







收集整理了一份《2024年最新Python全套学习资料》免费送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来
如果你需要这些资料,可以添加V无偿获取:hxbc188 (备注666)

正文
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘https://www.tmall.com/’)
tm = “document.querySelector(‘.tmall-logo-img’).style.display=‘none’”
fox.execute_script™
12306出发日期只读可选,修改成可写,

注意大小写,readOnly
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘https://www.12306.cn/’)
tm = “document.getElementById(‘train_date’).readOnly=false”
fox.execute_script™

页面滚动条
因为如果页面没有完全显示,element如果是在下拉之后才能显示出来,只能先滚动到该元素才能进 行click,否则是不能click
1. document.body.scrollHeight 获取对象的滚动高度
2. document.body.scrollWidth 获取对象的滚动宽度
3、window.scrollTo(x,y) 方法可把内容滚动到指定的坐标。
动到页面底部
1. 左下角:window.scrollTo(0,document.body.scrollHeight)
2. 右下角:window.scrollTo(document.body.scrollWidth,document.body.scrollHeight)
3. 指定位置:window.scrollTo(0,数值)
4. 滑动到指定元素:ele.srollIntoView() true:与元素顶部对其,false:与元素底部对齐
document.querySelector(‘’).scrollIntoView(false)
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘https://www.taobao.com/’)
fox.maximize_window()
打印页面高度
js_height = “return document.body.scrollHeight”
height = fox.execute_script(js_height)
print(height)
打印页面宽度
js_width = “return document.body.scrollWidth”
width = fox.execute_script(js_width)
print(width)
下滑1000px
js_left = “window.scrollTo(0,1000)”
fox.execute_script(js_left)
下滑最底部
jx_left_down = “window.scrollTo(0,document.body.scrollHeight)”
fox.execute_script(jx_left_down)
下滑到指定元素
jx_left_zd = “document.querySelector(‘ul.list > a:nth-child(3) > div:nth-child(1) > div:nth-child(2)’).scrollIntoView(false)”
fox.execute_script(jx_left_zd)
如果是页面内部的滚动条,那就直接上元素定位,ele是元素定位赋的变量。这里实在没找到例子,了解一下。
1. ele.scrollHeight # 获取滚动条高度
2. ele.scrollWidth # 获取横向滚动条宽度
3. ele.scrollTo(x,y) #滑动到指定坐标位置
4. ele.scrollTop=1000 #控制纵向滚动条位置,距离y轴原点的距离
5. ele.scrollLeft=1000 # 控制横向滚动条位置,距离x轴原点的距离
等待时间
====
等待时间有三类,隐式等待,显示等待,强制等待,各有个的好处,且可以搭配使用,等待时间的统一好处就是帮助你更好的定位元素,有时候网络慢了,元素没有加载出来,或者想看看具体的点击操作等,等待时间都可以帮助你解决。
隐式等待不需要额外导包,强制等待与显示等待需要额外导包,看例子
强制等待
最简单的一种办法就是强制等待sleep(X),强制让浏览器等待X秒,不管当前操作是 否完成,是否可以进行下一步操作,都必须等X秒的时间。
import time
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘http://www.baidu.com’)
强制等待2S
time.sleep(2)
退出浏览器
fox.quit()
这里新介绍了一个方法,.quit(),退出的意思,这里导入了一个time,用去强制等待2S,2S后自动退出浏览器。强制等待还有一种写法,较为简便:
from time import sleep
from selenium import webdriver
fox = webdriver.Firefox()
fox.get(‘http://www.baidu.com’)
强制等待2S
sleep(2)
退出网址
fox.quit()
效果是一样的,在后续就不需要每次都time.sleep()了。
