







信号量S,初始值为0或某个正整数,取值范围为 [-(n-k),k],当S为正时,表示可用的资源数,当S为负时,表示正在等待的进程数。
PV操作:
//P减一操作:S>=0系统有资源,进程执行,S<0进程进入阻塞状态
//V加一操作:S>0进程执行,S<=0系统中有等待使用资源的进程,唤醒等待的进程
wait(S){
while(S<=0);
S–;
}
signal(S){
S++;
}
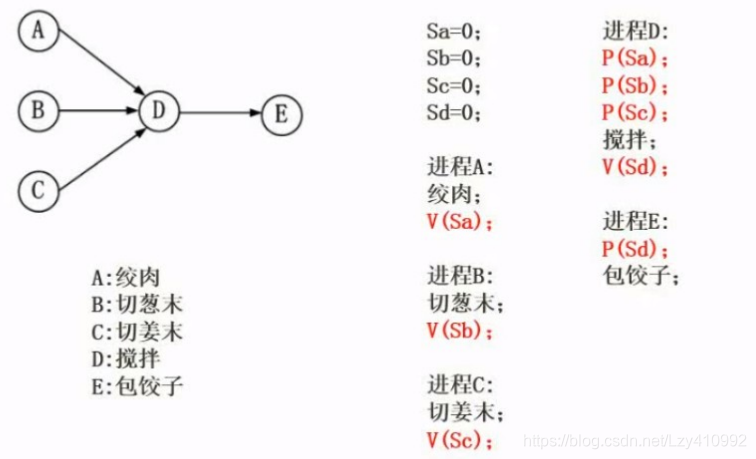
生产者消费者模型:

例题:
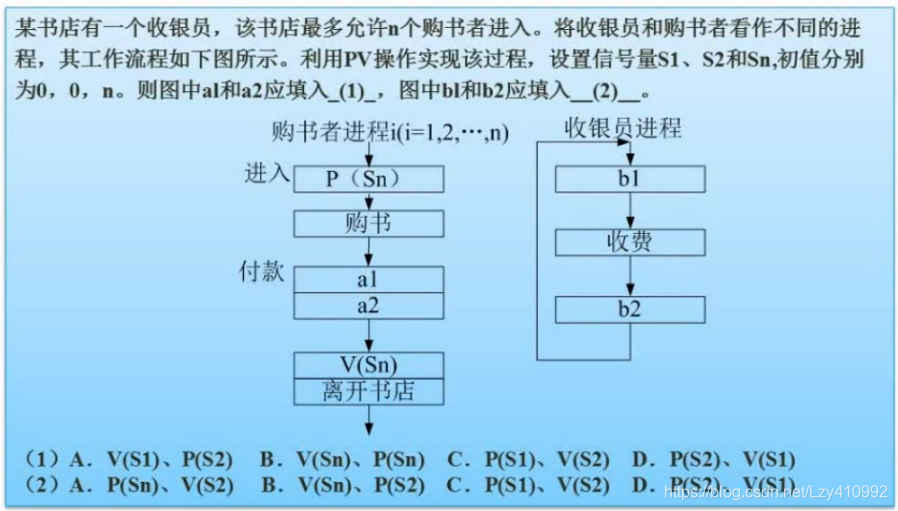
答案:A、C
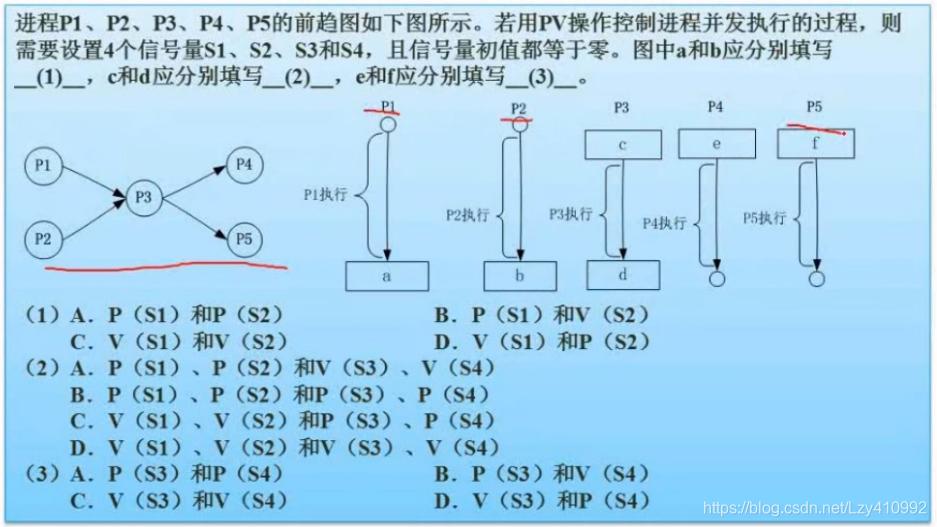
