







如果你也是看准了Python,想自学Python,在这里为大家准备了丰厚的免费学习大礼包,带大家一起学习,给大家剖析Python兼职、就业行情前景的这些事儿。
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。


四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

成为一个Python程序员专家或许需要花费数年时间,但是打下坚实的基础只要几周就可以,如果你按照我提供的学习路线以及资料有意识地去实践,你就有很大可能成功!
最后祝你好运!!!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
格式:“if 后的结果” if num >= 60 else “else的结果”
def test\_judge2(self):
"""
使用三元运算符判断 成绩是否及格
@return:
"""
num = int(input("请输入一个数字:"))
# 这个三元运算符和 JAVA,C不同,它if后的结果是写在最前面的
res = "及格" if num >= 60 else "不及格"
print(res)
一个数值的范围比较
- 常规的写法
def test\_judge5(self):
"""
判断一个值得的范围大小
@return:
"""
num = int(input("请输入一个数字:"))
if num >= 0 and num <= 100:
print("数字在0-100之间")
else:
print("数字不在0-100之间")
- 简洁的写法
def test\_judge6(self):
"""
判断一个值得的范围大小
@return:
"""
num = int(input("请输入一个数字:"))
# 使用更简洁的写法
if 0 <= num <= 100:
print("数字在0-100之间")
else:
print("数字不在0-100之间")
有的场景下使用 try…exception 代替if…else
在判断字典的某一个 key 是否为空,可以用 try…exception来实现
def test\_judge3(self):
dict_data = {
"user\_base": {
"uid": 1,
"uname": "allen",
"email": "hjc\_042043@sina.cn"
},
"user\_info": {
"age": 18,
"sex": "男"
}
}
try:
score = dict_data["user\_base"]["score"]
except KeyError:
score = 0
print(score)

