







 本文详细探讨了HTTP缓存中的Etag、Last-Modified的区别,以及它们在浏览器缓存中的角色。重点介绍了Vue项目中Webpack配置对资源文件缓存的影响,以及如何通过Cache-Control指令来管理缓存,以解决刷新页面资源更新的问题。
本文详细探讨了HTTP缓存中的Etag、Last-Modified的区别,以及它们在浏览器缓存中的角色。重点介绍了Vue项目中Webpack配置对资源文件缓存的影响,以及如何通过Cache-Control指令来管理缓存,以解决刷新页面资源更新的问题。
- 在性能上,
Etag要逊于Last-Modified,毕竟Last-Modified只需要记录时间,而Etag需要服务器通过算法来计算出一个hash值; - 在优先级上,服务器校验优先考虑
Etag。
注⚠️:关于 Cache-Control: max-age=秒 和 Expires Expires = 时间,设置以分钟为单位的绝对过期时间,HTTP 1.0 版本,缓存的载止时间,允许客户端在这个时间之前不去检查(发请求); max-age = 秒,HTTP 1.1版本,资源在本地缓存多少秒。 如果max-age和Expires同时存在,则被Cache-Control:max-age覆盖。Expires 的一个缺点: 就是返回的到期时间是服务器端的时间,这样存在一个问题,如果客户端的时间与服务器的时间相差很大,那么误差就很大,所以在HTTP 1.1版开始,使用Cache-Control: max-age=秒替代。Expires =max-age + “每次下载时的当前的request时间”,所以一旦重新下载的页面后,expires就重新计算一次,但last-modified不会变化。
1.3.3 既生 Last-Modified 何生 Etag ?
有童鞋可能会觉得使用Last-Modified已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要Etag呢?HTTP1.1中Etag的出现主要是为了解决几个Last-Modified比较难解决的问题:
- 一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新GET;
- 某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),
If-Modified-Since能检查到的粒度是s级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒); - 某些服务器不能精确的得到文件的最后修改时间。
这时,利用Etag能够更加准确的控制缓存,因为Etag是服务器自动生成或者由开发者生成的对应资源在服务器端的唯一标识符。
注⚠️:Last-Modified与ETag是可以一起使用的,服务器会优先验证ETag,一致的情况下,才会继续比对Last-Modified,最后才决定是否返回304。
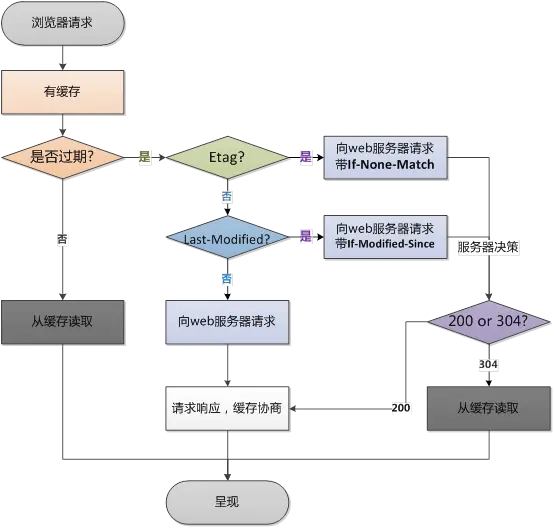
1.4 浏览器缓存过程
- 浏览器第一次加载资源,服务器返回200,浏览器将资源文件从服务器上请求下载下来,并把response header及该请求的返回时间一并缓存;
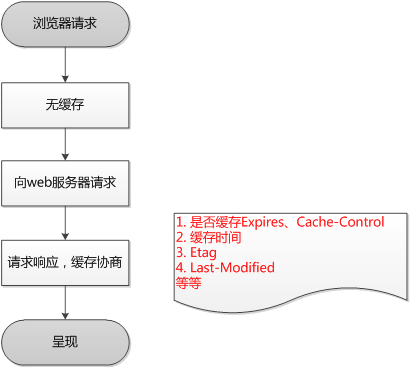
- 下一次加载资源时,先比较当前时间和上一次返回200时的时间差,如果没有超过
cache-control设置的max-age,则没有过期,命中强缓存,不发请求直接从本地缓存读取该文件(如果浏览器不支持HTTP1.1,则用expires判断是否过期);如果时间过期,没有命中强缓存,浏览器会发送请求到服务器,请求会携带第一次请求返回的有关缓存的header字段信息(Last-Modified/If-Modified-Since和Etag/If-None-Match); - 服务器收到请求后,优先根据
Etag的值判断被请求的文件有没有做修改,Etag值一致则没有修改,命中协商缓存,返回304;如果不一致则有改动,直接返回新的资源文件带上新的Etag值并返回200;; - 如果服务器收到的请求没有
Etag值,则将If-Modified-Since和被请求文件的最后修改时间做比对,一致则命中协商缓存,服务器返回304,并将新的响应header信息更新缓存中的对应header信息,但是并不返回资源内容,它会告知浏览器可以直接从缓存获取;否则返回新的last-modified和文件并返回200;
1.5 用户行为对浏览器缓存的影响
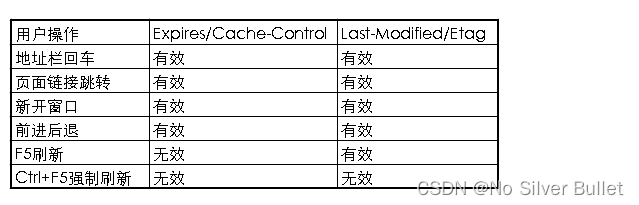
1.5.1 点击刷新按钮或者按F5
浏览器应用协商缓存,会带上If-Modifed-Since,If-None-Match,这就意味着服务器会对文件检查有效性,返回结果可能是304,也有可能是200。
1.5.2 用户按Ctrl+F5(强制刷新)
浏览器应用强缓存,而且不会带上 If-Modifed-Since,If-None-Match,相当于之前从来没有请求过,返回结果是200.