答案:
死锁问题:
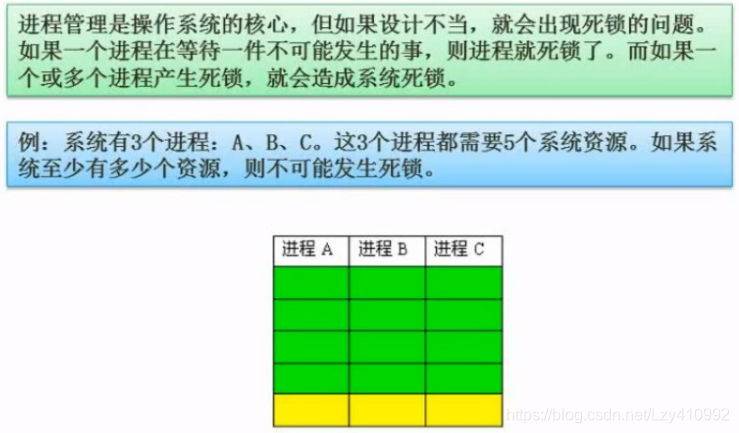
假设有12个资源,每个进程分配4个资源,则刚好发生死锁,任意一个进程再获得一个资源时,死锁解除。
k个进程,需要n个资源时,不发生死锁的最少资源数 = k*(n-1)+1
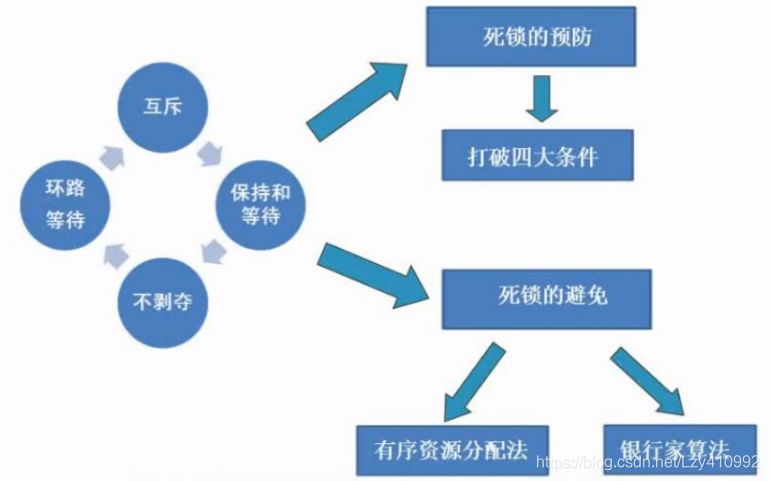
死锁形成的条件: 互斥、保持和等待、不剥夺、环路等待中任何一个发生
解决死锁问题的方案: 死锁的预防、死锁的避免(银行家算法)

例题:
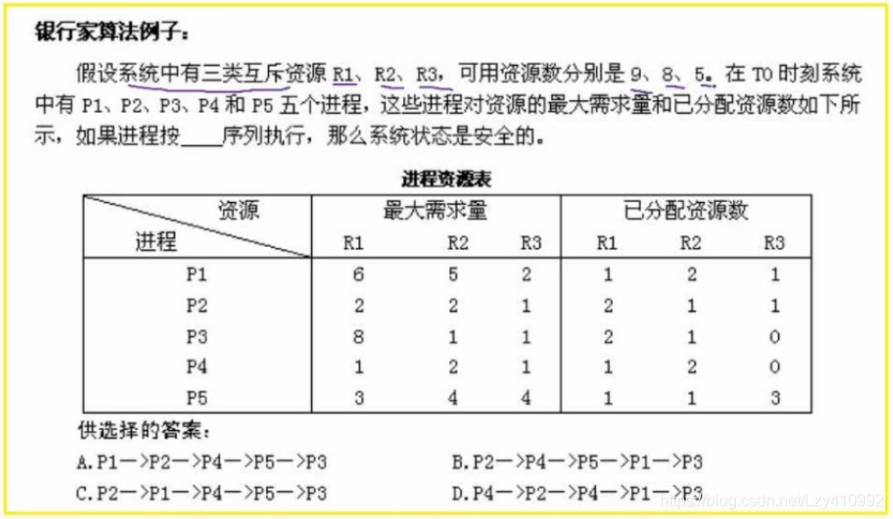
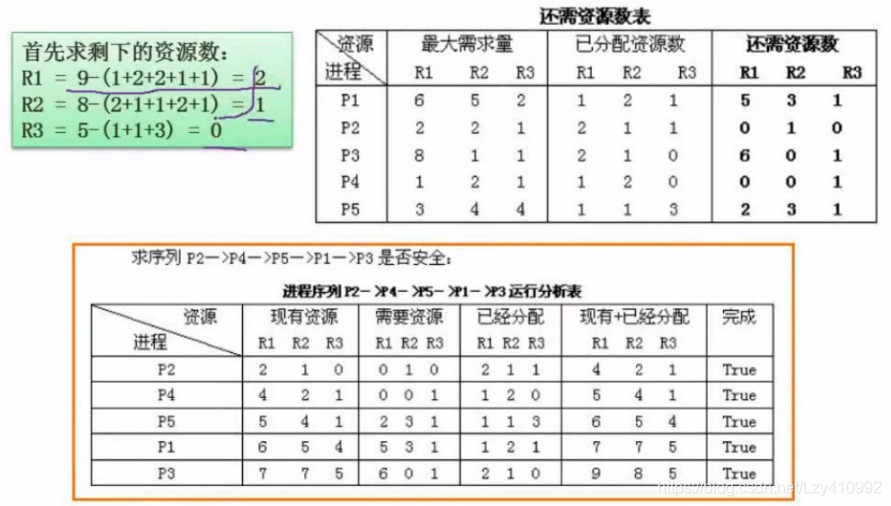
