







 本文分享了一份全面的Web前端学习资料,包括零基础到进阶课程,涵盖95%前端知识点。重点介绍了JavaScript的垃圾回收机制,如标记清除算法,并提供大厂面试经验分享和系统化的学习路径。作者鼓励加入技术交流社区,共同提升技术能力。
本文分享了一份全面的Web前端学习资料,包括零基础到进阶课程,涵盖95%前端知识点。重点介绍了JavaScript的垃圾回收机制,如标记清除算法,并提供大厂面试经验分享和系统化的学习路径。作者鼓励加入技术交流社区,共同提升技术能力。
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Web前端全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上前端开发知识点,真正体系化!
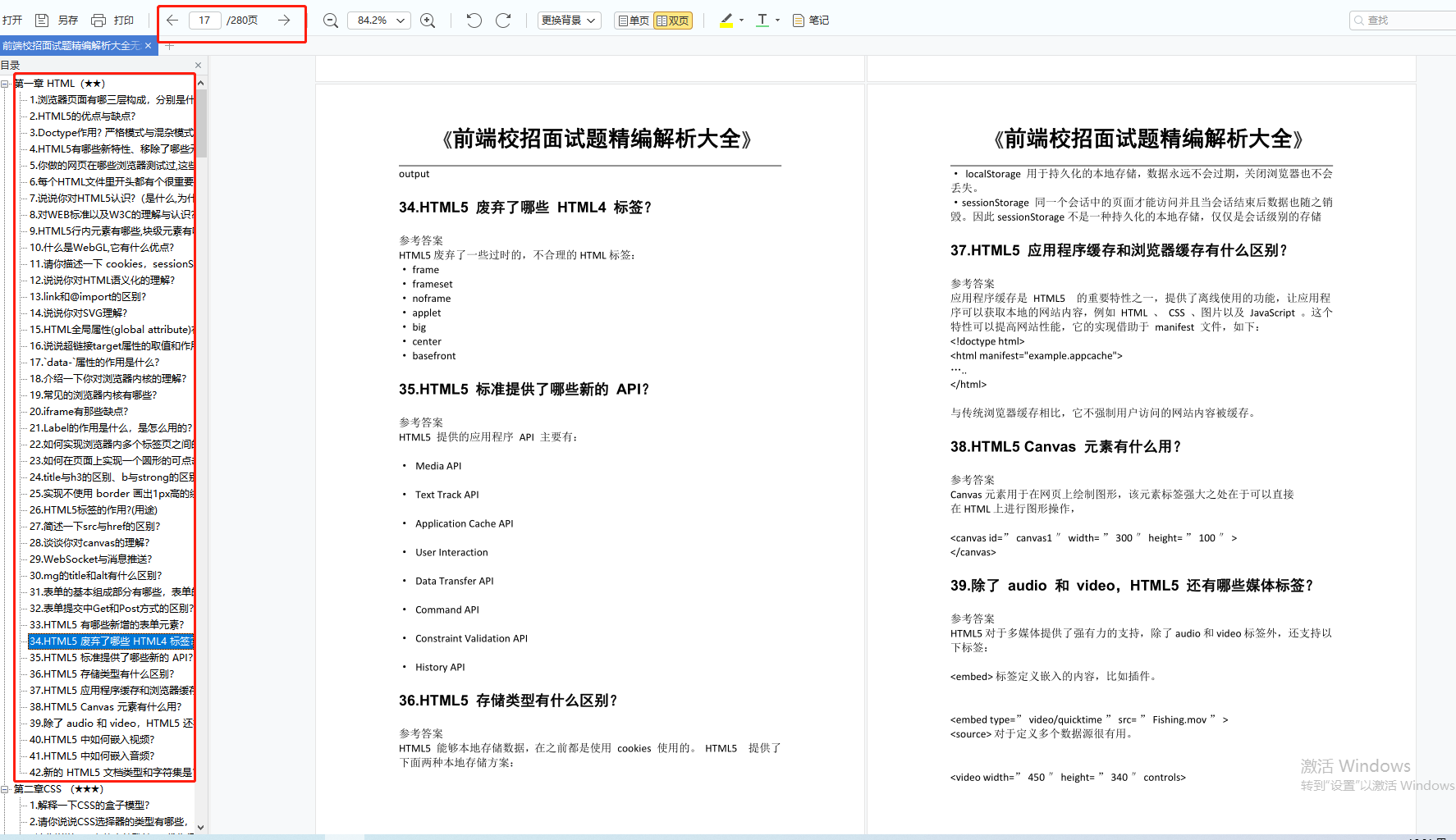
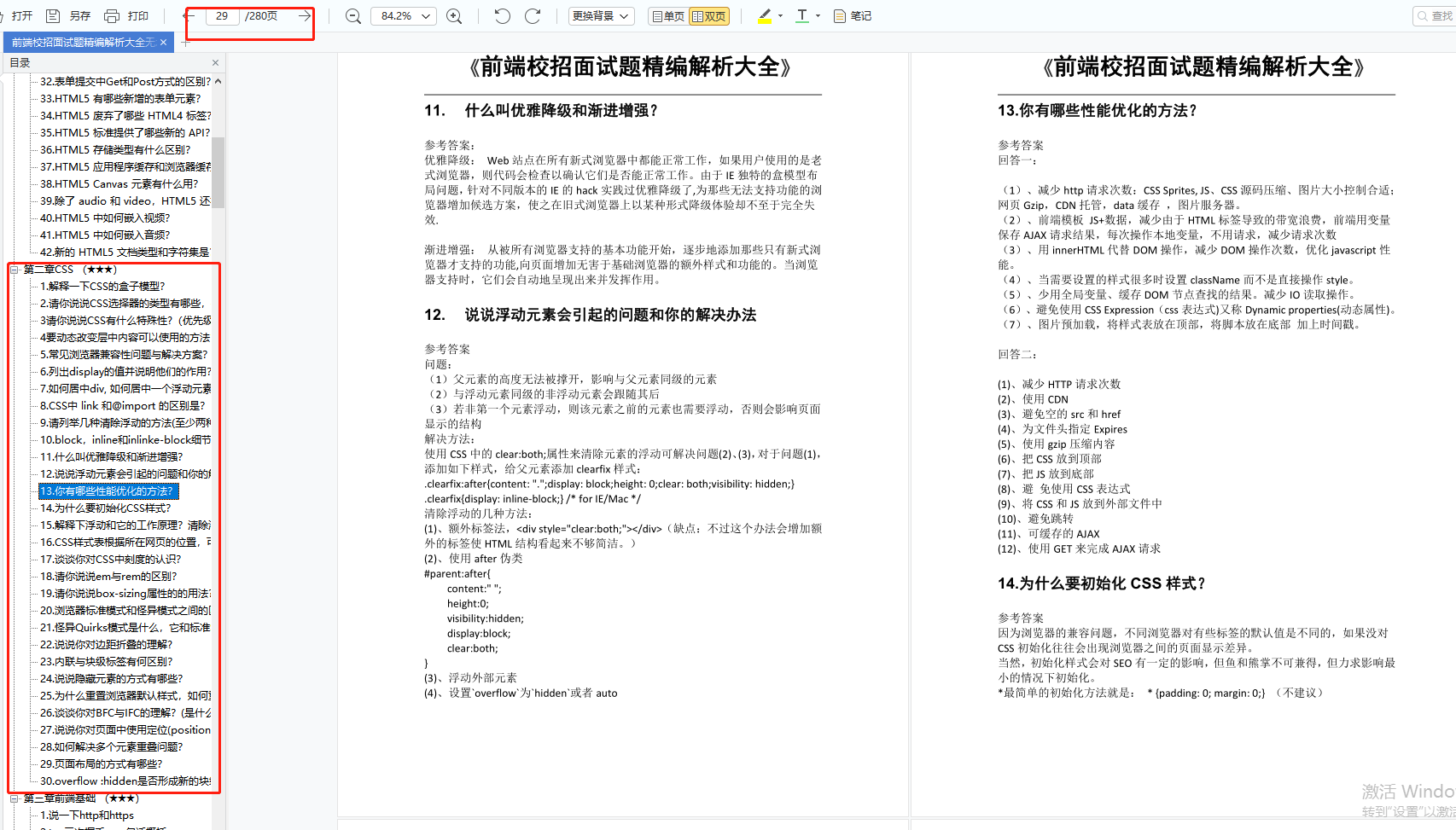
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注前端)

正文
-
内存分配:当我们申明变量、函数、对象,并执行的时候,系统会自动为他们分配内存
-
内存使用:即读写内存,也就是使用变量、函数等
-
内存回收:使用完毕,由垃圾回收机制自动回收不再使用的内存
垃圾回收机制策略
标记清除算法
JavaScript 中最常用的垃圾收集方式是标记清除(mark-and-sweep)。
它的实现原理就是通过判断一个变量是否在执行环境中被引用,来进行标记删除。
垃圾回收器给所有内存变量进行标记,然后去掉执行环境中和被引用的标记,剩余的标记变量是 不会被用到的变量,会被垃圾回收器回收。
