







总结
大厂面试问深度,小厂面试问广度,如果有同学想进大厂深造一定要有一个方向精通的惊艳到面试官,还要平时遇到问题后思考一下问题的本质,找方法解决是一个方面,看到问题本质是另一个方面。还有大家一定要有目标,我在很久之前就想着以后一定要去大厂,然后默默努力,每天看一些大佬们的文章,总是觉得只有再学深入一点才有机会,所以才有恒心一直学下去。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
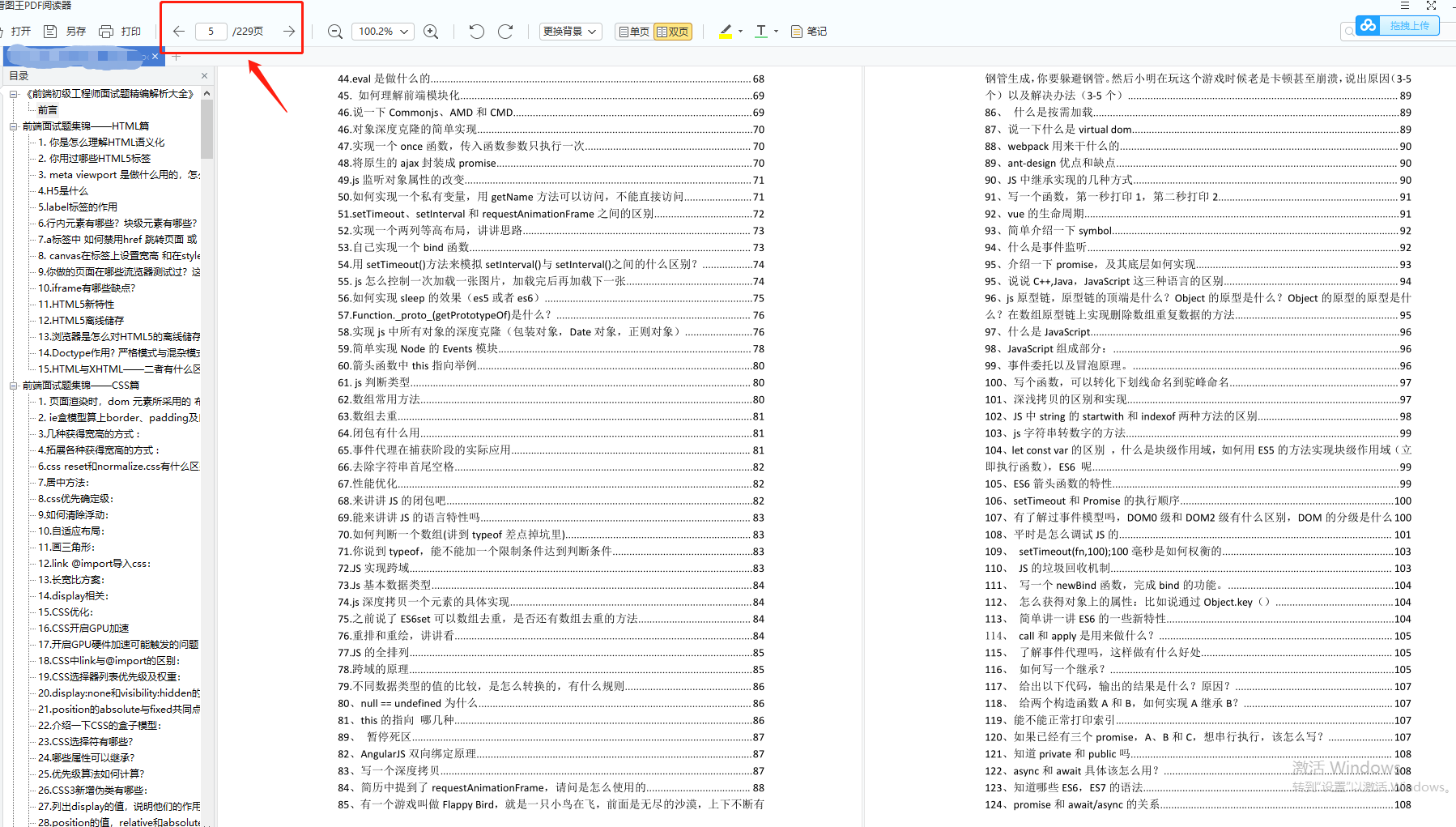
vue 项目打包部署上线之后,每一次都会有浏览器缓存问题,导致系统用户访问上个迭代批次的旧资源(css/js资源),若当前迭代批次项目包中不存在旧资源,系统就是出现404错误信息,需要系统用户手动清除缓存才能解决以上问题,导致用户体验非常不好。
注⚠️:以下说的浏览器缓存是指http缓存。
http缓存是基于HTTP协议的浏览器文件级缓存机制。即针对文件的重复请求情况下,浏览器可以根据协议头判断从服务器端请求文件还是从本地读取文件。
1.1 什么是浏览器缓存
浏览器缓存(Browser Caching)机制是为了节约网络资源提升页面渲染性能,浏览器在用户磁盘上会对最近请求过的文档进行存储,当访问者再次请求这个页面时,浏览器就可以从本地磁盘显示文档,进而提升页面性能。
1.2 浏览器缓存的优势与劣势
优势:
- 节约网络资源,提高网络效率;
- 减少页面资源请求数,降低服务器压力,减少服务器负担;
缺点:
- 缓存没有清理机制;
- 占用硬盘空间;
- 页面缓存,导致页面样式、图片或脚本等未能及时更新展示;
1.3 浏览器缓存类型
浏览器第一次必须获取到资源后,然后根据返回的信息来告诉如何缓存资源,可能采用的是强缓存,也可能告诉客户端浏览器是协商缓存,这都需要根据响应的header内容来决定的
浏览器缓存主要有两类:缓存协商和彻底缓存,也有称之为协商缓存和强缓存。
- 强缓存:不会向服务器发送请求,直接从缓存中读取资源,在chrome控制台的network选项中可以看到该请求返回
200的状态码; - 协商缓存:向服务器发送请求,服务器会根据这个请求的
request header的一些参数来判断是否命中协商缓存,如果命中,则返回304状态码并带上新的response header通知浏览器从缓存中读取资源;
两者的共同点是,都是从客户端缓存中读取资源;区别是强缓存不会发请求,协商缓存会发请求。
强缓存与协商缓存的区别,可以用下表来进行描述:

1.3.1 强制缓存
强缓存为直接从缓存中获取资源而不经过服务器;与强缓存相关的header字段有两个:
Expires:response header里的过期时间,浏览器再次加载资源时,如果在这个过期时间内,则命中强缓存。这是http1.0时的规范;它的值为一个绝对时间的GMT格式的时间字符串,如Mon, 10 Jun 2015 21:31:12 GMT,如果发送请求的时间在expires之前,那么本地缓存始终有效,否则就会发送请求到服务器来获取资源。cache-control:max-age=number,这是http1.1时出现的header信息,主要是利用该字段的max-age值来进行判断,它是一个相对值;资源第一次的请求时间和Cache-Control设定的有效期,计算出一个资源过期时间,再拿这个过期时间跟当前的请求时间比较,如果请求时间在过期时间之前,就能命中缓存,否则就不行;例如当值设为max-age=300时,则代表在这个请求正确返回时间(浏览器也会记录下来)的5分钟内再次加载资源,就会命中强缓存。cache-control除了该字段外,还有下面几个比较常用的设置值:no-cache:不使用本地缓存。需要使用缓存协商,先与服务器确认返回的响应是否被更改,如果之前的响应中存在ETag,那么请求的时候会与服务端验证,如果资源未被更改,则可以避免重新下载。no-store:直接禁止浏览器缓存数据,每次用户请求该资源,都会向服务器发送一个请求,每次都会下载完整的资源。
注意⚠️:如果cache-control与expires同时存在的话,cache-control的优先级高于expires。
public:可以被所有的用户缓存,包括终端用户和CDN等中间代理服务器。private:只能被终端用户的浏览器缓存,不允许CDN等中继缓存服务器对其缓存。
1.3.2 协商缓存
协商缓存是由服务器来确定缓存资源是否可用,所以客户端与服务器端要通过某种标识来进行通信,从而让服务器判断请求资源是否可以访问缓存,这主要涉及到下面两组header字段,这两组header都是成对搭档出现的,即第一次请求的响应头带上某个字段(Last-Modify或者Etag),则后续请求则会带上对应的请求字段(If-Modified-Since或者If-None-Match),若响应头没有Last-Modify或者Etag字段,则请求头也不会有对应的字段。
Last-Modified/If-Modify-Since:二者的值都是GMT格式的时间字符串,具体交互过程如下:
- 浏览器第一次请求一个资源的时候,服务器在返回这个资源的同时,在
response的header中会加上Last-Modified,Last-Modified是一个时间标识,用于标识该资源的最后修改时间;- 当浏览器再次请求该资源时,
request的请求头中会包含If-Modified-Since,该值为缓存之前返回的Last-Modified。- 服务器收到
