






总结
其他的内容都可以按照路线图里面整理出来的知识点逐一去熟悉,学习,消化,不建议你去看书学习,最好是多看一些视频,把不懂地方反复看,学习了一节视频内容第二天一定要去复习,并总结成思维导图,形成树状知识网络结构,方便日后复习。
这里还有一份很不错的《Java基础核心总结笔记》,特意跟大家分享出来
目录:

部分内容截图:


数据类型 数组名[ ][ 列数 ] = { 数据1,数据2,数据3,数据4};
int arr[2][3];
int arr2[2][3] =
{
{1,2,3},
{4,5,6}
};
int arr3[2][3] = { 1,2,3,4,5,6 };
int arr4[][3] = { 1,2,3,4,5,6 };
-
以上4种定义方式,利用第二种更加直观,提高代码的可读性
-
如果对全部元素赋初值,定义数组时对第一维的长度可以不指定,但是第二维的长度不能省略
- 用来存放字符数据的数组是字符数组,字符数组中的一个元素存放一个字符
定义:
char c[10] = {′I′,′ ′,′a′,′m′,′ ′,′h′,′a′,′p′,′p′,′y′};
赋值:
只能对字符数组的元素赋值,而不能用赋值语句对整个数组赋值
char c[5];
c={′C′,′h′,′i′,′n′,′a′}; //错误,不能对整个数组一次赋值
C[0]=′C′; c[1]=′h′; c[2]=′i′; c[3]=′n′; c[4]=′a′; //对数组元素赋值,正确
int a[5],b[5]={1,2,3,4,5};
a=b; //错误,不能对整个数组整体赋值
a[0]=b[0]; //正确,引用数组元素
-
字符串连接函数
strcat -
字符串复制函数
strcpy -
字符串比较函数
strcmp -
字符串长度函数
strlen
======================================================================
作用:将一段经常使用的代码封装起来,减少重复代码
函数的定义一般主要有5个步骤:
1、返回值类型
2、函数名
3、参数表列
4、函数体语句
5、return 表达式
语法:
返回值类型 函数名 (参数列表)
{
函数体语句
return表达式
}
-
返回值类型 :一个函数可以返回一个值。在函数定义中
-
函数名:给函数起个名称
-
参数列表:使用该函数时,传入的数据
-
函数体语句:花括号内的代码,函数内需要执行的语句
-
return表达式: 和返回值类型挂钩,函数执行完后,返回相应的数据
示例:定义一个加法函数,实现两个数相加
//函数定义
int add(int num1, int num2)
{
int sum = num1 + num2;
return sum;
}
功能:使用定义好的函数
语法:函数名(参数)
int result = add(10,20);
-
函数定义里小括号内称为形参,函数调用时传入的参数称为实参
-
例如此处的
num1,num2为形参,10,20为实参 -
函数不能嵌套定义但是可以嵌套调用(常考)
- 函数的声明可以多次,但是函数的定义只能有一次
//声明可以多次,定义只能一次
//声明
int max(int a, int b);
int max(int a, int b);
//定义
int max(int a, int b)
{
return a > b ? a : b;
}
int main() {
int a = 100;
int b = 200;
cout << max(a, b) << endl;
system(“pause”);
return 0;
}
-
所谓值传递,即单向传递,就是函数调用时实参将数值传入给形参,而不能由形参传回来给实参。
-
值传递时,如果形参发生改变,并不会影响实参(值传递时,形参是修饰不了实参的),请务必理解并记住,此处因篇幅就不进行讲解了!
