重点)
String s =“1234”;
int i = Integer.parseInt(s);
3️⃣ 包装类和String之间的转换
- Integer——>String
Integer a = 1234;
String s = a.toString();
- String——>Integer
String s =“1234”;
Integer a = Integer.valueOf(s);
案例:统计成绩,为了区分0分与缺考。
class Student{
Integer score =null;
/\*对象类型默认是null,如果不给赋值成绩那就是null,那就是缺考。如果是0分那么就是0;\*/
}
日期处理
util包里有一个日期类Class Calendar
3.字符串处理String
凡是没有数值含义的属性都不要做成数值,例如手机号。
public final class String我们不能更改,只能用。本质上一个字符串就是一个字符数组的封装。
字符串中的常用方法
1️⃣ 与字符数组相关的方法
- String(char[] cs) 利用字符数组cs来构造String
- toCharArray()把字符串转正字符数组
把字符串全部变为大写:因为 大写+32=小写 String str="HelloWorld"; char[] cs = str.toCharArray(); for(int i =0; i<cs.length; i++){ if(cs[i] >= 'a' && cs[i] <='z'){ cs[i] -= 32;} String str2 = new String(cs); System.out.println(str2); }2️⃣基础的方法
- toUpperCase(); //转大写
- toLowerCase(); //转小写
- charAt(int index); //获得字符串下标
- length() //获得字符串的长度
- trim() //去掉字符串前后的换行符和空格符
- equals() //比较两个字符串中的内容
- equalsIgnoreCase(String str) //判断当前字符串和str内容是否相同,忽略大小写。例如验证码验证的时候。
3️⃣ 与子串相关
- starsWith(String str) / endsWith(String str) //判断当前字符串是否以str这个子串开头 /结尾
- contains(String str) //判断当前字符串是否包含子串str
s.contains("BC");s中有没有BC子串- indexOf(String str) 返回str子串在当前字符串中第一次出现的下标,不存在返回-1
- substring(int fromIndex) 找出当前字符串从fromIndex开始,到结尾的子串
- substring(int fromIndex,int endIndex) 返回从from到end的子串
- replace(String str1,String str2) 将字符串中str1替换为str2
- split(String str) 以str为分隔符,将字符串切割为String[]
String常量池
把相同内容的字符串只保留一份。
☯️ 引入字符串常量池:
一个String对象的内容是不可变的,只有不可变才可以让多个引用指向同一个对象。如果更改就创建新的对象,引用指向新的。
串池:字符串常量池,用来存放字符串对象,以供多个引用共享(通常存储在方法区)
创建一个String对象,先去字符串常量池里找,有的话直接引用赋值,没有的话在串池创建。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MpnIXEpy-1625741443297)(JavaSE复习.assets/image-20210705185347581.png)]](https://img-blog.csdnimg.cn/20210708191457591.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
如果有new 那么一定是在堆空间中分配内存!
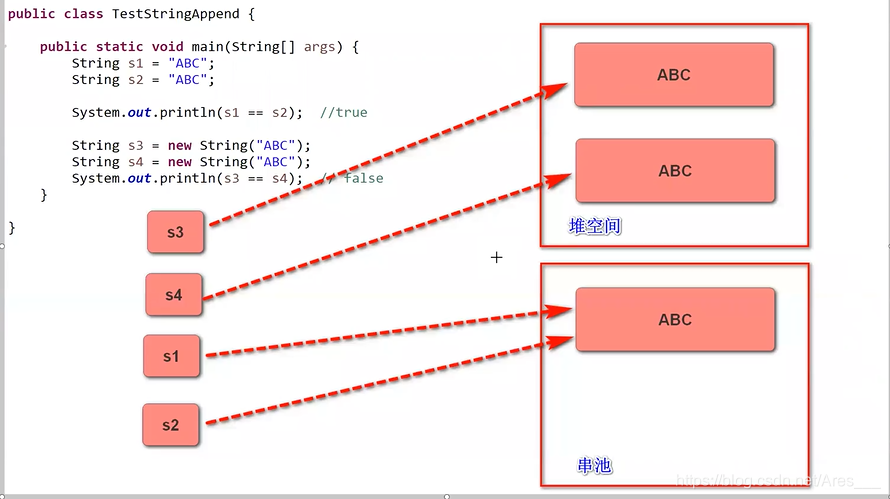
intern() 返回字符串在串池中的对应字符串地址
我们如果用数组的方式创建了String,肯定用到了new String() 这时候肯定在堆空间中,我们可以用intern()来找串池对象地址,然后把引用赋值。s4 = s4.intern();
String s3 =new String(cs).intern();
StringBuilder
当字符串的内容改变时,只会创建新的对象。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BCoQsuKb-1625741443297)(JavaSE复习.assets/image-20210705192414243.png)]](https://img-blog.csdnimg.cn/20210708191525123.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
显然,费时且占地儿。
用StringBuilder完成字符串的拼接,内容变化时,不会产生新的对象
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rbk5iqn7-1625741443298)(JavaSE复习.assets/image-20210705194823121.png)]](https://img-blog.csdnimg.cn/20210708191532353.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
/\*案例:统计两种方式的运行时间比较\*/
static long stringAppend(){
long t1 = System.nanoTime();
String s= "";
for(int i =1; i<= 100000; i++){
s +="A";
}
long t2 =System.nanoTime();
return t2-t1;
}
/\*StringBuilder拼接\*/
static long stringBuilderAppend(){
long t1 = System.nanoTime();
String s= "";
StringBuilder sb = new StringBuilder(s);
for(int i =1; i<=100000; i++){
sb.append("A");
}
s = sb.toString();
long t2 =System.nanoTime();
return t2-t1;
}
草,这个结果太慢了,创建对象,垃圾回收太慢了(主要是垃圾回收):
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u8XlCKGJ-1625741443298)(JavaSE复习.assets/image-20210705200901675.png)]](https://img-blog.csdnimg.cn/20210708191541342.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
明显StringBuilder比加的方式快太多了。
4.集合(容器)
集合:用来存储对象的对象(容器) 。在生活中例如书架…
Object[] 最最最基础的集合。但是数组有局限性。
1.数组长度是固定的,数组扩充时需要复杂的拷贝操作。
2.数组在元素的插入和删除时使用不方便
集合:对基础数据结构的封装,由Java类库提供。
集合的组成
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I565luxd-1625741443299)(JavaSE复习.assets/image-20210706111608998.png)]](https://img-blog.csdnimg.cn/20210708191557915.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
1️⃣Collection
- 接口特点:元素是对象(Object)
- 常用方法
| 方法 | 说明 |
|---|---|
| add(Object o) | 把对象o放入当前集合 |
| addAll(Collection c) | 把集合c中所有的元素放入当前集合 |
| clear() | 清空集合 |
| contains(Object o) | 判断集合中是否存在元素o |
| remove(Object o) | 在当前集合中删除元素o |
| size() | 获取集合的长度 |
| toArray() | 将当前集合转换为Object[] |
| forEach() | 遍历当前集合 |
- 遍历
- 迭代遍历(陈旧了)
/\*\* \*Iterator 迭代器 \* hasNext() 看集合中还有没有下一个元素 \*next() 从迭代器中拿出下一个没被遍历的元素 \*/ Iterator it =list.Iterator(); while(it.hasNext()){ Object o = it.next(); String s = (String)o; System.out.println(s.toUpperCase()); }