缺点:
1. 不能准确把握需要等待的时间(有时操作还未完成,等待就结束了,导致报错;有时操作已经 完成了,但等待时间还没有到,浪费时间)
2. 如果在用例中大量使用,会浪费不必要的等待时间,影响测试用例的执行效率。
优点:
1. 使用简单,可以在调试时使用
隐式等待
对其设置了一个最长等待时间,如果在规定时间内网页加载完成,则执行 下一步,否则一直等到时间结束,然后执行下一步操作
from selenium import webdriver
fox = webdriver.Firefox()
隐式等待5S
fox.implicitly_wait(5)
fox.get(‘http://www.baidu.com’)
退出网址
fox.quit()
隐式等待5S,这里的例子比较简单,可能你看到的就是刚刚打开就自动退出。
缺点:
1. 使用隐式等待,程序会一直等待整个页面加载完成,才会执行下一步操作;但有时候页面想 要的元素早已经加载完成了,但是因为网页上个别元素还没有加载完成,仍要等到页面全部 完成才能执行下一步,使用也不是很灵活。
2. 在等待时间内页面没有加载完成,时间一到也会进入下一步操作;这种情况可能出现要定位 的元素没有出现,从而报元素无法找到的错误。
优点:
1. 隐性等待对整个driver的周期都起作用,每一次操作都会调用隐式等待,所以只要设置一次 即可
显示等待
程序每隔X秒看一眼,如果条件成立了,则执行下一步,否则继续等待,直到超 过设置的最长时间,然后抛出TimeoutException异常
显示等待一般性结合until来使用,until结合匿名函数lambda来使用,有些人就会问为什么要这样呢,因为显示等待搭配起来可以做更多的工作 ,相对于其他两种等待方式,显示等待可以做的工作超乎你的想象。甚至可以直接作为断言来使用。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
fox = webdriver.Firefox()
fox.get(‘https://baidu.com’)
fox.find_element_by_id(‘kw’).send_keys(‘python’)
fox.find_element_by_id(‘su’).click()
ele = ‘/html/body/div[1]/div[4]/div[1]/div[3]/div[3]/h3/a’
驱动,最大等待时间,检测时间间隔,超时后异常信息
wait = WebDriverWait(fox,10,0.5)
判断一个元素是否在存在界面上,message表示若定位不到这个元素啧给出提示信息
l = wait.until(lambda x:x.find_element_by_xpath(ele).is_displayed(),message = ‘无此定位’)
print(l)
.is_displayed() # 元素是否显示,返回True
.is_selected() # 元素是否被选中,返回False
.is_enabled() # 元素是否可用,返回True
退出网址
fox.quit()
这里的message作用就是,当你元素无法定位的时候控制台就会提示你此消息。
缺点:
1. 使用相对比较复杂;
2. 和强制等待类似,每一行等待只执行一次,如果要进行多个元素的等待,则需要多次写入 优点:
1. 等待判断准确,不会浪费多余的等待时间,在用例中使用,可以提高执行效率。
三种等待时间就介绍完了,等待时间是可以互相通用的,隐式等待过程中,你可以加入强制等待,在写项目的过程中,你可以定义一个隐式等待,必要的时候给定强制等待,用显示等待来做一个断言。用多了就知道哪个地方该用什么样的等待时间了。
EC模块
====
EC全名expected_conditions,因为名字太长,很多人都直接将其简写,所以导入包的过程中改名为EC了 。
简介:
expected_conditions是Selenium的一个模块,主要用于对页面元素的加载进行判断,包括元素是否 存在,可点击等等。
Expected Conditions的使用场景一版有两种:
1. 直接在断言中使用
2. 与WebDriverWait配合使用,显示等待页面上元素出现或者消失
写法
1、EC.方法(参数)(driver) ,包含True,不包含False
2、EC.方法(参数).__call__(driver),包含True,不包含False
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
fox = webdriver.Firefox()
fox.get(‘https://www.baidu.com’)
判断标题是否等于百度一下
see = EC.title_is(‘百度一下,你就知道’)(fox)
print(see)
see1 = EC.title_is(‘百度一下,你就知道’).call(fox)
print(see1)
判断标题是否包含百度一下
see2 = EC.title_contains(‘百度一下’).call(fox)
print(see2)
判断元素是否存在(元素定位方式,属性值)
baidu = (‘id’,‘su’)
res = EC.presence_of_element_located(baidu)(fox)
print(res)
搭配显示等待扩展
这里扩张,多增加一点内容,元素定位方式By.,这个定位方式与前面的find_element_by_系列差别无几,这个方式更适合封装的时候使用,看下面的例子。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
搭配显示等待