在C++中,函数的形参列表中的形参是可以有默认值的。
语法:返回值类型 函数名 (参数= 默认值){}
int func(int a, int b = 10, int c = 10) {
return a + b + c;
}
//1. 如果某个位置参数有默认值,那么从这个位置往后,从左向右,必须都要有默认值
//2. 如果函数声明有默认值,函数实现的时候就不能有默认参数
int func2(int a = 10, int b = 10);
int func2(int a, int b) {
return a + b;
}
int main() {
cout << "ret = " << func(20, 20) << endl;
cout << "ret = " << func(100) << endl;
system(“pause”);
return 0;
}
-
如果某个位置参数有默认值,那么从这个位置往后,从左向右,必须都要有默认值
-
如果函数声明有默认值,函数实现的时候就不能有默认参数
C++中函数的形参列表里可以有占位参数,用来做占位,调用函数时必须填补该位置
语法: 返回值类型 函数名 (数据类型){}
//函数占位参数 ,占位参数也可以有默认参数
void func(int a, int) {
cout << “this is func” << endl;
}
int main() {
func(10,10); //占位参数必须填补
system(“pause”);
return 0;
}
作用:函数名可以相同,提高复用性
函数重载满足条件:
-
函数名称相同
-
函数参数类型不同 或者 个数不同 或者 顺序不同
注意: 函数的返回值不可以作为函数重载的条件
//函数重载需要函数都在同一个作用域下
void func()
{
cout << “func 的调用!” << endl;
}
void func(int a)
{
cout << “func (int a) 的调用!” << endl;
}
void func(double a)
{
cout << “func (double a)的调用!” << endl;
}
void func(int a ,double b)
{
cout << “func (int a ,double b) 的调用!” << endl;
}
void func(double a ,int b)
{
cout << “func (double a ,int b)的调用!” << endl;
}
//函数返回值不可以作为函数重载条件
//int func(double a, int b)
//{
// cout << “func (double a ,int b)的调用!” << endl;
//}
int main() {
func();
func(10);
func(3.14);
func(10,3.14);
func(3.14 , 10);
system(“pause”);
return 0;
}
C++中有以下五个运算符不能重载
| 成员访问运算符 | 成员指针访问运算符 | 域运算符 | 长度运算符 | 条件运算符 |
| — | — | — | — | — |
| . | .* | :: | sizeof | ?: |
重载运算符规则:
-
重载不能改变运算符运算对象(即操作数)的个数
-
重载不能改变运算符的优先级别
-
重载不能改变运算符的结合性
-
运算符重载函数可以是类的成员函数,也可以是类的友元函数,还可以是既非类的成员函数也不是友元函数的普通函数
什么时候应该用成员函数方式,什么时候应该用友元函数方式?二者有何区别呢?()
-
一般将单目运算符重载为成员函数,将双目运算符(二元运算符)重载为友元函数
-
重载为类的成员函数 -
operator函数有一个参数 -
重载为类的友元函数 -
operator函数有两个参数 -
只能将重载
“>>”(流插入运算符)和“<<”(流提取运算符)的函数作为友元函数或者普通函数重载,而不能将它们定义为成员函数,因为参数为两个 -
类型转换运算符只能作为成员函数重载
单目运算符:只有一个操作数,如 !,-(负号),&,*,++,–
双目运算符:*,/,%,+,-,==,!=,<,>,<=,>=,&&,||
- 指定内置函数的方法很简单,只需在函数首行的左端加一个关键字inline即可。
inline int max(int a,int b);
-
使用内置函数可以节省运行时间
-
只有那些规模较小而又被频繁调用的简单函数,才适合于声明为inline函数。
语法:
template
函数声明或定义
解释:
template — 声明创建模板
typename — 表面其后面的符号是一种数据类型,可以用class代替
T — 通用的数据类型,名称可以替换,通常为大写字母
只适用于函数体相同、函数的参数个数相同而类型不同的情况,如果参数的个数不同,则不能用函数模板。
======================================================================
指针的作用: 可以通过指针间接访问内存
指针变量定义语法: 数据类型 * 变量名;
- 请看下方代码示例,理解指针变量的定义与使用,期末一般不会出太难指针的题,但是基本用法一定要会!!