- for-each jdk1.5
/\*\* \*把list中的每个元素放在o里 \*/ for(Object o : list){ String s=(String)o; System.out.println(s.toUpperCase()); }
- 自遍历 jdk1.8
class MyConsumer implements Consumer{ public void accept(Object o){ System.out.println(o) } } list.forEach(new MyConsumer()); //通用的逻辑 //=====>终极版 list.forEach(o ->System.out.println(o)); //list.forEach(System.out::println); 方法引用
- 实现类
没有直接实现类,但是它的子接口有实现类
2️⃣List
Collection的子接口
- 接口特点:元素是有顺序,有下标的,元素是可以重复的。
- 常用方法
| 方法 | 说明 |
|---|---|
| add(int pos,Object o) | 把元素o插入到当前集合的pos下标上 |
| get(int pos) | 获得集合中pos下标的元素 |
| indexOf(Object o) | 获得元素o在集合中的下标,如果不存在,返回-1 |
| remove(int pos) | 删除集合中pos下标的元素 |
| set(int pos,Object o ) | 把元素o设置到当前集合的pos下标上 |
- 遍历
- 下标遍历
for(int i = 0;i<list.size();i++){ Object o =list.get(i); String s =(String) o; System.out.println(s.toUpperCase); }
- 迭代遍历
- for-each
- forEach();
- 实现类
1.ArrayList 底层用数组实现 查询快 ,增删慢
2.LinkedList 用链表实现 查询慢,增删快
3.Vector 数组实现 1.0古老版本(舍弃)
与ArrayList的区别:Vector线程安全(不安全好),并发效率低
例如高速公路一直发生事故,那就限制路上只能有一个车。这就是Vector线程安全的样子。
3️⃣Set
Collection的子接口
- 接口特点:元素是无顺序,无下标的,元素的内容不可重复
- 常用方法:无特有,Collection中的方法
- 遍历:
- 迭代遍历
- for-each遍历
- forEach();
- 实现类
存储原理:不同的实现类,有不同的方法保证元素内容不同
- HashSet(散列表)查询也快,增删也快,占据空间稍大。为了最好的利用,我们要让其均匀分配。尽量保证不同对象返回不同整数。
底层链表数组,不按下标顺序存放,是根据hashCode() 与长度取余,放到相应的地方。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uvokWh23-1625741443299)(JavaSE复习.assets/image-20210706092642113.png)]](https://img-blog.csdnimg.cn/20210708191627494.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
假如遇到相同的怎么办???
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-62OQHBBP-1625741443300)(JavaSE复习.assets/image-20210706092726426.png)]](https://img-blog.csdnimg.cn/20210708191635229.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
会先对s3和s4进行内容的比对,如果equals为true,就拒绝加入。如果内容不相同,s4也会放在2下标,并且s3和s4形成链表。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RpNhT8Xr-1625741443300)(JavaSE复习.assets/image-20210706092954612.png)]](https://img-blog.csdnimg.cn/20210708191655119.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
现在问题来了:哈希码不同,即使内容相同也会放入set集合里。这就不能构成不重复。
解决办法就是我们重写hashCode(),让内容相同的哈希码也相同。
public int hashCode(){ return age; //例如用年龄作为哈希码,那么两个人就会比较 return name.hashCode()+age; }如果将自定义的对象放入HashSet,为了保证内容不重复,我们需要覆盖equals对象,保证内容相同的对象返回true;还要覆盖hashCode方法,保证内容相同的对象返回相同的整数,尽量保证不同对象返回不同整数。
- LinkedHashSet HashSet的子类,元素遍历的时候可以按顺序遍历
- TreeSet 自动对元素进行排序,根据排序规则过滤重复元素(很少用)
4️⃣Map
- 接口特点
元素是键值对 键对象:key 值对象:value
key:无顺序,内容不可重复
value:可重复
- 常用方法
| 方法 | 说明 |
|---|---|
| put(k key,V value) | 把key-value键值对放入Map,如果key已经存在,新的value覆盖原有的value |
| V get( k key) | 查找key所对应的value |
| containsKey(K key) | 判断Map中是否存在key这个键 |
| containsValue(V value) | 判断Map是否存在value这个值 |
| size() | 返回Map的长度,键值对的个数 |
| remove(K key) | 删除key 所对应的键值对 |
| keySet() | 返回Map中所有key的集合 就是一个Set |
| values() | 返回map中所有值得集合 就是一个Collection |
- 遍历
- keySet()
Set<Integer> ks = map.keySet(); for(Integer key :ks){ String calue = map.get(key); System.out.println(key +":"+value); }
- values() 遍历所有的值组成的集合
Collection<String> vs = map.values(); for(String value :vs){ sout(value); }
- 自遍历
map.forEach( (k,v)->System.out.println(K+"---"+v) );
- 实现类
- HashMap
与hashSet类似,就是hashMap有值。 链表数组,高版本中修改了,用的红黑树。在原始基础上做了优化。
2. linkedHashMap HashMap的子类,维护键值对的添加顺序
3. TreeMap 自动对key做排序
4. Hashtable 1.0线程安全 慢 不允许用null作为key 或value
5. Properties Hashtable的子类 key和value都是string,通常用语早起的配置文件处理
总结图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EPSGIg0Q-1625741443300)(JavaSE复习.assets/image-20210706111743944.png)]](https://img-blog.csdnimg.cn/20210708191723742.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
蓝线表示学习的时候对比记忆。
泛型
集合存储是Object,无法对元素的类型做出约束,导致类型不安全。
利用泛型,可以预定集合中元素的类型。
interface A <T,V>{
void m1();
}
/\*使用的时候\*/
class B implements A<Double , String>{
/\*谁使用,谁指定\*/
}
--------------------------------------------------------------
集合中使用泛型:
interface LIst<E>{
void add(E o);
E get(int pos);
}
List<String> ls=new ArrayList<String>();
ls.add("abc");
String s=ls.get(0);
LIst ls = new ArrayList();
必须:Type1==Typ2
List ls = new ArrayList();
既然前后必须一致,那么后面可以省略;
LIst ls = new ArrayList<>(); Jdk7
线程安全的集合
ArrayList 所有方法都不是同步方法。
Vector 所有方法都是同步方法。
1️⃣ ConcurrentHashMap
如何既保证线程安全,又保证并发效率很高?