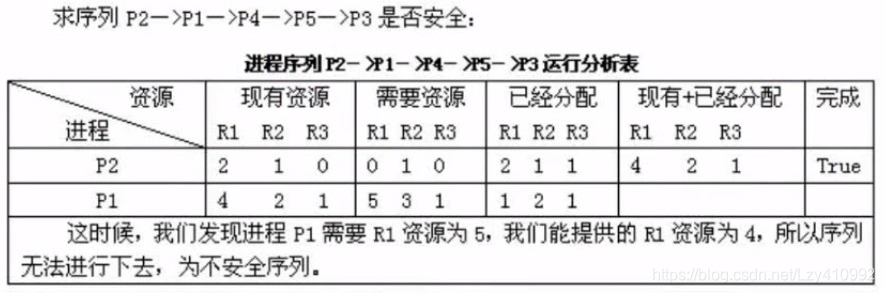
进程资源图:
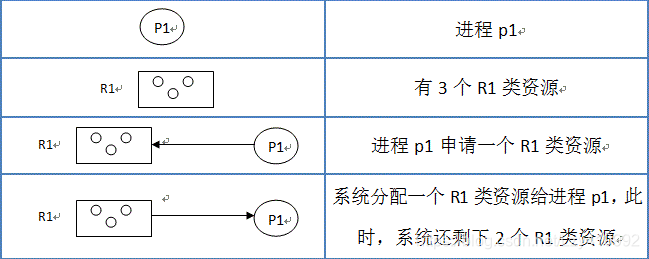
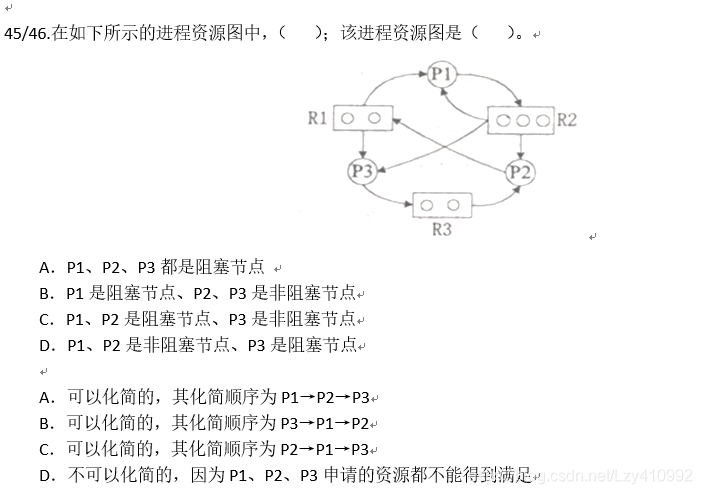
解析:
R1有两个资源,一个分配给了P1,一个分配给了P3,此时P2申请R1的资源,因为R1此时没有可用资源,P2堵塞。
R2有三个资源,已经给P1,P2,P3,各自分配了一个资源,而P1此时又再次申请资源R2,P1堵塞
R3有两个资源,已经分配给P2一个,P2申请一个资源,分配给它,所以P3是非阻塞结点
化简:看从没有阻塞的结点开始,删去P3周围所有的bian边,使其成为一个孤立的点,然后看剩下的资源按上述步骤再次进行分配,若到最后只剩下一群孤立的点,则说明该资源图是可以化简的。