int main() {
//1、指针的定义
int a = 10; //定义整型变量a
//指针定义语法: 数据类型 * 变量名 ;
int * p;
//指针变量赋值
p = &a; //指针指向变量a的地址
cout << &a << endl; //打印数据a的地址
cout << p << endl; //打印指针变量p
//0073F8BC
//0073F8BC
//2、指针的使用
//通过*操作指针变量指向的内存
cout << "*p = " << *p << endl;
// *p = 10
system(“pause”);
return 0;
}
指针变量和普通变量的区别
-
普通变量存放的是数据,指针变量存放的是地址
-
指针变量可以通过" * "操作符,操作指针变量指向的内存空间,这个过程称为解引用
总结1: 我们可以通过 & 符号 获取变量的地址
总结2:利用指针可以记录地址
总结3:对指针变量解引用,可以操作指针指向的内存
总结4:所有指针类型在32位操作系统下是4个字节(了解)
const修饰指针有三种情况
-
const修饰指针 — 常量指针
-
const修饰常量 — 指针常量
-
const既修饰指针,又修饰常量
int main() {
int a = 10;
int b = 10;
//const修饰的是指针,指针指向可以改,指针指向的值不可以更改
const int * p1 = &a;
p1 = &b; //正确
//*p1 = 100; 报错
//const修饰的是常量,指针指向不可以改,指针指向的值可以更改
int * const p2 = &a;
//p2 = &b; //错误
*p2 = 100; //正确
//const既修饰指针又修饰常量
const int * const p3 = &a;
//p3 = &b; //错误
//*p3 = 100; //错误
system(“pause”);
return 0;
}
技巧:看const右侧紧跟着的是指针还是常量, 是指针就是常量指针,是常量就是指针常量
作用:利用指针访问数组中元素
-
C++规定,数组名就是数组的起始地址
-
数组的指针就是数组的起始地址
-
数组名可以作函数的实参和形参,传递的是数组的地址
int main() {
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int * p = arr; //指向数组的指针
cout << "第一个元素: " << arr[0] << endl; //1
cout << "指针访问第一个元素: " << *p << endl; //1
for (int i = 0; i < 10; i++)
{
//利用指针遍历数组
cout << *p << endl;
p++;
}
system(“pause”);
return 0;
}
作用:利用指针作函数参数,可以修改实参的值(地址传递)
//值传递
void swap1(int a ,int b)
{
int temp = a;
a = b;
b = temp;
}
//地址传递
void swap2(int * p1, int *p2)
{
int temp = *p1;
*p1 = *p2;
*p2 = temp;
}
int main() {
int a = 10;
int b = 20;
swap1(a, b); // 值传递不会改变实参
swap2(&a, &b); //地址传递会改变实参
cout << "a = " << a << endl;
cout << "b = " << b << endl;
system(“pause”);
return 0;
}
int a[10];
int *p = &a[0]; // 等价于 int *p = a;
*p = 1; // 等价于 a[0] = 1;
*(p+1) = 2; // 等价于 a[1] = 2;
// 所以 *(p+1) = a[1]; *(p+2) = a[2];
- C++规定, p+1 指向数组的 下一个元素
void main()
{
int array[10];
// 用数组名作形参,因为接收的是地址,所以可以不指定具体的元素个数
f(array,10);
}
// 形参数组
f(int arr[],int n)
{
…
}
void main()
{
int a[10];
// 实参数组
f(a,10);
}
// 形参指针
f(int *x,int n)
{
…
}
总结:如果不想修改实参,就用值传递,如果想修改实参,就用地址传递
-
返回指针值的函数简称指针函数。
-
定义指针函数的一般形式为:
// 类型名 * 函数名(参数列表)
int * a(int x,int y);
======================================================================
作用: 给变量起别名
语法: 数据类型 &别名 = 原名
int main() {
int a = 10;
int &b = a;
cout << "a = " << a << endl;
cout << "b = " << b << endl;
// 10
// 10
b = 100;
cout << "a = " << a << endl;
cout << "b = " << b << endl;
// 100
// 100
system(“pause”);
return 0;
}
- 引用必须初始化
int &c; // 错误,引用必须初始化
- 在声明一个引用后,不能再使之作为另一变量的引用
作用:函数传参时,可以利用引用的技术让形参修饰实参
优点:可以简化指针修改实参
- 通过引用参数产生的效果同按地址传递是一样的。引用的语法更清楚简单
//1. 值传递