se = webdriver.Firefox()
se.get(‘https://www.baidu.com’)
#判断元素是否存在
bd_bth = (By.ID,‘kw’)
ele1 = EC.presence_of_element_located(bd_bth)(se)
ele1.send_keys(‘python’)
#判断元素是否存在
bd_bth1 = (By.ID,‘su’)
ele2 = EC.presence_of_element_located(bd_bth1)(se)
ele2.click()
res_link = (By.XPATH,‘/html/body/div[1]/div[3]/div[1]/div[3]/div[1]/h3/a’)
结合until方法使用,EC调用类不需要调用se
res1 = WebDriverWait(se,10).until(EC.presence_of_element_located(res_link),message=‘元素不存在’)
res1.click()
fox.quit()
WebDriverWait(se,10),默认间隔等待时间是0.5S,所以可以不写,看了上面的例子,是不是对元素定位有了一个不错的认知,这样的方式要是觉得简洁你也可以这么写,定位方式就这些,By系列:By.ID,By.XPATH,By.NAME…但凡有的By都可以.上它,写法就如上述例子。
无头模式
====
听这名字是不是觉得不可思议,但是告诉你,无头模式就是不打开浏览器的情况下,让代码照常的运行。
声明火狐配置对象
fox = webdriver.FirefoxOptions()
无头模式1
fox.set_headless()
无头模式2,True为无头,False为有头模式
fox.headless = True
无头模式3,headless为无头,head为有头
fox.add_argument(argument=‘headless’)
实例化火狐浏览器
fx = webdriver.Firefox(firefox_options = fox)
fx.get(‘http://www.baidu.com’)
if fx.title==‘百度一下,你就知道’:
print(‘打开成功’)
else:
print(‘打开失败’)
这里给出了三种无头模式,喜欢哪种就用哪种吧,无头模式还没比较方便的,至少我认为方便不少。特殊时候特殊使用。
窗口切换
====
这个操作还是十分实用的,可以帮助你定位很多的页面,比如知乎登录界面,QQ网页邮箱等。。。先来了解一下其他的操作吧。慢慢来,切记,跟着码代码。
设置窗口大小
先打开百度界面,然后进行一些列的设置操作。
from selenium import webdriver
fx = webdriver.Firefox()
隐式等待10秒
fx.implicitly_wait(10)
fx.get(‘http://www.baidu.com’)
设置窗口指定大小
fx.set_window_size(900,600)
窗口最大化
fx.set_minmize_window()
最小化
fx.set_maxmize_window()
三种设置窗口都可以自己跑起来看看,这里我用了隐式等待,隐式等待在调试过程中还是比较方便的。
多窗口切换
有些页面的链接打开后,会重新打开一个窗口,对于这种情况,想在新页面上操作,就 得先切换窗口了。
在web应用中,每一个窗口都有一个对应的唯一句柄来进行标识,如果我们切换窗口, 则只需要获取新窗口的句柄,然后切换句柄即可。
每一个窗口的唯一标识,每个窗口的句柄都不一样
1. 获取当前句柄 :driver.current_window_handle
2. 获取所有句柄:driver.window_handles
3. 切换句柄:driver.switch_to_window(句柄号)
我们看代码:
from time import sleep
from selenium import webdriver
# 实例化火狐浏览器
fox = webdriver.Firefox()
隐式等待5秒
fox.implicitly_wait(5)
fox.get(‘https://baidu.com’)
获取窗口句柄号
bai_1 = fox.current_window_handle
print(bai_1)
点击学术连接
fox.find_element_by_link_text(‘学术’).click()
bai_2 = fox.current_window_handle
print(bai_2)
获取所有窗口句柄号
all_h = fox.window_handles
print(all_h)
切换窗口,列表取值1,python舍弃的方法
fx.switch_to_window(all_h[-1])
切换窗口,列表取值2,python推荐的方法
fox.switch_to.window(all_h[-1])
点击文本操作
fox.find_element_by_class_name(‘new_index_icon_scholar’).click()
sleep(2)
切回百度窗口
fox.switch_to.window(bai_1)
搜索其他内容
fox.find_element_by_id(‘kw’).send_keys(‘python’)
fox.find_element_by_id(‘su’).click()
fox.quit()
这个例子,获取单个窗口号是可以省略的,因为后面我写了一个获取全部的窗口号,主要是为做了解,但也要记住了。
iframe
这个就比较有意思了,事关切换到登录界面进行登录操作!