JDK7 以前,采用分段锁。控制锁的力度,把Map分为16个片段,针对每个片段加锁。
(举例:map是一个大厕所,有很多小隔间,一个人进去直接把大门锁了,显然影响效率,而ConcurrentHashMap就相当于锁小隔间的门,只会锁其中的一个片段。)
JDK8以后,采用CAS算法(比较交换),无锁算法,存储效率非常接近于HashMap.
2️⃣ CopyOnWriteArrayList 永远不会改变原始集合中的数据
适用于读操作。并发效率接近于ArrayList,线程安全
- 读操作:获取集合的数据(不需要加锁)
- 写操作:改变集合的数据( 复制新的集合来实现写,效率低 )
3️⃣CopyOnWriteArraySet 原理和CopyOnWriteArrayList一致
队列Queue
队尾进,对头出。
1️⃣LinkedList 同时也实现了队列接口
Queue<String> queue = new LinkedList<>();
线程不安全的类。
2️⃣ ConcurrentLinkedQueue
线程安全的 CAS无锁算法
BlockingQueue 阻塞队列,队列的子接口:当队列为空的时候,从队列中取元素的线程会阻塞,而当队列满的时候,向队列中添加元素的线程会阻塞
- 有界队列:ArrayBlockingQueue有上限,存在满的问题,当队列满的时候,添加元素线程会阻塞
- 无界队列:LinkedBlockingQueue
集合总结:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IowW6IJz-1625741443301)(JavaSE复习.assets/image-20210707164541784.png)]](https://img-blog.csdnimg.cn/20210708191751722.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RcvkD8Jp-1625741443302)(JavaSE复习.assets/image-20210707164807515.png)]](https://img-blog.csdnimg.cn/20210708191758953.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
5.异常
提高程序的容错性:解决程序运行时的问题
异常的分类
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YOMTioKS-1625741443302)(JavaSE复习.assets/image-20210706121333586.png)]](https://img-blog.csdnimg.cn/20210708191813252.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
避免异常:尽可能使异常不出现,不发生
处理异常:当异常发生时,应对这种异常
Throwable 所有异常的父类
|- error 错误 严重的底层错误,不可避免 无法处理
|- Exception 异常 可以处理
|- RuntimeException 子类 运行时异常 未检查异常 可以避免(空指针、数组下标越界、类型转换异常) 可以处理可以不处理
|-非 RuntimeException子类 已检查异常 不可避免,需要处理异常
异常对象的产生和传递
异常对象的产生:
throw 异常对象:抛出一个异常
抛出异常:方法以异常对象作为返回值,返回等同于return
后面的语句就不打印了
异常对象的传递
沿着方法调用链,沿着方法的调用链,逐层返回,直到JVM
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7bhtO3zG-1625741443302)(JavaSE复习.assets/image-20210706124413399.png)]](https://img-blog.csdnimg.cn/20210708191830725.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
这是中止运行,jvm会显示异常名,异常内容和异常路径
自定义异常:
如果想写已检查异常需要extends Exception
如果想写未检查异常需要extends RuntimeException
异常的处理
声明抛出
public void method() throws IOException
throws 异常类名1,异常类名2,…异常类名n
意思:本方法中出现IO异常,我不做任何处理,抛给上层调用处理!
