







文末有福利领取哦~
👉一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
👉二、Python必备开发工具

👉三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉 四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(文末领读者福利)

👉五、Python练习题
检查学习结果。

👉六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉因篇幅有限,仅展示部分资料,这份完整版的Python全套学习资料已经上传
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
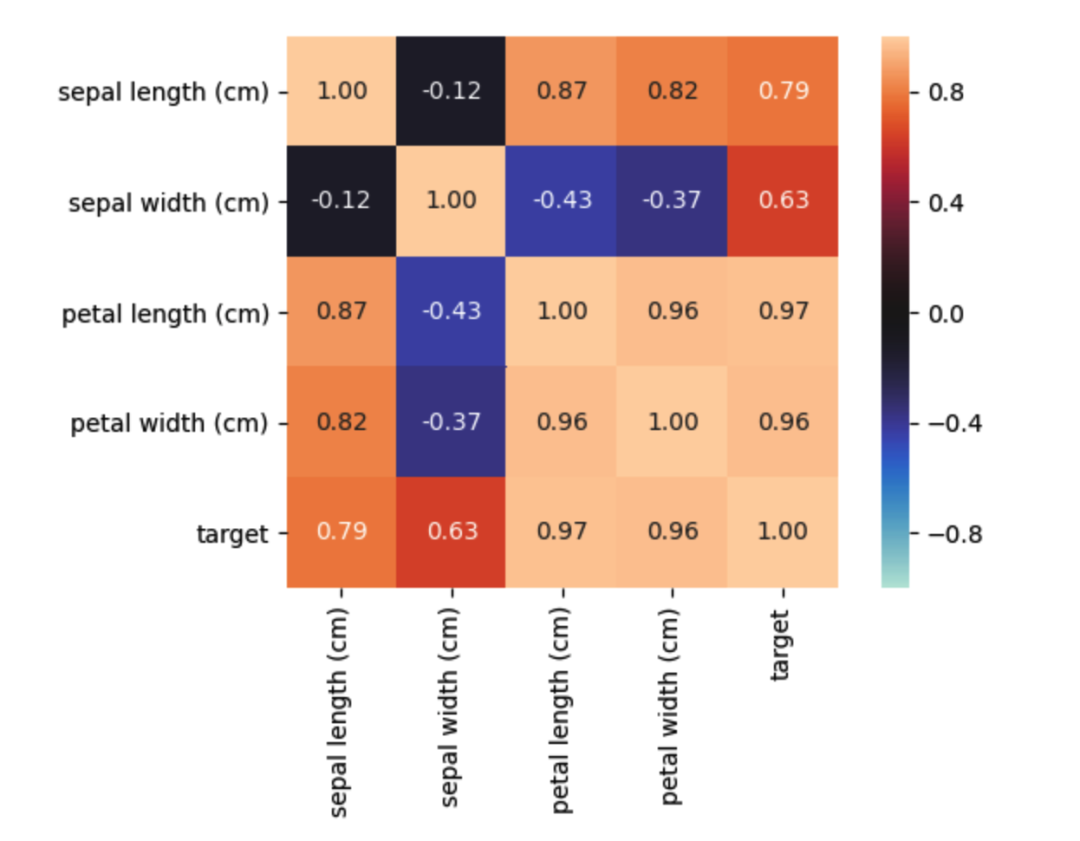
Plot features associations
associations(df)
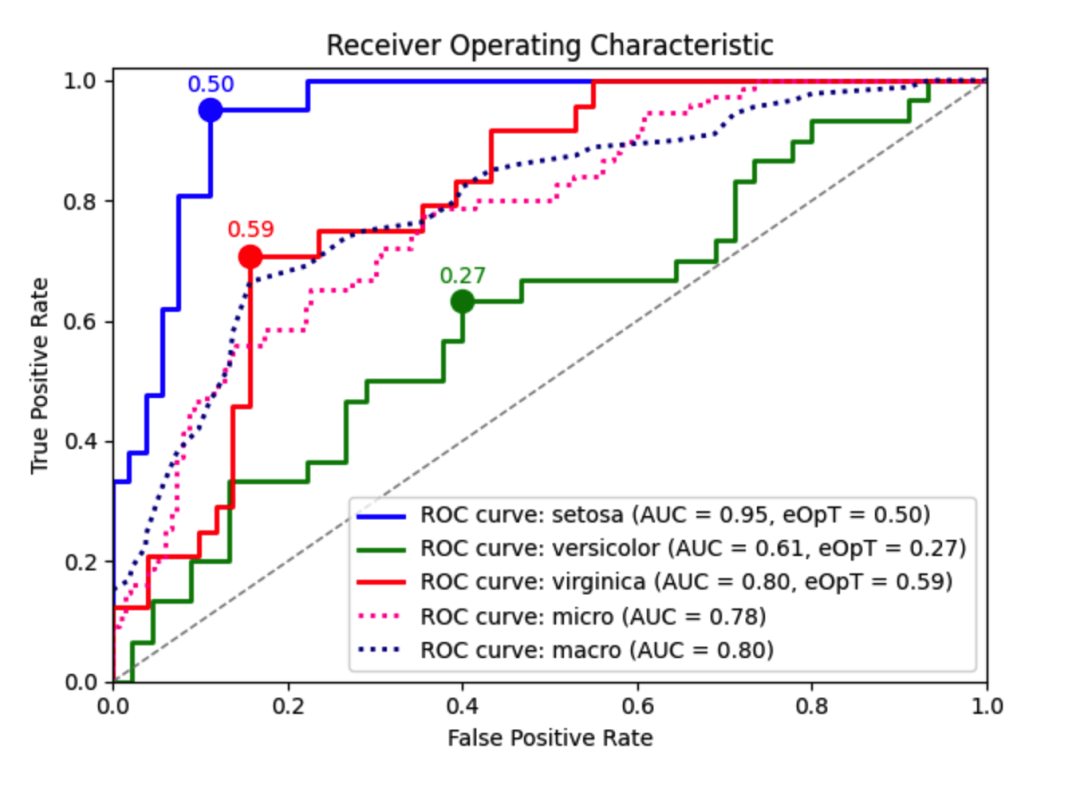
阈值寻找
只需要给定机器学习多种模型的预测,使用dython便可以轻松显示每个种模型的 ROC 曲线、AUC 分数并找到模型估计的最佳阈值
在Iris 数据集上绘制 SVM 模型预测示例ROC图,便可以使用dython.model_utils.metric_graph() 来进行实现
import numpy as np
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
from dython.model_utils import metric_graph
Load data
iris = datasets.load_iris()
X = iris.data
y = label_binarize(iris.target, classes=[0, 1, 2])
Add noisy features
random_state = np.random.RandomState(4)
n_samples, n_features = X.shape
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)]
Train a model
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.5, random_state=0)
classifier = OneVsRestClassifier(svm.SVC(kernel=‘linear’, probability=True, random_state=0))
Predict
y_score = classifier.fit(X_train, y_train).predict_proba(X_test)
Plot ROC graphs
