







现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
二、解析图片地址,进行简单JS解密
点击进入第一话后,分析网页源码,发现图片保存在a标签下的img中,但是需要爬取的src是用javascript写的!这个时候直接用lxml库去解析是拿不到图片的。 这里,我们先分析图片链接的组成,用正则把提取出来即可。
这里,我们先分析图片链接的组成,用正则把提取出来即可。
src='"+m201304d+"newkuku/2016/02/15/鬼灭之刃][第1话/JOJO\_001513.jpg'
其中,m201304是加密的部分,这个网站比较简单,直接找到js4.js文件,即可发现m201304对应的是http://v2.kukudm.com/,除此之外还有三个加密码,我们可以构建成列表,用if判断是否含如下加密码,再用replace替换即可。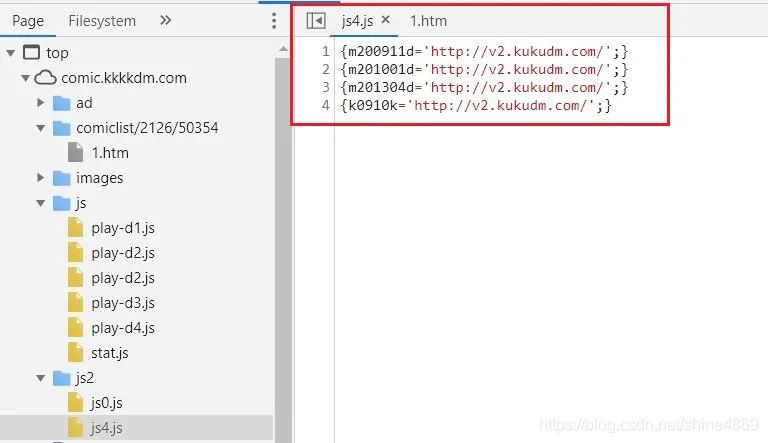
三、翻页分析

 分析URL可知,第一话共54页,通过改变末尾的/number.html即可实现翻页
分析URL可知,第一话共54页,通过改变末尾的/number.html即可实现翻页
全部代码
所有图片都放在桌面的comic文件夹下
import requests
import json
import os
import re
import time
os.chdir('C:/Users/dell/Desktop/comic')
url='https://api.soman.com/soman.ashx?action=getsomancomicdetail&comicname=%E9%AC%BC%E7%81%AD%E4%B9%8B%E5%88%83&source=kuku%E5%8A%A8%E6%BC%AB'
header={'user-agent':"Opera/9.80 (Windows NT 6.0; U; en) Presto/2.8.99 Version/11.10"}
def get\_html(url):
r=requests.get(url,headers=header,timeout=5)
r.encoding='gbk'
if r.status_code==200:
return r.text
else:
print('网络连接异常')
def get\_total\_chapter():
data=json.loads(get_html(url))
chapter_total=data['Comics'][2]['Chapters']
for item in chapter_total:
yield item.get('Url')
def save\_items(url,count):
r=requests.get(url,headers=header,timeout=5)
with open('./第{}话/'.format(count)+str(int(time.time()))+'.jpg','wb') as f:
f.write(r.content)
def get\_all\_img(): #得到每话总图片数
src_list=["m200911d","m201001d","m201304d","k0910k"]
count=0
for chapter in get_total_chapter():
try:
count+=1
os.makedirs('./第{}话'.format(count))
pat='共(.\*?)页'
total_page=re.search(pat,get_html(chapter)).group(1)
for page in range(1,int(total_page)+1):
pat1='<IMG SRC=(.\*)></a>'
src=re.search(pat1,get_html(chapter)).group(1)
for item in src_list:
if item in src_list:
src=src.replace("+"+item+"+",'http://v2.kukudm.com/').replace('"','')
save_items(eval(src),count)
print('第{}话第{}页爬取完成'.format(count,page))
now_page=re.search('.\*/(.\*)\.htm',chapter).group(1)
chapter=chapter.replace(str(now_page)+'.htm',str(page+1)+'.htm')
except:
print('未爬取到数据')
if __name__=='\_\_main\_\_':
get_all_img()
最终爬取的漫画如下(这里仅作示例,只爬取了前10话的内容):
 10话大概爬取了25分钟左右,算下来,爬完188话,也要7个多小时…后续可以用多进程方法加速一下爬取速度。
10话大概爬取了25分钟左右,算下来,爬完188话,也要7个多小时…后续可以用多进程方法加速一下爬取速度。
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)

👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