方法覆盖时,子类不能比父类抛出种类更多的异常
捕获异常
try{ 语句1 语句2 ... //遇到异常 去catch处理 } catch(异常类型 e){ } catch(异常类型 e){ e.printStackTrace();//打印异常对象的栈追踪信息 } finally{ 这里面的无论有没有异常都运行 } ......可以同时捕获父类异常和子类异常,但是必须先捕获子类异常,再捕获父类异常。
Java中,有三种try-catch结构:
try{} catch(){} try{} catch(){} finally{} try{} finally{} //无法捕获异常,利用finally必须执行的特点完成特定操作
6.B IO
Java程序的输入和输出
IO流的分类
1️⃣ 流的概念:用来传递东西的对象
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SNxqakbS-1625741443303)(JavaSE复习.assets/image-20210706141329138.png)]](https://img-blog.csdnimg.cn/20210708191844935.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
2️⃣ 流的分类:
- 流的方向:输入流(读取数据)/输出流(写数据)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-865XRdn9-1625741443303)(JavaSE复习.assets/image-20210706141549607.png)]](https://img-blog.csdnimg.cn/20210708191852263.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
- 数据单位: 字节流(以字节为单位,可以处理一切数据)
字符流(字符为单位 = 2字节 ,用来处理文本数据)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lv2YKEsa-1625741443303)(JavaSE复习.assets/image-20210706142032601.png)]](https://img-blog.csdnimg.cn/20210708191859278.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
- 按照流的功能:
节点流:实际负责数据的传输
过滤流:为节点流增强功能
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zoa2av7x-1625741443305)(JavaSE复习.assets/image-20210706142720112.png)]](https://img-blog.csdnimg.cn/20210708191906982.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
IO编程的基本顺序:
- 创建节点流
- 构造过滤流
- 使用过滤流
- 关闭外层流
字节流
InputStream :字节输入流 抽象类,字节流的父类
OutputStream: 字节输出流 抽象类,字节流的父类
子类:文件字节流
- FileInputStream/FileOutputStream
写文件
/\*输出流\*/
public class IOStream {
public static void main(String[] args) {
try {
OutputStream outputStream = new FileOutputStream("a.txt");
outputStream.write('A'); //向a.txt中写一个A
outputStream.close(); //关闭流(这个不该写在这里!后面有讲)
} catch (FileNotFoundException e) {
System.out.println("文件没找到");
} catch (IOException e) {
e.printStackTrace();
}
}
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YgHJkOVj-1625741443305)(JavaSE复习.assets/image-20210706145955581.png)]](https://img-blog.csdnimg.cn/20210708191914894.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
OutputStream outputStream = new FileOutputStream("a.txt",true);追加的方式来打开流
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yN2Wdr5Q-1625741443306)(JavaSE复习.assets/image-20210706150305512.png)]](https://img-blog.csdnimg.cn/20210708191921624.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
如果wirte(‘王’);汉字已经超过了字节的范围
读文件
先不考虑异常的情况下读文件:
public class DuFile {
public static void main(String[] args) throws IOException {
InputStream inputStream = new FileInputStream("a.txt");
while(true){
int a = inputStream.read();
if(a == -1){
break;
}
System.out.println((char) a);
}
inputStream.close();
}
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sHV9TLU3-1625741443307)(JavaSE复习.assets/image-20210706154050866.png)]](https://img-blog.csdnimg.cn/20210708191934439.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
IO流处理异常的方法
常规处理:
public class IOStream {
public static void main(String[] args) {
OutputStream outputStream = null;
try {
outputStream = new FileOutputStream("a.txt",true);
outputStream.write('D'); //向a.txt中写一个A
} catch (IOException e) {
e.printStackTrace();
} finally {
if (outputStream != null){
try {
outputStream.close(); //关闭流
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
代码缺点:太多,麻烦 jdk1.7 提供了 try-with-resource
try-with-resource:带资源的都需要关闭,一定在finally中。
try(定义资源 必须是实现类 AutoCloseable接口的对象){ 代码}
catch(Exception e){}
//定义在try里的资源会自动关闭
写文件异常处理写法:
public class IOStream {
public static void main(String[] args) {
// OutputStream outputStream = null;
// try {
// outputStream = new FileOutputStream("a.txt",true);
// outputStream.write('D'); //向a.txt中写一个A
// } catch (IOException e) {
// e.printStackTrace();
// } finally {
// if (outputStream != null){
// try {
// outputStream.close(); //关闭流
// } catch (IOException e) {
// e.printStackTrace();
// }
// }
// }
try(OutputStream outputStream = new FileOutputStream("a.txt",true)){
outputStream.write('A');
} catch (IOException e) {
e.printStackTrace();
}
}
}
读文件异常处理
public class DuFile {
public static void main(String[] args) {
try (InputStream inputStream = new FileInputStream("a.txt")) {
while (true) {
int a = inputStream.read();
if (a == -1) {
break;
}
System.out.println((char) a);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
文件拷贝
public class FileCopy {
public static void main(String[] args) {
FileOutputStream fos = null;
FileInputStream fis = null;
//要复制的文件
String filename = "a.txt";
try{
fis = new FileInputStream(filename);
fos = new FileOutputStream("new"+filename);
while(true){
int a = fis.read();
if (a == -1){break;}
fos.write(a);
}
} catch (IOException e) {
e.printStackTrace();
}
finally {
if( fis !=null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if( fos !=null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
IO效率最重要!,但是上面的代码执行效率很低,接下来就是提升性能的方法——加一个过滤流
缓冲字节流
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E5FaZn7D-1625741443307)(JavaSE复习.assets/image-20210706162040586.png)]](https://img-blog.csdnimg.cn/20210708191952533.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
过滤流:只能给节点流增加功能
PrintStream可以取代BufferedOutputStream带缓冲的字节输出流,这个就是sout使用的。
System.out.println
- System:类名 java.long.System
- System.out:System类中公开静态常量,是PrintStream类的对象
- println:方法名
BufferedInputStream/BufferedOutputStream 缓冲功能,提高I/O效率
一个流中的构造参数是另外一个流,这个流就是一个过滤流
flush() //关流或者清空缓冲区都可以让缓冲区的该去哪去哪 对于缓冲输出流
改造后的文件拷贝:
public class FileCopy {
public static void main(String[] args) {
FileOutputStream fos = null; //节点流
FileInputStream fis = null; //节点流
BufferedOutputStream out = null; //输出缓冲流,这是过滤流
BufferedInputStream in = null; //输入缓冲流
//要复制的文件
String filename = "a.txt";
try{
fis = new FileInputStream(filename);
in = new BufferedInputStream(fis); //加强节点流的功能,带缓冲
fos = new FileOutputStream("new"+filename);
out = new BufferedOutputStream(fos);//带缓冲的输出流
while(true){
int a = in.read(); //用换出流读数据,存到缓冲区
if (a == -1){break;}
out.write(a); //缓冲输出流王外写
}
} catch (IOException e) {
e.printStackTrace();
}
//关流的时候只需要关最外层的流,例如过滤流包裹节点流,关过滤流就行
finally {
if( in !=null) {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if( out !=null) {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
对象序列化
我们想把对象写入文件要怎么写呢?