list 在判断下标是否存在时也可以用这个方法
def test\_judge4(self):
"""
判断列表中是否有某一个索引值
@return:
"""
list_data = [78, 82, 93, 84, 65]
try:
score = list_data[6]
except IndexError:
score = 0
print("学生成绩:", score)
2、字符串相关
字符串函数有很多,因篇幅有限列举3个,具体参考这个连接:https://baijiahao.baidu.com/s?id=1769926940734111824&wfr=spider&for=pc
格式化连接
- 常规的字符串连接
uid = 123
uname = 'allen'
age = 18
string = 'uid=' + str(uid) + '&uname=' + uname + '&age=' + str(age)
print(string)
- 使用字符串对象的format格式化连接
string = 'uid={}&uname={}&age={}'.format(uid, uname, age)
print("字符串对象的format方法:", string)
- 格式化方式f-string(python3.6之后):
string = f'uid={uid}&uname={uname}&age={age}'
print("f-string:", string)
打印结果:
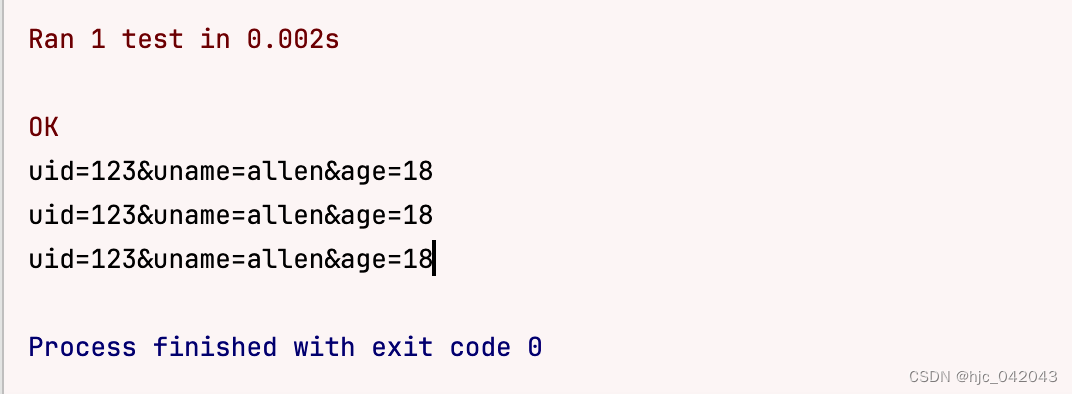
字符串的分割
字符串分割,默认以空白符分割,除了空格还有其他符号,比如:\t,\n,\r
也可以指定分隔符,比如:,或|,#等其他字符
def test\_split(self):
uname = "Tom green yellow"
new_list = uname.split()
print(new_list)
num_str = "1,2,3,4,5,6,7,8,9,10"
new_list = num_str.split(",")
print(new_list)
num_str = "1|2|3|4|5|6|7|8|9|10"
new_list = num_str.split("|")
print(new_list)
pass
字符串的连接
def test\_join(self):
"""
字符串连接,默认以空白符连接,除了空格还有其他符号,比如:\t,\n,\r
@return:
"""
list = ["Tom", "green", "yellow"]
new_str = "".join(list)
print(new_str)
list = ["1", "2", "3", "4", "5", "6", "7", "8", "9", "10"]
new_str = ",".join(list)
print(new_str)
list = ["1", "2", "3", "4", "5", "6", "7", "8", "9", "10"]
new_str = "|".join(list)
print(new_str)
pass
3、生成器
- yield即生成器,相比return的优势是 循环体内,程序在执行到yield时,程序会暂停,并把值出栈;
这样子就不会占用内存,下次循环进来时再接着上一次的yield的位置继续往下执行,而return的方式是先把数据都存放在栈中,一次性全部返回- yield可以处理比较耗时,占用内存的操作,比如网络请求,文件读取等,类似异步处理,比如一边下载文件,一边把文件内容显示出来
下面列举两个简单的例子
- 例子1:
计算100以内的平方数
import unittest
class YieldTestCase(unittest.TestCase):
"""
todo: 计算100以内的平方数
@return:
"""
def test\_return\_square(self):
lst = return_square()
print(lst)
pass
def test\_yield\_square(self):
gen = yield_square()
for e in gen:
print(e)
pass
pass
def return\_square():
"""
todo 使用return用于生成100以内的平方数
@return:
"""
lst = []
for i in range(100):
lst.append(i \*\* 2)
return lst
def yield\_square():
"""
todo 使用yield实现一个生成器,用于生成100以内的平方数
"""
for i in range(100):
yield i \*\* 2
- 例子2:
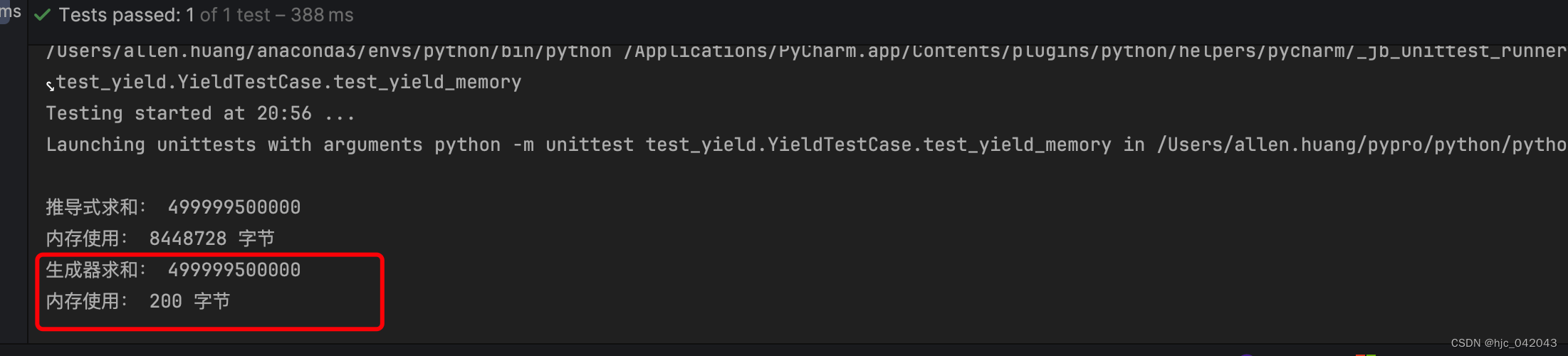
测试下内存的使用情况,数值是100W
def test\_yield\_memory(self):
# 先用列表推导式生成一个1000000的列表,再求和
list1 = [x for x in range(1000000)]
sum1 = sum(list1)
print("推导式求和:", sum1)
print("内存使用:", sys.getsizeof(list1), "字节")
# 用生成器生成一个1000000的列表,再求和
list2 = (x for x in range(1000000))
sum2 = sum(list2)
print("生成器求和:", sum2)
print("内存使用:", sys.getsizeof(list2), "字节")
pass
通过测试比较,效果一目了然,面对大数据,吃内存,耗时大的,使用生成器较好
4、列表相关
取最后一个元素
def test9(self):
lst = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 取最后一个元素
print(lst[-1])
判断列表是否为空
def test10(self):
"""
判断list是否为空
@return:
"""
lst = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 不好的写法:
if len(lst) > 0:
print('列表不为空')
# 好的写法
if lst:
print('列表不为空')
pass
列表合并
def test13(self):
list1 = [1, "hjc", "email", 3.14, True]
list2 = [2, "username"]
print("将list+list2两个列表合并:", list1 + list2)
list3 = [1, 2, 3, 4, 5]
list4 = [6, 7, 8, 9, 10]
print("将list3+list4两个列表合并:", [\*list3, \*list4])
pass
去除列表中的重复值
def test12(self):
"""
去掉列表中的重复值
@return:
"""
lst = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3]
my_set = set(lst)
print(list(my_set))
pass
判断某个值是包含在序列中
def test11(self):
"""
判断某个值是否包含在序列中,包含列表,字符串,元组,字典等
@return:
"""
lst = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
num = 5
# 某个值是否包含在列表中,类似于 JAVA 的 a.contains(b)方法
if num in lst:
print('列表中包含该元素')
else:
print('列表中不包含该元素')
# 某个字符子串是否包含着一个字符串中
string = 'hello world'
if 'hello' in string:
print('字符串中包含该子串')
else:
print('字符串中不包含该子串')
# 字典的键是否包含在字典中
dic = {'name': 'allen', 'age': 20}
if 'name' in dic:
print('字典中包含该键')
else:
print('字典中不包含该键')
pass
列表推导式
- 常规for循环
def test1(self):
"""
使用常规的for循环遍历列表,将列表中的元素转换为大写
@return:
"""
new_list = []
for fruit in self.fruites:
new_list.append(fruit.upper())
print(new_list)
pass
- 列表推导式:
这个推导式中的含义是:
①先看for循环,把元素遍历出来,
②再看 fruit.upper(),把循环体中元素转换为大写,
③最后把结果赋值给new_list
def test2(self):
"""
todo:使用列表推导式将列表中的元素转换为大写
@return:
"""
new_list = [fruit.upper() for fruit in self.fruites]
print(new_list)
pass