void mySwap01(int a, int b) {
int temp = a;
a = b;
b = temp;
}
//2. 地址传递
void mySwap02(int* a, int* b) {
int temp = *a;
*a = *b;
*b = temp;
}
//参数:把地址传进去,用指针接收
//3. 引用传递
void mySwap03(int& a, int& b) {
int temp = a;
a = b;
b = temp;
}
//参数:别名,下面的a是上面的a的别名,用别名操作修改可原名操作修改是一样的
int main() {
int a = 10;
int b = 20;
// 值传递,形参不会修饰实参
mySwap01(a, b);
cout << “a:” << a << " b:" << b << endl;
// a:10 b:20
// 地址传递,形参会修饰实参
mySwap02(&a, &b);
cout << “a:” << a << " b:" << b << endl;
// a:20 b:10
// 引用传递,形参会修饰实参
mySwap03(a, b);
cout << “a:” << a << " b:" << b << endl;
// a:20 b:10
system(“pause”);
return 0;
}
作用:引用是可以作为函数的返回值存在的
//数据类型后加&,相当于用引用的方式返回
int& test02() {
// 必须使用静态变量,需加 static 关键字
static int a = 20;
return a;
}
int main(){
int& ref2 = test02();
system(“pause”);
return 0;
}
========================================================================
在C++中 struct和class唯一的区别就在于 默认的访问权限不同
区别:
-
struct 默认权限为公共
-
class 默认权限为私有
-
构造函数:主要作用在于创建对象时为对象的成员属性赋值,构造函数由编译器自动调用,无须手动调用。
-
析构函数:主要作用在于对象销毁前系统自动调用,执行一些清理工作。
构造函数语法:类名(){}(构造和析构很容易出选择题,特点要记住)
-
构造函数,没有返回值也不写void
-
构造函数的名字必须与类名相同
-
构造函数可以有参数,因此可以发生重载
-
程序在调用对象时候会自动调用构造函数,无须手动调用,而且只会调用一次(构造函数不需用户调用,也不能被用户调用)
析构函数语法: ~类名(){}
-
析构函数,没有返回值也不写void
-
函数名称与类名相同,在名称前加上符号
~ -
析构函数不可以有参数,因此不可以发生重载
-
程序在对象销毁前会自动调用析构,无须手动调用,而且只会调用一次
class Person
{
public:
//构造函数
Person()
{
cout << “Person的构造函数调用” << endl;
}
//析构函数
~Person()
{
cout << “Person的析构函数调用” << endl;
}
};
void test01()
{
Person p; //在栈上的数据,test01()执行完毕后,释放这个对象
}
int main() {
test01();
system(“pause”);
return 0;
}
构造函数按参数分为: 有参构造和无参构造
调用方式:括号法
class Person {
public:
//无参(默认)构造函数
Person() {
cout << “无参构造函数!” << endl;
}
//有参构造函数
Person(int a) {
age = a;
cout << “有参构造函数!” << endl;
}
//析构函数
~Person() {
cout << “析构函数!” << endl;
}
public:
int age;
};
//2、构造函数的调用
//调用无参构造函数
void test01() {
Person p; //调用无参构造函数
}
//调用有参的构造函数
void test02() {
// 括号法,常用
Person p1(10);
}
- 尽管在一个类中可以包含多个构造函数,但是对于每一个对象来说,建立对象时只执行其中一个构造函数,并非每个构造函数都被执行
- C++提供了初始化列表语法,用来初始化属性
语法:构造函数():属性1(值1),属性2(值2)... {}
class Person {
public:
传统方式初始化
//Person(int a, int b, int c) {
// m_A = a;
// m_B = b;
// m_C = c;
//}
//初始化列表方式初始化
Person(int a, int b, int c) :m_A(a), m_B(b), m_C© {}
void PrintPerson() {
cout << “mA:” << m_A << endl;
cout << “mB:” << m_B << endl;
cout << “mC:” << m_C << endl;
}
private:
int m_A;
int m_B;
int m_C;
};
int main() {
Person p(1, 2, 3);
p.PrintPerson();
system(“pause”);
return 0;
}
C++类中的成员可以是另一个类的对象,我们称该成员为 对象成员
例如:
class A {}
class B
{
A a;
}
-
B类中有对象A作为成员,A为对象成员
-
那么当创建B对象时,A与B的构造和析构的顺序是谁先谁后?
