








最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
- [6.3所有节点](#63_223)
- [6.4创建高可用组](#64_247)
- [6.5测试](#65_305)
- [6.6监控 AG 状态](#66_AG__340)
- [6.7故障转移读取缩放AG上的主要副本](#67AG_356)
+ [7.参考连接](#7_500)
Docker部署SQL Server 2017 Always On集群
1.Docker部署Always on集群
SQL Server在2016年开始支持Linux。随着2017和2019版本的发布,它开始支持Linux和容器平台上的HA/DR、Kubernetes和大数据集群解决方案。
在本文中,我们将在3个机器的Docker容器上安装SQL Server 2017,并创建AlwaysOn可用性组。
2.前提工作
注意: 所有机器操作
2.1安装Docker
安装Docker就不介绍了,自行安装即可.
2.2配置时间同步
crontab -e #增加
* * * * * /usr/sbin/ntpdate time.windows.com && /usr/sbin/hwclock -w >/dev/null 2>&1
3.架构
| 主机名 | IP | 端口 | 角色 |
|---|---|---|---|
| sql01 | 192.168.1.30 | 1433:14335022:5022 | 主 |
| sql02 | 192.168.1.31 | 1433:14335022:5022 | 副本 |
| sql03 | 192.168.1.32 | 1433:14335022:5022 | 副本 |
端口表示:外网端口:内网端口
4.准备相关容器镜像
注意: 所有机器操作
拉取数据库的Docker镜像,如下
4.1SQL Server 2017
docker pull mcr.microsoft.com/mssql/server:2017-latest
可通过docker images来查看已下载的镜像信息。
镜像地址:https://hub.docker.com/_/microsoft-mssql-server
5.开始配置-容器
环境准备完毕后,开始正式的配置安装。
5.1创建Dockerfile
注意: 所有机器操作
创建目录用于存放dockerfile、docker-compose.yml等文件。
vi dockerfile
- dockerfile内容如下
FROM mcr.microsoft.com/mssql/server:2017-latest
RUN /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
RUN /opt/mssql/bin/mssql-conf set sqlagent.enabled true
说明:
FROM:表示基于什么镜像进行安装的
RUN:在镜像中进行的操作
5.2编译镜像
注意: 所有机器操作
通过dockerfile来编译镜像,用于后面的安装,命令:docker build -t mcr.microsoft.com/mssql/server:2017-ty .
其中mcr.microsoft.com/mssql/server为镜像名称,2017-ty是镜像标签,.表示在当前目录下编译,因为dockerfile就在当前目录下。
最后出现Successfully表示编译成功,否则根据错误信息进行解决。
5.3创建master容器
在sql01执行:
docker run --name sql01 \
--hostname sql01 \
-p 1433:1433 \
-p 5022:5022 \
-e 'ACCEPT\_EULA=Y' \
-e 'SA\_PASSWORD=P@ssw0rd02' \
-e "MSSQL\_AGENT\_ENABLED=True" \
-e "MSSQL\_PID=Developer" \
-d mcr.microsoft.com/mssql/server:2017-ty
5.4创建slave容器
在sql02执行:
docker run --name sql02 \
--hostname sql02 \
-p 1433:1433 \
-p 5022:5022 \
-e 'ACCEPT\_EULA=Y' \
-e 'SA\_PASSWORD=P@ssw0rd02' \
-e "MSSQL\_AGENT\_ENABLED=True" \
-e "MSSQL\_PID=Developer" \
-d mcr.microsoft.com/mssql/server:2017-ty
在sql03执行:
docker run --name sql03 \
--hostname sql03 \
-p 1433:1433 \
-p 5022:5022 \
-e 'ACCEPT\_EULA=Y' \
-e 'SA\_PASSWORD=P@ssw0rd02' \
-e "MSSQL\_AGENT\_ENABLED=True" \
-e "MSSQL\_PID=Developer" \
-d mcr.microsoft.com/mssql/server:2017-ty
至此容器已经启动完成,下面通过SSMS连接数据库进行相关检查和配置ALWAYSON。
5.5SSMS连接MSSQL
通过宿主机的外网IP+端口连接相应的数据库,如下:
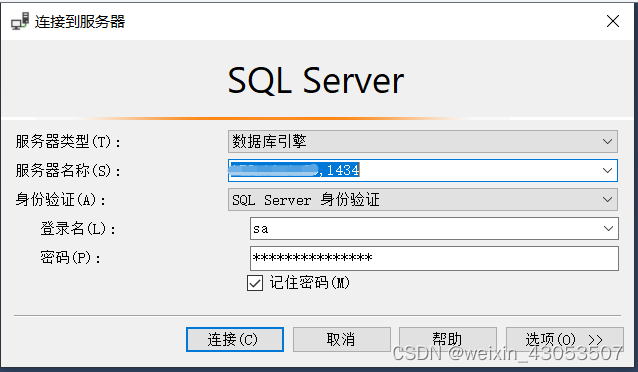
注意:IP和端口之间是逗号
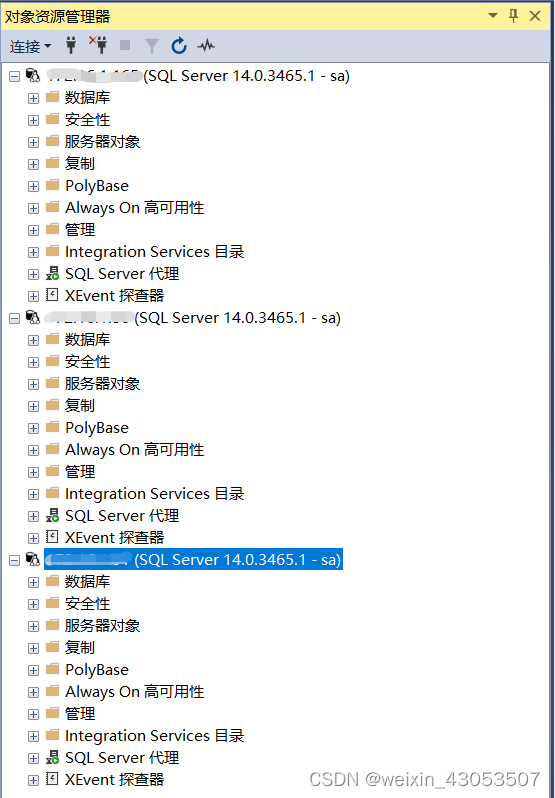
可以看到数据库的图标也是Linux的图标。
6.配置-数据库
这部分就是在数据库中进行相关配置,如:创建KEY加密文件,管理用户、可用组等。
6.1连接主库-sql01
主库也就是节点1,端口是1433,连接方法如上图。
我们将证书和私钥提取到/tmp/dbm_certificate.cer和/tmp/dbm_certificate.pvk文件中。