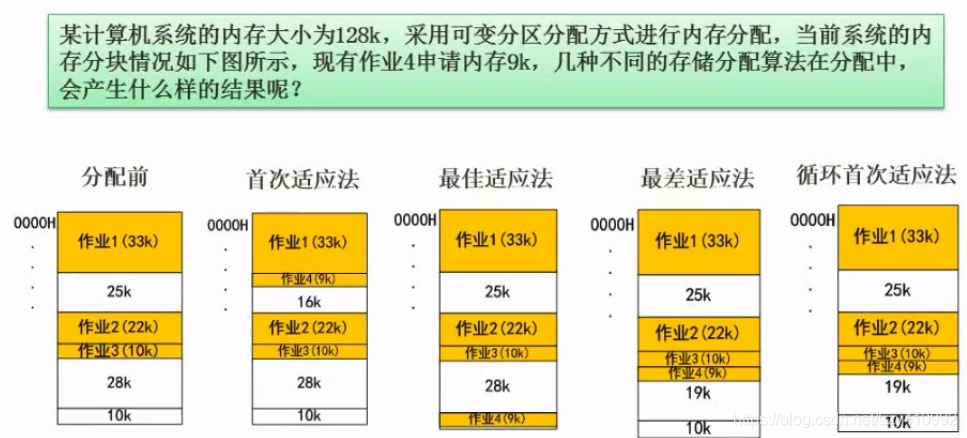
基于顺序搜索的动态分区分配算法:
首次适应(first fit,FF)算法:从链首开始顺序査找,直至找到一个大小能满足要求的空闲分区为止。
循环首次适应(next fit,NF)算法:不再是每次都从链首开始查找,而是从上次找到的空闲分区的下一个空闲分区开始査找,直至找到一个能满足要求的空闲分区。
最佳适应( best fit,BF)算法:每次为作业分配内存时,总是把能满足要求、又是最小的空闲分区分配给作业,避免“大材小用”。
最坏适应( worst fit,WF)算法:与最佳适应算法相反:它在扫描整个空闲分区表或链表时,总是挑选一个最大的空闲区,从中分割一部分存储空间给作业使用。