-
先调用对象成员的构造,再调用本类构造(如上例中,先调用A的构造函数)
-
析构顺序与构造相反
静态成员就是在成员变量和成员函数前加上关键字static,称为静态成员
静态成员分为:
-
静态成员变量
-
所有对象共享同一份数据
-
在编译阶段分配内存
-
类内声明,类外初始化
-
静态成员函数
-
所有对象共享同一个函数
-
静态成员函数只能访问静态成员变量
**示例1 **:静态成员变量
class Person
{
public:
static int m_A; //静态成员变量
//静态成员变量特点:
//1 在编译阶段分配内存
//2 类内声明,类外初始化
//3 所有对象共享同一份数据
private:
static int m_B; //静态成员变量也是有访问权限的
};
int Person::m_A = 10;
int Person::m_B = 10;
void test01()
{
//静态成员变量两种访问方式
//1、通过对象
Person p1;
p1.m_A = 100;
cout << "p1.m_A = " << p1.m_A << endl;
Person p2;
p2.m_A = 200;
cout << "p1.m_A = " << p1.m_A << endl; //共享同一份数据
cout << "p2.m_A = " << p2.m_A << endl;
//2、通过类名
cout << "m_A = " << Person::m_A << endl;
//cout << "m_B = " << Person::m_B << endl; //私有权限访问不到
}
int main() {
test01();
system(“pause”);
return 0;
}
示例2:静态成员函数
class Person
{
public:
//静态成员函数特点:
//1 程序共享一个函数
//2 静态成员函数只能访问静态成员变量
static void func()
{
cout << “func调用” << endl;
m_A = 100;
//m_B = 100; //错误,不可以访问非静态成员变量
}
static int m_A; //静态成员变量
int m_B; //
private:
//静态成员函数也是有访问权限的
static void func2()
{
cout << “func2调用” << endl;
}
};
int Person::m_A = 10;
void test01()
{
//静态成员变量两种访问方式
//1、通过对象
Person p1;
p1.func();
//2、通过类名
Person::func();
//Person::func2(); //私有权限访问不到
}
int main() {
test01();
system(“pause”);
return 0;
}
常函数:
-
成员函数后加const后我们称为这个函数为常函数
-
常函数内不可以修改成员属性
常对象:
-
声明对象前加const称该对象为常对象
-
常对象只能调用常函数
| 形式 | 含义 |
| — | — |
| Time const t1 | t1 是常对象,其值在任何情况下都不能改变 |
| void Time::fun() const | fun 是 Time类中的常成员函数,可以引用,但不能修改本类中的数据成员 |
| Time * const p | p 是指向Time对象的常指针,P的值不能改变 |
| const Time *p | p是指向 Time 类常对象的指针,其指向的类对象的值不能通过指针来改变 |
| Time &t1 = t; | t1是Time类对象t的引用,二者指向同一段内存空间 |
======================================================================
继承的好处:可以减少重复的代码
继承的语法:class 子类 : 继承方式 父类
class A : public B;
A 类称为子类 或 派生类
B 类称为父类 或 基类
继承方式一共有三种:
-
公共继承
-
保护继承
-
私有继承
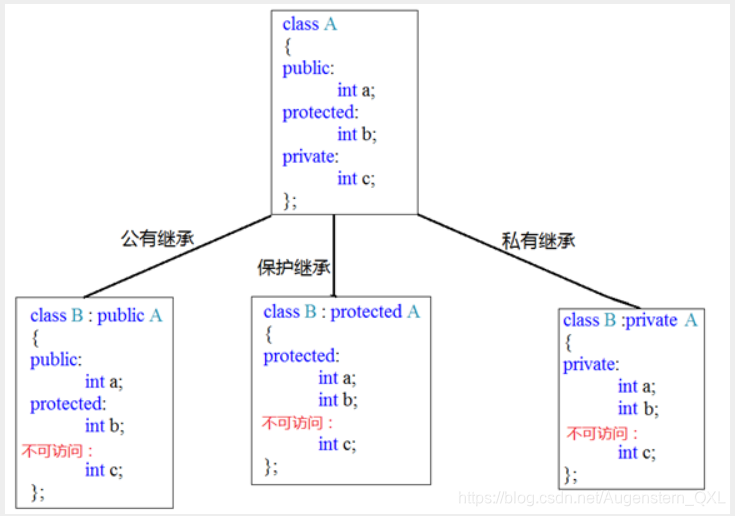
简单的说:
-
公共继承:基类的公用成员和保护成员在派生类中保持原有访问属性,其私有成员仍为基类私有。
-