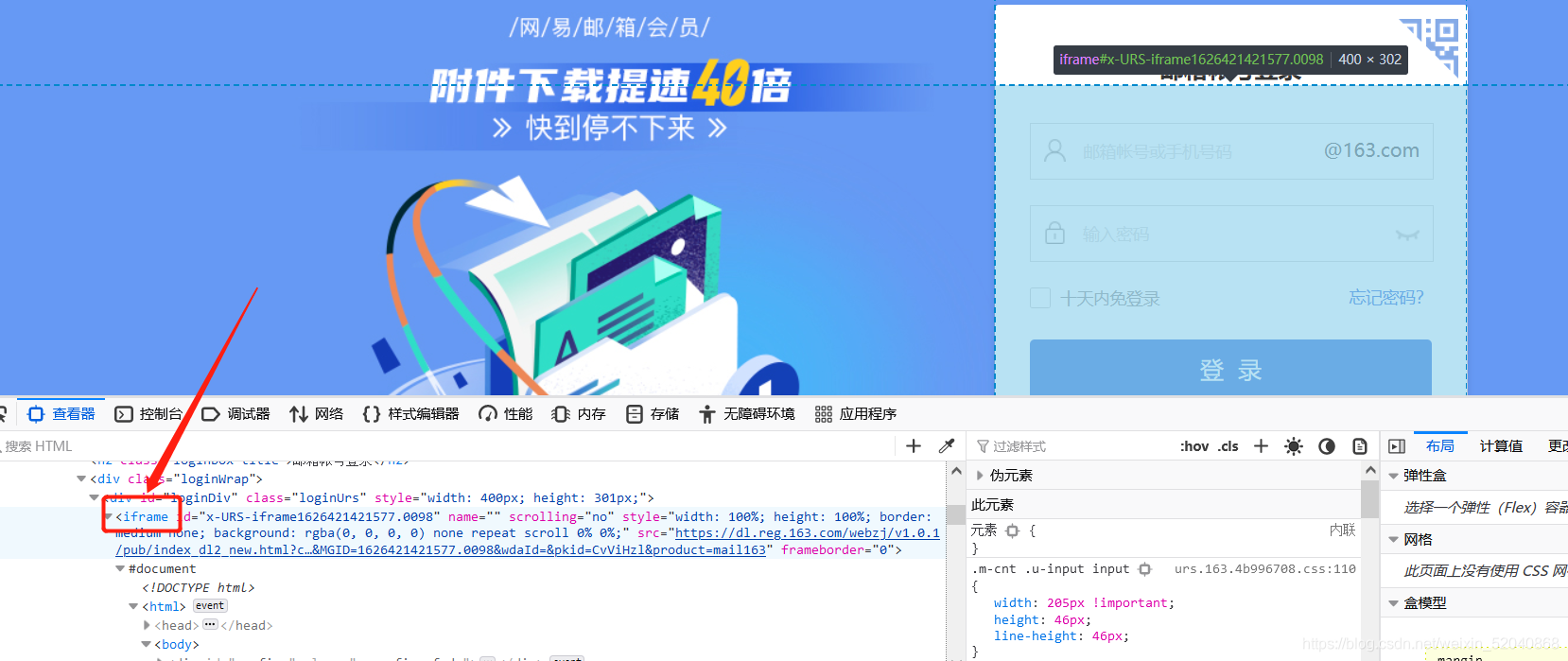
如果学了上述之后,你觉的你可以了,那你就很膨胀,飘了?