页式存储:
逻辑地址=页号+页内地址
物理地址=物理块号+物理地址
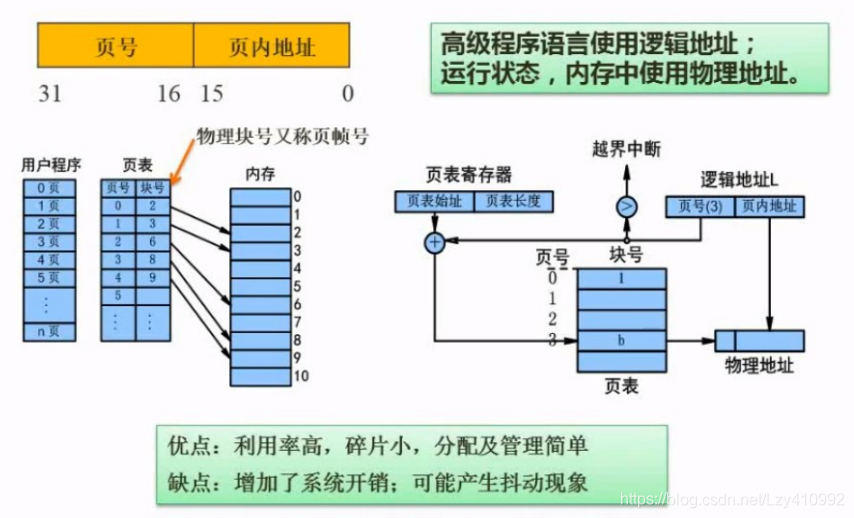
例题:
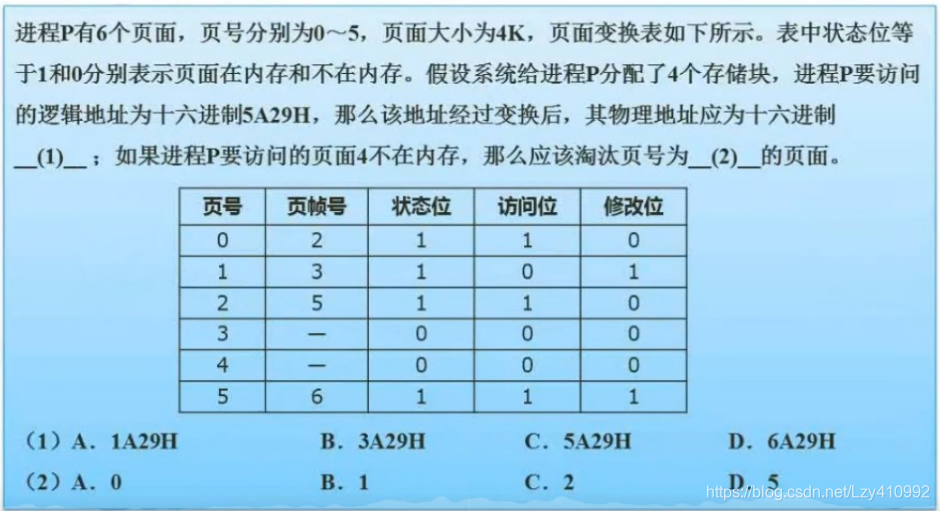
答案:D、B
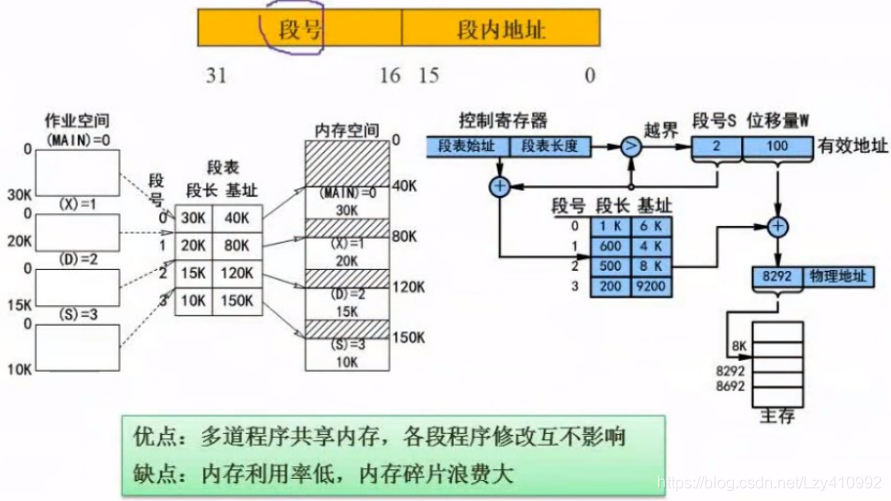
段式存储:
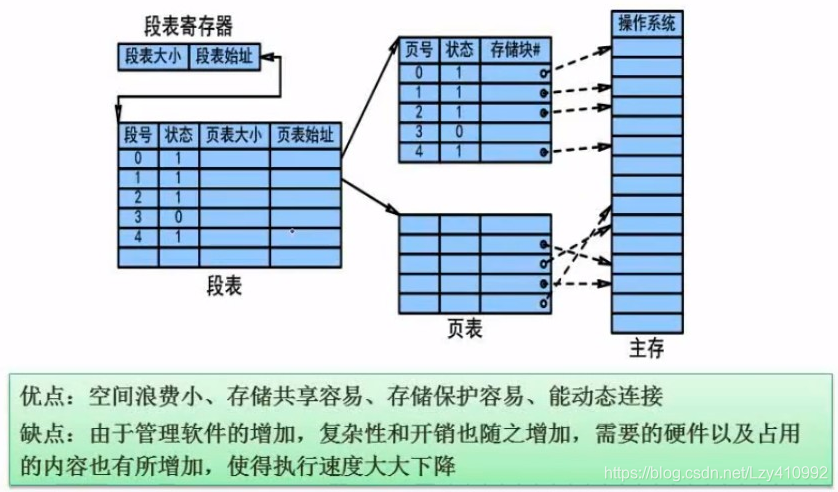
段页式存储:
快表:

页面置换算法:

先进先出算法:
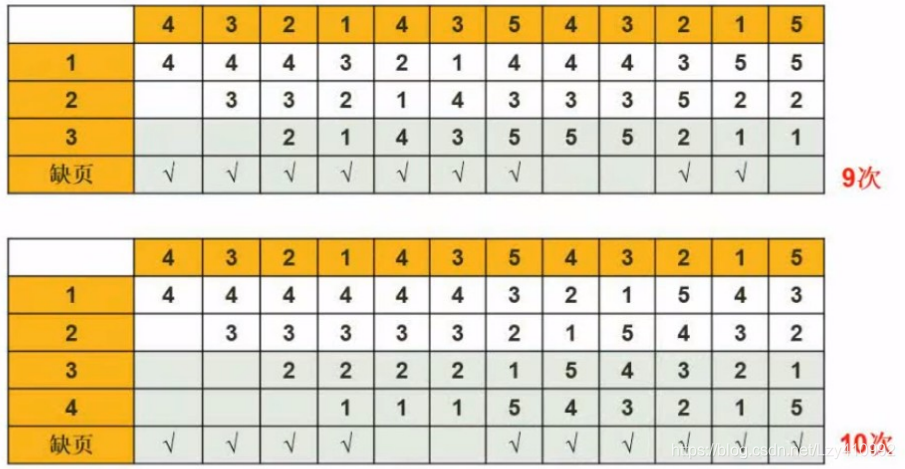
最近最少使用算法:
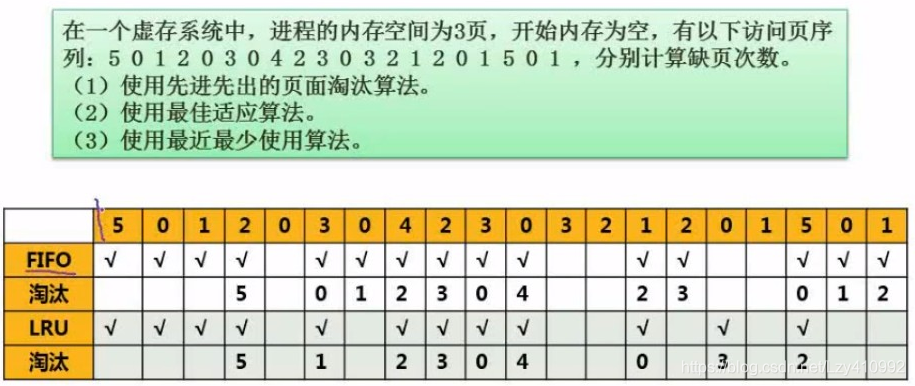