我们将这些文件复制到其他节点,并根据以下文件创建主密钥和证书:执行以下脚本
USE master
GO
CREATE LOGIN dbm_login WITH PASSWORD = 'Test@13579';
CREATE USER dbm_user FOR LOGIN dbm_login;
GO
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'Test@13579';
go
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE dbm_certificate
TO FILE = '/tmp/dbm\_certificate.cer'
WITH PRIVATE KEY (
FILE = '/tmp/dbm\_certificate.pvk',
ENCRYPTION BY PASSWORD = 'Test@13579'
);
GO
将文件拷贝到其他两个节点:
#sql01操作
docker cp sql01:/tmp/dbm_certificate.cer ./
docker cp sql01:/tmp/dbm_certificate.pvk ./
scp dbm_certificate.* 192.168.1.31:/data/ty/
scp dbm_certificate.* 192.168.1.32:/data/ty/
#sql02操作
docker cp dbm_certificate.cer sql02:/tmp/
docker cp dbm_certificate.pvk sql02:/tmp/
#sql03操作
docker cp dbm_certificate.cer sql03:/tmp/
docker cp dbm_certificate.pvk sql03:/tmp/
6.2连接从库-sql02和sql03
两个从库的端口分别是:1502和1503.然后重复主库执行的操作,如下:
CREATE LOGIN dbm_login WITH PASSWORD = 'Test@13579';
CREATE USER dbm_user FOR LOGIN dbm_login;
GO
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'Test@13579';
GO
CREATE CERTIFICATE dbm_certificate
AUTHORIZATION dbm_user
FROM FILE = '/tmp/dbm\_certificate.cer'
WITH PRIVATE KEY (
FILE = '/tmp/dbm\_certificate.pvk',
DECRYPTION BY PASSWORD = 'Test@13579'
);
GO
6.3所有节点
在所有节点上执行以下命令
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_IP = (0.0.0.0), LISTENER_PORT = 5022)
FOR DATA_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login];
GO
启用开机自启动ALWAYON,在所有节点执行以下命令
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON);
GO
6.4创建高可用组
可以用SSMS工具和T-SQL两种方式,下面以T-SQL为例:
运行以下脚本在主节点中创建一个可用性组。 请注意,选择CLUSTER_TYPE = NONE选项是因为它是在没有诸如Pacemaker或Windows Server故障转移群集之类的群集管理平台的情况下安装的。
如果要在Linux上安装AlwaysOn AG,则应为Pacemaker选择CLUSTER_TYPE = EXTERNAL:
CREATE AVAILABILITY GROUP [AG1]
WITH (CLUSTER_TYPE = NONE)
FOR REPLICA ON
N'sql01'
WITH (
ENDPOINT_URL = N'tcp://192.168.1.30:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
SEEDING_MODE = AUTOMATIC,
FAILOVER_MODE = MANUAL,
SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL)
),
N'sql02'
WITH (
ENDPOINT_URL = N'tcp://192.168.1.31:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
SEEDING_MODE = AUTOMATIC,
FAILOVER_MODE = MANUAL,
SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL)
),
N'sql03'
WITH (
ENDPOINT_URL = N'tcp://192.168.1.32:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
SEEDING_MODE = AUTOMATIC,
FAILOVER_MODE = MANUAL,
SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL)
);
GO
在从库中执行以下命令,将从库加入到AG组中
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = NONE);
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
GO
至此在Docker容器中安装SQL Server Alwayson集群已经完成了!