私有继承:基类的公用成员和保护成员在派生类中成了私有成员。其私有成员仍为基类私有
-
保护继承:基类的公用成员和保护成员在派生类中成了保护成员,其私有成员仍为基类私有。
-
构造函数的主要作用是对数据成员初始化
-
派生类是不能继承基类的析构函数,也需要通过派生类的析构函数去调用基类的析构函数
-
继承中 先调用父类构造函数,再调用子类构造函数,析构顺序与构造相反
- C++中,不能被派生类继承的是:
构造函数
单继承:一个派生类只从一个基类派生
多继承:一个派生类有两个或多个基类的称为多重继承
=======================================================================
多态性是指具有不同功能的函数可以用同一个函数名,这样就可以用一个函数名调用不同内容的函数
多态分为两类
-
静态多态: 函数重载 和 运算符重载属于静态多态,复用函数名
-
动态多态: 派生类和虚函数(virtual function)实现运行时多态
什么是虚函数?
- 在基类用
virtual声明成员函数为虚函数
虚函数的作用:
- 虚函数的作用是允许在派生类中重新定义与基类同名的函数,并且可以通过基类指针或引用来访问基类和派生类中的同名函数
虚函数的使用方法:
-
在基类用
virtual声明成员函数为虚函数。这样就可以在派生类中重新定义此函数,为它赋予新的功能,并能方便地被调用 -
在类外定义虚函数时,不必再加
virtual -
在派生类中重新定义此函数,要求函数名、函数类型、函数参数个数和类型全部与基类的虚函数相同,并根据派生类的需要重新定义函数体
C++规定,当一个成员函数被声明为虚函数后,其派生类中的同名函数都自动成为虚函数。因此在派生类重新声明该虚函数时,可以加virtual,也可以不加,但习惯上一般在每一层声明该函数时都加virtual,使程序更加清晰
class Animal
{
public:
//Speak函数就是虚函数
//函数前面加上virtual关键字,变成虚函数,那么编译器在编译的时候就不能确定函数调用了。
virtual void speak()
{
cout << “动物在说话” << endl;
}
};
class Cat :public Animal
{
public:
void speak()
{
cout << “小猫在说话” << endl;
}
};
class Dog :public Animal
{
public:
void speak()
{
cout << “小狗在说话” << endl;
}
};
//我们希望传入什么对象,那么就调用什么对象的函数
//如果函数地址在编译阶段就能确定,那么静态联编
//如果函数地址在运行阶段才能确定,就是动态联编
void DoSpeak(Animal & animal)
{
animal.speak();
}
//
//多态满足条件:
//1、有继承关系
//2、子类重写父类中的虚函数
//多态使用:
//父类指针或引用指向子类对象
void test01()
{
Cat cat;
DoSpeak(cat);
Dog dog;
DoSpeak(dog);
}
int main() {
test01();
system(“pause”);
return 0;
}
多态满足条件
-
有继承关系
-
子类重写父类中的虚函数
- 纯虚函数
- 纯虚函数是在声明虚函数时被“初始化”为0的函数。声明纯虚函数的一般形式是
virtual 函数类型 函数名 (参数表列) =0;
-
纯虚函数没有函数体
-
最后面的
=0,并不表示函数返回值为0,它只告诉编译系统“老子是纯虚函数” -
纯虚函数只有函数的名字而不具备函数的功能,不能被调用
- 抽象类
-
凡是包含纯虚函数的类都是抽象类
-
一个基类如果包含一个或一个以上纯虚函数,就是抽象基类。抽象基类不能也不必要定义对象、
=========================================================================
C++中对文件操作需要包含头文件 < fstream >
文件类型分为两种:
-
文本文件 - 文件以文本的ASCII码形式存储在计算机中
-
二进制文件 - 文件以文本的二进制形式存储在计算机中,用户一般不能直接读懂它们
操作文件的三大类:
-
ofstream:写操作
-
ifstream: 读操作
-
fstream : 读写操作