有iframe的不做特殊切换操作是定位不了的,不信 你可以去试试。定位这个特殊的元素,与之前的操作也近乎相似,看这个163邮箱的例子。
iframed定位案例
fx = webdriver.Firefox()
fx.implicitly_wait(10)
fx.get(‘https://mail.163.com’)
定位到iframe,列表取值第一个iframe
if_rame = fx.find_elements_by_tag_name(‘iframe’)[0]
切换到iframe中,第一种方法
fx.switch_to_frame(if_rame)
第二种
fx.switch_to.frame(if_rame)
用户名
fx.find_element_by_name(‘email’).send_keys(‘1235646@163.com’)
密码
fx.find_element_by_name(‘password’).send_keys(‘6541566’)
点击登录
fx.find_element_by_id(‘dologin’).click()
切出iframe,点击企业邮箱
fx.switch_to_default_content()
fx.find_element_by_link_text(‘企业邮箱’).click()
fx.quit()
这个画横线的是过期语法,不过不影响使用。学会了这个,赶紧去试试QQ空间吧,自己写一个出来,https://qzone.qq.com/地址给到给到你们啦。
弹窗处理
Alter:一般只有确认按钮
confirm:一般有确认取消按钮
prompt:一般有文字输入款,加上确认取消按钮
操作 方法:
1. switch_to_alert() 首先要切换到 alert 弹出框上,才能做确定、取消等这些操作
2. accept() :点击"确认"
3. dismiss() :点击"取消"
4. send_keys() :输入文本值 --仅限于 prompt,在 alert 和 confirm 上没有输入框
5. text:获取文本值



下面举个例子,给出代码,弹框找个有弹框的网址就能试手:
fox = webdriver.Firefox()
fox.get(‘http://123456789.com’)
fox.implicitly_wait(5)
“”"
定位操作
fox.find_element_by_xpath(‘/html/body/a’).click()
fox.find_element_by_name(‘username’).send_keys(‘123456’)
fox.find_element_by_name(‘password’).send_keys(‘456’)
fox.find_element_by_xpath(‘/html/body/form/p[3]/button’).click()
sleep(2)
以上是小北写的时候必须要登录才能看到,所以可以忽略,以下是重点
“”"
定位弹框的元素
fox.find_element_by_name(‘promptbutton’).click()
sleep(2)
切换窗口
click_d = fox.switch_to_alert()
sleep(2)
#点击确认
click_d.accept()
给个HTML弹窗源码,可以给你们试试水,复制到txt文本,把后缀改成.html打开即可:
鼠标键盘操作
======
此处无特别的地方,但是既然讲了,那么它就有它有用的地方
键盘操作
此操作需要导入一个包:
from selenium.webdriver.common.keys import Keys
我们先来看看一般常用的一些键位
| 删除键(BackSpace) | send_keys(Keys.BACK_SPACE) |
| 空格键(Space) | send_keys(Keys.SPACE) |
| 制表键(Tab) | send_keys(Keys.TAB) |
| 回退键(Esc) | send_keys(Keys.SCAPE) |
| 回车键(Enter) | send_keys(Keys.ENTER) |
| 全选(Ctrl+A) | send_keys(Keys.CONTROL, 'a') |
| 复制(Ctrl+C) | send_keys(Keys.CONTROL, 'c') |
| 剪切(Ctrl+X) | send_keys(Keys.CONTROL, 'x') |
| 粘贴(Ctrl+V) | send_keys(Keys.CONTROL, 'v') |