If-Modified-Since后,根据浏览器传过来If-Modified-Since和资源在服务器上的最后修改时间判断资源是否有变化,如果没有变化则返回304 Not Modified,但是不会返回资源内容;如果有变化,就正常返回资源内容。当服务器返回304 Not Modified的响应时,respons header中不会再添加Last-Modified的header,因为既然资源没有变化,那么Last-Modified也就不会改变,这是服务器返回304时的response header。- 浏览器收到304的响应后,就会从缓存中加载资源。
- 如果协商缓存没有命中,浏览器直接从服务器加载资源时,
Last-Modified的Header在重新加载的时候会被更新,下次请求时,If-Modified-Since会启用上次返回的Last-Modified值。
Etag/If-None-Match:这两个值是由服务器生成的每个资源的唯一标识字符串(生成规则由服务器决定),只要资源有变化就这个值就会改变;其判断过程与Last-Modified/If-Modified-Since类似,当资源过期时(使用Cache-Control标识的max-age),发现资源具有Etage声明,则再次向web服务器请求时带上头If-None-Match(Etag的值)。web服务器收到请求后发现有头与Last-Modified不一样的是,当服务器返回304 Not Modified的响应时,由于ETag重新生成过,response header中还会把这个ETag返回,即使这个ETag跟之前的没有变化。
ETag和Last-Modified的作用和用法,区别如下:
Etag要优于Last-Modified。Last-Modified的时间单位是秒,如果某个文件在1秒内改变了多次,那么他们的Last-Modified其实并没有体现出来修改,但是Etag每次都会改变确保了精度;- 在性能上,
Etag要逊于Last-Modified,毕竟Last-Modified只需要记录时间,而Etag需要服务器通过算法来计算出一个hash值; - 在优先级上,服务器校验优先考虑
Etag。
注⚠️:关于 Cache-Control: max-age=秒 和 Expires Expires = 时间,设置以分钟为单位的绝对过期时间,HTTP 1.0 版本,缓存的载止时间,允许客户端在这个时间之前不去检查(发请求); max-age = 秒,HTTP 1.1版本,资源在本地缓存多少秒。 如果max-age和Expires同时存在,则被Cache-Control:max-age覆盖。Expires 的一个缺点: 就是返回的到期时间是服务器端的时间,这样存在一个问题,如果客户端的时间与服务器的时间相差很大,那么误差就很大,所以在HTTP 1.1版开始,使用Cache-Control: max-age=秒替代。Expires =max-age + “每次下载时的当前的request时间”,所以一旦重新下载的页面后,expires就重新计算一次,但last-modified不会变化。
1.3.3 既生 Last-Modified 何生 Etag ?