带条件的列表推导式
- 常规
列表遍历,并且将以 a 开头的元素转换为大写
def test3(self):
new_list = []
for fruit in self.fruites:
if fruit.startswith('a'):
new_list.append(fruit.upper())
print(new_list)
pass
- 推导式简写
def test4(self):
new_list = [fruit.upper() for fruit in self.fruites if fruit.startswith('a')]
print(new_list)
pass

5、字典相关
俩字典合并
格式:新的字典 = {**字典1,**字典2}
def test\_dict\_merge(self):
"""
合并两个字典
:return:
"""
dict1 = {"a": 1, "b": 2, "c": 3}
dict2 = {"d": 4, "e": 5, "f": 6}
# 这里两个字典的\*\*表示解包,将两个字典的键值对合并成一个新的字典
new_dict = {\*\*dict1, \*\*dict2}
print(new_dict)
字典反转
使用map 函数来对字典序列,回调反转排序函数
def test\_everse(self):
"""
字典反转
@return:
"""
dict1 = {
'one': 1,
'tow': 2,
'three': 3
}
new_dict = dict(map(reversed, dict1.items()))
print(new_dict)
对字典列表中的元素进行排序
def test\_sort\_item(self):
"""
根据字典列表中的字典元素年龄进行倒序排列
@return:
"""
dict_list = [
{'name': 'allen', 'age': 18},
{'name': 'john', 'age': 20},
{'name': 'tom', 'age': 15}
]
new_dict_list = sorted(dict_list, key=lambda x: x['age'], reverse=True)
print(new_dict_list)
将两个列表的值组成字典
def test\_lists\_to\_dict(self):
"""
将两个列表合并到一个字典中,一个列表的值作为 key,另一个列表的值作为 value
### 最后
Python崛起并且风靡,因为优点多、应用领域广、被大牛们认可。学习 Python 门槛很低,但它的晋级路线很多,通过它你能进入机器学习、数据挖掘、大数据,CS等更加高级的领域。Python可以做网络应用,可以做科学计算,数据分析,可以做网络爬虫,可以做机器学习、自然语言处理、可以写游戏、可以做桌面应用…Python可以做的很多,你需要学好基础,再选择明确的方向。这里给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
#### 👉Python所有方向的学习路线👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

#### 👉Python必备开发工具👈
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

#### 👉Python全套学习视频👈
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

#### 👉实战案例👈
学python就与学数学一样,是不能只看书不做题的,直接看步骤和答案会让人误以为自己全都掌握了,但是碰到生题的时候还是会一筹莫展。
因此在学习python的过程中一定要记得多动手写代码,教程只需要看一两遍即可。

#### 👉大厂面试真题👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

**[需要这份系统化学习资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