例题:
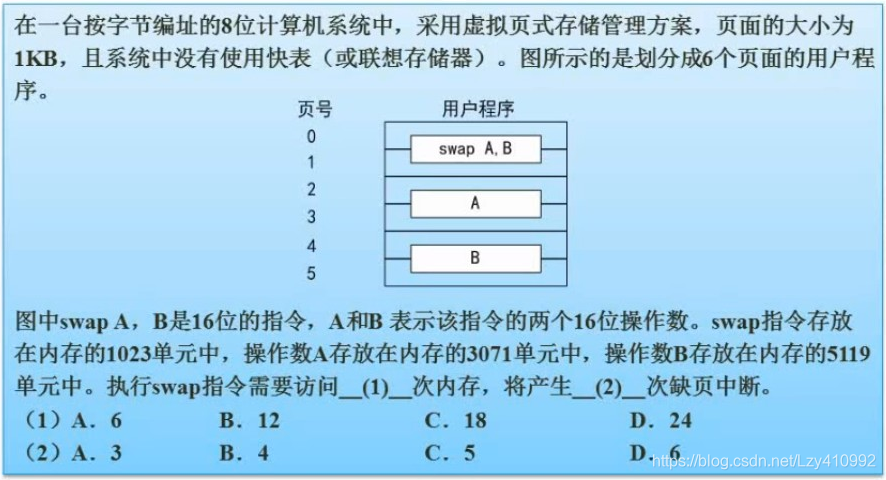
答案:B、C
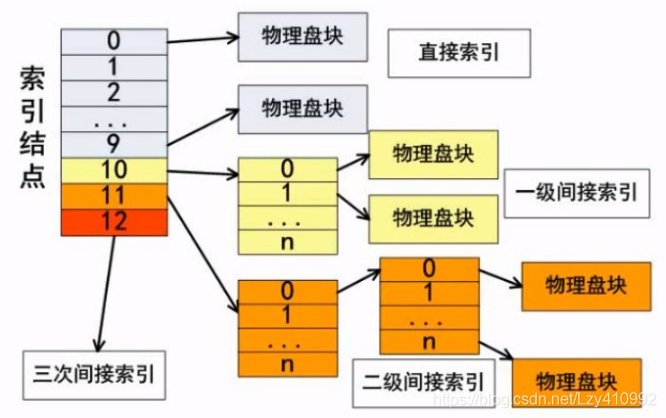
索引文件结构默认13个节点
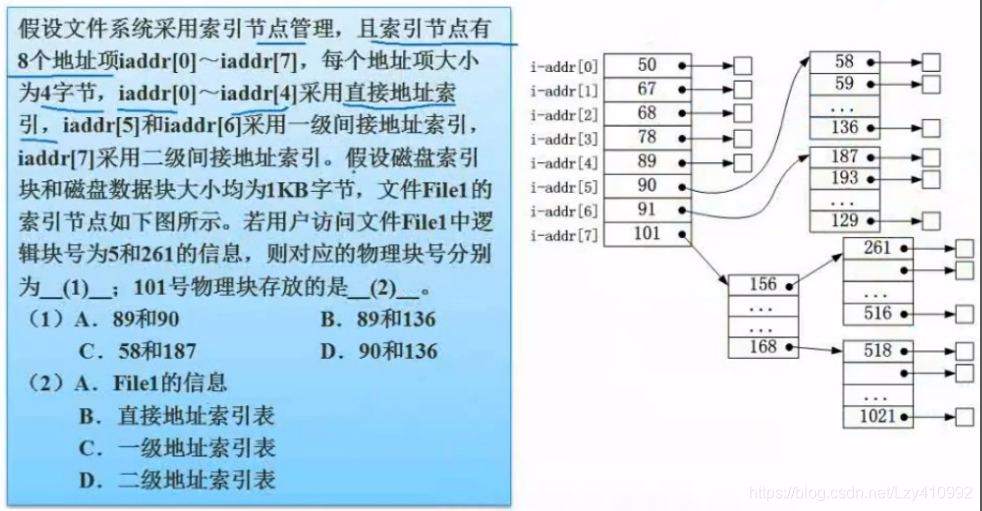
每个数据项的大小是4B,所以一个磁盘块中可以存 1 KB / 4 B = 1024 / 4 = 256,而前5个块(0~4)采用直接地址,所以,逻辑号为5的对应物理块号为58,而编号为261的对应第262个物理块,即编号为187的物理块(直接索引5个 + 90对应的256个 = 261个)。
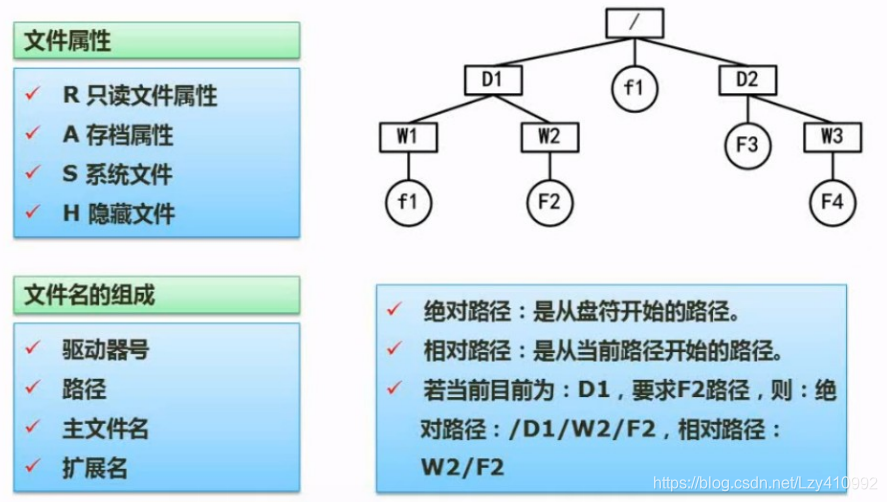
树形目录结构:
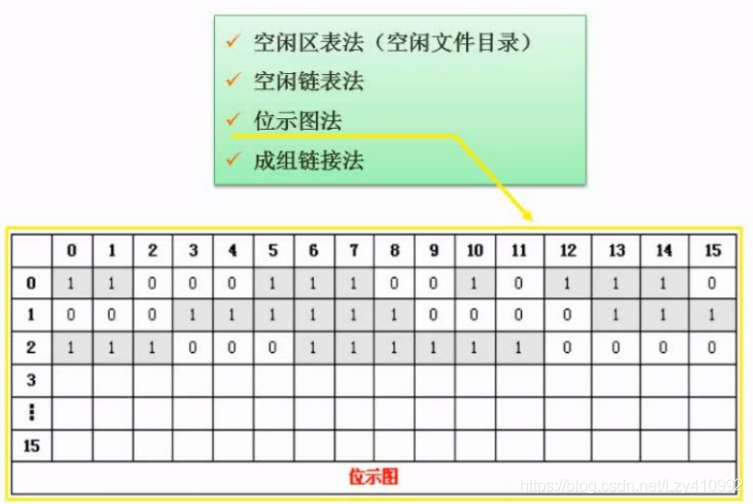
空闲存储空间管理:
总结
上述知识点,囊括了目前互联网企业的主流应用技术以及能让你成为“香饽饽”的高级架构知识,每个笔记里面几乎都带有实战内容。
很多人担心学了容易忘,这里教你一个方法,那就是重复学习。
打个比方,假如你正在学习 spring 注解,突然发现了一个注解@Aspect,不知道干什么用的,你可能会去查看源码或者通过博客学习,花了半小时终于弄懂了,下次又看到@Aspect 了,你有点郁闷了,上次好像在哪哪哪学习,你快速打开网页花了五分钟又学会了。
从半小时和五分钟的对比中可以发现多学一次就离真正掌握知识又近了一步。

人的本性就是容易遗忘,只有不断加深印象、重复学习才能真正掌握,所以很多书我都是推荐大家多看几遍。哪有那么多天才,他只是比你多看了几遍书。
能会去查看源码或者通过博客学习,花了半小时终于弄懂了,下次又看到@Aspect 了,你有点郁闷了,上次好像在哪哪哪学习,你快速打开网页花了五分钟又学会了。
从半小时和五分钟的对比中可以发现多学一次就离真正掌握知识又近了一步。
[外链图片转存中…(img-GxoNkK21-1714221559064)]
人的本性就是容易遗忘,只有不断加深印象、重复学习才能真正掌握,所以很多书我都是推荐大家多看几遍。哪有那么多天才,他只是比你多看了几遍书。















 2258
2258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