注意:当指定
CLUSTER_TYPE = NONE创建可用组时,在执行故障转移时需执行以下命令-- 将主角色转移到可用性组中的某个备份副本 ALTER AVAILABILITY GROUP [ag1] FORCE_FAILOVER_ALLOW_DATA_LOSS; -- 尝试进行优雅的故障转移,如果不能完成,则允许丢失数据 -- ALTER AVAILABILITY GROUP [ag1] FAILOVER;
6.5测试
在主库上创建一个数据库,并加入到可用组AG中。
--创建数据库
CREATE DATABASE agtestdb;
GO
ALTER DATABASE agtestdb SET RECOVERY FULL;
GO
BACKUP DATABASE agtestdb TO DISK = '/var/opt/mssql/data/agtestdb.bak';
GO
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [agtestdb];
GO
-- 创建表
use agtestdb
CREATE TABLE ExampleTable (
ID INT PRIMARY KEY,
Name NVARCHAR(50),
Description NVARCHAR(100)
);
-- 插入数据
DECLARE @counter INT = 1;
WHILE @counter <= 100
BEGIN
INSERT INTO ExampleTable (ID, Name, Description)
VALUES (@counter, 'Name ' + CAST(@counter AS NVARCHAR(10)), 'Description for ' + CAST(@counter AS NVARCHAR(10)));
SET @counter = @counter + 1;
END;
GO
通过SSMS查看同步状态是否正常.
6.6监控 AG 状态
通过以下这些视图可以监控 AG 中各个部分的状态。
group的监控
select * from sys.availability_groups; select * from sys.availability_groups_cluster; select * from sys.dm_hadr_availability_group_states;
replica 的监控
select * from sys.availability_replicas; select * from sys.dm_hadr_availability_replica_states; select * from sys.dm_hadr_availability_replica_cluster_nodes; select * from sys.dm_hadr_availability_replica_cluster_states;
在 AG 中的 database 的监控
select * from sys.availability_databases_cluster; select * from sys.dm_hadr_database_replica_states; select * from sys.dm_hadr_database_replica_cluster_states; select name,database_id,replica_id,group_database_id from sys.databases;
6.7故障转移读取缩放AG上的主要副本
每个可用性组仅有一个主要副本。 主要副本允许读取和写入操作。 若要更改哪个副本为主要副本,可进行故障转移。 在典型的可用性组中,群集管理器自动执行故障转移过程。 在群集类型为 NONE 的可用性组中,需手动执行故障转移过程。
在群集类型为 NONE 的可用性组中,有两种对主要副本进行故障转移的方法:
手动故障转移(无数据丢失)
强制手动故障转移(会丢失数据)
手动故障转移(无数据丢失)
主要副本可用时使用此方法,但你需要暂时或永久更改托管主要副本的实例。 若要避免潜在的数据丢失,发出手动故障转移前,确保目标次要副本为最新版本。
手动故障转移(无数据丢失):
- 将当前的主要副本和目标次要副本设置为 SYNCHRONOUS_COMMIT。
ALTER AVAILABILITY GROUP [AGRScale]
MODIFY REPLICA ON N'<node2>'
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以点击这里获取!](https://bbs.csdn.net/topics/618635766)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 325
325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