有童鞋可能会觉得使用Last-Modified已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要Etag呢?HTTP1.1中Etag的出现主要是为了解决几个Last-Modified比较难解决的问题:
- 一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新GET;
- 某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),
If-Modified-Since能检查到的粒度是s级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒); - 某些服务器不能精确的得到文件的最后修改时间。
这时,利用Etag能够更加准确的控制缓存,因为Etag是服务器自动生成或者由开发者生成的对应资源在服务器端的唯一标识符。
注⚠️:Last-Modified与ETag是可以一起使用的,服务器会优先验证ETag,一致的情况下,才会继续比对Last-Modified,最后才决定是否返回304。
1.4 浏览器缓存过程
- 浏览器第一次加载资源,服务器返回200,浏览器将资源文件从服务器上请求下载下来,并把response header及该请求的返回时间一并缓存;
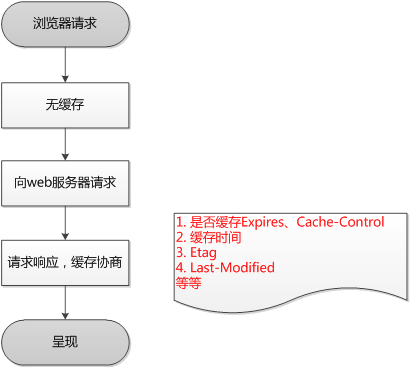
- 下一次加载资源时,先比较当前时间和上一次返回200时的时间差,如果没有超过
cache-control设置的max-age,则没有过期,命中强缓存,不发请求直接从本地缓存读取该文件(如果浏览器不支持HTTP1.1,则用expires判断是否过期);如果时间过期,没有命中强缓存,浏览器会发送请求到服务器,请求会携带第一次请求返回的有关缓存的header字段信息(Last-Modified/If-Modified-Since和Etag/If-None-Match); - 服务器收到请求后,优先根据
Etag的值判断被请求的文件有没有做修改,Etag值一致则没有修改,命中协商缓存,返回304;如果不一致则有改动,直接返回新的资源文件带上新的Etag值并返回200;; - 如果服务器收到的请求没有
Etag值,则将If-Modified-Since和被请求文件的最后修改时间做比对,一致则命中协商缓存,服务器返回304,并将新的响应header信息更新缓存中的对应header信息,但是并不返回资源内容,它会告知浏览器可以直接从缓存获取;否则返回新的last-modified和文件并返回200;
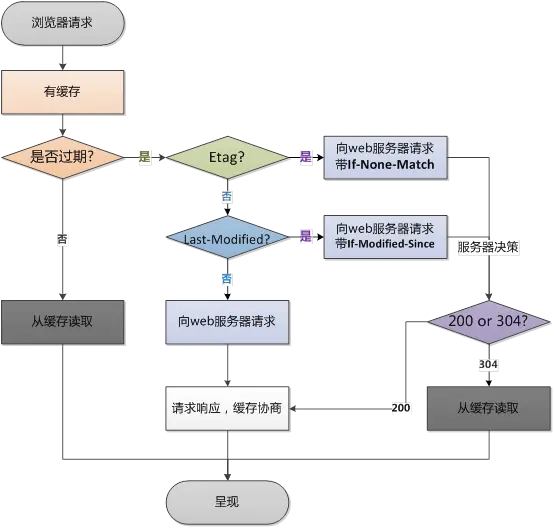
1.5 用户行为对浏览器缓存的影响
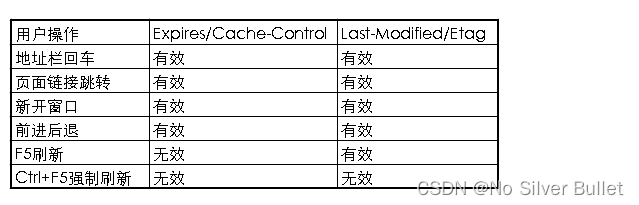
1.5.1 点击刷新按钮或者按F5
浏览器应用协商缓存,会带上If-Modifed-Since,If-None-Match,这就意味着服务器会对文件检查有效性,返回结果可能是304,也有可能是200。
1.5.2 用户按Ctrl+F5(强制刷新)
浏览器应用强缓存,而且不会带上 If-Modifed-Since,If-None-Match,相当于之前从来没有请求过,返回结果是200.