把对象通过流来传输叫做对象的序列化。
有些对象可以序列化,有些不能。生活中的例子,例如我搬家的时候,有的可以拆成小的然后搬,有的却不行。
**只有实现了Serializable的接口才能序列化。**就是个标记,告诉IO可以切(序列化)
可以给对象加transient修饰属性,称为临时属性不参与序列化
我们有相应的过滤流:ObjectOutputStream/ObjectInputStream
有out.wirteObject();方法是写对象的。
readObject(); 读对象。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CVjmIXkH-1625741443307)(JavaSE复习.assets/image-20210706171514084.png)]](https://img-blog.csdnimg.cn/20210708192005924.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
对象的克隆
就是在java堆空间中复制一个新对象;
最简单的办法就是用Object中的clone(); 但是要重写,修改修饰符。而且对象必须是一个支持克隆的对象实现Cloneable接口。
注意:他的克隆方式:浅拷贝
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rPNyIYTm-1625741443308)(JavaSE复习.assets/image-20210706174159566.png)]](https://img-blog.csdnimg.cn/20210708192012815.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
teacher指向的同一个对象。
浅拷贝:对象复制,但是对象内的属性不会复制
深拷贝:对象复制,里面的属性也复制,就会有两个teacher对象。
如何实现深拷贝?对象序列化。这样的地址完全不同
字符流
专门处理char,String数据,而且可以方便的处理字符的编解码
‘A’ ----> 65 :编码 str.getBytes("GBK")
65 ----> ‘A’ :解码 String( ,"GBK")
不同国家有不同字符集,当编码格式与解码格式不同就会出现乱码现象。
- ASCII 美国 字符集:英文字符
- ISO-8859-1 西欧字符
- GB2312 GBK简体中文
- Big5 繁体中文
- Unicode 全球统一的编码方式
- UTF-16(java采用的编码)
- UTF-8 (常用的)
Reader/writer
抽象类 字符流的父类
子类:FileReader/FileWriter 文件字节流,节点流
BufferedReader/BufferdWriter 过滤流,缓冲作用
PrintWriter带缓冲的字符输出流,通常可以取代BufferdWriter
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ShtKtTte-1625741443308)(JavaSE复习.assets/image-20210706184451594.png)]](https://img-blog.csdnimg.cn/20210708192023238.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TuiOy4cR-1625741443309)(JavaSE复习.assets/image-20210706184506426.png)]](https://img-blog.csdnimg.cn/2021070819203076.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
读:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CH2i1OCZ-1625741443309)(JavaSE复习.assets/image-20210706184728031.png)]](https://img-blog.csdnimg.cn/20210708192039991.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
技巧:先创建字节流然后用InputStreamReader/OutputStreamWriter过滤流把字节流构造成字符流 (桥转换类)
可以在桥转换的过程中指定编解码的方式
OutputStream fos = new FileOutputStream("a.txt");
Wrirer fw = new OutputStreamWriter(fos,"GBK");
File类
file对象代表了磁盘上的一个文件 或 目录(文件夹),用来实现一些文件操作。
public class FileTest {
public static void main(String[] args) throws Exception {
File file = new File("1.txt");
file.createNewFile();//创建1.txt文件
file.delete();//删除1.txt //空目录
file.mkdirs(); //创建目录
file.delete(); //删除目录
System.out.println(file.exists());//file.exists();判断是否存在
file.getAbsolutePath();//获得绝对路径
file.lastModified();//获取最后修改时间
file.length();//获取长度
File f = new File("D:\\");
//file.listFiles();//返回文件数组
}
}
无法访问文件内容。
7.多线程(并发编程)
注重思想,我们写一个页面,如果大量用户访问,那么有上亿个线程,是否会出现数据出错,卡顿等。
并发编程:多个任务同时执行
进程:OS中并发的一个任务
线程:在一个进程中,并发的顺序执行流程。
并发原理:CPU分时间片交替执行,宏观并行,微观串行,由OS负责调度。如今的CPU已经发展到了多核CPU,真正存在并行。
线程的三要素:
- CPU OS负责调度
- 数据 堆空间,栈空间(多线程堆空间共享,栈空间独立)
- 代码 (主函数就是主线程)
如何创建线程?
方法1(初始):
- 实现Runnable接口,实现run方法
- 创建Runnable对象(任务对象)
- 通过Runnable对象,创建Thread对象(线程对象)、
现在只是有线程对象:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-87vAmnwO-1625741443309)(JavaSE复习.assets/image-20210706195053998.png)]](https://img-blog.csdnimg.cn/20210708192059305.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
4. 调用线程对象start()启动线程(向操作系统申请创建线程)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u0Jp5oUp-1625741443310)(JavaSE复习.assets/image-20210706195216125.png)]](https://img-blog.csdnimg.cn/20210708192105504.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
现在的代码中就有三个线程了,main,t1,t2
方法2(老式):
- 直接继承Thread类,覆盖run方法
- 创建继承的Thread对象
- 调用start()方法
线程的基本状态
1️⃣程序最开始的时候主线程处于运行状态
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WTudi9JT-1625741443310)(JavaSE复习.assets/image-20210706200657211.png)]](https://img-blog.csdnimg.cn/20210708192112294.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
2️⃣ 主线程执行创建对象,t1,t2处于初始状态
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ol7WBxMp-1625741443310)(JavaSE复习.assets/image-20210706200833488.png)]](https://img-blog.csdnimg.cn/2021070819211942.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
3️⃣ 调用start()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3wvYbFoB-1625741443310)(JavaSE复习.assets/image-20210706200915281.png)]](https://img-blog.csdnimg.cn/20210708192125859.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
4️⃣ main结束,OS调度,运行run里的代码,选谁呢??