5.1.1写文件
写文件步骤如下:
- 包含头文件
#include
- 创建流对象
ofstream ofs;
- 打开文件
ofs.open(“文件路径”,打开方式);
- 写数据
ofs << “写入的数据”;
- 关闭文件
ofs.close();
文件打开方式:
| 打开方式 | 解释 |
| — | — |
| ios::in | 为读文件而打开文件 |
| ios::out | 为写文件而打开文件 |
| ios::ate | 初始位置:文件尾 |
| ios::app | 追加方式写文件 |
| ios::trunc | 如果文件存在先删除,再创建 |
| ios::binary | 二进制方式 |
注意: 文件打开方式可以配合使用,利用|操作符
**例如:**用二进制方式写文件 ios::binary | ios:: out
示例:
#include
void test01()
{
ofstream ofs;
ofs.open(“test.txt”, ios::out);
ofs << “姓名:张三” << endl;
ofs << “性别:男” << endl;
ofs << “年龄:18” << endl;
ofs.close();
}
int main() {
test01();
system(“pause”);
return 0;
}
总结:
-
文件操作必须包含头文件 fstream
-
读文件可以利用 ofstream ,或者fstream类
-
打开文件时候需要指定操作文件的路径,以及打开方式
-
利用<<可以向文件中写数据
-
操作完毕,要关闭文件
5.1.2读文件
读文件与写文件步骤相似,但是读取方式相对于比较多
读文件步骤如下:
- 包含头文件
#include
- 创建流对象
ifstream ifs;
- 打开文件并判断文件是否打开成功
ifs.open(“文件路径”,打开方式);
- 读数据
四种方式读取
- 关闭文件
ifs.close();
示例:
#include
#include
void test01()
{
ifstream ifs;
ifs.open(“test.txt”, ios::in);
if (!ifs.is_open())
{
cout << “文件打开失败” << endl;
return;
}
//第一种方式
//char buf[1024] = { 0 };
//while (ifs >> buf)
//{
// cout << buf << endl;
//}
//第二种
//char buf[1024] = { 0 };
//while (ifs.getline(buf,sizeof(buf)))
//{
// cout << buf << endl;
//}
//第三种
//string buf;
//while (getline(ifs, buf))
//{
// cout << buf << endl;
//}
char c;
while ((c = ifs.get()) != EOF)
{
cout << c;
}
ifs.close();
}
int main() {
test01();
system(“pause”);
return 0;
}
总结:
-
读文件可以利用 ifstream ,或者fstream类
-
利用is_open函数可以判断文件是否打开成功
-
close 关闭文件
5.2 二进制文件
以二进制的方式对文件进行读写操作
打开方式要指定为 ios::binary
5.2.1 写文件
二进制方式写文件主要利用流对象调用成员函数write
函数原型 :ostream& write(const char * buffer,int len);
参数解释:字符指针buffer指向内存中一段存储空间。len是读写的字节数
示例:
#include
最后总结
ActiveMQ+Kafka+RabbitMQ学习笔记PDF




关于分布式,限流+缓存+缓存,这三大技术(包含:ZooKeeper+Nginx+MongoDB+memcached+Redis+ActiveMQ+Kafka+RabbitMQ)等等。这些相关的面试也好,还有手写以及学习的笔记PDF,都是啃透分布式技术必不可少的宝藏。以上的每一个专题每一个小分类都有相关的介绍,并且小编也已经将其整理成PDF啦
文件打开方式:
| 打开方式 | 解释 |
| — | — |
| ios::in | 为读文件而打开文件 |