这个算法把“对象是否不再需要”简化定义为“对象是否可以获得”。
该算法假定设置一个叫做根(root)的对象(在Javascript里,根是全局对象)。垃圾回收器将
定期从根开始(在JS中就是全局对象)扫描内存中的对象。凡是能从根部到达的对象,都是还需要使用的。那些无法由根部出发触及到的对象被标记为不再使用,稍后进行回收。
此算法可以分为两个阶段,一个是标记阶段(mark),一个是清除阶段(sweep)。
-
标记阶段,垃圾回收器会从根对象开始遍历。每一个可以从根对象访问到的对象都会被添加一个标识,于是这个对象就被标识为可到达对象。
-
清除阶段,垃圾回收器会对堆内存从头到尾进行线性遍历,如果发现有对象没有被标识为可到达对象,那么就将此对象占用的内存回收,并且将原来标记为可到达对象的标识清除,以便进行下一次垃圾回收操作。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fc2y4K94-1617796650632)(垃圾回收机制.assets/169158136a253bc3)]](https://img-blog.csdnimg.cn/20210407195917136.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80Mzc0NTA3NQ==,size_16,color_FFFFFF,t_70)
在标记阶段,从根对象1可以访问到B,从B又可以访问到E,那么B和E都是可到达对象,同样的道理,F、G、J和K都是可到达对象。
在回收阶段,所有未标记为可到达的对象都会被垃圾回收器回收。
何时开始垃圾回收?