选择的规则:不同OS不同任务调度策略。但是因为start()耗时,所以经常看见t1先执行,是因为这时候t1还没准备好
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gDoV9XJf-1625741443311)(JavaSE复习.assets/image-20210706202317962.png)]](https://img-blog.csdnimg.cn/20210708192133408.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
5️⃣ t1时间片到期,t1回到可运行,OS选择下一个线程(不一定选谁)可能还是t1。
6️⃣ 线程结束
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JXqmwm06-1625741443311)(JavaSE复习.assets/image-20210706202540142.png)]](https://img-blog.csdnimg.cn/20210708192141738.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
线程的等待
等待状态:线程执行过程中发现执行不下去了,缺少条件,没有条件之前进入等待状态。(例如等红绿灯)
- 等待数据的输入 scanner/B io 不确定时间
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jdKvkObo-1625741443311)(JavaSE复习.assets/image-20210706203552344.png)]](https://img-blog.csdnimg.cn/20210708192149191.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
- sleep() 限时等待,给休眠时间
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sMfCwn2K-1625741443312)(JavaSE复习.assets/image-20210706203816165.png)]](https://img-blog.csdnimg.cn/20210708192158186.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
线程中的sleep()异常只能用try-catch解决,因为方法覆盖不能抛出比父类多的异常。
还有一个join() 线程同步中讲解。
线程池 JDK5
创建一个线程只为一个任务所服务会造成资源浪费。(频繁创建销毁线程就是资源浪费)
线程池的概念:(就像高铁站出租车区域,来客人就去拉客,送到后还回来继续等下一个任务,或者办公室的例子)当一个任务结束时,对应的线程资源不会销毁,而是回到线程池中等待下一个任务。
**线程池的好处:**可以控制最高并发数
有了线程池之后,Thread类就不推荐使用了!
线程池的编码:
一个ExecutorService对象就代表一个线程池
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cc5Oqgz0-1625741443313)(JavaSE复习.assets/image-20210706212145554.png)]](https://img-blog.csdnimg.cn/20210708192208386.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
newCachedThreadPool();长度不固定的,有几个任务就有几个线程
用匿名内部类简化编码
executorService.submit(new Runnable() {
@Override
public void run() {
for (int i = 1; i <= 100; i++) {
System.out.println("CCC"+i);
}
}
});
用lambda表达式简化
executorService.submit(()->{
for (int i = 0; i <= 100; i++) {
System.out.println("CCC"+i);
}
});
Callable和Future接口
用来取代Runnable接口、
Runnable的缺点:
- run没有返回值
- 不能抛异常
Callable接口允许线程有返回值,也允许线程抛出异常
Future接口用来接受返回值
案例:计算1~10000的和,用两个线程,一个算基数,一个算偶数,最后相加。
主要问题:如何获得返回值
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F0fjm2rI-1625741443313)(JavaSE复习.assets/image-20210706215722854.png)]](https://img-blog.csdnimg.cn/20210708192218835.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
返回值存在Future对象中
package com.gaoji;
import java.util.concurrent.*;
import static java.util.concurrent.Executors.*;
/\*\*
\* @author 王泽
\*/
public class AddTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService es = newFixedThreadPool(2);
// es.submit(new task1());
// es.submit(new task2());
//如何拿到两个任务的返回值呢?我们只是扔给了线程池
Future<Integer> f1 = es.submit(new task1());
Future<Integer> f2 = es.submit(new task1());
//...主线程执行自己的任务
//获取返回值,能取到就取,取不到就等待。
Integer result1 = f1.get();//从future中取到返回值
Integer result2 = f2.get();//从future中取到返回值
System.out.println(result1+result2);
es.shutdown();
}
}
/\*\*所有基数的和\*/
class task1 implements Callable<Integer>{
@Override
public Integer call(){
int result = 0;
for (int i = 1; i < 10000; i+=2) {
result +=i;
}
return result;
}
}
/\*\*所有偶数的和\*/
class task2 implements Callable<Integer>{
@Override
public Integer call(){
int result = 0;
for (int i = 2; i < 10000; i+=2) {
result +=i;
}
return result;
}
}
线程的同步(重点)
两个线程同时往一个集合中放元素,
当一个线程对另一个线程join()的时候,这个线程就会等待状态
例如:主线程中写t1.join() t1结束,主线程才继续。
t1.join(); //mian线程等待t1结束
引出问题案例分析:
正确的过程(假设t1先启动):
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RxVwuxHw-1625741443313)(JavaSE复习.assets/image-20210707084522266.png)]](https://img-blog.csdnimg.cn/20210708192227644.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
实际上的顺序
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s4AIXBf9-1625741443313)(JavaSE复习.assets/image-20210707084920851.png)]](https://img-blog.csdnimg.cn/20210708192235752.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
因为sleep,出现了上面的情况,但是不sleep依旧有可能会出现(要执行index++的时候时间片到期了)
多线程共同访问同一个对象,由于多线程中堆空间共享,如果破坏了不可分割的操作,就可能导致数据不一致。
👨🚀 临界资源:被多线程共同访问的对象
💁♂ 原子操作:不可分割的操作,要么全部执行要么都不执行
怎么解决呢?——加锁
synchronized
开发中不鼓励使用
//对obj对象加锁的同步代码块
synchronized (obj) {}
Java中,每个对象都有一个互斥锁标记(monitor),用来分配一个线程
只有拿到对象obj锁标记的线程,才能进入到obj加锁的同步代码块。
t2 synchronized (obj){ t1//即使sleep,t2依旧进不来 } t2想进来进不来,这就是阻塞状态了必须进入到所标记代码块才能执行,线程离开同步代码块时,会释放对象的锁标记。
// 修电线的代码: synchronized (闸盒对象){ 将闸盒变为OFF 爬上电线杆 检修电路 爬下电线杆 将闸盒变为ON } 只有这一套完成后,别人才能拿到闸盒的钥匙。
线程的阻塞状态
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xcWKtydn-1625741443313)(JavaSE复习.assets/image-20210707091129689.png)]](https://img-blog.csdnimg.cn/20210708192248349.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
线程安全的对象
该对象成为临界资源,被多线程访问时,不会发生原子操作被破坏,导致数据不一致的问题。
锁的是对象
Girl :对象
Boy:线程
拿到Girl锁标记的Boy,成为Girl的男朋友
synchronized(girl){
拥抱;
接吻;
壁咚;
.........