| 键盘F1 | send_keys(Keys.F1) |
直接上一个百度搜索案例,这个嘛主要做一个了解,别到后面需要的时候没有这个技能点,两个例子让你明明白白:
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
键盘操作
fox = webdriver.Firefox()
fox.implicitly_wait(5)
fox.get(‘https://baidu.com’)
ele = fox.find_element_by_id(‘kw’)
ele.send_keys(‘python’)
删除一个字母
ele.send_keys(Keys.BACK_SPACE)
ele.send_keys(Keys.BACKSPACE)
全选删除
ele.send_keys(Keys.CONTROL,‘a’)
ele.send_keys(Keys.BACK_SPACE)
刷新界面
ele.send_keys(Keys.F5)
输入空格+教程
ele.send_keys(’ 教程’)
全选,剪切,粘贴
ele.send_keys(Keys.CONTROL,‘a’)
ele.send_keys(Keys.CONTROL,‘x’)
百度输入框粘贴
fox.find_element_by_id(‘kw’).send_keys(Keys.CONTROL,‘v’)
fox.quit()
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
fox = webdriver.Firefox()
fox.get(‘https://baidu.com’)
fox.implicitly_wait(5)
定位输入框,点击搜索。
ele = fox.find_element_by_id(‘kw’)
ele.send_keys(‘python 教程’)
键盘回车
ele.send_keys(Keys.ENTER)
光标向左移动两格
for i in range(2):
ele.send_keys(Keys.ARROW_LEFT)
光标向左移动6格
for j in range(7):
ele.send_keys(Keys.LEFT_SHIFT,Keys.ARROW_LEFT)
剪切
ele.send_keys(Keys.CONTROL,‘x’)
光标向左移动两格
for m in range(2):
ele.send_keys(Keys.ARROW_RIGHT)
复制
ele.send_keys(Keys.CONTROL,‘v’)
按下回车键
ele.send_keys(Keys.ENTER)
清空内容
for b in range(9):
ele.send_keys(Keys.BACK_SPACE)
fox.quit()
get全部的操作,此处一定要跟着码字,别偷懒!!!
鼠标操作
也是需要导入 一个包
from selenium.webdriver.common.action_chains import ActionChain
来看看常用的操作表:
| click(xb) | 鼠标左键单击 |
| context_click(xb) | 鼠标右键单击 |
| double_click(xb) | 鼠标左键双击 |
| drag_and_drop(source,target) | 拖动到某个元素后松开 |
| move_to_element(xb) | 鼠标悬停在一个元素上 |
| click_and_hold(xb) | 鼠标左键单击,不松开 |
| release | 在某个元素上松开鼠标左键 |
| perform() | 执行上述鼠标操作 |
这里一个例子已经无法说明其中的奥义了,就我个人而言,这个鼠标操作可以干太多的事情了,如果说元素定位以及很强了,那么这个鼠标 操作就是如虎添翼,直接起飞,必须得压轴讲解:
以携程为例子
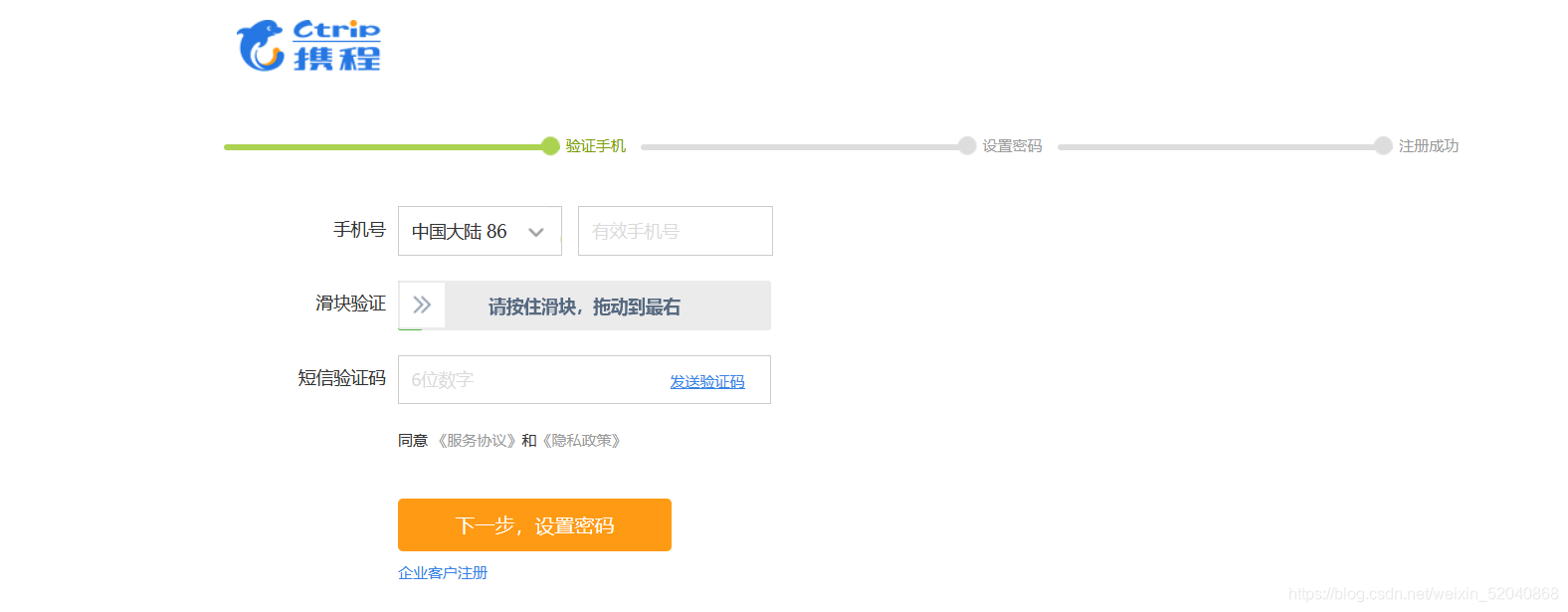

使用鼠标把这个滑块验证搞定了。思路:先定位滑块元素,定位再使用滑块距离,再鼠标按钮进行操作
from selenium import webdriver
from selenium.webdriver import ActionChains
fox = webdriver.Firefox()
fox.implicitly_wait(5)
fox.get(‘https://passport.ctrip.com/user/reg/home’)
点击 同意按钮