metric_graph(y_test, y_score, ‘roc’, class_names=iris.target_names)
这个dython一共有4个子模块,分别实现分析、预测、检验、采样等功能
data_utils
data_utils子模块集成了一些基础性的数据探索性分析相关的API
-
identify_columns_with_na()可用于快速检查数据集中的缺失值情况
-
identify_columns_by_type()可快速选择数据集中具有指定数据类型的字段
-
one_hot_encode()可快速对数组进行「独热编码」
-
split_hist()则可以快速绘制分组直方图,帮助用户快速探索数据集特征分布
nominal
nominal子模块包含了一些进阶的特征相关性度量功能
-
associations()可以自适应由连续型和类别型特征混合的数据集,并自动计算出相应的Pearson、Cramer’s V、Theil’s U、条件熵等多样化的系数
-
cluster_correlations()可以绘制出基于层次聚类的相关系数矩阵图等实用功能
model_utils
model_utils子模块包含了诸多对机器学习模型进行性能评估的工具
-
ks_abc() 对二元分类器的正负分布执行 Kolmogorov-Smirnov 检验,然后找到最佳阈值,即能够实现最佳类别分离的阈值。
-
metric_graph()绘制预测器结果(包括 AUC 分数)的图表,其中 y_true 和 y_pred 的每一行代表一个示例。
sampling
sampling子模块则包含了boltzmann_sampling()和weighted_sampling()两种数据采样方法,简化数据建模流程。
-
boltzmann_sampling()从对提供的数字进行玻尔兹曼采样
-
weighted_sampling()从对所提供数字的加权采样
Dython的主要目的是实现各种功能的简易可读性,但是在性能上面稍有欠缺
大家如果对这个库想深入了解,可以参考网站 http://shakedzy.xyz/dython/ 来查看它的具体使用情况
好了,这就是今天的分享,技术永不眠,我们下期见~
授人以渔
一行当初为了学习技术买了太多的课程和书籍,但后来发现在这些资料不在多而在精
天下武功,为快不破,学习技术最高效的方式就是通过学习经典的书籍了
一行这里把自己学习技术路上的经典书籍全部整理出来,并通过网上的开源项目全部打包在一起分享给看到的知友,希望能够给你的技术能力加加速

你好,我是一行,厦门大学硕士毕业,用python发表过两篇顶刊论文 日常分享python的技术学习,面试技巧,赚钱认知等,欢迎关注
@一行玩python 一行肝了3天,精选了9个方面的计算机技术资料,希望能够对你能有帮助 链接:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