通常来说,在使用标记清除算法时,未引用对象并不会被立即回收。取而代之的做法是,垃圾对象将一直累计到内存耗尽为止。当内存耗尽时,程序将会被挂起,垃圾回收开始执行。
补充: 从2012年起,所有现代浏览器都使用了标记-清除垃圾回收算法。所有对JavaScript垃圾回收算法的改进都是基于标记-清除算法的改进,并没有改进标记-清除算法本身和它对“对象是否不再需要”的简化定义。
标记清除算法缺陷
-
那些无法从根对象查询到的对象都将被清除
-
垃圾收集后有可能会造成大量的内存碎片,像上面的图片所示,垃圾收集后内存中存在三个内存碎片,假设一个方格代表1个单位的内存,如果有一个对象需要占用3个内存单位的话,那么就会导致Mutator一直处于暂停状态,而Collector一直在尝试进行垃圾收集,直到Out of Memory。
引用计数算法
这是最初级的垃圾收集算法.现在已经没有浏览器会用这种算法.
此算法把“对象是否不再需要”简化定义为“对象有没有其他对象引用到它”。如果没有引用指向该对象(零引用),对象将被垃圾回收机制回收。
引用计数的含义是跟踪记录每个值被引用的次数。当声明了一个变量并将一个引用类型值赋给该变量时,则这个值的引用次数就是1。如果同一个值又被赋给另一个变量,则该值的引用次数加1。相反,如果包含对这个值引用的变量又取得了另外一个值,则这个值的引用次数减1。当这个值的引用次数变成0时,则说明没有办法再访问这个值了,因而就可以将其占用的内存空间回收回来。这样,当垃圾收集器下次再运行时,它就会释放那些引用次数为零的值所占用的内存。
引用计数缺陷
该算法有个限制:无法处理循环引用。如果两个对象被创建,并
互相引用,形成了一个循环。它们被调用之后会离开函数作用域,所以它们已经没有用了,可以被回收了。然而,引用计数算法考虑到它们互相都有至少一次引用,所以它们不会被回收。
Chrome V8回收算法
减少垃圾和回收对性能的影响:
主要注意以下两点:
-
让垃圾回收尽量少地进行,尤其是全堆垃圾回收。这部分我们基本上帮不了什么忙,主要靠v8自己的优化机制.
-
避免内存泄露,让内存及时得到释放. 即下面要讲的如何管理内存,避免内存泄漏
如何管理内存
JS 的内存自动管理一个最主要的问题就是分配给 Web 浏览器的可用内存数量通常比分配给桌面应用程 序的少。
最后
在面试前我花了三个月时间刷了很多大厂面试题,最近做了一个整理并分类,主要内容包括html,css,JavaScript,ES6,计算机网络,浏览器,工程化,模块化,Node.js,框架,数据结构,性能优化,项目等等。
包含了腾讯、字节跳动、小米、阿里、滴滴、美团、58、拼多多、360、新浪、搜狐等一线互联网公司面试被问到的题目,涵盖了初中级前端技术点。
-
HTML5新特性,语义化
-
浏览器的标准模式和怪异模式
-
xhtml和html的区别
-
使用data-的好处
-
meta标签
-
canvas
-
HTML废弃的标签
-
IE6 bug,和一些定位写法
-
css js放置位置和原因
-
什么是渐进式渲染
-
html模板语言
-
meta viewport原理
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注前端)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
做到真正的技术提升。**
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注前端)
[外链图片转存中…(img-ssRFYi9m-1713319111655)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 128
128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