}// 分手之后,才能让别人成为男朋友
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yTQHJOR5-1625741443314)(JavaSE复习.assets/image-20210707093001595.png)]](https://img-blog.csdnimg.cn/20210708192256731.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0FyZXNfX18=,size_16,color_FFFFFF,t_70)
同步方法
只有获得对象obj所标记的线程,才能调用obj的同步方法
调用之前竞争obj的锁标记
方法调用结束时,会释放obj的锁标记
public class A{ public synchronized void m(){} //同步方法 对this加锁的同步代码块 } A a1 = new A(); A a2 = new A(); a1.m(); //线程获得a1的锁标记 a1.m();//线程获得a2的锁标记synchronized void m(){} ====== void m(){ synchronized(this){ } }
死锁
synchronized不仅仅会造成并发效率低,还会造成死锁问题。
synchronized(a){
//t1
synchronized(b){
}
}
------死锁了
synchronized(b){
//t2
synchronized(a){
}
}
死锁靠线程之间的通信来解决,t1调用Object中的wait(),会释放t1所有锁标记,进入等待状态。 t2调用notify,通知所有调用过wait()的线程,离开等待状态。
wait() 和sleep() 有什么区别??
都会让线程进入等待状态,wait会释放锁标记,sleep不会释放锁标记。
(电话亭打电话,你在里面睡着了,锁依旧是锁着,这是sleep,如果无人接听,你先出去让别人打,这就是wait)
避免多线程访问临界资源,造成数据不一致的办法:
- 用数据最好用局部变量,这样就可以没有临界资源。(局部变量存在栈空间,栈空间是线程独立的)
- 尽量使用无锁算法,使用线程安全同时并发效率也很高的对象
- 使用锁标记来控制线程安全
8.反射和设计模式
反射是底层技术 通常用来实现框架和工具
运行时的类型判定。
目前创建对象都是采用硬编码
new Dog。
类对象
1️⃣类加载:当JVM第一次使用一个类的时候,它需要将这个类对应的字节码文件读入JVM,从而获取这个类的全部信息(类的父类,拥有哪些属性,方法,构造方法等等)并保存起来(保存在JVM方法区)
2️⃣类对象:类加载的产物,包含了一个类的全部信息。
3️⃣ 类对象所属的类叫 Class类
- 类的对象:该类的对象 Dog类的对象---->一只狗
- 类对象:记录类信息的对象 Dog类对象,相当于动物园的牌子
- 类加载:就相当于你不认识这个动物,你把这个动物是啥记忆在脑子里
⭐️获得类对象的三种方式:
- 类名.class 直接获取类对象,也可以获取到8种基本类型的对象
- 类的对象.getClass() 获取类对象,例如你去动物园看见一直候,你问他你啥对象??🐒:自己看牌子!
- class.forName(“类的全名”) 通过类名字符串获得类对象
一个类的类对象只能有一个,在JVM中只会产生一个
拿到了类对象之后 获取类的信息
类对象.getName() //查看类名
类对象.getSuperclass().getName() //查看父类名
Class[] cs = 类对象.getInterfaces();//获得一个类实现的所有接口
属性方法构造方法又会被封装
getMethods() //获取所有公开的方法的Method对象(子类父类都可以拿到)
getDecalredMethods()//获得本类中所有方法的Method对象
getMethod()/getDeclaredMethod() //根据方法名和参数表,获得类中的某个方法
Class:封装了类的信息
Method:封装了方法的信息
3️⃣获取类的对象我们可以对类对象调用newInstance() 通过类对象,创建类的对象(手里有个美女介绍,我直接newInstance 直接来一个,美女的对象)
String classname="com.girl.FullMoneyGirl"; //类名
Class c = Class.forName(classname); //获得类对象
Object o = c.newInstance(); //创建类的对象
4️⃣ 调用方法
利用Method对象.invoke() 通过Method调用该方法
String methodname="look"; //方法名
Method m = c.getMethod(methodname); //通过类对象c获取方法
m.invoke(o);
调用对象的私有方法
String methodname="ppp"; //方法名
Method m = c.getDeclaredMethod(methodname); //通过类对象c获取方法
m.setAccessible(true);
m.invoke(o);
三、设计模式
🗡共有23种设计模式,好书推荐:《java与模式》
1.单例设计模式
编写一个类,这个类只能有一个对象。
1️⃣ 饿汉式
ClassA a1 = ClassA.newInstance(); //获得对象
class ClassA{
private static ClassA instance = new ClassA(); //先创建一个对象,作为静态的属性,ClassA类的唯一对象
public static ClassA newInstance(){
return instance;
}//调用静态方法 返回已经创建的对象
private ClassA(){} //防止用户用构造方法创建对象导致不是单例
}
应用场景:比较常用,不会有并发问题,但是浪费了存储空间
2️⃣懒汉
对象的创建时机不一样,当需要对象时,创建对象,有并发效率问题
class ClassB{
private static ClassB newInstance(){
if(instance == null) instance = new ClassB();
return instance;
}
private ClassB(){}
}
如果是多线程调用的话,这种懒汉模式就不是单例的。考虑并发的问题,导致数据不一致。
/\*启动两个线程,创建懒汉模式\*/
new Thread(()->ClassB.newInstacnce()).start();
new Thread(()->ClassB.newInstacnce()).start();
正确写法:
class ClassB{
private static ClassB instance = null;
public static synchronized ClassB newInstance(){
if(instance == null) instance = new ClassB();
return instance;
}
private ClassB(){}
}
但是加了锁之后,就降低了并发效率。
3️⃣ 集合了饿汉式懒汉式的优点
//类加载的时候线程安全,只有需要的时候才创建对象。
//Holder只会加载一次
class ClassC{
static class Holder{
static ClassC instance = new ClassC();
}
public static ClassC newInstance(){
return Holder.instance;
}
private ClassC(){}
}
2.工厂模式
使用反射进行对象创建,IO流读取文件
开闭原则:软件对修改关闭,对拓展开放。
利用工厂创建对象。
public static Animal createAnimal(){