fox.find_element_by_xpath(‘/html/body/div[6]/div[3]/a[2]’).click()
定位滑块,并输出宽度
ele = fox.find_element_by_class_name(‘cpt-img-double-right-outer’)
ele_p = ele.size[‘width’]
定位滑块框的宽度
ele_width = fox.find_element_by_class_name(‘cpt-drop-bg-container’)
ele_l = ele_width.size[‘width’]
需要滑动的距离
ele_len = ele_l - ele_p
实例化鼠标操作
actions = ActionChains(fox)
拖动指定位置并松开,拖动的元素,x轴,y轴
actions.drag_and_drop_by_offset(fox.find_element_by_class_name(‘cpt-img-double-right-outer’),ele_len,0).perform()
sleep(2)
第二个例子淘宝的鼠标悬浮操作:

这个操作其实帮助你简洁一些繁琐的元素定位,直接鼠标上也是可以的。
from selenium import webdriver
from selenium.webdriver import ActionChains
from time import sleep
fox = webdriver.Firefox()
fox.implicitly_wait(5)
fox.get(‘https://www.taobao.com’)
定位元素
ele = fox.find_element_by_class_name(‘site-nav-region’)
sleep(2)
实例化鼠标操作
actions = ActionChains(fox)
执行定位操作
actions.move_to_element(ele).perform()
click_q = fox.find_element_by_xpath(‘/html/body/div[1]/div[1]/div/ul[1]/li[1]/div[2]/ul/li[4]’)
执行点击操作
actions.click(click_q).perform()
sleep(2)
fox.quit()
最后补充几点基本操作:
refresh() eg: driver.refresh() 刷新
forward() eg: driver.forward() 前进
back() eg: driver.back() 后退
get_screenshot_as_file(保存路径) eg: get_screenshot_as_file(‘D:/jie.png’) 截图,png格式
close() eg: driver.close() 关闭浏览器,不终止进程
当你看到很多时候元素定位有空格的,如下:
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
如果你需要这些资料,可以添加V无偿获取:hxbc188 (备注666)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
片描述](https://img-blog.csdnimg.cn/8fc093dcfa1f476694c574db1242c05b.png)
(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。
(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。
(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。
(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。
这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
如果你需要这些资料,可以添加V无偿获取:hxbc188 (备注666)
[外链图片转存中…(img-LUnz36hi-1713853730354)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 532
532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