| ios::out | 为写文件而打开文件 |
| ios::ate | 初始位置:文件尾 |
| ios::app | 追加方式写文件 |
| ios::trunc | 如果文件存在先删除,再创建 |
| ios::binary | 二进制方式 |
注意: 文件打开方式可以配合使用,利用|操作符
**例如:**用二进制方式写文件 ios::binary | ios:: out
示例:
#include
void test01()
{
ofstream ofs;
ofs.open(“test.txt”, ios::out);
ofs << “姓名:张三” << endl;
ofs << “性别:男” << endl;
ofs << “年龄:18” << endl;
ofs.close();
}
int main() {
test01();
system(“pause”);
return 0;
}
总结:
-
文件操作必须包含头文件 fstream
-
读文件可以利用 ofstream ,或者fstream类
-
打开文件时候需要指定操作文件的路径,以及打开方式
-
利用<<可以向文件中写数据
-
操作完毕,要关闭文件
5.1.2读文件
读文件与写文件步骤相似,但是读取方式相对于比较多
读文件步骤如下:
- 包含头文件
#include
- 创建流对象
ifstream ifs;
- 打开文件并判断文件是否打开成功
ifs.open(“文件路径”,打开方式);
- 读数据
四种方式读取
- 关闭文件
ifs.close();
示例:
#include
#include
void test01()
{
ifstream ifs;
ifs.open(“test.txt”, ios::in);
if (!ifs.is_open())
{
cout << “文件打开失败” << endl;
return;
}
//第一种方式
//char buf[1024] = { 0 };
//while (ifs >> buf)
//{
// cout << buf << endl;
//}
//第二种
//char buf[1024] = { 0 };
//while (ifs.getline(buf,sizeof(buf)))
//{
// cout << buf << endl;
//}
//第三种
//string buf;
//while (getline(ifs, buf))
//{
// cout << buf << endl;
//}
char c;
while ((c = ifs.get()) != EOF)
{
cout << c;
}
ifs.close();
}
int main() {
test01();
system(“pause”);
return 0;
}
总结:
-
读文件可以利用 ifstream ,或者fstream类
-
利用is_open函数可以判断文件是否打开成功
-
close 关闭文件
5.2 二进制文件
以二进制的方式对文件进行读写操作
打开方式要指定为 ios::binary
5.2.1 写文件
二进制方式写文件主要利用流对象调用成员函数write
函数原型 :ostream& write(const char * buffer,int len);
参数解释:字符指针buffer指向内存中一段存储空间。len是读写的字节数
示例:
#include
最后总结
ActiveMQ+Kafka+RabbitMQ学习笔记PDF
[外链图片转存中…(img-jlaQFnaa-1715817036875)]
[外链图片转存中…(img-75ubUUVT-1715817036875)]
[外链图片转存中…(img-nD31zdIs-1715817036876)]
[外链图片转存中…(img-GEvcsaOy-1715817036876)]
关于分布式,限流+缓存+缓存,这三大技术(包含:ZooKeeper+Nginx+MongoDB+memcached+Redis+ActiveMQ+Kafka+RabbitMQ)等等。这些相关的面试也好,还有手写以及学习的笔记PDF,都是啃透分布式技术必不可少的宝藏。以上的每一个专题每一个小分类都有相关的介绍,并且小编也已经将其整理成PDF啦















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