String classname = null;
Properties ps = new Properties();
try(
FileInputStream fis = new FileInputStream("config.txt")
){
ps.load(fis);
classname = ps.getProperty("animal");
class c = Class.forName(classname);
Object o = c.newInstance();
return (Animal)o;
}
catch(Exception e){
e.printStackTrace();
return null;
}
}
四、常见算法
1.汉诺塔问题
❓ 有A B C 三个柱子,和若干个大小不同的圆盘,起初圆盘都在A柱上,小盘在上。现在要把A柱的盘子转到B柱上。(每次只能移动一个,且小盘子在上面)
思考过程:把大问题化小。如果A柱上有两个盘子,先把A上的小盘子移动到C,然后把A 上的大盘子移动到B ,然后把C柱上的小盘子移动到B。 这样就是每次移动一个盘子。下面是步骤:
- 先移动(n-1)个盘子 从A 到 C -----小问题
- 将最底层大盘子移动到B
- n-1 个盘子 从C 到 B -------大问题
- 设计函数
package com.jichu; /\*\* \* @author 王泽 \*/ public class HanNuoTa { public static void main(String[] args) { transfer(5,'A','B','C'); } /\*\* \* 汉诺塔方法: \* n:移动几个盘子 \*form:从哪个柱子离开 \*to:移动到哪个柱子 \*temp:借助哪个柱子 \* \*/ static void transfer( int n, char from , char to, char temp){ //返回条件 if (n == 0) { return; } //把n-1个盘子从 from 移动到temp 借助 to transfer(n-1,from,temp,to); //将大盘子从from 移动到 to System.out.println(from+"----->"+to); //把n-1 个从temp 移动到 to 借助 from transfer(n-1,temp,to,from); } }
2.排序
1.冒泡排序
用相邻的两个元素比较,按照排序要求对调位置。
👀 我们会发现,每一轮冒泡排序会把最大(最小)的排到最后,第二次冒泡排序就不包含最后一个。n个元素要做n-1次排序。
package com.suanfa.paixu; /\*\* \* @author 王泽 \*/ public class MaoPao { public static void main(String[] args) { int[] a = {3,8,6,9,2,7}; System.out.println("数组的长度=="+a.length); //冒泡排序 for (int i = 0; i < a.length-1; i++) { //相邻元素比较 for (int j = 0; j <a.length-1-i ; j++) { if(a[j]>a[j+1]){ int temp = a[j]; a[j]=a[j+1]; a[j+1] = temp; } } } //打印 for (int i = 0; i < a.length; i++) { System.out.println(a[i]+" "); } } }
五、常见机试题
🤑 主要用于提升编码能力,重要的编码在于集合与IO。更新中。。。。
最后总结
ActiveMQ+Kafka+RabbitMQ学习笔记PDF




关于分布式,限流+缓存+缓存,这三大技术(包含:ZooKeeper+Nginx+MongoDB+memcached+Redis+ActiveMQ+Kafka+RabbitMQ)等等。这些相关的面试也好,还有手写以及学习的笔记PDF,都是啃透分布式技术必不可少的宝藏。以上的每一个专题每一个小分类都有相关的介绍,并且小编也已经将其整理成PDF啦
果A柱上有两个盘子,先把A上的小盘子移动到C,然后把A 上的大盘子移动到B ,然后把C柱上的小盘子移动到B。 这样就是每次移动一个盘子。下面是步骤:
- 先移动(n-1)个盘子 从A 到 C -----小问题
- 将最底层大盘子移动到B
- n-1 个盘子 从C 到 B -------大问题
- 设计函数
package com.jichu; /\*\* \* @author 王泽 \*/ public class HanNuoTa { public static void main(String[] args) { transfer(5,'A','B','C'); } /\*\* \* 汉诺塔方法: \* n:移动几个盘子 \*form:从哪个柱子离开 \*to:移动到哪个柱子 \*temp:借助哪个柱子 \* \*/ static void transfer( int n, char from , char to, char temp){ //返回条件 if (n == 0) { return; } //把n-1个盘子从 from 移动到temp 借助 to transfer(n-1,from,temp,to); //将大盘子从from 移动到 to System.out.println(from+"----->"+to); //把n-1 个从temp 移动到 to 借助 from transfer(n-1,temp,to,from); } }
2.排序
1.冒泡排序
用相邻的两个元素比较,按照排序要求对调位置。
👀 我们会发现,每一轮冒泡排序会把最大(最小)的排到最后,第二次冒泡排序就不包含最后一个。n个元素要做n-1次排序。
package com.suanfa.paixu; /\*\* \* @author 王泽 \*/ public class MaoPao { public static void main(String[] args) { int[] a = {3,8,6,9,2,7}; System.out.println("数组的长度=="+a.length); //冒泡排序 for (int i = 0; i < a.length-1; i++) { //相邻元素比较 for (int j = 0; j <a.length-1-i ; j++) { if(a[j]>a[j+1]){ int temp = a[j]; a[j]=a[j+1]; a[j+1] = temp; } } } //打印 for (int i = 0; i < a.length; i++) { System.out.println(a[i]+" "); } } }
五、常见机试题
🤑 主要用于提升编码能力,重要的编码在于集合与IO。更新中。。。。
最后总结
ActiveMQ+Kafka+RabbitMQ学习笔记PDF
[外链图片转存中…(img-NSxXVnXY-1714873073137)]
[外链图片转存中…(img-qLEbB4BB-1714873073139)]
[外链图片转存中…(img-kTpKpDkk-1714873073139)]
[外链图片转存中…(img-VoPG0DdM-1714873073140)]
关于分布式,限流+缓存+缓存,这三大技术(包含:ZooKeeper+Nginx+MongoDB+memcached+Redis+ActiveMQ+Kafka+RabbitMQ)等等。这些相关的面试也好,还有手写以及学习的笔记PDF,都是啃透分布式技术必不可少的宝藏。以上的每一个专题每一个小分类都有相关的介绍,并且小编也已经将其整理成PDF啦















 178
178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