1.5.3 地址栏回车
浏览器发起请求,按照正常流程,本地检查是否过期,然后服务器端检查有效性,最后返回内容。
1.5.4 强缓存如何重新加载缓存缓存过的资源?
前面说到,使用强缓存时,浏览器不会发送请求到服务端,根据设置的缓存时间浏览器一直从缓存中获取资源,在这期间若资源产生了变化,浏览器就在缓存期内就一直得不到最新的资源,那么如何防止这种事情发生呢?
通过更新页面中引用的资源路径,让浏览器主动放弃缓存,加载新资源。
类似下图所示:

这样每次文件改变后就会生成新的query值,这样query值不同,也就是页面引用的资源路径不同了,之前缓存过的资源就被浏览器忽略了,因为资源请求的路径变了。
二、问题分析
页面在浏览器中进行渲染时,基于浏览器缓存机制,当用户访问之前访问过的系统页面时,浏览器会加载之前已经缓存的页面资源。
vue项目使用webpack进行编译,生产环境核心配置文件webpack.prod.conf.js配置的js资源文件生成策略如下:
output: {
// 打包后的文件放在dist目录里面
path: config.build.assetsRoot,
// 文件名称使用 static/js/[name].[chunkhash].js, 其中name就是main,chunkhash就是模块的hash值,用于浏览器缓存.
filename: utils.assetsPath('js/[name].[chunkhash].js'),
// chunkFilename是非入口模块文件,也就是说filename文件中引用了chunckFilename
chunkFilename: utils.assetsPath('js/[id].[chunkhash].js')
},
....
// extract css into its own file
new ExtractTextPlugin({
// 生成独立的css文件,下面是生成独立css文件的名称
filename: utils.assetsPath('css/[name].[contenthash].css')
}),
其中,chunkhash与contenthash的区别详参博文《Vue进阶(七十):了解 webpack 的 hash、chunkhash、contenthash》。
no-cache浏览器会缓存,但刷新页面或者重新打开时会请求服务器,服务器可以响应304,如果文件有改动就会响应200。no-store浏览器不缓存,刷新页面需要重新下载页面。
三、解决方案
在 HTTP 响应头中添加缓存控制的指令来控制浏览器缓存。修改index.html的内容,可以使用以下缓存请求指令,让所有的css/js资源重新加载:

<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, user-scalable=no">
<meta http-equiv="pragram" content="no-cache">
<meta http-equiv="cache-control" content="no-cache, no-store, must-revalidate">
<meta http-equiv="expires" content="0">
<link rel="icon" href="<%= BASE\_URL %>favicon.ico">
</head>
跳槽是每个人的职业生涯中都要经历的过程,不论你是搜索到的这篇文章还是无意中浏览到的这篇文章,希望你没有白白浪费停留在这里的时间,能给你接下来或者以后的笔试面试带来一些帮助。
也许是互联网未来10年中最好的一年。WINTER IS COMING。但是如果你不真正的自己去尝试尝试,你永远不知道市面上的行情如何。这次找工作下来,我自身感觉市场并没有那么可怕,也拿到了几个大厂的offer。在此进行一个总结,给自己,也希望能帮助到需要的同学。
面试准备
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
面试准备根据每个人掌握的知识不同,准备的时间也不一样。现在对于前端岗位,以前也许不是很重视算法这块,但是现在很多公司也都会考。建议大家平时有空的时候多刷刷leetcode。算法的准备时间比较长,是一个长期的过程。需要在掌握了大部分前端基础知识的情况下,再有针对性的去复习算法。面试的时候算法能做出来肯定加分,但做不出来也不会一票否决,面试官也会给你提供一些思路。















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