1.5.3 地址栏回车
浏览器发起请求,按照正常流程,本地检查是否过期,然后服务器端检查有效性,最后返回内容。
1.5.4 强缓存如何重新加载缓存缓存过的资源?
前面说到,使用强缓存时,浏览器不会发送请求到服务端,根据设置的缓存时间浏览器一直从缓存中获取资源,在这期间若资源产生了变化,浏览器就在缓存期内就一直得不到最新的资源,那么如何防止这种事情发生呢?
通过更新页面中引用的资源路径,让浏览器主动放弃缓存,加载新资源。
类似下图所示:

这样每次文件改变后就会生成新的query值,这样query值不同,也就是页面引用的资源路径不同了,之前缓存过的资源就被浏览器忽略了,因为资源请求的路径变了。
二、问题分析
页面在浏览器中进行渲染时,基于浏览器缓存机制,当用户访问之前访问过的系统页面时,浏览器会加载之前已经缓存的页面资源。
vue项目使用webpack进行编译,生产环境核心配置文件webpack.prod.conf.js配置的js资源文件生成策略如下:
output: {
// 打包后的文件放在dist目录里面
path: config.build.assetsRoot,
// 文件名称使用 static/js/[name].[chunkhash].js, 其中name就是main,chunkhash就是模块的hash值,用于浏览器缓存.
filename: utils.assetsPath('js/[name].[chunkhash].js'),
// chunkFilename是非入口模块文件,也就是说filename文件中引用了chunckFilename
chunkFilename: utils.assetsPath('js/[id].[chunkhash].js')
},
....
// extract css into its own file
new ExtractTextPlugin({
// 生成独立的css文件,下面是生成独立css文件的名称
filename: utils.assetsPath('css/[name].[contenthash].css')
}),
其中,chunkhash与contenthash的区别详参博文《Vue进阶(七十):了解 webpack 的 hash、chunkhash、contenthash》。
no-cache浏览器会缓存,但刷新页面或者重新打开时会请求服务器,服务器可以响应304,如果文件有改动就会响应200。no-store浏览器不缓存,刷新页面需要重新下载页面。
三、解决方案
在 HTTP 响应头中添加缓存控制的指令来控制浏览器缓存。修改index.html的内容,可以使用以下缓存请求指令,让所有的css/js资源重新加载:

<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, user-scalable=no">
<meta http-equiv="pragram" content="no-cache">
<meta http-equiv="cache-control" content="no-cache, no-store, must-revalidate">
<meta http-equiv="expires" content="0">
<link rel="icon" href="<%= BASE\_URL %>favicon.ico">
</head>
其中,
Cache-Control表示控制缓存的行为;Pragma表示报文指令。Pragma是HTTP/1.1之前版本的历史遗留字段,仅作为与HTTP/1.0的向后兼容而定义。所有的中间服务器如果都能以HTTP/1.1为基准,那直接采用Cache-Control: no-cache指定缓存的处理方式是最为理想的。但要整体掌握全部中间服务器使用的 HTTP 协议版本却是不现实的。因此,发送的请求会同时含有Pragma: no-cache与Cache-Control: no-cache两个首部字段。expires表示缓存的载止时间,允许客户端在这个时间之前不去检查(发请求);must-revalidate表示可缓存但必须再向源服务器进行确认。使用must-revalidate指令,代理会向源服务器再次验证即将返回的响应缓存目前是否仍然有效。若代理无法连通源服务器再次获取有效资源的话,缓存必须给客户端一条504(Gateway Timeout)状态码。另外,使用must-revalidate指令会忽略请求的max-stale指令(即使已经在首部使用了max-stale,也不会再有效果)。
此外,还有no-transform配置参数表示代理不可更改媒体类型。使用 no-transform 指令规定无论是在请求(客户端向代理发请求,代理响应)还是响应(源服务器向代理发响应,代理缓存)中,缓存都不能改变实体主体的媒体类型。这样做可防止缓存或代理压缩图片等类似操作。
注⚠️:
no-cache从字面意思上很容易误解成为不缓存,但事实上no-cache代表不缓
存过期资源,缓存会向源服务器进行有效性确认后处理资源,也许称为do-notserve- from-cache-without-revalidation更合适。no-store才是真正地不进行缓存!no-store会导致浏览器禁用缓存,no-store用于防止重要、保密信息被无意的发布。在请求消息中发送将使得请求和响应消息都不使用缓存。页面渲染需要重新下载页面关联资源,进而导致网路带宽占用过高,页面渲染性能下降,内存占用过高等问题发生。建议非必要不使用该参数配置!Cache-Control指定请求和响应遵循的缓存机制。在请求消息或响应消息中设置Cache-Control并不会修改另一个消息处理过程中的缓存处理过程。
疑问:在vue项目中, 应用Cache-Control可否实现指定特定页面实现请求和响应遵循的缓存机制?
答:
四、延伸阅读: HTTP 状态码汇总
4.1 1xx(临时响应)
表示临时响应并需要请求者继续执行操作的状态代码。
- 100 (继续) 请求者应当继续提出请求。 服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。
- 101 (切换协议) 请求者已要求服务器切换协议,服务器已确认并准备切换。
4.2 2xx (成功)
表示成功处理了请求的状态代码。
- 200 (成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。
- 201 (已创建) 请求成功并且服务器创建了新的资源。
- 202 (已接受) 服务器已接受请求,但尚未处理。
- 203 (非授权信息) 服务器已成功处理了请求,但返回的信息可能来自另一来源。
- 204 (无内容) 服务器成功处理了请求,但没有返回任何内容。
- 205 (重置内容) 服务器成功处理了请求,但没有返回任何内容。
- 206 (部分内容) 服务器成功处理了部分 GET 请求。
4.3 3xx (重定向)
表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向。
- 300 (多种选择) 针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。
- 301 (
永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。 - 302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
- 303 (查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。
- 304 (
未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。 - 305 (使用代理) 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。
- 307 (
临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
4.4 4xx(请求错误)
这些状态代码表示请求可能出错,妨碍了服务器的处理。
- 400 (错误请求) 服务器不理解请求的语法。
- 401 (
未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。 - 403 (
禁止) 服务器拒绝请求。 - 404 (
未找到) 服务器找不到请求的资源。 - 405 (方法禁用) 禁用请求中指定的方法。
- 406 (不接受) 无法使用请求的内容特性响应请求的网页。
- 407 (需要代理授权) 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。
- 408 (请求超时) 服务器等候请求时发生超时。
- 409 (冲突) 服务器在完成请求时发生冲突。 服务器必须在响应中包含有关冲突的信息。
- 410 (已删除) 如果请求的资源已永久删除,服务器就会返回此响应。
- 411 (需要有效长度) 服务器不接受不含有效内容长度标头字段的请求。
- 412 (未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。
- 413 (请求实体过大) 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。
- 414 (请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法处理。
- 415 (不支持的媒体类型) 请求的格式不受请求页面的支持。
- 416 (请求范围不符合要求) 如果页面无法提供请求的范围,则服务器会返回此状态代码。
- 417 (未满足期望值) 服务器未满足"期望"请求标头字段的要求。
4.5 5xx(服务器错误)
这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错。
- 500 (服务器内部错误) 服务器遇到错误,无法完成请求。
- 501 (尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。
- 502 (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。
- 503 (
服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。 - 504 (
网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
总结
大厂面试问深度,小厂面试问广度,如果有同学想进大厂深造一定要有一个方向精通的惊艳到面试官,还要平时遇到问题后思考一下问题的本质,找方法解决是一个方面,看到问题本质是另一个方面。还有大家一定要有目标,我在很久之前就想着以后一定要去大厂,然后默默努力,每天看一些大佬们的文章,总是觉得只有再学深入一点才有机会,所以才有恒心一直学下去。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】















 2387
2387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









